(1) 변수
- 값을 저장하는 메모리를 말한다.
- 또한 메모리를 준비시키는 명령문을 변수선언이라 한다.
-> 메모리종류 메모리이름;
-> datatype variable;
-> ex) String str;
(2) 변수의 데이터 타입
1) 정수
1byte byte a; // -128 ~ +127
2byte short b; // -32768 ~ +32767
4byte int c; // 약 -21억 ~ +21억
8byte long d; // 약 -922경 ~ +922경
2) 부동소수점
4byte float x; // 유효자릿수 7자리
8byte double y; // 유효자릿수 15자리
3) 논리
(4byte) boolean v;
4바이트라 명시되진 않았음.
4) 문자
2byte char ch; // UCS-2에 따른 0~65535의 16비트 코드
1) 2) 3) 4) -> 이 8개를 java primitive data type, 자바 원시(기본) 데이터 타입 이라 한다.
5) 레퍼런스
- 메모리 주소를 저장한다.
- 원시 타입을 제외한 모든 데이터 타입은 레퍼런스다. // String도 일단은 레퍼런스이다.
- ex) Object obj;
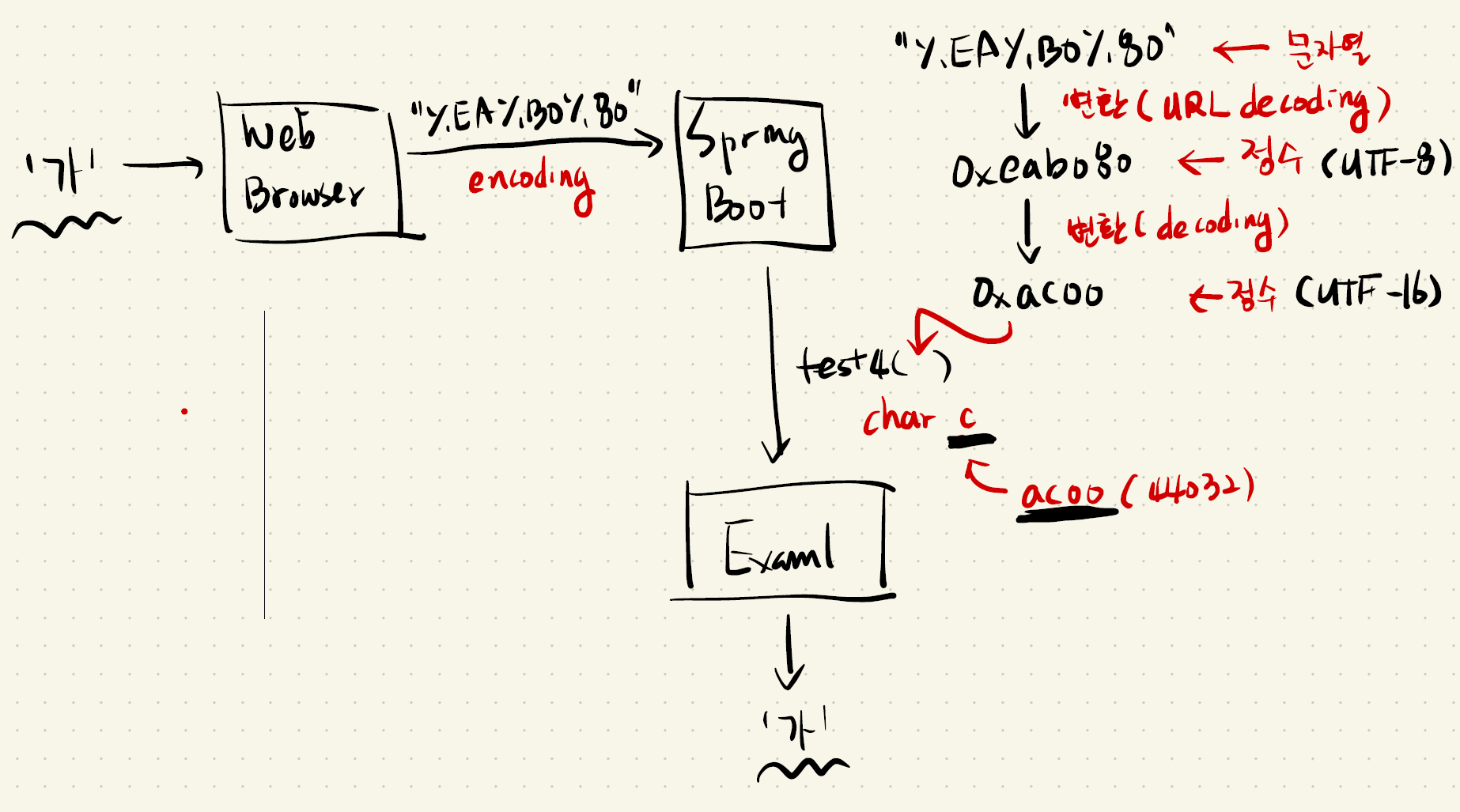
(3) 문자전송과 URL 인코딩
-
URL을 작성할 때 문자사용규칙에 따라 변환한다. (RFC 3986)
-
영어, 숫자, 특수문자는 변환 없이 보낸다.
