span : 한 개 이상의 단어로 이뤄진 명사구가 될 가능성이 있는 단어들의 집합
mention : 상호참조해결의 대상이 되는 모든 명사구
head : mention에서 해당 구의 실질적인 의미를 나타내는 단어이며 중심어라고 불림
antecedent : 선행사
coreference : 임의의 개체(entity)를 표현하는 다양한 명사구(멘션)들을 찾아 연결해주는 자연어처리 문제. 우리는 별명, 약어, 대명사, 한정사구 등을 이용해 하나의 개체를 다양하게 표현한다. 그리고 이들 간의 참조 관계를 올바르게 찾아낼 수 있으면 담화나 문서 내에서 언급하는 대상에 대한 정보를 일관성 있게 유지할 수 있고, 정확하게 전달할 수 있다. 따라서 상호참조해결은 문서에서 등장하는 개체를 이해하는데 매우 중요한 역할을 하며, 질의 응답, 문서요약, 기계 번역, 정보 추출 등에 응용될 수 있다. Task의 복잡도가 높은 만큼 최근 딥러닝을 활용해 이 문제를 해결하려는 시도가 많아지고 있다.
cataphora : 그 뒤에 무언가에 의존하는 종속 용어
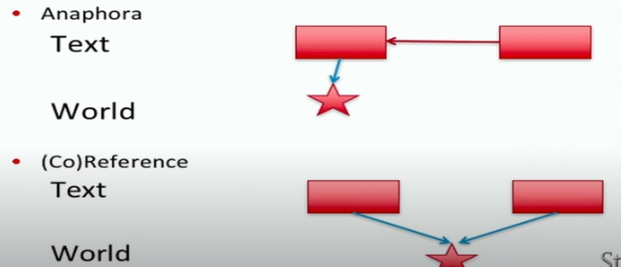
anaphora : 언어학에서 아나포는 문맥의 다른 표현에 따라 해석이 달라지는 표현의 사용
- 이전에 언급된 단어나 구를 가리키는 것을 anaphora 이라고 부르는 반면, cataphora는 이전에 나올 것이라는 것을 미리 알려주는 말
- “Before he could go to the party, John had to finish his homework"에서 "Before"라는 단어는 "he"와 "John"이 나오기 전에 나오면서 이후에 나올 인물에 대한 정보를 제공합니다. 이 경우 "Before"는 cataphoric이며, "he"와 "John"은 anaphoric
bridging anaphora :

기본적으로 세계의 일부 엔티티를 나타내는 명사구가 되도록 하는 것 → 문장에서 모든 명사구를 찾음
같은 명사구 끼리 구분 ( 공동참조 라고 표현), → 공동 참조 해결 작업임 이게
어떤 소설에서 이름과 같은 고유명사를 찾은 후 → 대명사찾음 그러고 → 일반적이 장소, 사물등의 명사를 찾음 (보통 명사구)
이러한 coreference 된 명사구를 찾는 작업은 매우 귀찮은 작업이고 힘든 작업이다.
-
purning
purning : 모델 학습 시 중요한 파라미터는 살리고 그렇지 않은 파라미터는 덜어내는(가지치기)하는 경량화 테크닉
-
장점 :
- 추론 속도가 빨라진다 (parameter 줄어듬)
- regularization 이 일반화 성능을 높인다 → 모델 복잡도를 줄인다.
-
단점 :
- 정보 손실이 생긴다.
- 입자도(granularity, 세밀함) → 하드웨어 가속 디자인의 효율성 영향을 미친다.
