Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
논문리뷰
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
전통적 지도학습은 input x → output , 학습이 진행된다. prompt based 학습은 텍스트의 직접확률 언어모델을 베이스로 한다. prompt task를 위해서는 input x 를 를 사용해 안채워진 으로 바꿔주어야 한다. 그리고 언어모델은 최종 을 얻기위해 확률적으로 안채워진 정보를 채우는데 사용된다. 이 는 최종 결과 y를 가져온다.
초록
이러한 새로운 프롬프팅 function을 정의하면서 모델은 few or no label data에 대해 few-shot or zero-shot learning을 할 수 있다.
→ 이 글은 prompt 유망한 기술을 소개하고 pre-trained language models, prompts, and tuning strategies 에 대해서 말한다.
prompting engineering :
쇼셜미디어 감정분류 : I felt so, “English: I missed the bus today. French: ” 이런식으로 blank를 통해 기계가 우리가 원하는 결과 값을 순식간에 얻을 수 있게 돕는다.
A Systematic Survey of Prompting Methods in Natural Language Processing
1. TWO SEA CHANGES IN NATURAL LANGUAGE PROCESSING
일반적으로 대부분의 기계학습 부분에서 지도학습이 주류를 이뤘다. 이전 NLP task 는 대부분 엔지니어링에 초점이 있었다면 2017~2019에는 큰 변화가 많이 생겼고 현재는 supervised paradigm이 점차 줄어들고 있다. 그러면서 paradigm이 pre-train 과 fine-tune pardigm으로 변화하였다.
Within this paradigm, the focus turned mainly to objective engineering, designing the training objectives used at both the pre-training and fine-tuning stages
즉 현재의 관점은 목적에 따라 재 구성하고, prompt의 사용과 함께 downstream tasks 를 수행한다.

2. Formal description of prompting
2.1 supervised Learing in NLP
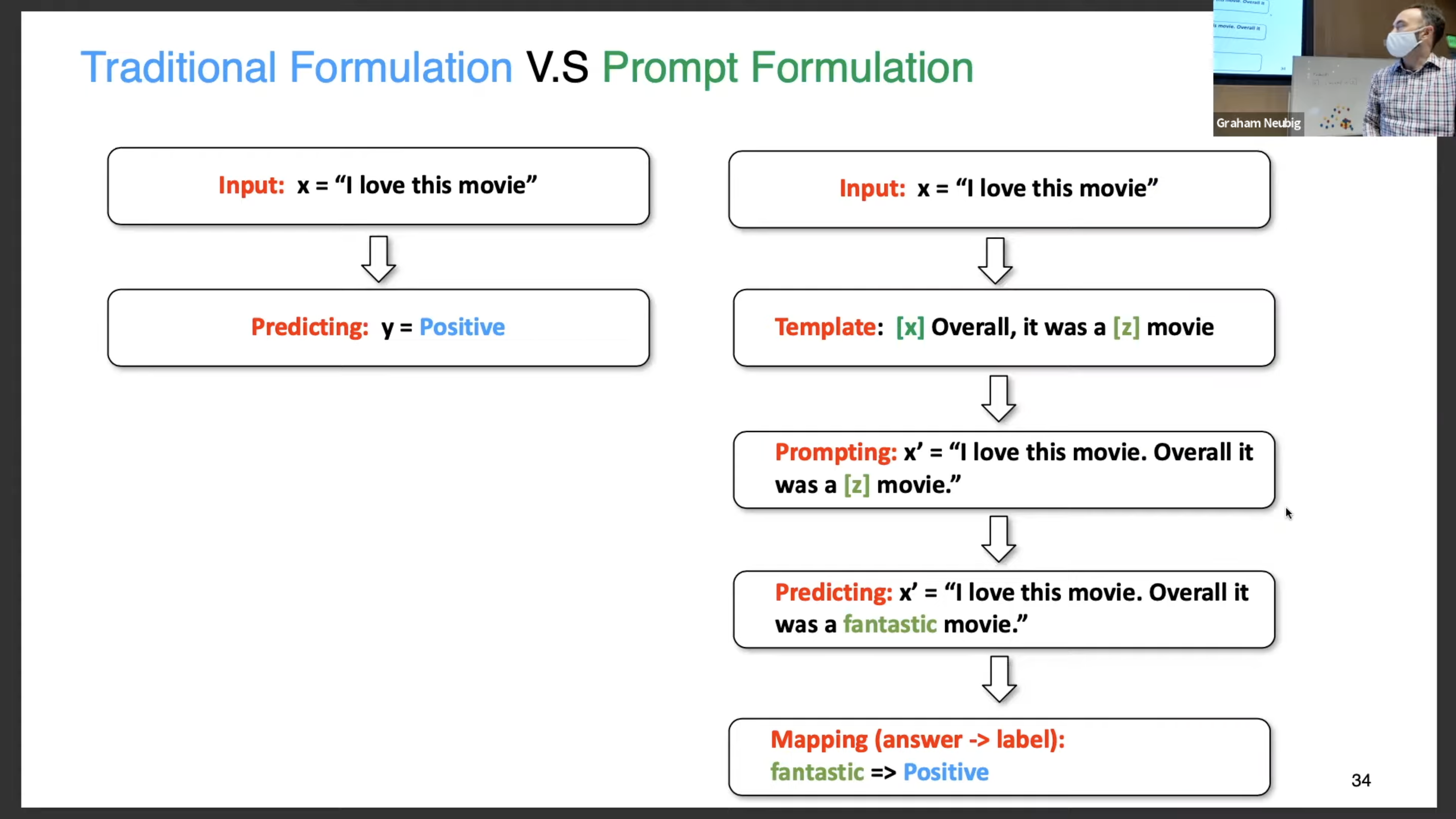
- 전통지도학습 : input x → output , , predict output y based on model
- input text를 구분하기위해 label y가 필요하고 이를 통해 감정분류 및 번역등의 tasks를 진행한다.
2.2 Prompting Basics
-
일반적으로 basic prompting predicts the hightest-scoring
-
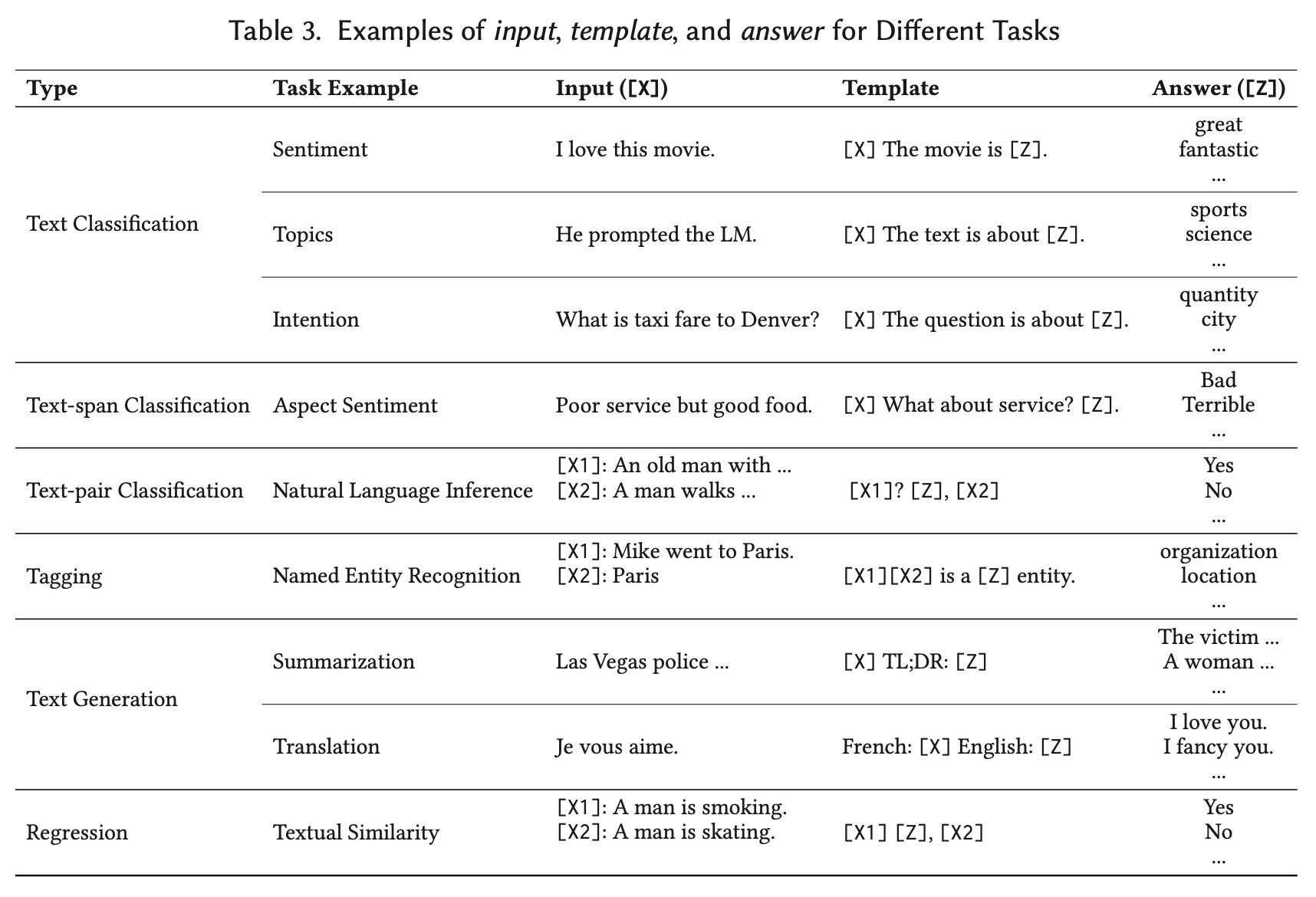
2.2.1 Prompt Addition : In this step a prompting function (·) is applied to modify the input text x into a prompt =
-
라는 string 타입의 2가지 슬롯을 넣는 곳이 있고 하나는 (input slot) → (answer slot) answer slot 에서 나온 것은 예측값인 y에 귀결 → x 대입
-
ex) translation : “Finnish: [X] English: [Z],”
-
ex) sentiment analysis : “[X] Overall, it was a [Z] movie.”