-
위의 경우가 아니라면. 퍼센트 인코딩(URL 인코딩)에 따라, 문자에 부여된 정수값을 "%-"식으로 문자열로 변환한다.
-
7비트 네트워크 장비를 거쳐갈 때 데이터가 짤리지 않도록 조치하기 위한 방법이다.
-
ex)
!(0x21) -> "%21"
#(0x23) -> "%23"
+(0x2B) -> "%2B"
?(0x3F) -> "%3F"
가(0xEAB080) -> "%EA%B0%80"
(4) 논리값 전송 및 수신
-
JVM 내부에서 true, false를 정수 값(1,0)으로 다룬다고 해서 boolean 변수에 직접 1과 0을 저장할 수는 없다.
-
하지만 브라우저에선 스프링부트서 개입하므로, 변수에 1,0 등을 저장해도 정상적으로 true, false가 출력된다.
(5) 크기가 다른 변수끼리의 값 할당
-
변수의 값을 다른 변수에 저장할 때, 값의 크기에 상관없이 같거나 큰 크기의 메모리이어야 한다.
-
ex)
long l = 100;
int i = 100;
short s = 100;
byte b = 100;
char c = 100;
long l2;
int i2;
short s2;
byte b2;
char c2;
// long ===> long 이상
l2 = l;
//i2 = l; // 컴파일 오류
//s2 = l; // 컴파일 오류
//b2 = l; // 컴파일 오류!
//c2 = l; // 컴파일 오류!