- 너무 sparse하게 만들어 버리면 하드웨어 가속 효율이 떨어진다.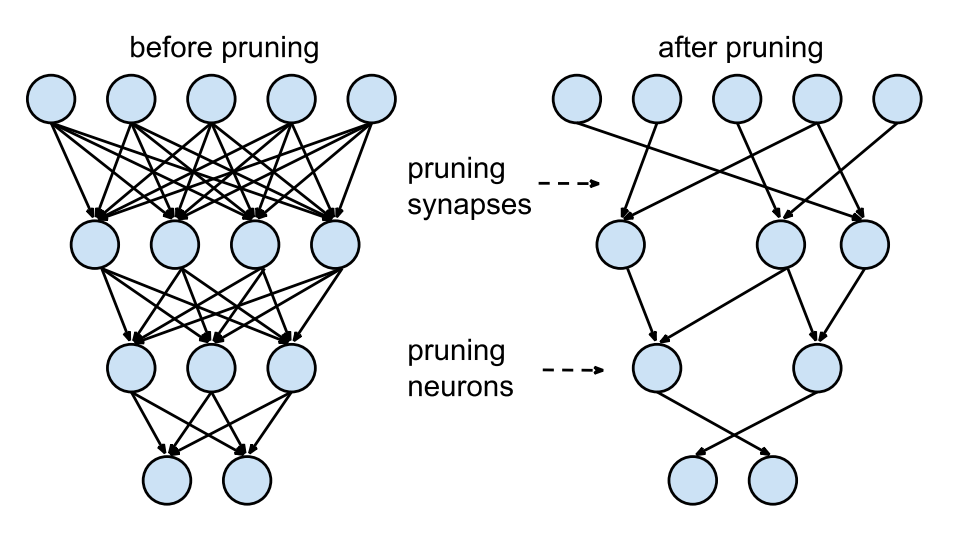
drop out 과 다른점은 ? 드롭아웃에서는 앙상블 효과가 있음, pruning은 잘라낸 뉴런을 보관하지 않음, drop out은 regularization이 목적이므로 학습시 뉴런들을 랜덤으로 껏다가 보관 → 다시 키는 과정 반복한다. → test 시 (추론시 ) 모든 뉴런을 켜고 수행
-
-
parsing, parser, Syntax Analyzer
parsing : 문장을 문법 규칙과 여러 종류의 규칙을 이용해 구조화 한 것
파싱하는 프로그램을 parser, Syntax Analyzer( 구문 분석기) 라고 함
1. Introduction
작업의 인스턴스
End-to-end Neural Coreference Resolution(Kenton Lee et al, 2017) 이전의 coreference resolution은 mention detection을 먼저 하고, 이 mention들에 대해서 clustering을 진행하는 두 가지 단계로 이루어졌다
2. Related Work
2017 논문이전
- Coreference Resolution (상호참조해결) 에서 머신러닝 기법을 사용하게 된 것을 꽤 오래됨.
- 하지만 Coreference Resolution task 가 복잡하기 때문에 수작업 시스템을 사용한 기법이 최근까지도 사용되었음.
- 이런 파서를 이용한 파리프라인 구조는 문제점이 존재
- 잘못된 파싱이 연속된 에러를 야기
- 새로운 언어에 대한 일반화 하지 못함
- Daum´e III and Marcu (2005) - mentio detection과 상호참조해결을 함께 한꺼번에 모델링 한 non-pipline system이 처음 제안 L → R coreference structure을 예측하는 검색 기반 시스템
Key idea
모든 span을 잠재적 mention으로 본다.
각 mention에 대한 가능한 선행사의 분포를 학습한다.
3. Task
- D: document, speaker와 genre에 대한 정보를 메타데이터로 가짐
- T: 문서 내 단어 갯수
- N: T(T+1)/2, 문서 내 가능한 span 갯수
- i 번째 span의 시작단어인 START(i)에 근거하여 span의 순서를 정한다.
- 동일한 START(i)를 가진 span은 END(i)에 의해 순서가 정해지게 된다.
- ϵ: dummy antecedent → 더미 선행사
- 더미 선행사가 가능한 두 가지 시나리오는 :
- 1) span i 는 entity mention이 아니다.
- 2) span i는 entity mention 이지만 선행사가 없다.

- span i 의 TRUE 선행사 span j (i ≤ j ≤ i-1) 는 i와 j사이의 coreference링크를 나타낸다.
- 각 span i 에는 선행사 y_i가 할당된다. y_i에 대해 가능한 선행사 집합 = Y(i)={ϵ, 1, …, i -1}

이러한 방식으로 일련의 선행사를 예측하고 연결된 모든 범위를 그룹화하여 최종 군집을 수행
4. Model
Mention Ranking 모듈
Mention Ranking 모듈은 Mention Pair 모듈의 출력을 기반으로, 각 언급(span)이 대상 개체(target entity)의 첫 번째 언급인지 여부를 예측합니다. 이를 위해, Mention Ranking 모듈은 다음과 같은 두 가지 단계를 거칩니다.
- Candidate Representation : 대상 개체(target entity)의 첫 번째 언급과 다른 모든 언급(span)의 특징(feature)을 결합하여 해당 언급(span)이 대상 개체(target entity)의 첫 번째 언급인지 여부를 예측하기 위한 특징을 생성합니다.
