보간법(Interpolation): 주파수 파형 등을 부드럽게 변화시키는 방법
Neural Tangent Kernel (NTK)는 딥러닝과 커널 메소드를 연결하는 개념. DNN 학습할 동안 발생하는 기울기 변화를 분석하는데 사용된다. NTK는 딥러닝 모델의 특정 초기화와 아키텍처에 대해, 네트워크의 각 레이어에 대한 입력 데이터의 미세한 변화가 최종 출력에 어떻게 영향을 미치는지를 정량화 한다. NTK는 국소 선형화를 제공하며, 네트워크의 학습 동안 변화하는 내부 매핑을 이해하는데 도움을 준다. NTK는 무한히 넓은 네트워크에서의 함수 근사와 최적화 문제를 분석할 수 있게 해주는 수학적 도구이다.
원래 Transformer는 Absolute sinusoidal position encoding을 사용했으나, 이를 개선하기 위해 RoPE(Rotary Position Embedding)가 출현함.
이후 PI(Positional Interpolation)라는 방법이 RoPE를 사용하는 LLM의 context window를 확장했다. 하지만 PI는 모든 dimension을 동일하게 scaling하기 때문에 high frequency 정보 손실이 있다.
"NTK-aware" interpolation라는, 높은 주파수(high-frequency) 정보의 손실을 방지하기 위해 주파수별로 가변 스케일링하는 방법이 제안되기도 했다. 이 방법은 extrapolation으로 인해 fine-tuning 성능이 떨어지는 문제가 발견되었다.
NTK-Aware Scaled RoPE: 기존 RoPE 인터폴레이션 방법을 개선하여 텍스트 생성 모델의 문맥 크기는 8000이상으로 확장하는 방법에 대한 설명이 포함되어 있다. 이 방법은 추가적인 학습 없이 사용가능하다. 기존 방법은 fouier 공간에서 선형적으로 RoPE를 인터폴레이트하는 것이다. 이는 토큰의 순서와 위치는 정확히 구분하는데 있어 최적이 아니였다. 특히 인접한 토큰들을 구분하는데 문제가 존재. NTK 이론을 바탕으로 비선형 인터폴레이션 방식을 개발했다. 새로운 방식은 RoPE의 기저를 변경하여 각 차원 벡터가 다음 벡터와 비교하여 회전하는 속도를 직관적으로 변경했다. 이는 포리에 특성을 직접 스케일링하지 않고 모든 위치를 서로 완벽하게 구별할 수 있다. https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/
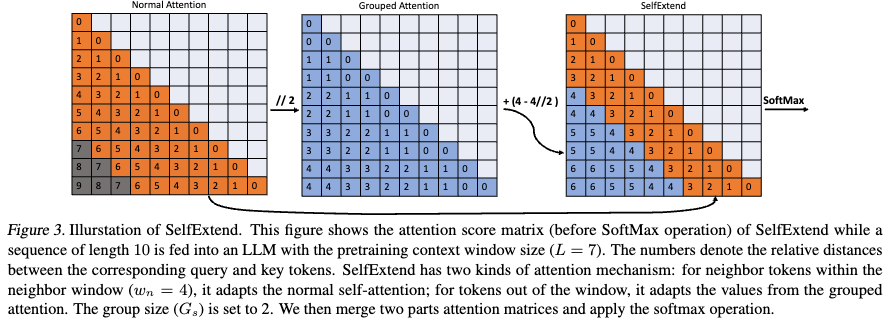
LLM Maybe LongLM - (SelfExtend): 약간의 코드 변형을 통해서 긴 context를 사용할 수 있는 모델을 만들어냄. keyword: grouped attention, neighbor window
ABSTACT
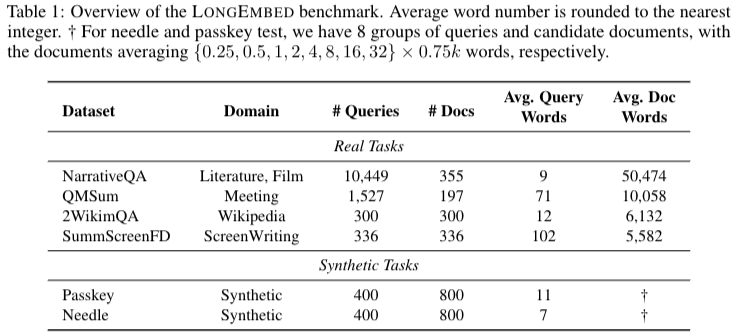
LLM의 Context length를 늘리는 연구는 1M tokens까지 늘릴정도지만, embedding의 context length는 8K정도 밖에 되지 않는다는 문제가 있다. 이는 법조문과 같은 긴 context가 필요한 task에서 제한이 있다. 본 논문은 32K 까지 추가적인 학습없이 context window를 늘렸다. 본 논문의 시험을 위해 long context embedding benchmark를 만들었으며 이를 LONGEMBED 라고 한다. LONGEMBED에는 2개의 synthetic task와 4개의 real world tasks가 있다.