// int ===> int 이상
l2 = i;
i2 = i;
//s2 = i; // 컴파일 오류!
//b2 = i; // 컴파일 오류!
//c2 = i; // 컴파일 오류!
// short ===> short 이상
l2 = s;
i2 = s;
s2 = s;
//b2 = s; // 컴파일 오류!
//c2 = s; // 컴파일 오류! char(0 ~ 65535) | short(-32768 ~ 32767)
// byte ===> byte 이상
l2 = b;
i2 = b;
s2 = b;
b2 = b;
//c2 = b; // 컴파일 오류! char(0 ~ 65535) | byte(-128 ~ 127)
float f;
double d;
d = 3.14;
// 값의 유효 여부에 상관없이 메모리 크기가 큰 변수의 값을 작은 크기에 변수에 저장할 수 없다.
//f = d; // 문법 오류!(6) 배열
-
같은 종류의 메모리를 여러개 만드는 명령문이다.
-
int age1, age2, age3 ...; 이런식으로 메모리를 계속 할당시키는건 비효율적이므로,
int age = new int[30]; 처럼 배열을 사용하여 4바이트 메모리를 30개 만드는 형태로 사용한다. -
new int[30]; ->여기서 new는 메모리를 준비시키는 명령이다.
-
int age[30]; 이런 식으로 사용하진 않는다. -> 이건 C / C++ 언어의 문법이다.
