
목차

Introduction

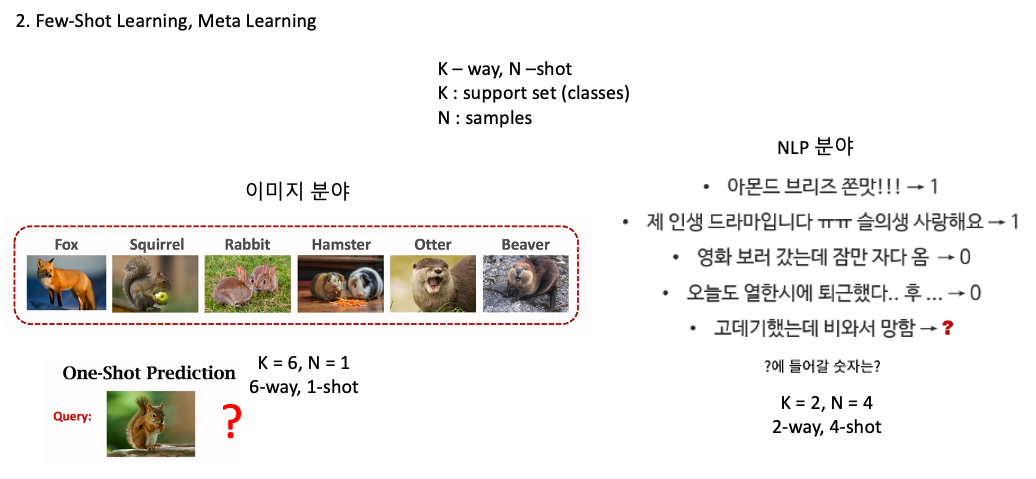
Few-Shot Learning, Meta Learing

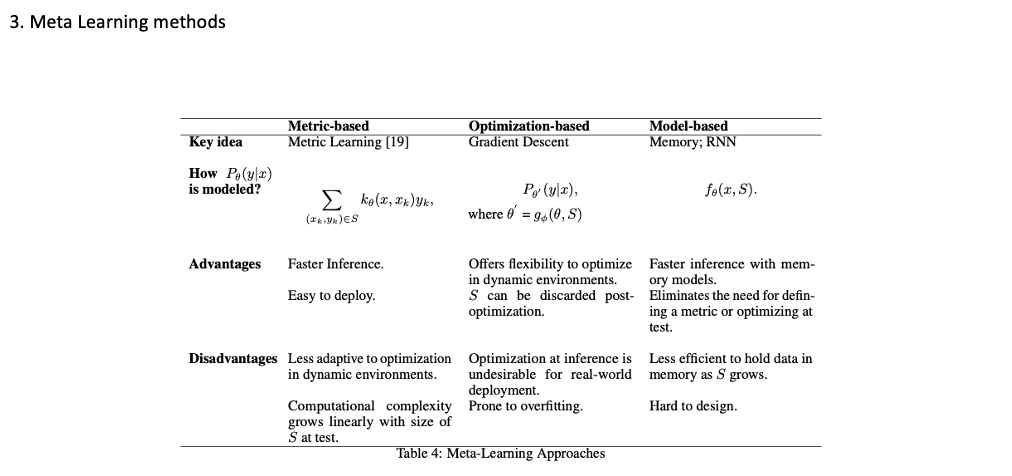
Meta Learing Methods
Metric :
- 빠른 추론, 다양한 응용분야에서 활용 가능한 유연한 메타러닝 방법, 다양한 문제에 적용가능한 일반적인 유사도 측정 기법 학습 가능(데이터 분류, 검색, 임베딩)
- Less -> 새로운 태스크에 적용하기위해서 새로운 유사도 측정이 필요, 당연히 테스트셋에따라 연산량이 증가함
Optimization :
- 동적환경에서 하이퍼 파라미터 자동 최적화가 가능, 사전 최적화를 버릴 수 있다.
- 과접합 되기 쉽다, 실제환경에서 배포되기 어렵다
Model-based
- 메모리 모델을 통한 빠른추론, 테스트 시 최적화할 필요가 없다.
- S(support set) 커짐에 따라 데이터를 메모리에 보관하는 것이 덜 효율적이 된다.
Siamese Neural Network

