잘못된 내용이 있다면 댓글 부탁드립니다!! 감사합니다 :)
Motivation: 사람이 수학문제를 풀 때 중간에 틀린 부분을 참고해서 학습하게되는데 모델을 answer부분만 학습을 하고있음. → 중간단계를 학습시키는 것이 성능에 더 효과적이지 않을까?
Summary: 답변만 검증하는 모델(ORM) 그리고 학습 중간단계를 검증하는 모델 (PRM) 모델들의 성능 차이를 확인을 통해 어떤 방식이 더 검증을 잘하는가 평가를 진행함 (정확하게는 여러개 샘플중 어떤 답변이 가장 합리적인지 찾는 테스크).
Novelty: Purpose reasoning step verification using model training
ABSTRACT
reasoning task를 잘 수행하는 모델들이 많이 생겼지만 여전히 logical mistakes 가 나온다. 본 논문은 최종답변을 더 좋게 만들기 위해 중간단계(reasoning steps)의 RM을 만들어 성능을 증가시킨다. 또한 학습을 위한 PRM800K 데이터를 만들었다. reward 모델 만들기 위해 사람feedback이 들어간 label로 800,000 step 학습을 진행하였다.
INTRODUCTION
Outcome-supervised reward models (ORMs): 최종 결과에 대한 reward model
process-supervised reward models (PRMs): reasoning 중간 단계에 대한 reward model
“Solving math word problems with process-and outcome-based feedback” 논문에서는 Reward model을 나눠서 학습하는 것이 차이가 없다고 주장했다. (in-domain of grade school math) 하지만 본 논문에서는 다음과 나누는 것이 효과적이라고 말하며 MATH 데이터셋에 대해서 실험을 진행했다.
본 논문의 contribution은 아래와 같다.
- PRM 을 이용해 SOTA 성능 달성
- large reward model이 human supervision을 approximate 할 수 있다고 주장함.
- active learning 방식이 2.6x improvement in the data effciency of process supervision
- PRM800K 데이터셋 공개
METHODS
process supervision 과 output supervision 간 동등한 비교는 어렵다고 함 → small scale model을 만들어서 비교했다 (??)
평가방법으로는 best-of-N 전략을 이용해 N개의 솔루션 중에서 가장 좋은 솔루션을 선택하는 능력을 평가한다.
large-scale 실험은 GPT-4 model을 이용했으며, small-scale 실험은 gpt-4와 유사한 디자인의 x200배 더 적은 pretrained model을 이용했다. 두 모델 전부 1.5B 토큰의 fine-tuning을 진행했다.
Generator는 각 스텝을 생성하는 역할로 사용된다.
Dataset은 기존 MATH 데이터를 바탕으로 GPT 가 생성하고 이를 pos, neg, neu 로 3개로 rationale 각 step을 평가를 진행했다. 이렇게 해서 step-labels 는 75K 이고, solutions 는 12K의 학습데이터셋을 만들었다. 전체 평가셋은 4.5K 이지만 500개만 이용해서 test데이터를 구성했다.
PRM 을 학습시키기 위해서는 convincing worng-answer 데이터셋을 학습시키는 것이 중요하다. 효과적으로 학습시키기 위해 selection strategy과 iteratively re-train을 사용했다. 각 iteration 마다 problem1개에 N 개의 solution을 바탕으로 top-K 개의 convincing worng-answer 데이터를 골랐다. (data collection process가 매우 비싸 process에 대한 ablation 과정을 진행할 수 없다고 말함.)
Outcome-supervised Reward Models (ORMs)
”Training verifiers to solve math word problems.” 과 학습방법을 동일하게 진행하였다. 최종 답변을 보고 correct인지 incorrect인지 구분하도록 학습이 진행된다.
Process-supervised Reward Models (PRMs)
해당 학습은 단순히 target 토큰의 log-likelihood를 maximize 시키는 방향으로 학습이 진행한다. 특별한 accomodation없이 일반적인 language model pipline과 동일하게 학습된다.
모델 학습을 진행할 때 저자들은 의도적으로 첫 번째로 incorrect step까지만 선택해서 학습했다. 해당 과정은 ORM과 PRM의 차이를 더 분명하게 하며, 이렇게 학습하는 것이 사람의 행동과 더 유사하고 말한다.
