한줄요약: sequential 한 강화학습에서 casual transformer 모델을 적용함
요약: 기존 강화학습에서 transformer 적용하기 힘들다는 점이 있었다. 이를 r, s, a 순서로 tranformer에 주입하고 동시에 들어간 timestep에 같은 PE를 부여하면서 action을 예측하도록 학습을 진행 이때 사용하는 방식이 imitation learning을 사용 (정답을 바로 주고 action을 학습하도록) 기존 강화학습에서는 보상을 최대화하는 방식으로 action을 학습시키다 보니 transformer 적용이 힘들엇다.
문제: 기존 강화학습에서 transformer 적용하기 힘들다는 점
해결: imitation learning + PE, action prediction
novelty:
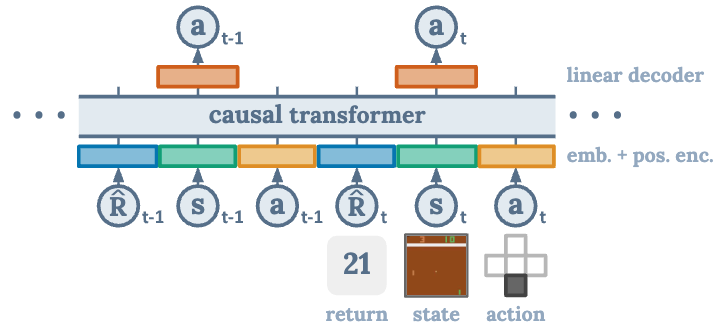
RL의 계속적인 문제는 conditional sequence modeling을 해야한다는 것이다.
이전 방식들은 value function을 학습시키고 policy gradient를 적용시켰지만 해당 방식에서는 Decision transforemr에서 causally masked transofrmer를 사용해 해당 문제를 해결하고자 시도.
Introduction
data. collective 한 후 학습시킴(sampling) 장점 → bootstrapping 안함
deadly triad: credit assignment로 인해 단기에 잘못된 행동을 선택하게되는 문제 → 매우 불안적적 요소로 작용
모델 파라미터를 크게 함으로써 안정적 학습 가능할 것으로 기대
error propagation: value overestimation: 초기에 잘못된 action으로 인해 subsequent decision에 영향을 미치게 되는 것
value overestimatioion: 특정 state와 action에 과적합되는 현상
Method
기존 트랜스포머와는 다르게 s,a,r 에 같은 position embedding을 준다.
action을 예측하게 해서 MSE loss를 흘려준다.
limitation: state, return은 예측방식 찾지 못했다고 한다.

해당 방식에서 env 로 부터 나오는 action을 바탕으로 loss 흘려줌 (imitation learning)