-
각각의 메모리에 접근할 땐 다음의 방식으로 한다.
age[0]=98;
age[2]=80;
age[29]=100;
(7) 배열의 활용
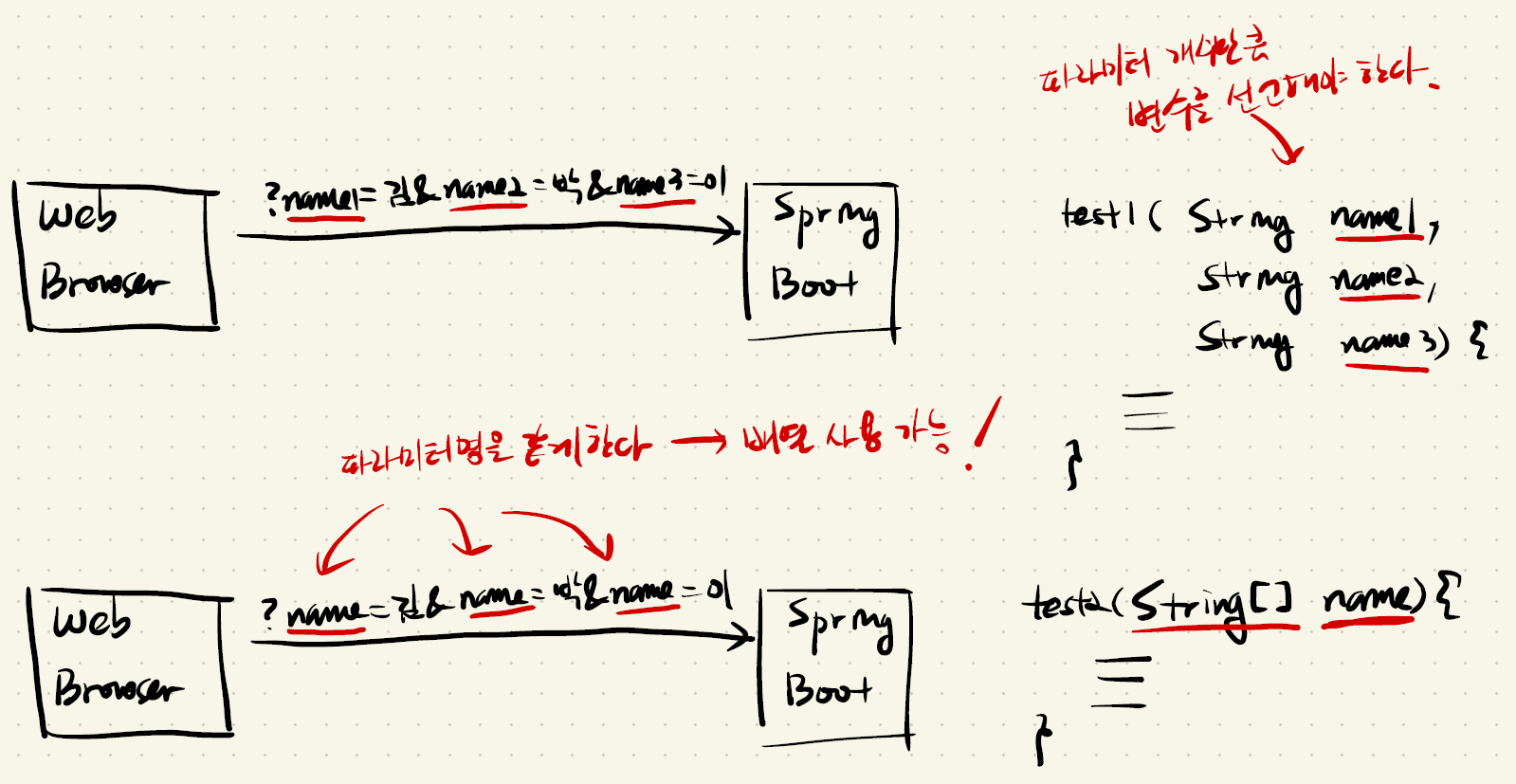
(8) 배열과 메모리
-
변수의 선언은 특정 데이터 종류와 특정 크기의 메모리를 준비하는 것이다.
-
int age1, age2, age3, age4, age5, age6, age7, age8, age9;
-
만약 같은값을 여러개 저장해야되는 상황이라면 위와 같이 유사한 이름으로 변수명을 적을것이다.
-
또한, 저장할 값의 개수가 많아진다면 변수 선언이 더 번거로워진다.
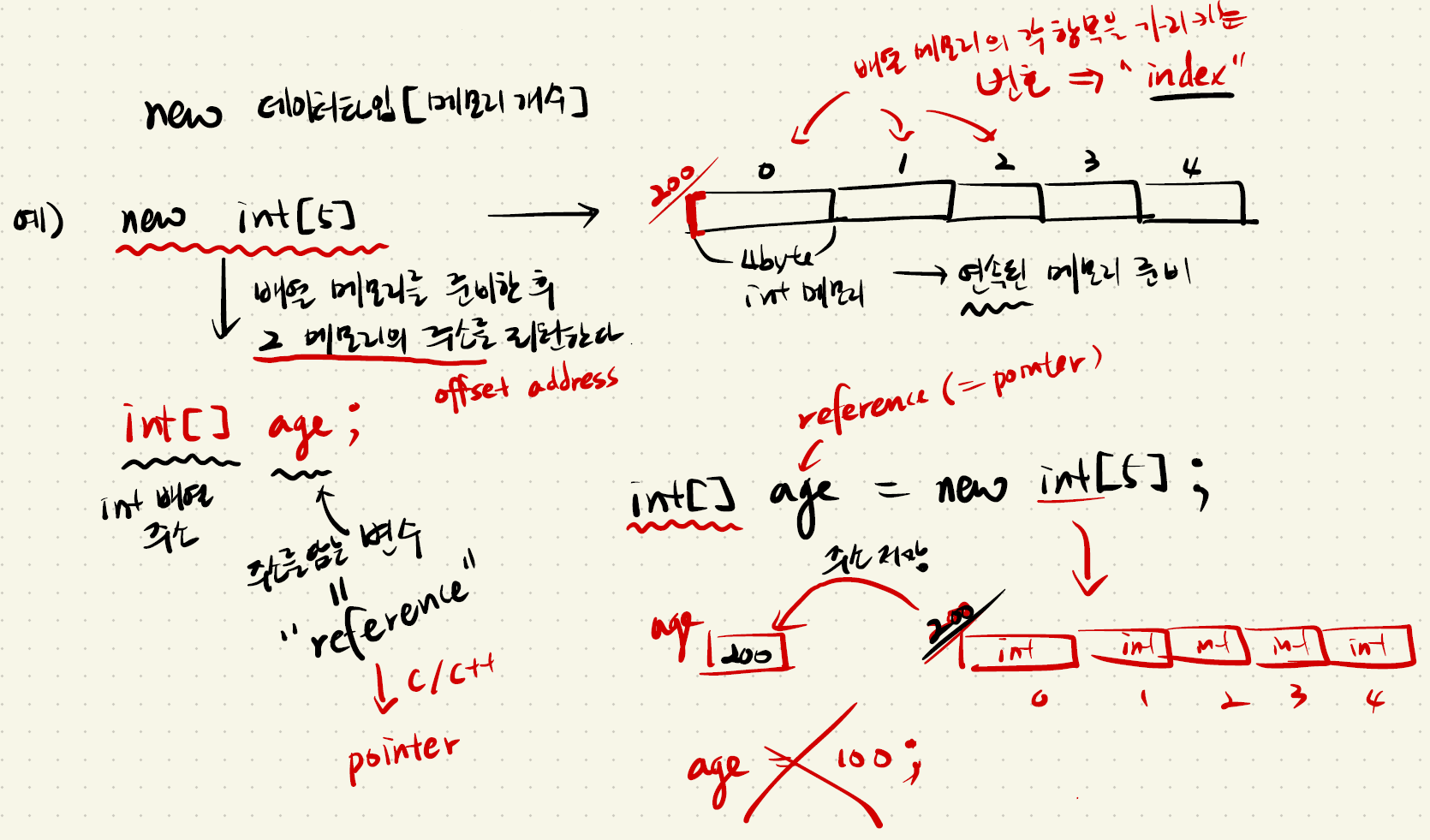
-
int[] age; : 배열 메모리를 준비한 후 그 메모리의 주소를 리턴한다.
-- 여기서 age는 주소를 담는 변수인 레퍼런스이고, C 혹은 C++에서는 이 개념을 포인터라 칭한다.
-- 여기에서의 주소는 절대적인 위치가 아니라, 어떤 기준점으로부터의 위치를 말하며, 그 기준점을 offset address라 한다.
-- 더 자세히 이야기하면, RAM이라는 메모리는 운영체제가 관리하고, 프로그램이 이걸 쓰려면 운영체제를 통해 받아야 한다. 주소란 RAM 안에서 offset address를 주소로 갖는 특정 메모리에 대해, 몇 번째 떨어져있는 메모리인지를 나타내는 개념이다.