- Candidate Score : Candidate Representation을 입력으로 받아 해당 언급(span)이 대상 개체(target entity)의 첫 번째 언급인지 여부를 나타내는 점수(score)를 출력합니다. 이를 위해, 이진 분류기(binary classifier)를 사용하여 해당 언급(span)이 대상 개체(target entity)의 첫 번째 언급인 경우 1을, 그렇지 않은 경우 0을 출력합니다.→ span purning(모델의 정확도를 유지하면서도 계산 비용을 크게 줄일 수 있음)
Mention Pair 모듈
입력 문장에서 나타난 모든 언급(span) 쌍(pair)을 고려하여 각 쌍이 지시하는 두 개의 개체가 동일한지 여부를 예측
- Pair Representation : 두 개의 언급(span)의 특징(feature)을 결합하여 해당 쌍(pair)의 특징을 생성합니다. 이 과정에서, 두 언급(span)의 차이(difference)를 계산하여 해당 쌍(pair)을 설명하는 추가적인 정보를 제공합니다.
- Pair Score : Pair Representation을 입력으로 받아 해당 쌍(pair)이 지시하는 개체가 동일한지 여부를 나타내는 점수(score)를 출력합니다. 이를 위해, 이진 분류기(binary classifier)를 사용하여 해당 쌍(pair)이 지시하는 개체가 동일한 경우 1을, 다른 경우 0을 출력합니다.
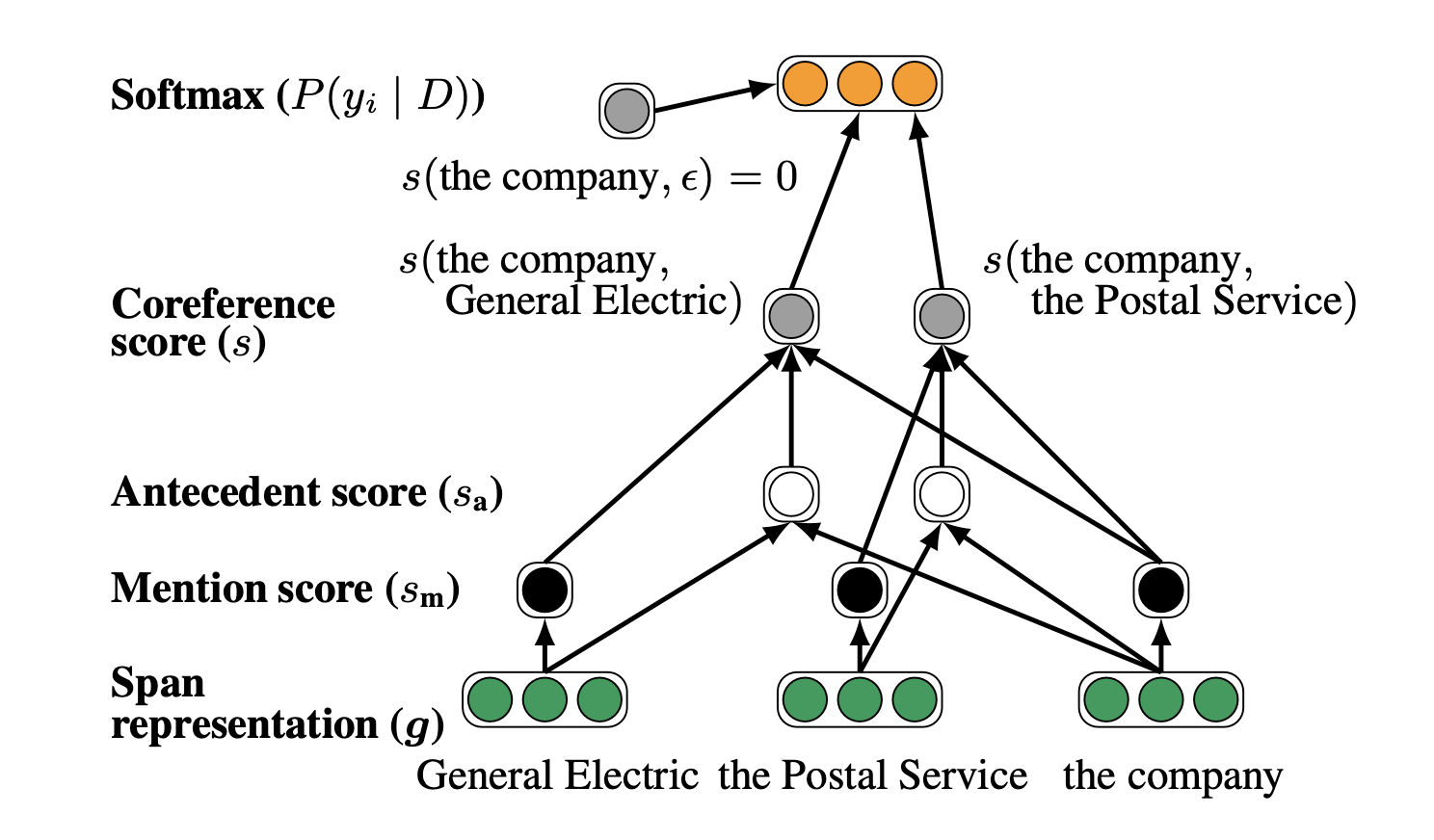
Mention Pair 모듈과 Mention Ranking 모듈을 결합하여 End-to-end Neural Coreference Resolution 시스템을 완성합니다. 이 시스템은 입력 문장에서 언급(span) 간의 상호 참조 관계를 모델링하며, 이를 통해 문장에서 언급(span) 간의 개체(coreference)를 해결합니다.
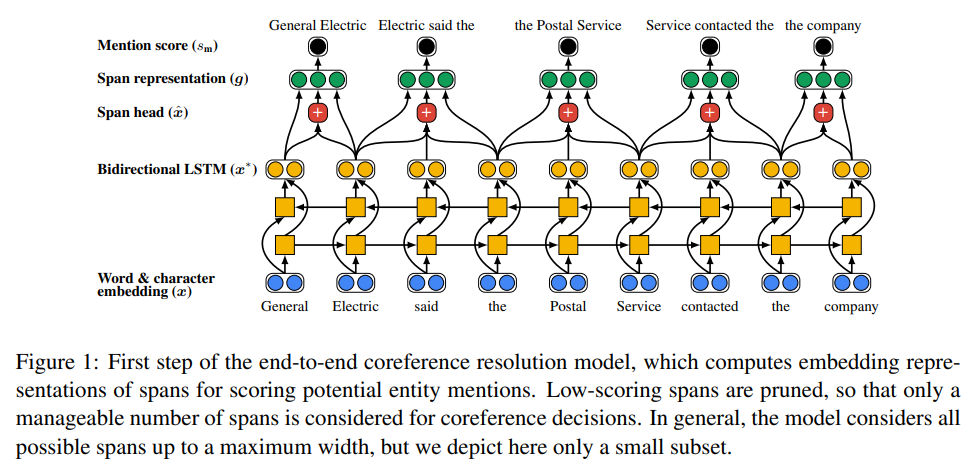
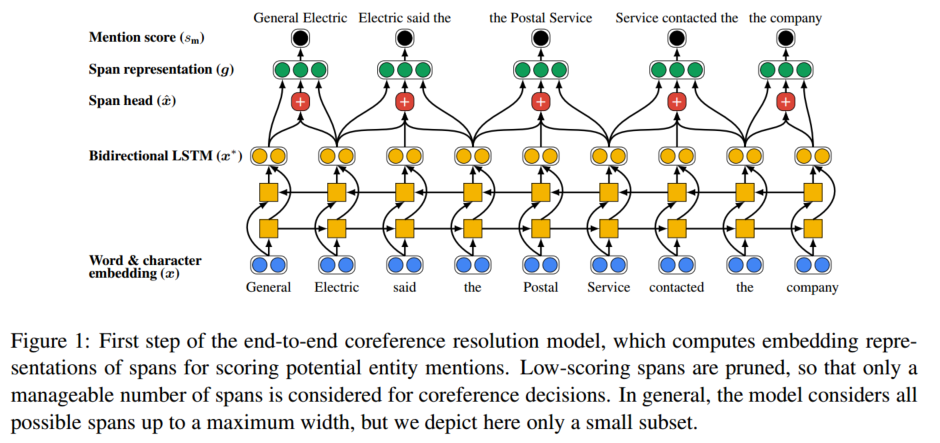
- span embedding representation을 계산한다. 이는 bidirectional LSTM을 이용한다.