-
텍스트 중간에 오는 것을 : cloze prompt, input text 가 z 전에 오는 것을 : prefix prompt
-
Prefix prompt는 사용자가 질문에 대한 답변을 이어서 작성하는 방식이고, Cloze prompt는 주어진 문장이나 문서에서 빈칸을 채우는 방식
-
x 와 z 슬롯의 수는 task에 따라 달라질 수 있다. → input 과 output 의 수는 자유롭다
-
-
2.2.2 Answer Search - 프롬프트를 hand-crafted 하는 것이 아닌 자동적으로 찾기 위한 방식이다. discrete space 와 continuous space 두가지가 있다.
-
를 z의 허용가능한 값의 집합으로 정의
-
ex) = {“excellent”, “good”, “OK”, “bad”, “horrible”} to represent each of the classes in = {++, +, ~, -, --}. ,, 를 위의 표에서 answer 이라고 생각해주면 된다.
-
function 함수에서 [Z]의 위에 채워진 프롬포트의 answer 이 z이다.
-
-
2.2.3 Answer Mapping.
- 번역이나 몇몇 경우에서는 answer 와 output 이 같을 수 있다. 하지만 감정분류 등 represent 가 {++,+,~,-,--} 와 같이 나오는 경우에 answer 과 output 을 매핑시킬 필요가 있다.
-
2.3 Design Considerations for Prompting
- 프롬프트 과정 공식화
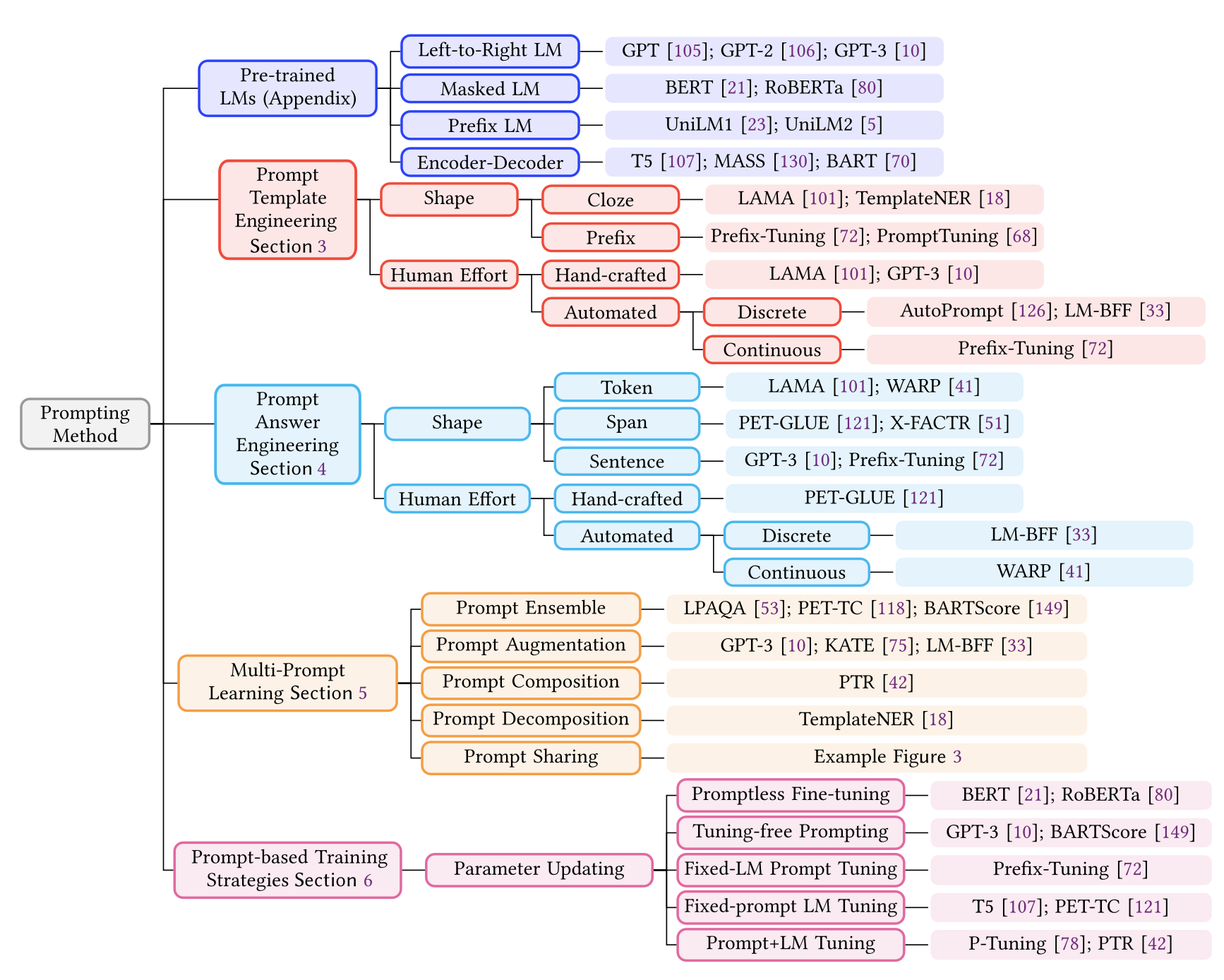
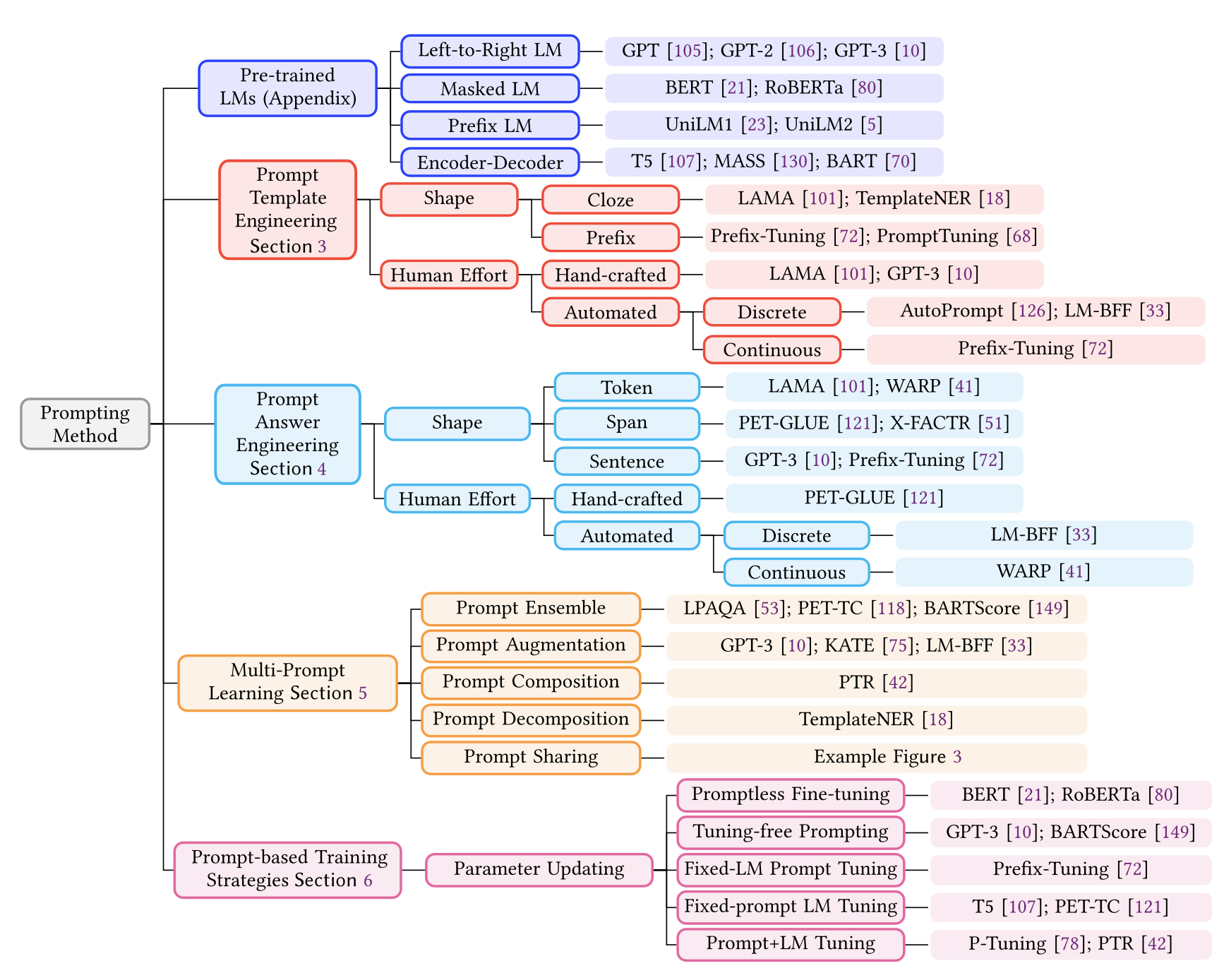
- Pre-trained LM Choice → Prompt Template Engineering → Prompt Answer Engineering → Expanding the Paradigm → Prompt-based Training Strategies
3. PROMPT TEMPLATE ENGINEERING
function 를 만드는 과정 → downstream task 성능 향상에 효과적이다.
가장 먼저 prompt shape 을 고민해봐야 하고 이게 manual or automated 접근으로 할지 결정해야한다.
3.1 Prompt shape
대표적으로 cloze prompt 와 prefix prompt 두가지의 형태가 있다.
prefix prompt : 생성모델과 자기회귀 LM 에서 주로 사용된다.
cloze prompt : 마스킹 LM 에 주로 사용 도니다. 그리고 input 이 여러개일 때는 template 가 반드시 인풋 갯수에 맞춰서 들어가 줘야한다.
3.2 Manual Template Engineering
직관에 따라 프롬프트를 만드는 것, 메뉴얼적으로 각 분야에 따라 cloze와 prefix를 사용해 pre-defined template를 사용한다.
3.3 Automated Template Learning
Manual 방식은 복잡한 의미구문분석의 경우 시간과 경험이 필요로 한다. → prompt 디자이너도 수동으로 발견하지 못할 수 있다. → 이 문제를 해결하기위해 automate the template design process가 제안되어 왔다.