ex) age가 offset으로부터 200번째 떨어져 있으면 이것이 address가 된다. -
new int[5]; : 배열 메모리의 각 항목을 가리키는 번호를 index라 한다.
-
int age = new int[5]; : age의 메모리 안엔 200번째라는 주소가 담기고 다른 메모리에 각 배열의 값이 담긴다.
-- 이때, age를 reference(참조변수)라 부른다. (정확히는 배열 reference)
=> 여기에 주소 이외의 값이 담기면 컴파일 오류가 난다.
(9) 레퍼런스와 인스턴스
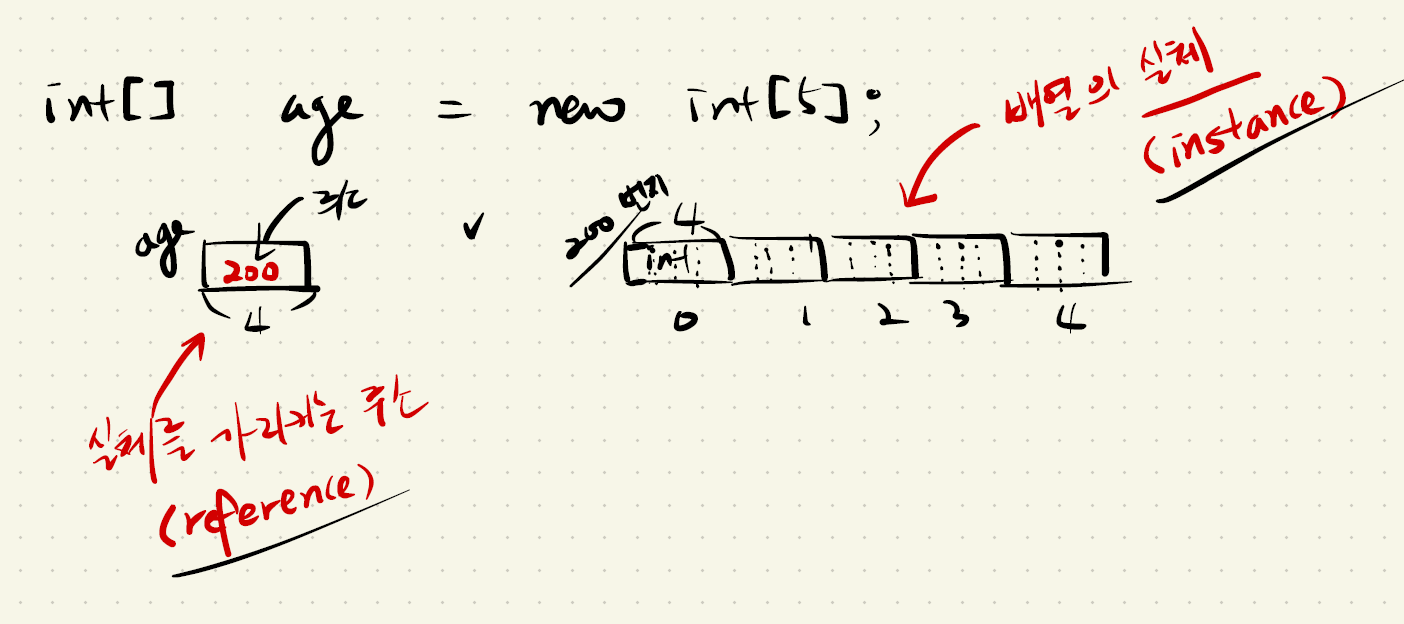
- int[ ] age -> 여기의 주소가 200이면 (실체를 가리키는 주소)
new int[5] -> 여기에 할당된 메모리의 주소도 모두 200이다. - 그리고 new int[5]에 할당된 메모리는 배열의 실체이고, 이 실체를 배열 instance 라고 한다.
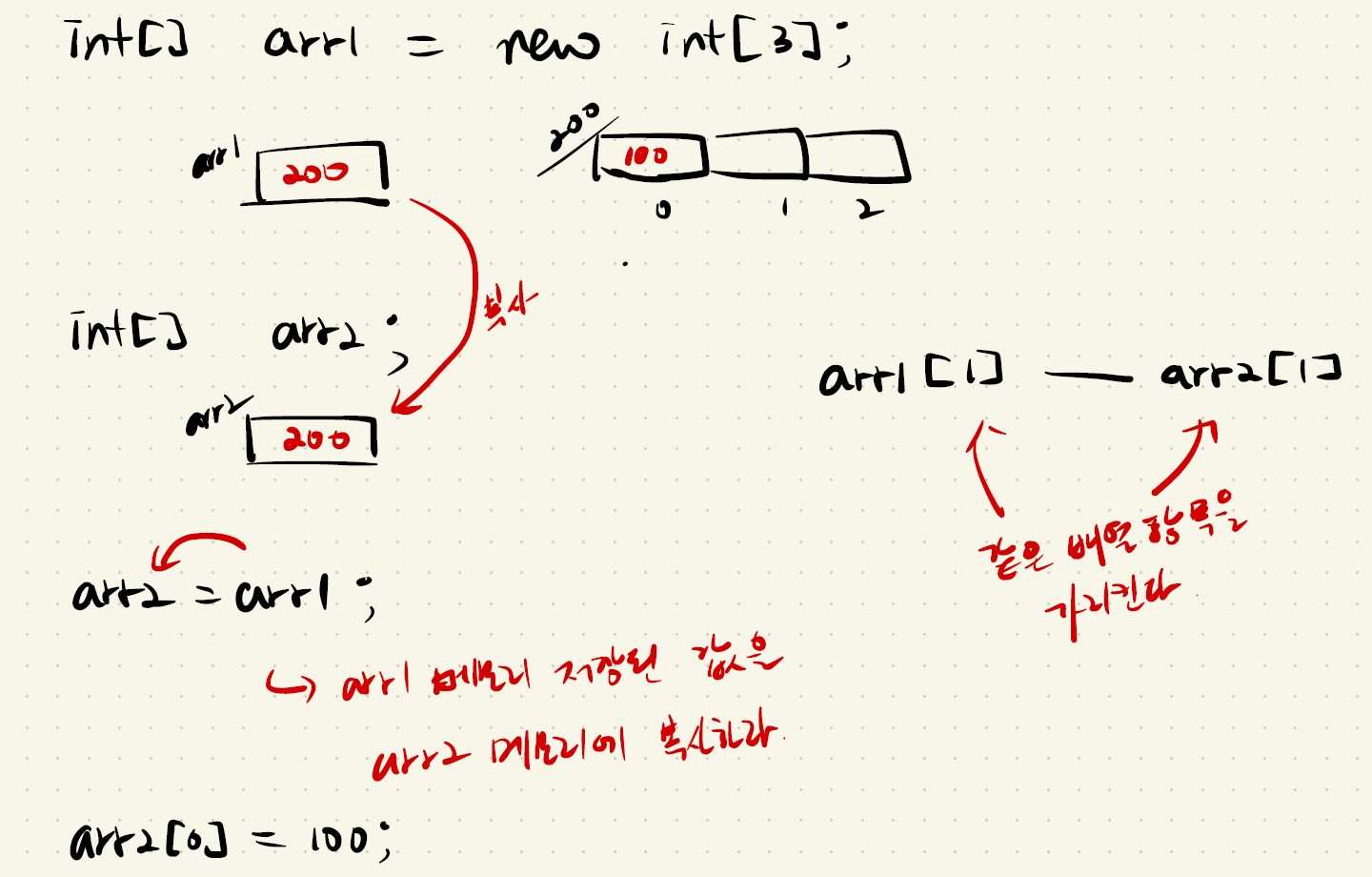
- int[] arr1 = new int[3];
int[] arr2; 에서
arr2=arr1; 을 통해 arr1 메모리에 저장된 값을 arr2 메모리에 복사하면, 두 배열의 주소가 같아지므로, arr1[1] 과 arr2[1]는 같은 배열 항목을 가리킨다.
