June 29, 2022
https://arxiv.org/abs/2206.14176
빠른속도로 학습이 가능, world model과 intricate challenges
60분만에 로봇이 world에서 물리적으로 걸을 수 있게 되었다.
straightforward Online Reinforcement Learning pipeline 덕분에 빠른 학습이 가능하다.
enhanced synergy between its supervised learning-based world model and neural network policy
학습과정에서 낮은 지연시간으로 actions을 효과적으로 학습시킨다.
world model learning
world model은 환경다이나믹스를 예측하는 것을 학습한다.
DayDreamer는 simulator를 사용해서 빠른 학습, world model 에 대해 neural network 사용. 로봇이 자신의 고유 environment simulator를 만들도록 한다.
world model
- encoder network: encoder는 이전 s 와 a를 받고 현재 visual frame을 바탕으로 현재 s를 만들어낸다.
- decoder network: decoder는 t의 상태값을 받아 visual frame을 approx 하는 x를 만들어낸다.
- dynamics network: dynamics 는 이전 s와a를 받아 다음 s를 만들어내는 네트워크
- reward network: reward는 얼마나 다음 스테이트를 예측을 잘 했는지를 바탕으로 보상값을 준다.
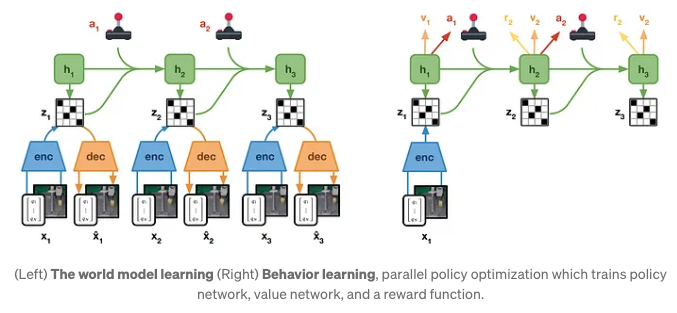
이 월드모델은 sensor데이트에서 오는 compact representation과 센서로부터 representation의 변화를 기다리는 dynamics network로 구성되어 있다. 추가적으로 reward 는 특성 작업을 수행하기 위한 상태의 가치를 측정하기 위해 사용된다.Actor-Critic Learning
world model은 AC 알고리즘의 control 전략을 습득하기위해 활용된다. 월드모델 덕분에 control space에서 다양한 행동들을 동시에 탐험해볼 수 있다.
이는 기존에 한번의 행동만 해볼 수 있던 hardware 로봇들과는 확연하게 다른 방식이다.
- actor network: prob disdt를 얻기 위한 것, 각 latent model state에서 효율적인 action을 포함한다. → 미래 테스크에 대해서 cumulative predicted reward를 최대화 하기위한 action을 뽑는다.
- critic network: critic은 reward를 예측하기 위한 모델로 사용한다. (TD 사용)
이러한 방식으로 simulated environment와 비슷한 접근이 가능해진다.
conclusion: hardware 상에서 학습시켜야할 때 새로운 패러다임을 도입함.