INTRODUCTION
text embedding은 RAG나 IR 분야에서 많이 사용된다.
전통적인 방식은 좋은 퀄리티의 데이터를 바탕으로 contrastive learning을 진행하는 방식이 있다.
문제1: 이러한 학습을 통해 long context embedding model을 scratch로부터 학습시키는데는 computation overhead가 존재한다는 문제가 있다.
문제2: long context embedding 을 평가할 metric의 부재로 본 논문은 LONGEMBED benchmark 제안한다.
RELATED WORK
text embedding
Modern embedding model은 query-doc pairs 를 바탕으로 in-batch negative를 통해 contrastive learning을 진행, 최근에는 GRIT 과 같은 embedding과 generation을 함께하는 모델을 만들어냈다. 또한 embedding의 context length 를 늘리기 위해서는 추가적인 학습을 필요로 했다.
Context window Extension for LLM
Scratch부터 pre-training을 진행하는 것을 computation이 많이 들어가므로, LLM에서 plug-and-play manner 가 많이 연구되어왔다.
1) Divide-and-conquer: input text를 segmenting 진행을 통해 나눠주는 방식 - PCW 논문
2) Position reorganization: reorganize position id → boost length extrapolation - SelfExtend, DCA
3) Position interpolation: PI, NTK, YaRN and Resonance RoPE 라는 기존방식이 있는데 본 논문은 해당 파트에 해당함.
본 논문은 또한 original training data를 바탕으로 long training sample을 만드는방법또한 공개한다.
THE LONGEMBED BENCHMARK

METHODOLOGY
Context Window Extension for APE-Based Models
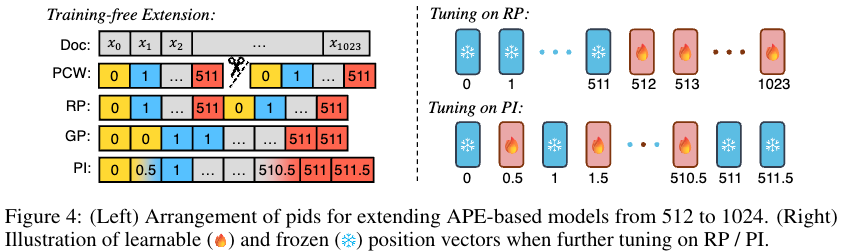
- Parallel Context Windows (PCW): PCW는 긴 document를 multiple short chunks로 나눠서 나중에 결과를 aggregate. 쉬운 예시로 chunk embedding을 평균내는 방식이 있음.
- Grouped Positions (GP) & Recurrent Positions (RP):
- Linear Position Interpolation (PI): assign embeddings for non-integers.
Context Window Extension for RoPE-based Models
-
Self Extend (SE): grouped attention, neighbor attention을 이용해 학습없이 context length를 늘릴 수 있는 방법을 제안함.