(10) 레퍼런스와 인덱스
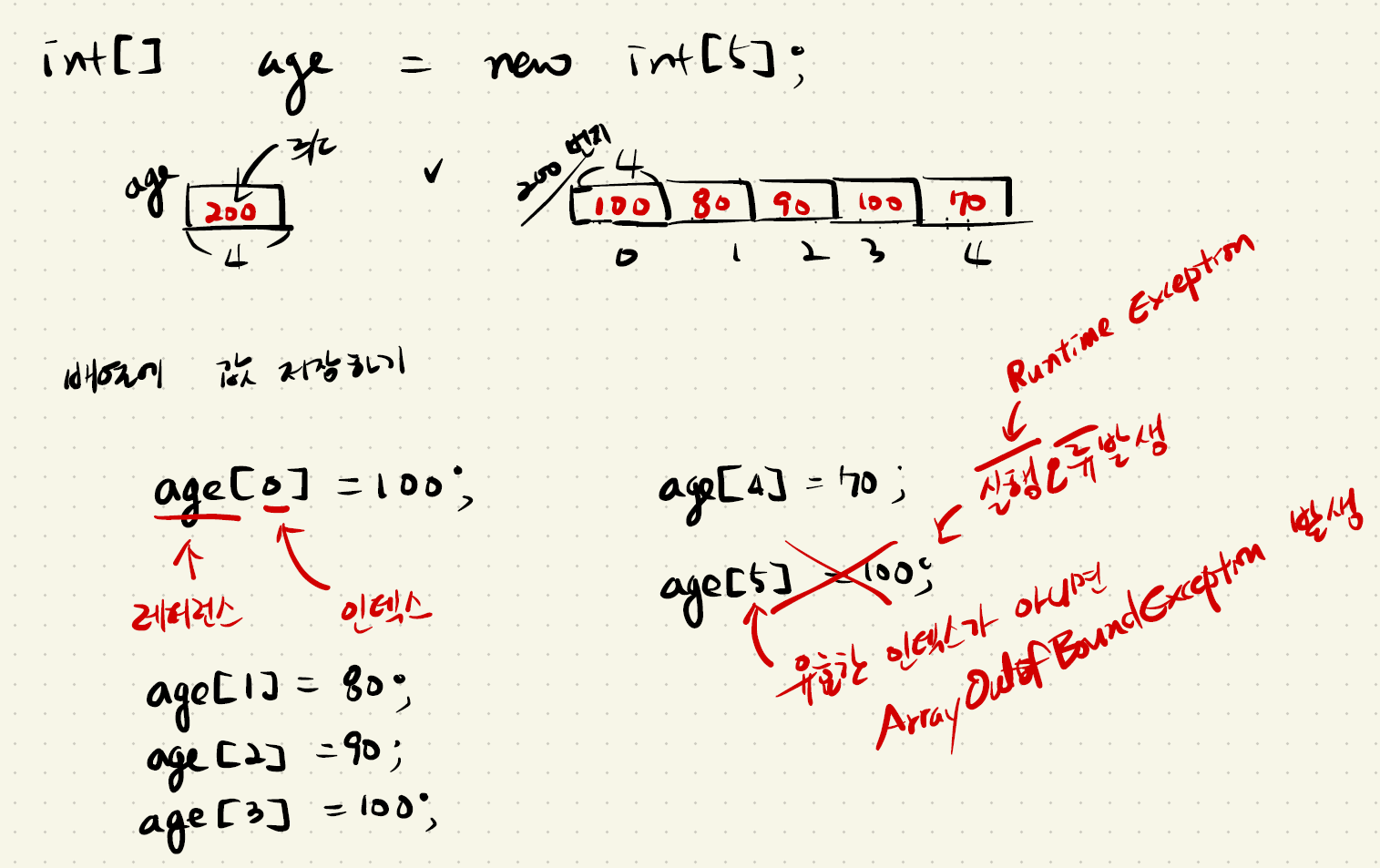
- age[5] =100; 의 경우 실행 오류가 발생한다 (Runtime Exception).