- discrete prompt : 실제 텍스트에서 실행하는 프롬프트
- continuous prompt : LM 의 embedding공간에서 실행하는 프롬프트
3.3.1 Discrete Prompts. - (a.k.a hard prompts)
- D1 : Prompt Mining : 기본적으로 입력및 출력 세트가 주어진 프롬프트가 존재, 우리가 a를 추출할 수 있거나, 입력 출력 학습 세트간에서 중간단어 or 종속적인 관계를 찾아내는 것
- Middle-word Prompts : [X] middle words [Z].
- Dependency-based Prompts : 문장의 구문 분석을 기반으로 한 관계를 나타내는 template 추출 subject 와 object 사이의 dependency path를 찾은 다음 dependency path를 바탕으로 pharse를 프롬프트로 사용

- D2 : Prompt Paraphrasing : 순환번역(back-translation), 동의어 사전등을 사용해 기존에 작성된 prompt를 의미상 유사하거나 동일한 표현으로 바꿔씀 e.g. “x shares a boarder with y” → “x has a common border with y” → “x adjoins y”
- D3 : Gradient-guided Search : 각 token을 template에 사용했을 때 LM의 likelihood가 가장많이 증가하는 token을 선택한다. ,, 최적 pormpt를 탐색하는 자동화 방법론 각 label y에 대해 LM의 likelihood가 가장많이 증가하는 trigger token [T]를 탐색 token [T]를 [MASK] token으로 초기화한 뒤 해당 위치에 다른 token[T]가 들어갔을 때 label의 likelihood를 최대로 하는 token[T]를 탐색

- D4 : Prompt Generation :
- LM-BFF 방식 - T5 모델을 이용해 prompt template를 생성
- PADA 방식 - LM-BFF방식에서 domain adaptation을 추가해, 특정 domain 에 대한 prompt생성
- D5 : Pompt Scoring : 사람이 직접 장성한 template 후보에 입력 텍스트 x와 answer z를 넣어 정답이 채워진 prompt를 만들고 GPT style의 LM에 통과시켜 prompts의 score를 측정, 가장 높은 LM probability를 가지는 pormpt를 선택
3.3.2 Continuous Prompts(a.k.a. Soft Prompts)
-
prompt가 반드시 사람이 이해할 수 있는 자연어 형태일 필요는 없음
- prompt를 위한 special token(or virtual token)을 만들어 continuous space에서 최적화
- special token을 사용하면 의미를 사람이 파악하기는 어렵지만, discrete prompts 보다 일반적으로 더 나은 성능을 보이며 더 활발히 연구되는 방식

-