-
NTK-Aware Interpolation (NTK): 높은 주파수(high-frequency) 정보의 손실을 방지하기 위해 주파수별로 가변 스케일링하는 방법
EXPERIMENT
기존 방식들에서 본인들이 만든 데이터셋에서 성능 baseline과 모델 사이즈
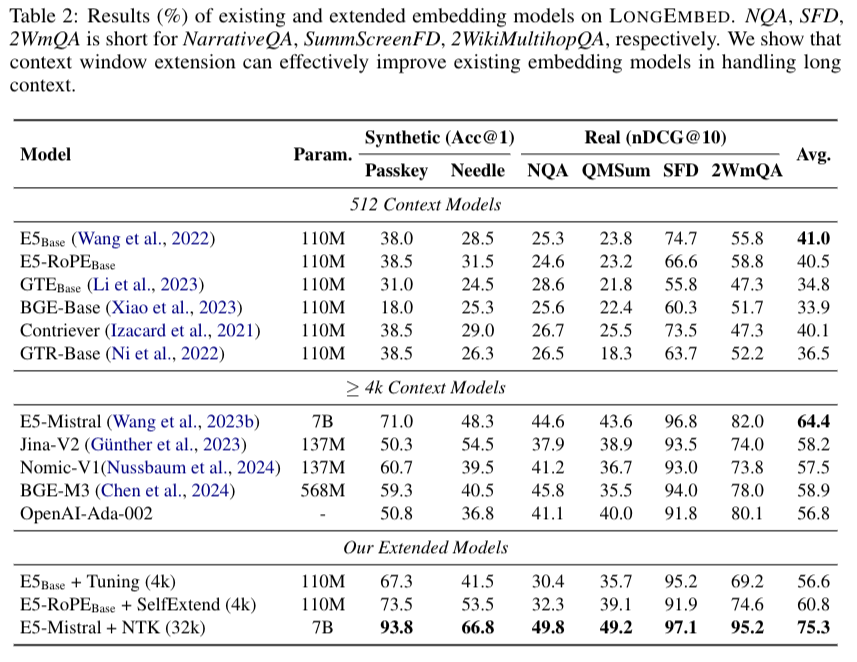
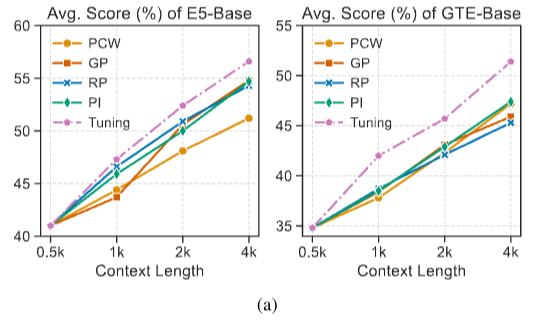
context length를 늘리는 방식중 어떤방식이 가장 효과적인지에 대한 실험결과
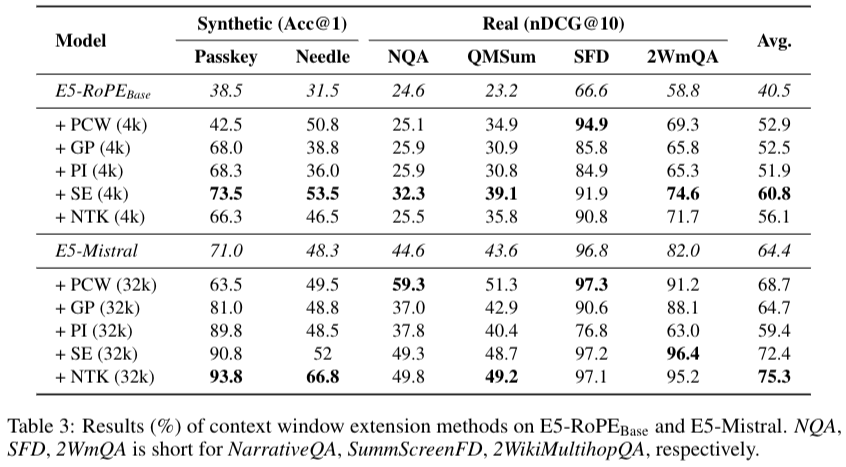
RoPE 와 APE중 어떤 방식이 embedding을 만드는데 더 좋은지에 대한 실험결과
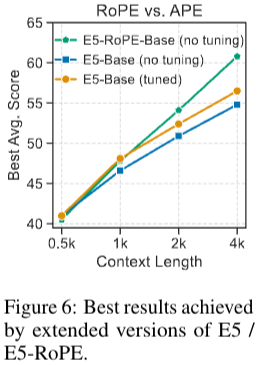
context length 늘리는 방식중 어떤방식이 acc가 가장 좋은지와 tuning을 적용했을 때 실험결과