배열의 크기는 5로 age[4]까지밖에 존재하지 않고, 유효한 인덱스가 아니면 ArrayOutofBoundException이 발생한다.
(11) 배열을 만들때 배열의 개수가 너무 많은 경우
-
배열의 최대 크기는 (Integer.MAX_VALUE - 2)이며, //JVM 규칙에 그렇게 나와있다.
-
Exception in thread "main" java.lang.OutOfMemoryError: Requested array size exceeds VM limit => 다음 오류는 VM의 배열의 크기 제한을 초과하였을때 발생하며, 배열의 최대 크기 이하로 설정하여야 한다.
-
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space => 다음 오류는JVM이 OS로부터 사용 허가를 받은 메모리 크기를 벗어났기 때문에 발생하며 다음의 방법으로 해결한다.
-- JVM을 실행할 때 최대 힙(heap) 메모리의 크기를 늘리기 위해, JVM 실행 옵션에 다음을 추가한다.
--Xmx메모리크기
ex) $ java -Xmx9g : 9기가로 바꿔줌-- RAM의 크기가 작더라도, 부족한 메모리는 ROM을 사용한다. 단지 RAM보다 처리속도는 현저히 느려진다.
(12) Garbage와 Garbage Collector
-
int[] arr1 = new int [5]; 일때 arr1의 주소가 200이다.
-
arr1 = new int [3]; 에서 arr1에 새로운 주소 700이 할당된다. 이때 윗줄의 배열(5개짜리 배열)에선 레퍼런스가 사라졌으므로 더이상 접근 할 수가 없다.
이때 주소를 알고있는 레퍼런스가 없어서 더이상 사용할 수 없는 메모리를 garbage라고 한다. -
garbage는 java 프로그램 종료되면 전부 사라진다. 자바한테 쓰라고 준 메모리를 os가 전부 회수해버리기 때문이다.
-
만약 java프로그램이 꺼지지 않고 계속 돌아간다면, 적절한 시점에 (메모리가 부족하거나 cpu가 한가할때) garbage collector가 garbage를 자동 제거한다.
(13) 배열 인스턴스 자동 초기화
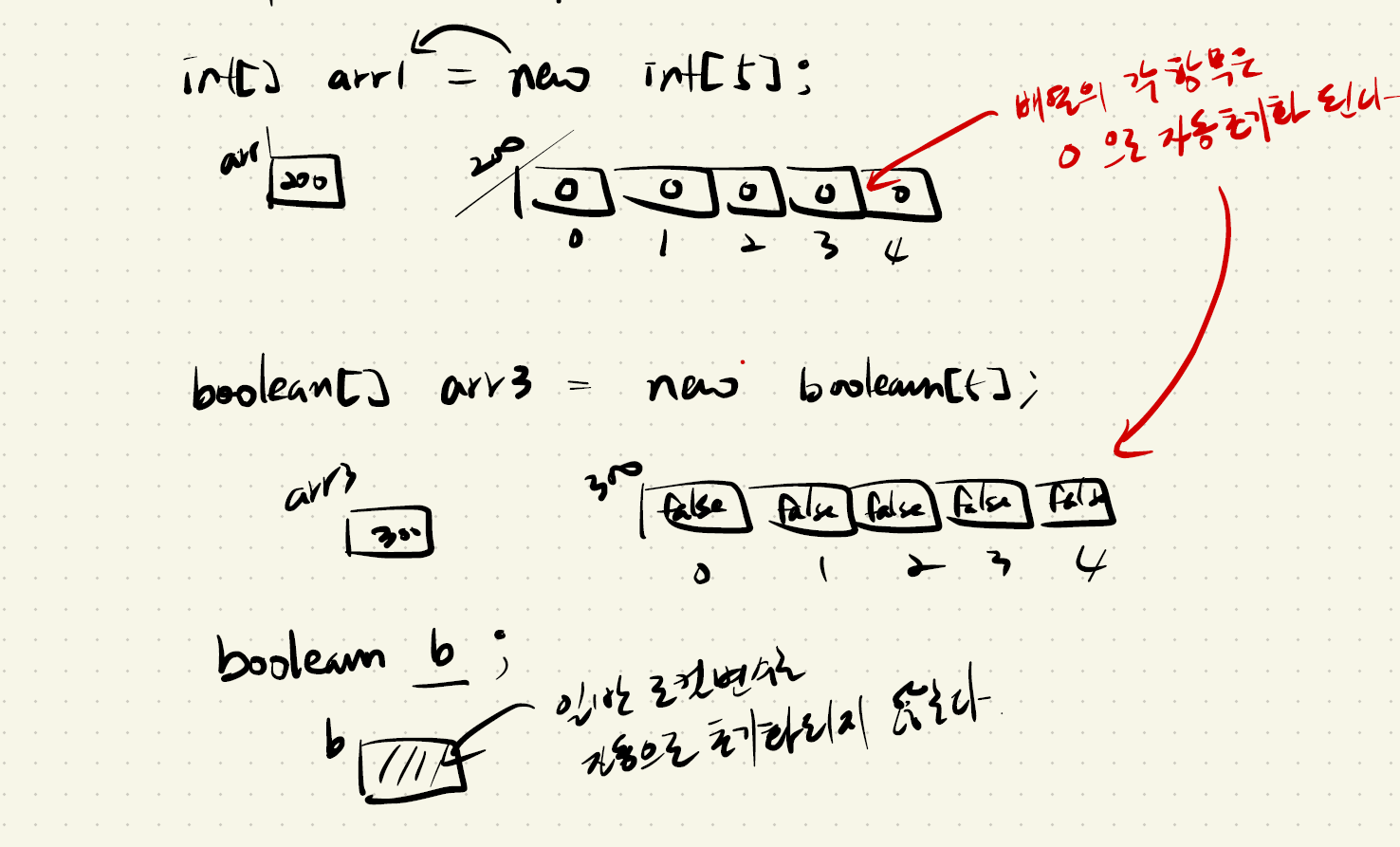
- 로컬 변수와 달리 new 명령으로 확보된 메모리는 종류에 상관없이 기본 값으로 자동 초기화 된다.
-> 따라서 배열 메모리 또한 생성되는 순간 기본 값으로 자동 초기화 된다.
-- 정수 배열(byte[], short[], int[], long[]) : 0
-- 부동소수점 배열(float[], double[]) : 0.0
-- 논리 배열(boolean[]) : false
-- 문자 배열(char[]) : '\u0000' -> null