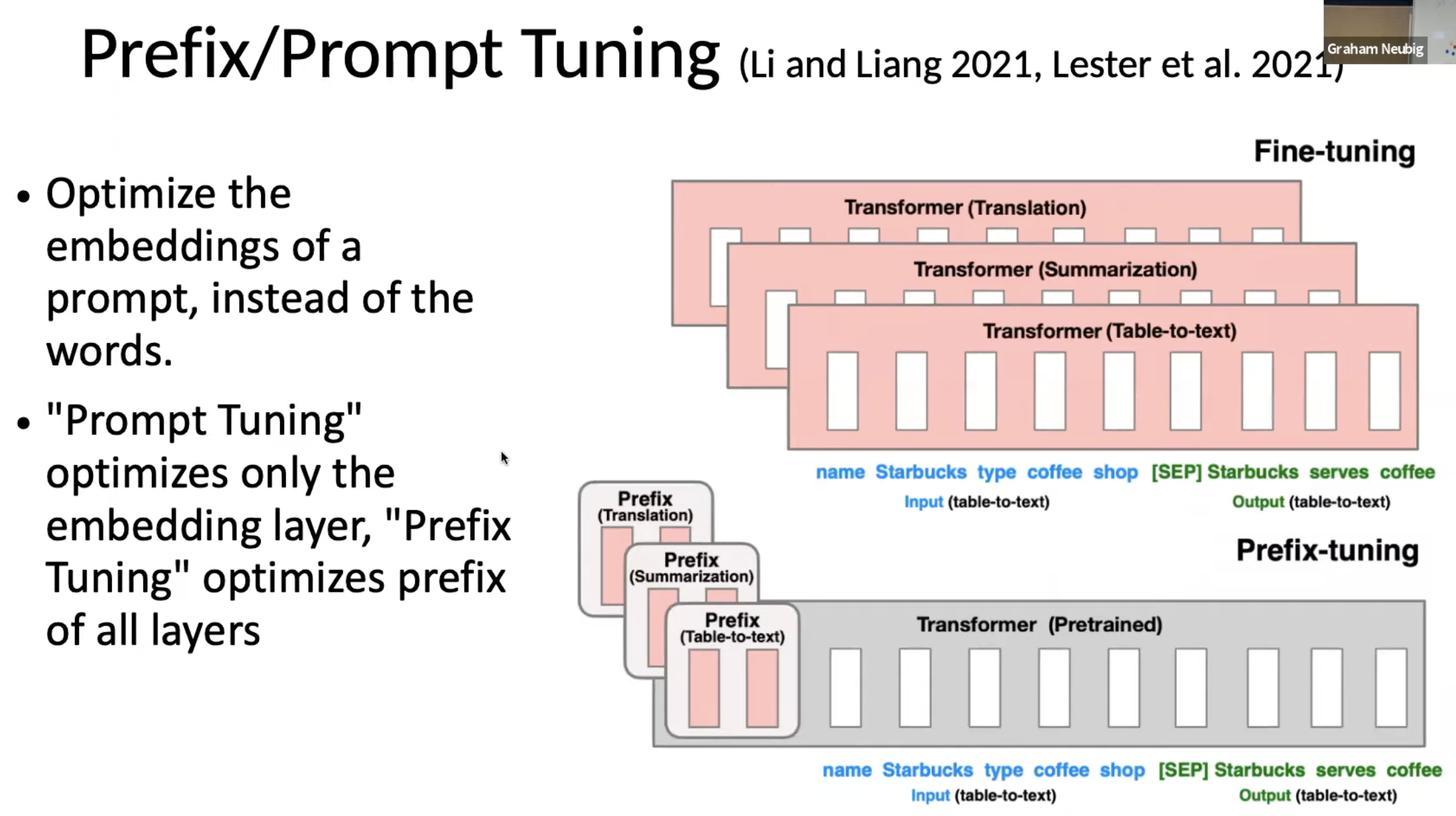
C1 : Prefix-Tuning - (Li and Liang, 2021) 가장 대표적인 방식
-
LM 고정, 각 layer의 input 앞에 task-specific vectors를 붙여 tuning
-
Task-specific parameter는 prompt token ,…, 을 입력 받아 각각의 decoder layer마다 FFN을 통과시켜 key, value로 변환 후 task-specific vectors를 출력 → input 과 cross attention 적용
-
각 Task에 대하여 parameter를 tuning 시켜 task 마다 적합한 task-specific vectors

-
prefix-tuning vs Fine-tuning
-
prefix는 각 task에 대한 task-specific vectors(Prefix)를 계산하는 parameter만을 fine-tuning 한다. → overhead 감소
-
Prefix 방식이 다른 조건보다 적은 파라미터에서 좋은 성능을 나타내는 것으로 나타남
Result - table-to-text generation task(GPT-2)
Dataset: E2E, WebNLG, DART
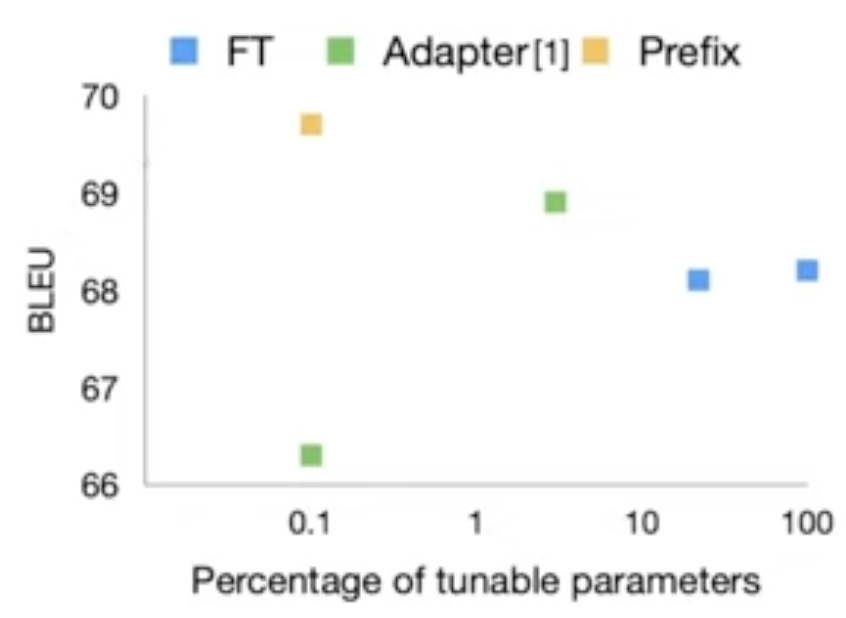
-
요약 부분에서 훨씬 적은 파라미터에서 비슷한 성능이 나오는 것을 볼 수 있음
Result - summarization(BART)
Dataset: XSUM
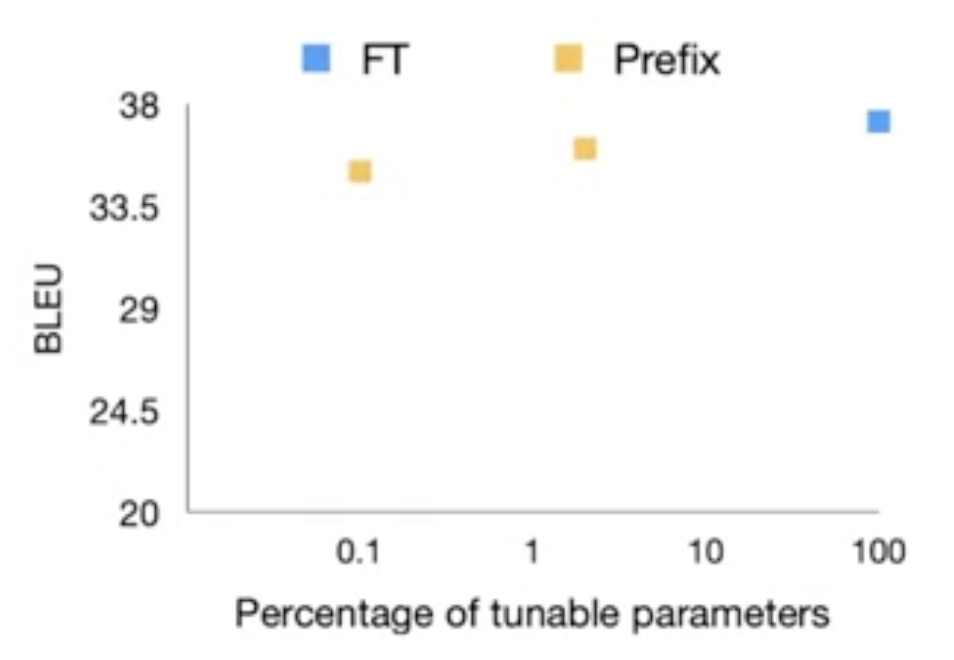
-
중요한 부분 차트
Result - Extrapolation : 모델이 학습한 범위를 벗어나는 입력에 대해 예측하는 것을 의미한다. (일반화 능력 평가하는데 중요한 역할) talbe-to-text generation task에 대해 학습하지 않았던 도메인에 대한 성능 평가 이러한 프롬프트가 학습하지 않았던 도메인에 대한 일반화에 도움이 된다는 장점이 있다는 것을 보여주는 차트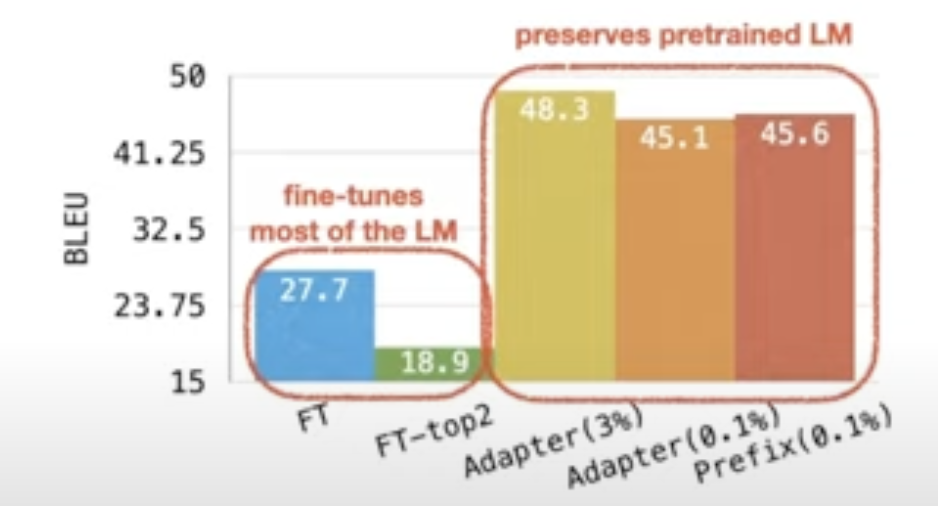
-
-
-
C2 : Tuning Initialized with Discrete Prompts : Discrete Prompts를 초기값으로 하여 Downstream task에 Tuning 빈간을 제외한 나머지 학습부분을 virtual token으로 대체함

-
OptiPrompt(Zhong et al., 2021) - LAMA benchmark에서 제공된 manual prompts의 prompt template을 이용 → 빈칸을 virtual token으로 대체 → 초기값은 원래 토큰의 embedding 값으로 설정 → virtual token의 task 정활도를 높이도록 fine-tuning(LM freezing) → 위에 차트는 BERT-base LAMA benchmark로 측정한 결과 48.6% 달성
-
Soft(Qin and Eisner, 2021) : 초기값 까지는 위와 동일, prompt에 앙상블 ㄱ시법으 ㄹ적용해 각 prompt에 가중치를 부여해 학습을 진행시킨다.