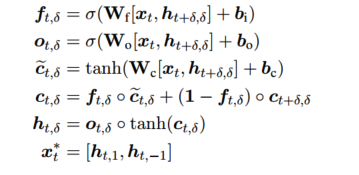
- span 내의 단어들의 attention을 이용하여 span head를 구한다. - activation : ReLU
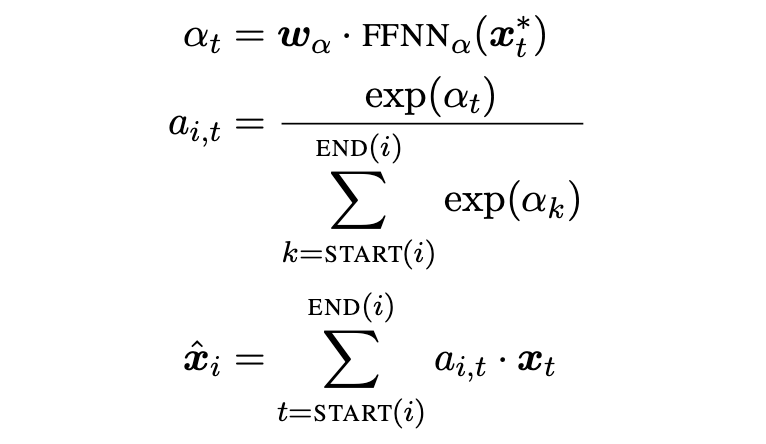
- gi는 boundary representation인 와 를 포함한다. 또한 soft head word vector xˆ_{i} 와 feature vector φ(i) 를 span i의 사이즈로 임베딩한 값(start와 end 간의 차이벡터)도 포함한다.
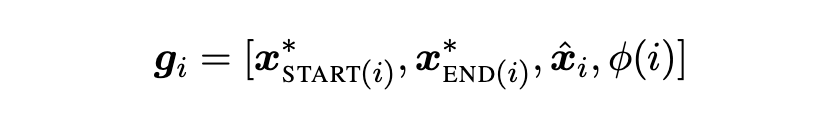
- 아래의 식을 이용해 mention score()를 계산진행. m은 주어진 Mention을, c는 주어진 문맥(Contex)을 나타냅니다. 는 주어진 Mention과 문맥으로부터 추출된 특징 벡터(feature vector)
- 이 score가 낮은 span에 대한 프루닝을 진행한다. (top λ*N을 이용하는데, 여기서 람다는 하이퍼 파라미터이다.) (- ReLU사용… 해당논문에서는 사용하지 않았는데 다른곳에서는 비선형성을 높여주기위해 넣기도 한다고 함)
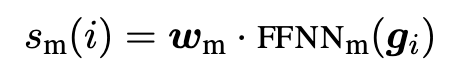
- number of pairwise computations을 줄이기 위해 mention score가 충분히 높은 span들만을 coreference decision 단계에서 이용한다.
- span들의 pair들을 이용하여 antecedent score를 계산한다. - ReLU 사용
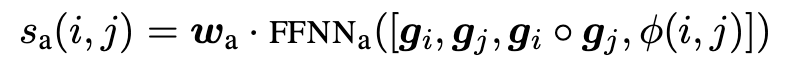
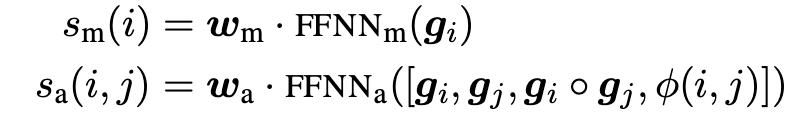
- Span Ranking Model : pair가 되는 각 span의 mention score들과 pairwise antecedent score를 종합하여 coreference score를 계산한다. 그리고 이를 maximize하도록 학습(marginal log-likelihood)한다.
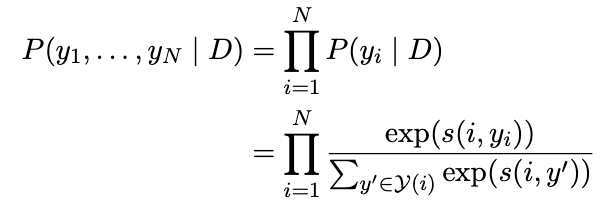

하이퍼 파라미터 :
- 300-dimensional GloVe embeddings(Pennington et al., 2014) ,50-dimensional embeddings from Turian et al. (2010) → normalized to be unit vectors
- character CNN, characters are represented as learned 8-dimensional embeddings
- The convolutions have window sizes of 3, 4, and 5 characters, each consisting of 50 filters.