-- 주소 변수(Object[]) : null
※ for each문
int[] arr1;
arr1 = new int[5];
arr1[0] = 100;
arr1[1] = 90;
arr1[2] = 80;
arr1[3] = 70;
arr1[4] = 60;
// 배열 변수에 들어 있는 값의 합계를 구해 보자!
int sum2 = 0;
for (int item : arr1) {
sum2 = sum2 + item;
}
System.out.println(sum2);위의 코드를 실행해보면, for each문에서 arr1의 각 item의 값들이 순차적으로 sum2 의 값에 더해지고 입력된다. 이는 배열의 마지막 item까지 반복이 되어 sum2에는 arr1의 모든 값들이 더해진 값이 입력된다.
(14) 배열 레퍼런스와 null
- 배열 레퍼런스를 초기화시키고 싶다면 null로 설정한다.
-ex)
int[] arr1;
arr1 = new int[5];
arr1 = null;-
이렇게 하면 레퍼런스의 주소값을 0으로 설정하여, 레퍼런스가 아무것도 가리키지 않게 만든다. 그렇다고 arr1 = 0;, 이런식으로 사용하면 안된다.
=> 억지로 사용할경우 다음과 같은 오류가 발생한다.
Exception in thread "main" java.lang.Error: Unresolved compilation problem:
Type mismatch: cannot convert from int to int[] -
인스턴스의 경우 초기화되는것이 아니라. 계속 메모리에 남는다.
-
레퍼런스가 배열 인스턴스를 가리키지 않은 상태에서 사용하려 하면,
System.out.println(arr1[0]); // NullPointerException 실행 오류가 발생한다.
(15) 배열 메모리 초기화
1) 배열 선언 + 초기화
-
형태 : 데이터타입[] 변수명 = new 데이터타입[]{값, 값, 값}
-
배열 메모리를 초기화시킬 때는 배열 개수를 지정해서는 안된다.
-
배열을 초기화시키는 값의 개수 만큼 메모리가 만들어진다.
-
즉 다음은 값 개수만큼 int 메모리가 3개가 생성된다.
ex) int[] arr = new int[]{10, 20, 30};
-
다음과 같이 new 명령을 생략할 수 있다.
데이터타입[] 변수명 = {값, 값, 값};
ex) int[] arr = {10, 20, 30};
2) 배열 선언 후 따로 배열 초기화 문장 실행
-
-
형태 :
데이터타입[] 변수명;
변수명 = new 데이터타입[]{값, 값, 값};ex)
int[] arr1;
arr1 = new int[]{10, 20, 30}; -
변수를 선언한 후 따로 배열을 초기화시킬 때는 new 명령을 생략할 수 없다.