-
-
C3 : Hard-Soft Prompt Hybrid Tuning
-
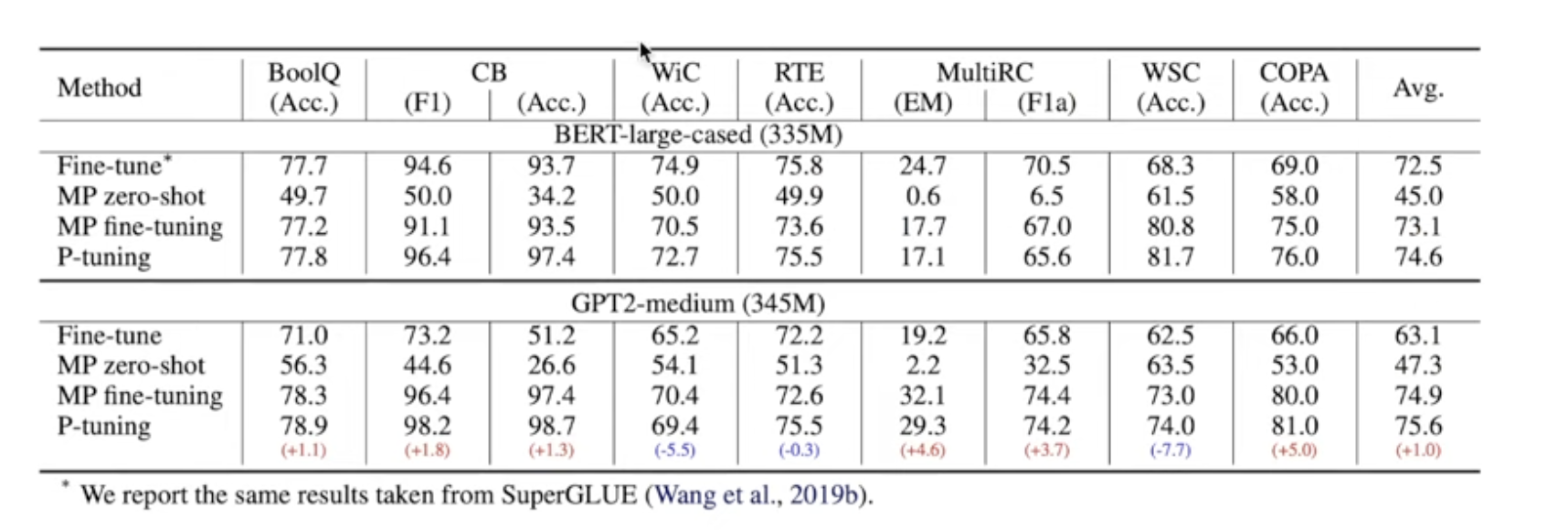
P-Tuning(Lui et al., 2021) : LM 입력부에 pormpt encoder(Bi-LSTM)을 두어 나온 출력값을 Prompt의 Token Embedding으로 사용, Task와 관련된 anchor tokens 을 추가하여 성능 개선(anchor token값은 고정)
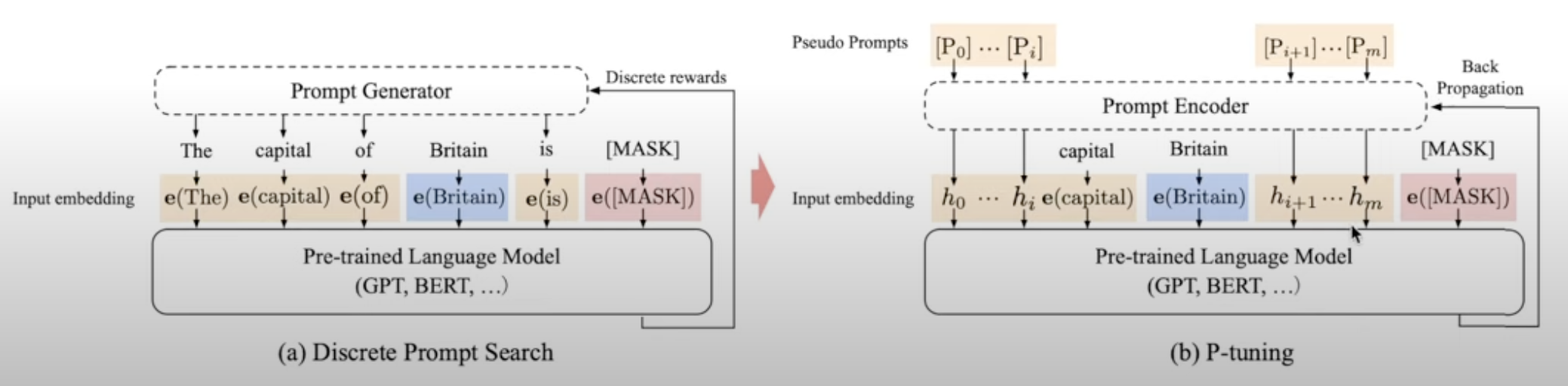
(b)에서 엥커 토큰은 고정시켰을때 성능이 더 잘 나온다고 주장
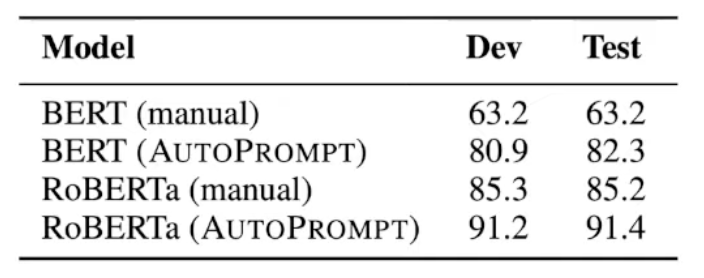
실험결과 : 일반적으로 버트가 gpt보다 좋은 성능을 가지고 있다 하지만, NLU Task에서 P-tuning을 사용했을 때 GPT style model로 BERT style model 보다 더 낫거나 비슷한 성능이 나온다.