- The hidden states in the LSTMs have 200 dimensions.
- Each feed- forward neural network consists of two hidden layers with 150 dimensions
- Pruning - L = 10, λ = 0.4, K = 250 ( K : Maximize number of antecedents, ) During training, documents are randomly truncated to up to 50 sentences.
- The learning rate is decayed by 0.1% every 100 steps, ADAM, 0.5 dropout to the word embeddings and character CNN outputs, 0.2 dropout to all hidden layers and feature embeddings
- Ensembling - ensemble experiments using five models trained with different random initializations.
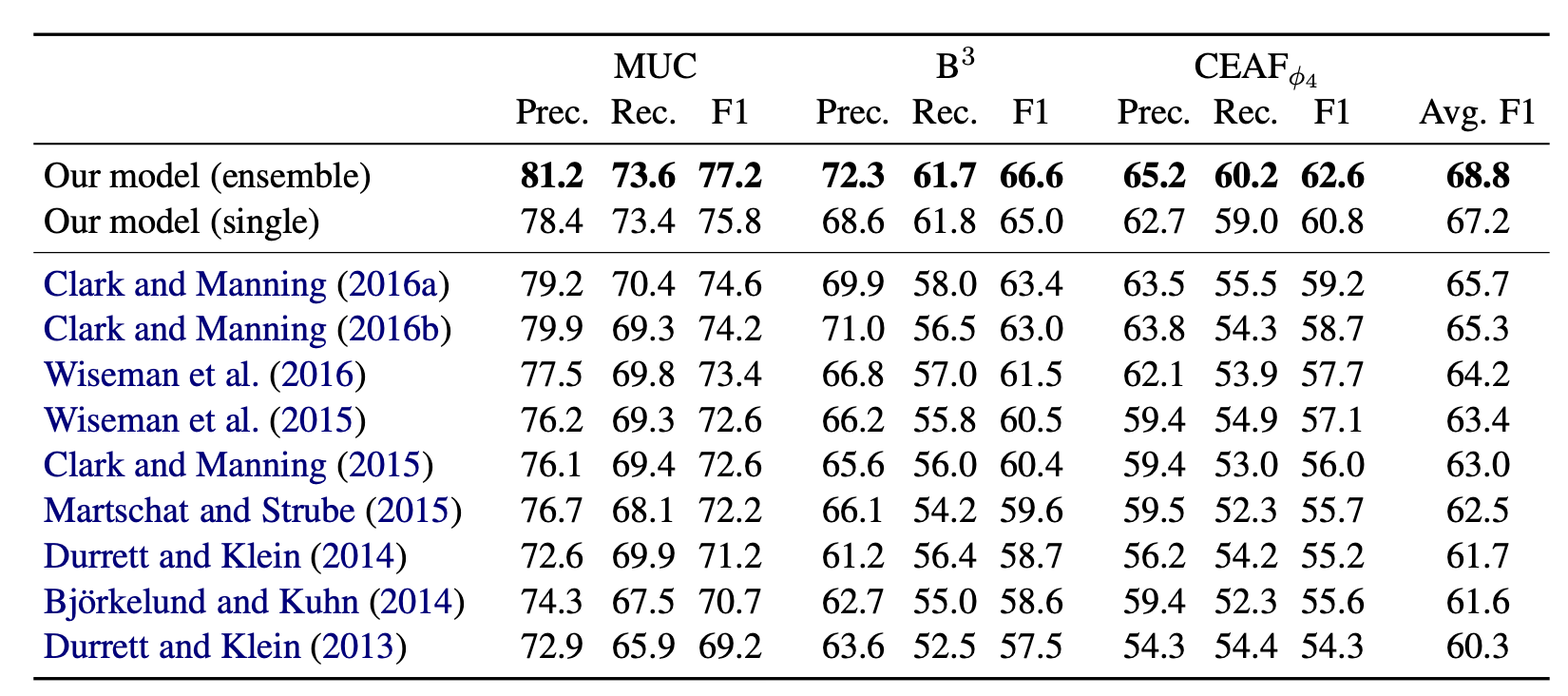
Result