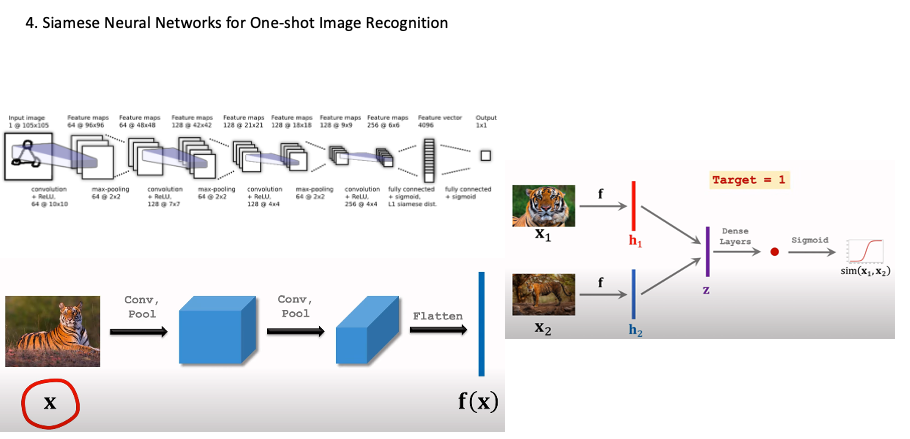
Siamese Neural Networks는 일반적으로 두 개의 인공 신경망으로 이루어져 있습니다. 이들은 같은 구조를 가지며, 동일한 가중치를 공유합니다. 즉, 두 개의 네트워크는 동일한 피처 추출기를 사용하여 입력 데이터에서 피처를 추출합니다. 이 추출된 피처는 각각의 네트워크에서 별도로 처리되며, 그 결과값을 사용하여 입력 데이터의 유사성을 측정합니다.
feature 벡터로 나타나게 하고 각 샘플의 뺀다. Z = V1-V2 그후 dence Layer로 나타나게 한 후 sigmoid 를 통해 로지스틱 분류를 진행한다.
Loss는 Cross-Enthropy를 사용, backpropagation을 통해 Dense Layer가중치와 f 에서의 가중치를 업데이트를 진행하게 된다.