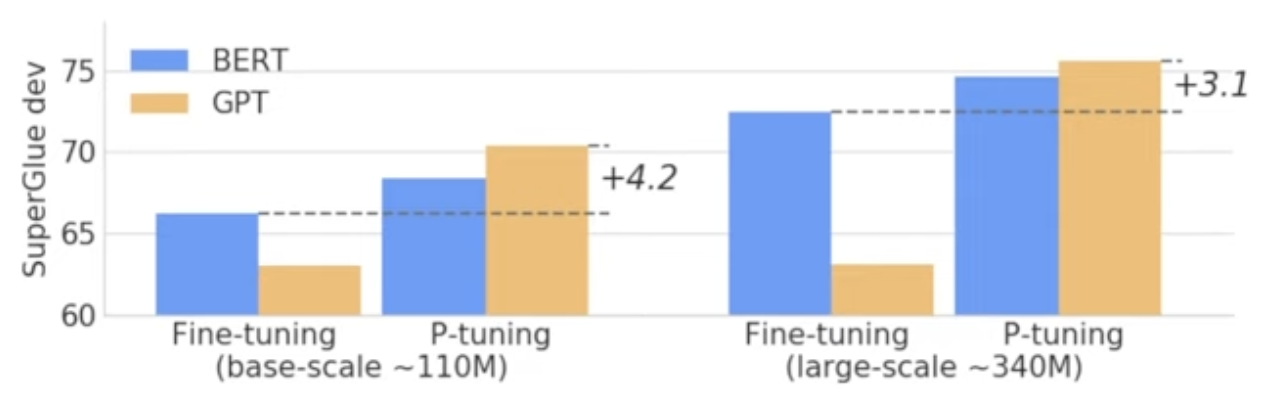
-
PTR : Prompt Tuning with Rules(Han et al., 2021) : 두 개 이상의 Manual template를 규칙 기반으로 조합해 task에 더 효과적인 template 생성
Manual template을 서로 연결하는 부분에 virtual token을 추가해 LM 과 함께 downstream task에 tuning
Relation Classification Task에 적용해 SoTA 달성
아래 그림에서 하늘색 virtual token이 위에서 말한 서로 연결하는 부분에 해당하며, 입력문장을 바탕으로 둘간의 관계를 바로 입력으로 사용하는 것이 아니라 논리적인 규칙을 활용해서 수행
Mark Twain은 어떤 특성을 가지고 있는지, Langdon는 어떤 특성을 가지고 있는지 그후에 이 둘간에는 무슨 관계가 있는지 순서로 Classification을 수행하도록 template구성함
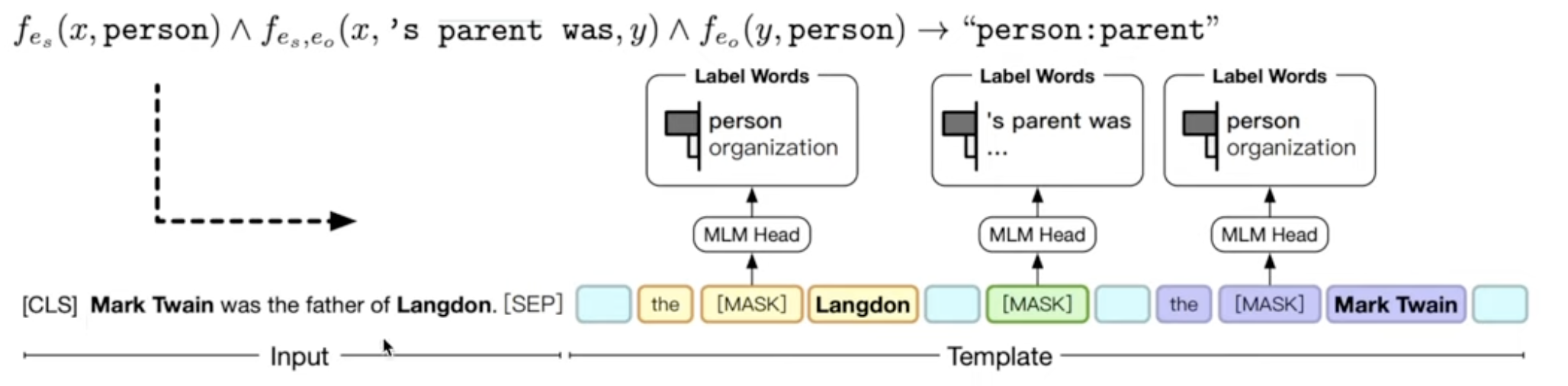
-
4. Answer Engineering
Manual Design - 사람이 직접 탐색
- 사람이 직접 answer z 와 output y의 대응 관계를 지정 Templete NER (Chi et al.,2021) Few-shot NER Task 에 Prompting method를 적용한 연구, 사람이 직접 매핑,
Automated Design
4.1.1 Discrete Answer
- Answer Paraphrasing - 동일한 의미를 갖는 다른 token을 answer space에 추가하는 방식
- Label Decomposition - Adaprompt (Chen et al., 2021)
- Relation Extraction Task에서 각각의 relation label을 구성하는 단어들을 분해, 각각을 answer token z로 취급
- e.g. per:city_of_death → {person, city, death}
- per:city_of_death의 확률 = 각 token(person, city, death)의 확률의 합
- Prune-then-Search - Answer token 후보를 추려낸 다음 → 알고리즘을 이용해 적절한 것을 선택
- PET (Pattern-prompt Exploiting Training):
-
Prune : 2개 이상의 알파벳을 포함하는 token z 중에 빈도 수가 높은 것들로 구성
-
Search : label y 에 대한 LM의 likelihood를 최대화하는 token z
Methods : Few-shot Text classification & NLI task에 Prompting 을 활용한 Semi-Supervised Learning 방법론 제안
Pompt 를 정의하는 방법을 Pattern-Verbalizer Pairs(PVPs)로 표현
서로다른 Prompt를 사용하는 모델을 ensemble
Results : Yelp, AG News, Yahoo, MNLI Benchmark에서 기존 SOTA 인 semi-supervised 방법론보다 더 나은 성능
-
- LM-BFF (Better Few-shot Fine-tuning of Language Models) : 최적의 Prompt template과 answer mapping을 탐색하는 자동화 방법론 제안
-
Prune : [Step 1] token z 가 들어갈 위치에서의 생성 확률이 가장 높은 top-k개 token 선택 [Step 2] zero-shot accuracy가 높은 것들로 구성
-
Search : LM fine-tuning 이후 dev set의 accuracy 기준으로 최종 answer token z 선택
Methods : PET와 동일한 prompt + LM fine-tuning 방식
