본 연구에서는 능동 검색 증강 생성에 대한 일반화된 관점, 생성 과정 전반에 걸쳐 언제, 무엇을 검색할지 적극적으로 결정하는 방법을 제공
Abstract
Forward-Looking Active REtrieval(FLARE): 다음에 나올 문장을 반복적으로 예측 및 해당 문장을 query로 활용한다. 해당 query는 document와 relevant를 측정 후 retrieve시키는 용도로 사용된다. 만약에 sentence가 low-confidence tokens을 포함한다면 다시 생성하도록 한다.
해당방식의 evaluation은 long-form knowledge-intensive generation task/dataset으로 검증을 진행했다.
저자들은 long-form knowledge-intensive generation task를 수행할 때 사람들과 유사하게 점진적으로 정보를 모아서 정보를 생성한다고 한다. ‘’long-form generation with LMs would require gathering multiple pieces of knowledge throughout the generation process.”
과거에 multiple times 생성을통한 시도들은 passively 하게 과거 context를 사용하고 정보를 검색 후에 고친다는 단점이 존재한다. 이는 언어모델이 정확한 생성에 필요한 intend를 반영하지 않는다는 단점이 존재한다. 또한 몇몇 논문에서는 multihop QA를 decompose를 통한 sub-question을 만들고 retrieve시키는 시도 또한 존재한다.
본 저자는 “actively decides when and what to retrieve” 할 수 있는 언어모델을 만들려는 시도를함.
RAG
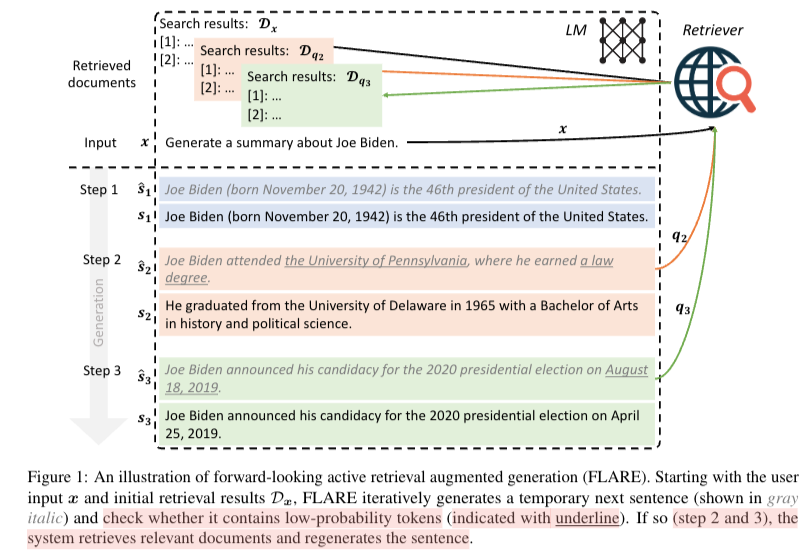
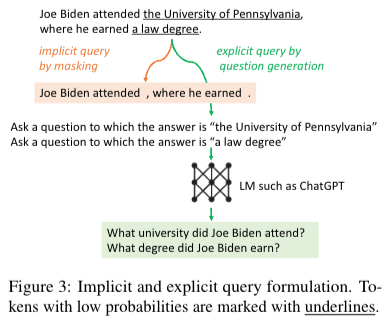
모델이 생성 중간에 나온 정보를 바탕으로 confidence가 낮을 시 retriever을 통해 docs를 새로 받아온 후 생성하도록 한다. 생성된 문장 까지와 question(input), docs를 model input으로 다시 넣어준다. 또한 본 저자는 sentence가 의미적 unit이 되기 때문에 문장단위로 끊어서 사용했다고 한다. 본 저자는 2개의 방식을 제안했다 1. FLARE{instruct}, 2. FLARE{directy} 2번의 방식은 query를 만들 때 아래의 그림과 같이 재작성을 통해서 retrieve.
Experiment

Previous-window: 이 방식은 query를 window size로 전행 이전 window로부터 생성된 토큰을 query로 사용한다. →
Previous-sentence: 해당 방식은 모든 문장을 retrieval시키는 방식으로 이전 문장들이 모두 query로 사용된다. → 성능에 매우 안좋음
Qestion decomposition: sub-qestions로 만들어서 output을 생산하는 방식 → (self-ask 논문에서 사용함)
본 논문에서 해당 방식들의 단점으로 1) 이전 생성된 토큰들을 쿼리로 사용해 LMs의 intend를 반영하지 못함. 2) 부정확한 points를 잡아 비효율적일 수 있다. 3) decomposition 의 경우 task-specific한 prompt engineering이 필요한다. 라고 설명했다.