query이미지를 support set과 하나씩 비교하면서 위의 과정을 통해 유사성 점수를 구할 수 있다. 여기서 가장 큰 값이 정답값이 된다. (위는 one-shot prediction에 해당)
Siamese Neural Networks는 많은 분야에서 사용됩니다. 예를 들어 얼굴 인식, 얼굴 감지, 비디오 추천, 문서 매칭, 검색 엔진 등에서 매우 유용합니다.
Triplet Loss
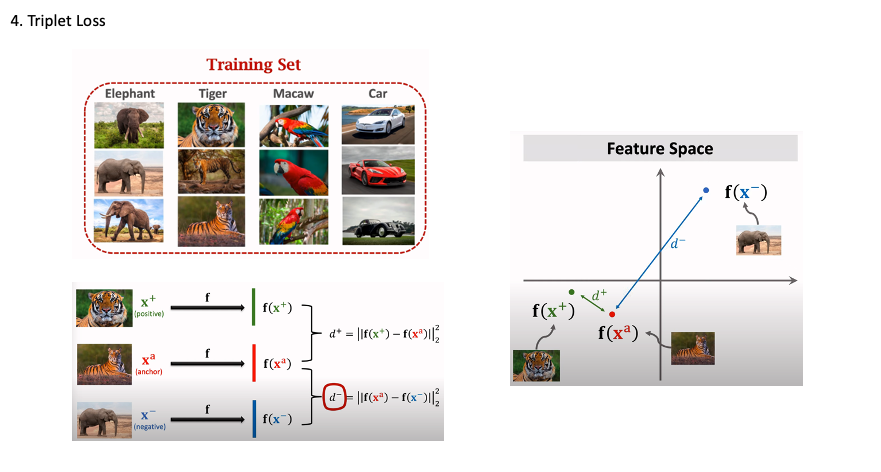
Data for training Siamese network , 위 트레이닝 셋에서 anchor라는 하나의 이미지를 가지고 긍정 샘플을 x+, 부정샘플을 x-라고 표현한다.
각 샘플에서의 convolution을 거쳐서 나온 dense 레이어에서 f(x+) 와 f(x_anchor)의 차의 제곱 (L2 Norm- 유클리디언 거리) 그리고
f(x-) 와 f(x_anchor)의 차의 제곱을 비교하면 d+는 상대적으로 작은 값이 나오고 d-는 상대적으로 큰 값이 나오게 된다.
이를 Feature space에서 표시할 수 있게 되는 특징이 있다.
Relation Network
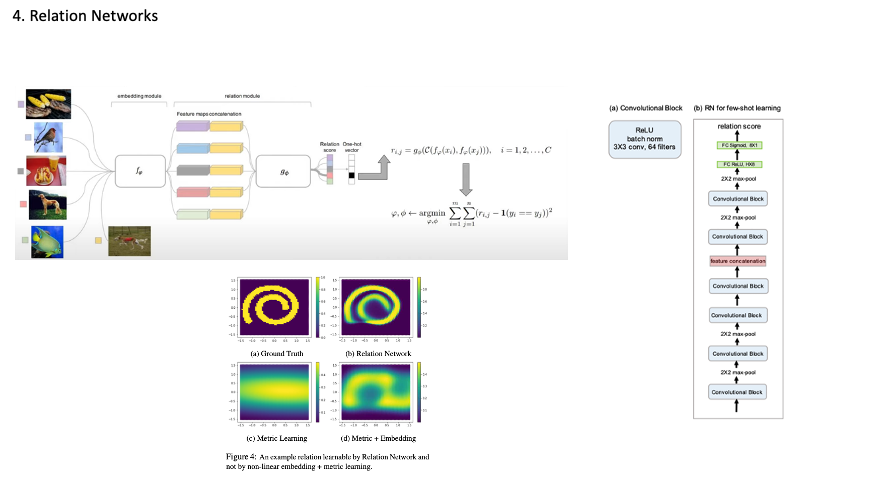
먼저 임베딩 네트워크에 CNN을 통해 Feature 맵을 추출하고 Relation Network 입력으로 사용됩니다. query feature map과 concat 한 후 relation network에서 이미지들간의 관계를 게산한 후 각 이미지 임베딩 벡터에 반영됩니다.그러고 나서 이미지 벡터간 유사도를 측정을 통해 socre가 나옵니다. 이후에는 MSE 를 최소화하는 방향으로 학습이 진행 되는 방식입니다.
Relation Network는 Pairwise Comparison, Non-Linearity, 그리고 Feature Space활용 Few-shot learning 해결하려했다.


옴니글랏 데이터셋 50가지의 언어 1623개 문자를 20개의 다른사람이 만들었음.
30개의 언어를 통해 학습시키고 20개의 언어로 one-shot task를 테스트 했다.
트레이닝 언어는 964개의 알파벳 테스트언어는 659개 알파벳을 사용해 학습을 진행함
Evaluation 할때 테스트 이미지와 support set 이미지를 넣어 테스트를 진행 support set에는 1개만 같은 이미지를 넣고 나머지는 다른 클래스의 이미지를 넣습니다.

결론부분에서는 원샷 분류를 수행으로 Metric 학습 접근 방식으로 인간 수준의 정확도를 도달했다는 가능했다는 것을 나타내고 이 접근 방식으로 다른 도메인 이미지에 대한 원샷 학습 작업으로 확장해 보는 것을 주장
MNIST 데이터 셋에서 얼마나 잘 일반화 할 수 있는지 확인하기 위해 MNIST one-shot을 시도, MNIST를 훈련시키지 않고 one-shot을 진행한 결과는 70.3% 정답률이 나왔습니다.
Reference
https://littlefoxdiary.tistory.com/44
https://jayhey.github.io/deep%20learning/2018/02/06/saimese_network/
https://arxiv.org/pdf/1412.6622.pdf
https://choice-life.tistory.com/104
https://www.cs.cmu.edu/~rsalakhu/papers/oneshot1.pdf
https://arxiv.org/abs/1711.06025