PET가사람이 작성한 prompt와 answer mapping을 사용하는 것과 달리 T5를 이용하여 answer와 prompt를 탐색
Demonstration 선택 방법 제안 Sentence-BERT를 이용하여 임베딩값이 input과 유사한 demonstration를 선택, 각 label의 demonstration를 하나씩 선택
-
- PET (Pattern-prompt Exploiting Training):
4.1.2 Continueous Answer Answer token z도 반드시 사람이 이해할 수 있는 형태일 필요는 없음
Label에 대한 virtual token을 만들어 처음부터 학습시키거나 vocab에 포함된 token embedding으로 초기화
special token을 사용하면 의미를 사람이 파악하기는 어렵지만, discrete prompts보다 일반적으로 더 나은 성능을 보임
- WARP(Hambardzumyan et al., 2021)
- 이미지 분야에서 이밎 입력에 특수한 노이즈를 주어 Pre-trained model을 업데이트 하지 않고도 다른 기능을 수행하게 하는 Adversarial ReProgramming 기법 제안
- 이를 NLP분야에 적용하여 input에 약간의 trainable embedding을 추가해 LM 이 sentiment classification을 수행하게 함

cv분야에 이미지 입력 부분에 특수한 노이즈를 주어 이미지로 학습한 모델이 fine-tuning하지 않고 전혀 다른 기능을 수행하는 네트워크로 만드는 Adversarial ReProgramming 기법 사용
ImageNet classifer로 학습한 모델을 고정시킨 체로 왼쪽그림에 흰색 사각형의 갯수를 맞추는 실험을 진행했었는데 이때 입력이미지의 주변부에 노이즈를 주어 입력할때 classifier가 사각형 갯수를 맞추는 전혀다른 기능을 하게 하는 실험 → NLP에 적용해
입력되는 텍스트 임베딩 앞 그리고 사이사이에 training embedding을 추가해 감정분류를 진행하게 했음
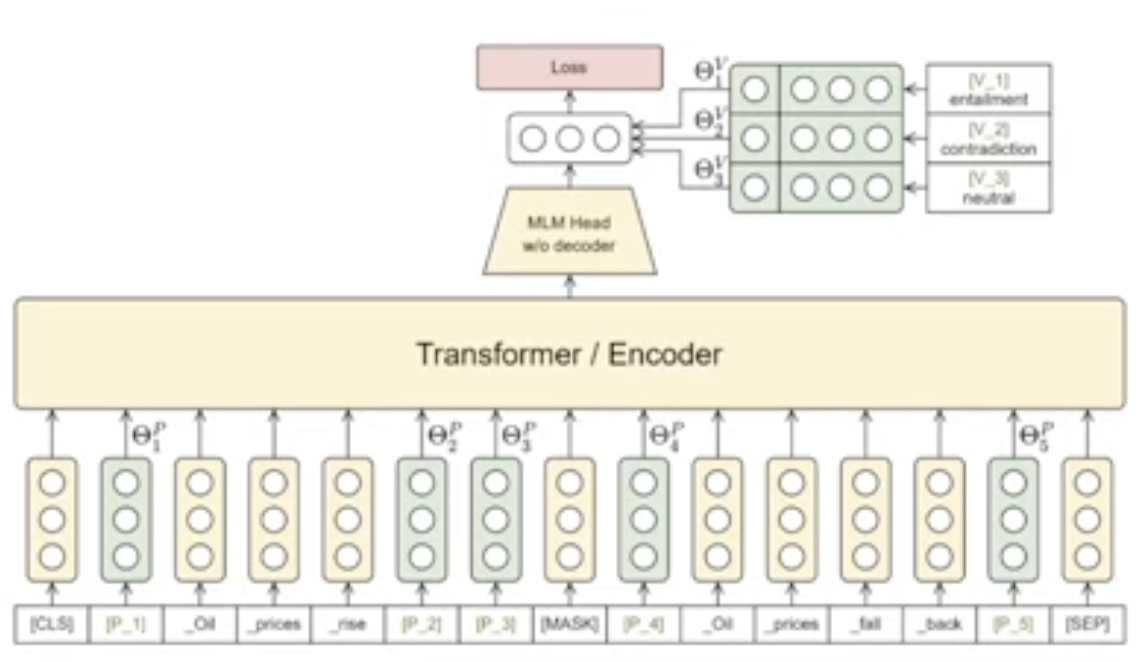
manual prompt template 에 virtual token()를 삽입, 레이블 토큰도 학습을 시킨다. → [MASK]와 레이블 토큰의embedding vector 내적한 값을 softmax 계산 진행 → virtual token과 label 만 업데이트 진행 32개 샘플, 25K개의 trainable parameter만으로 GPT-3성능을 뛰어 넘음, 기존 ipet 방법을 뛰어넘지는 못함
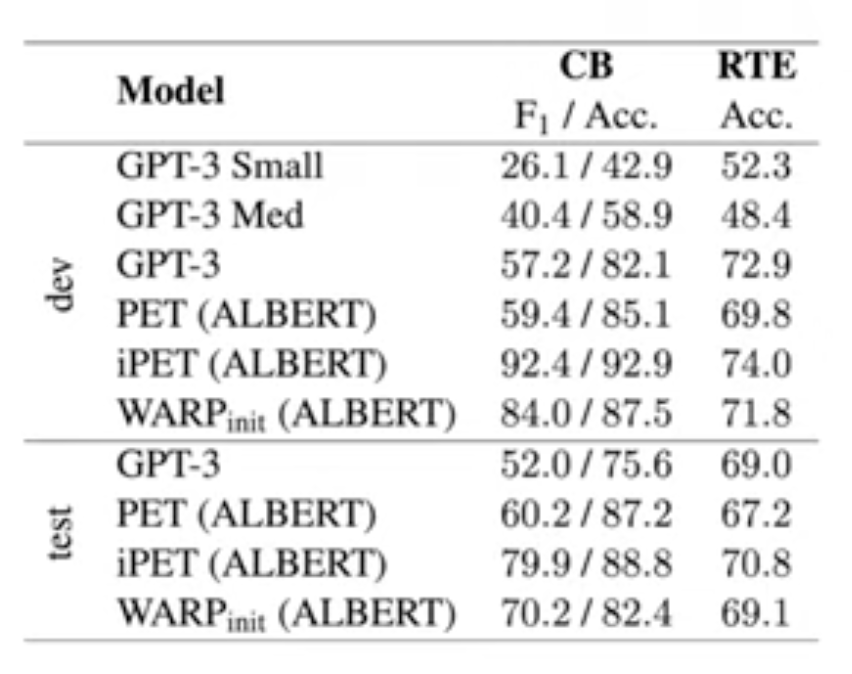
Few-shot setting : SST-2
- WARP10 : 입력 텍스트에 prompt token 10개 삽입
- WARPinit : manual template 에 prompt token 10개 삽입
- 샘플이 100개 일때까지는 AutoPrompt가 학습데이터가 많아질수록 WARP10가 더 높은 성능을 보인다.
- Manual Prompt 와 함께 사용한 조건인 WARPinit 에서는 다른 모든 방법보다 모든 조건에서 더 나은 성능을 보인다.
5. Multi-Prompt Learning - 4가지 방법 존재

1. 앙상블
- weighted average : 여러개 프롬프트에 앙상블을 적용 각 prompt에 가중치를 부여해 학습
- Uniform Averaging : 단일 가중치를 여러개 프롬프트에 적용
- Majority Voting : hard voting 방식
- Knowledge Distillation : ipet 방식과 비슷함 시,공간 복잡도를 줄이기 위해 학습된 레이블을 다음 학습에 참고하도록 하는 방식으로 앙상블한 효과를 가져옴
2. Prompt Augmentation
정답이 포함된 prompt를 예시로 추가
sample 선택과 제시 순서가 성능에 크게 영향을 미친다.
- sample Selection
- LM-BFF, KATE 방식 → sentence embedding 값이 input과 가까운 예시 prompt를 선택
- sample ordering
- orderentropy(Lu et al., 2021): Entropy 기반의 score를 이용해 각 prompt순서 조합에 대해 점수를 부여
3. Prompt Composition
- 각 특성 그리고 관계를 통해서 이것들의 물리적인 규칙을 추가해 prompt 를 만들어내는 방식 - PTR
4. Prompt Decomposition
- 하나의 prompt를 여러개의 sub-prompt로 분할
- sequence Labeling task : 하나의 prompt template으로 표현이 어려움 → 각 위치에 대하여 token z를 예측하는 여러개의 sub-prompt를 사용
- TemplateNER(Cui et al., 2021) : NER task 에 적용
5. Training Strategies for Prompt Methods
Prompt based downstream task learning
- Zeor-shot setting : LM 을 fine-tuning하지 않고 prompt만으로 task 수행 (Tuning-free prompting)
- Prompting method를 쓰면서 downstream task에 대해 fine-tuning 할 수도 있음
- 학습 데이터가 부족한 few-shot learning setting에서 유용
Parameter Update Method
LM 또는 prompts parameter의 update 여부에 따라 5가지로 분류

Fixed-LM prompt Tuning
LM 의 parameter는 고정, prompt와 관련된 parameter를 추가해 업데이트
관련연구 : prefix-tuning(Li and Liang., 2021), prompt-tuning(Lester et al., 2021), WARP(Hambardzumyan et al., 2021)
장점 :
- Catastrophic forgetting을 피할 수 있음
- 학습되는 parameter가 적어 few-shot setting에 적합하며 종종 tuning-free prompting보다 나은 성능을 보임
단점 :
- Zero-shot setting에서는 적용 불가
- Hyperparameter또는 random seed설정 필요
- Continuous Prompt를 최적화하므로 사람이 해석하거나 조작하기 어려움
+) Prompt-Tuning
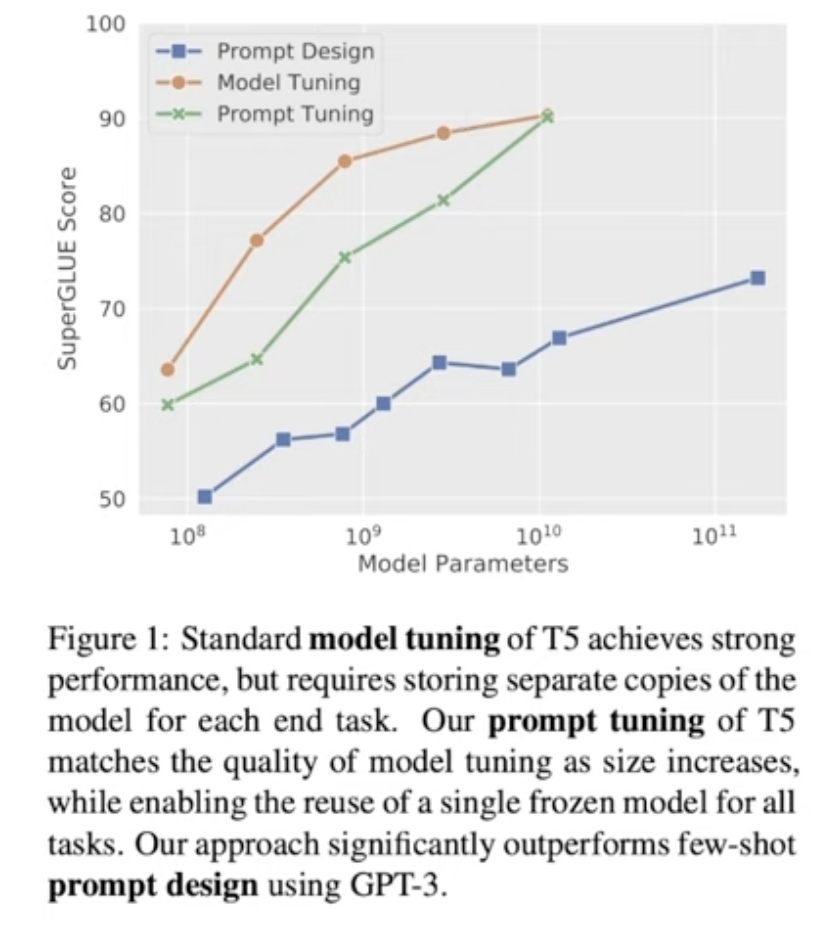
Power of Scale
- LM의 사이즈가 커질수록 fine-tuning과 prompt tuning의 성능 차이가 감소함
- 사이즈에 따라 T5에서 Prompt Tuning, Fine-tuning과 GPT-3의 Prompt Design을 비교한 결과, GPT-3보다 작은 T5가 Prompt Tuning만으로 더 높은 성능을 달성
Prefix-Tuning의 단순화된 버전
- input text의 앞에 downstream task에 대한 virtual token을 붙여 tuning
- Prefix-Tuning에서 제시된 대부분의 장점을 그대로 가져옴
- 새로운 domain에 대한 높은 일반화 성능
- 모델 관리 및 서비스 용이성
Fixed-prompt LM Tuning
Tuning-free Prompting 방식에서 LM의 parameter를 fine-tuning하는 방법
- 관련연구 : PET-TC(schick and shutze, 2021), PET-Gen(schick and shutze, 2020), LM-BFF(Gaoet al. 2021) 등 +) Logan IV et al(2021) → answer engineering과 LM fine-tuning을 조합하면 prompt engineering에 크게 신경쓰지 않고도 높은 성능을 낼 수 있음(NullPrompt)
- 장점 :
- prompting method를 이용해서 모델에 task를 보다 명확하게 지시하여 효과적인 학습 가능(특히 few-shot learning)
- 단점 :
- prompt 또는 Answer engineering필요
- Fine-tuning을 하기 때문에 한 downstream task에 학습된 모델은 다른 task에 좋은 성능을 얻지 못 할 수 있음
Prompt + LM Fine-tuning
Prompt parameter + LM의 parameter 일부 또는 전부를fine-tuning
- 기존 pre-train & fine-tune 방식과 비슷하지만, 서로 다른 promp가 model 학습에 bootstrapping 효과
관련연구
- PADA, P-Tuning
장점
- 가장 expressive한 방법, dataset이 충분할 때 적합
단점
- model의 모든 parameters를 학습하고 저장해야함
- 작은 데이터셋에 과적합 가능성
성능비교 - p-tuning논문
기존 discrete method를 모두 능가하는 결과를 보이며, LM을 고정시켰음에도 불구하고 fine-tuning방식보다 더 나은 성능을 보임

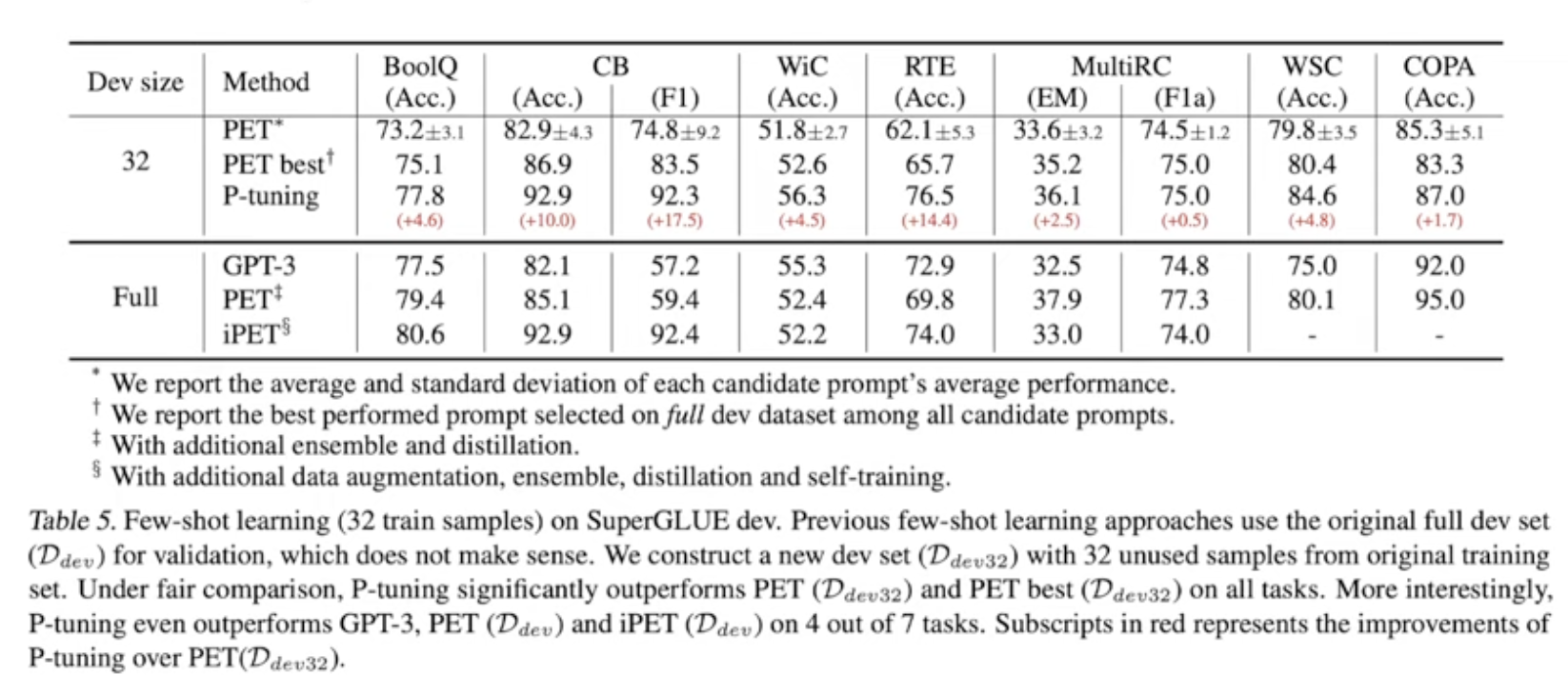
few-shot setting
Challenges

Reference
https://www.youtube.com/watch?v=zbuD21YwLZI&t=724s