Large-scale Supervision
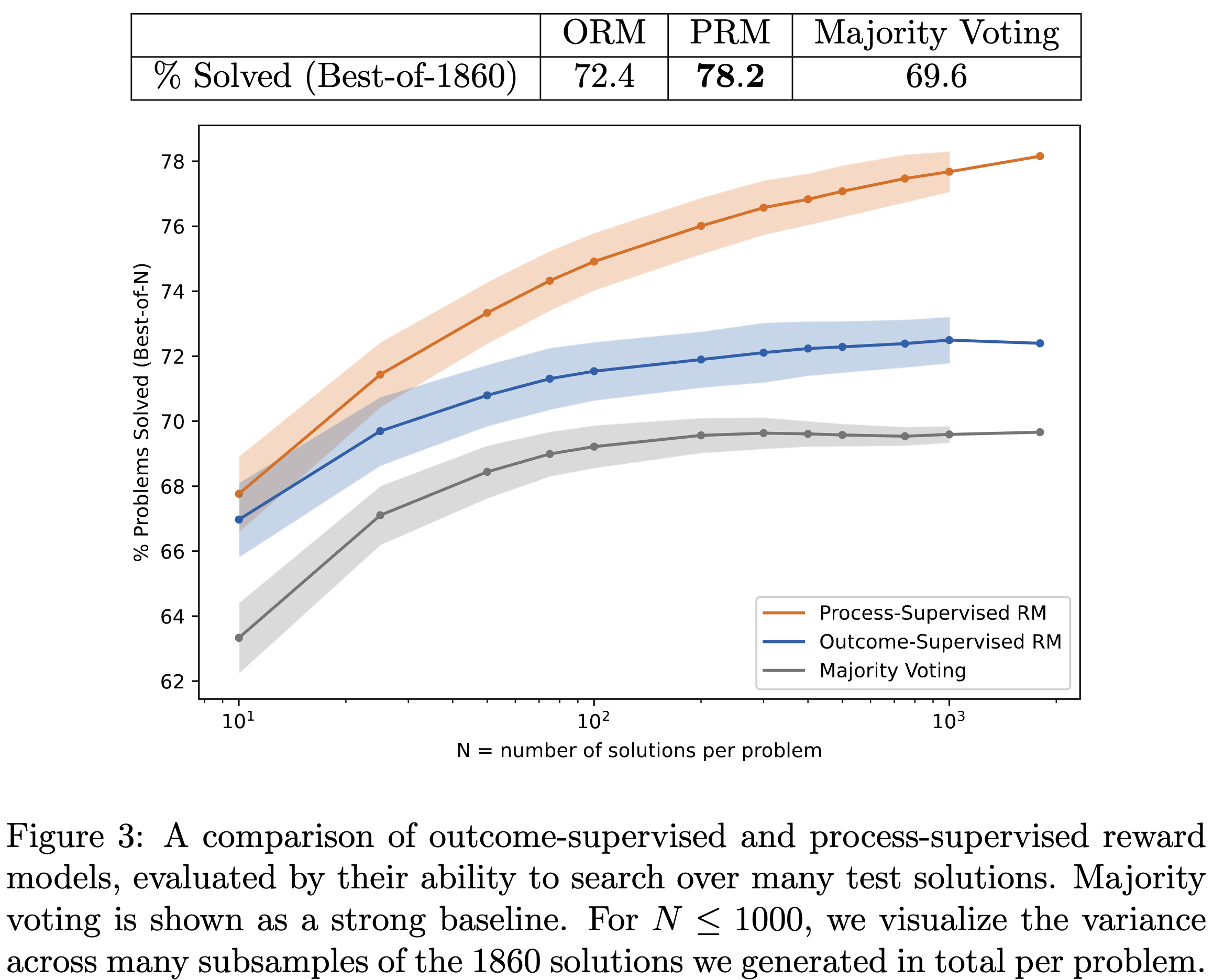
large scale (gpt4)를 바탕으로 학습시켰을 때 결과.
Small-scale Synthetic Supervision
large-scale supervision에서는 동등한 비교가 불가능하다. 1. training set이 ORM 과 PRM 이 다르다. PRM은 active learning을 통해 만들어진 데이터셋을 바탕으로 학습이 진행된다. 그렇게 되면 answer-incorrect solution에 편향되어 학습되게 된다. 2. 최종 답변에 대해 잘못된 추론이 존재해도 답만 맞은 경우 긍정적인 점수를 부여한다. 해당 학습으로 인해 ORM performance가 감소할 수 있는 문제가 있다.
Process vs Outcome Supervision
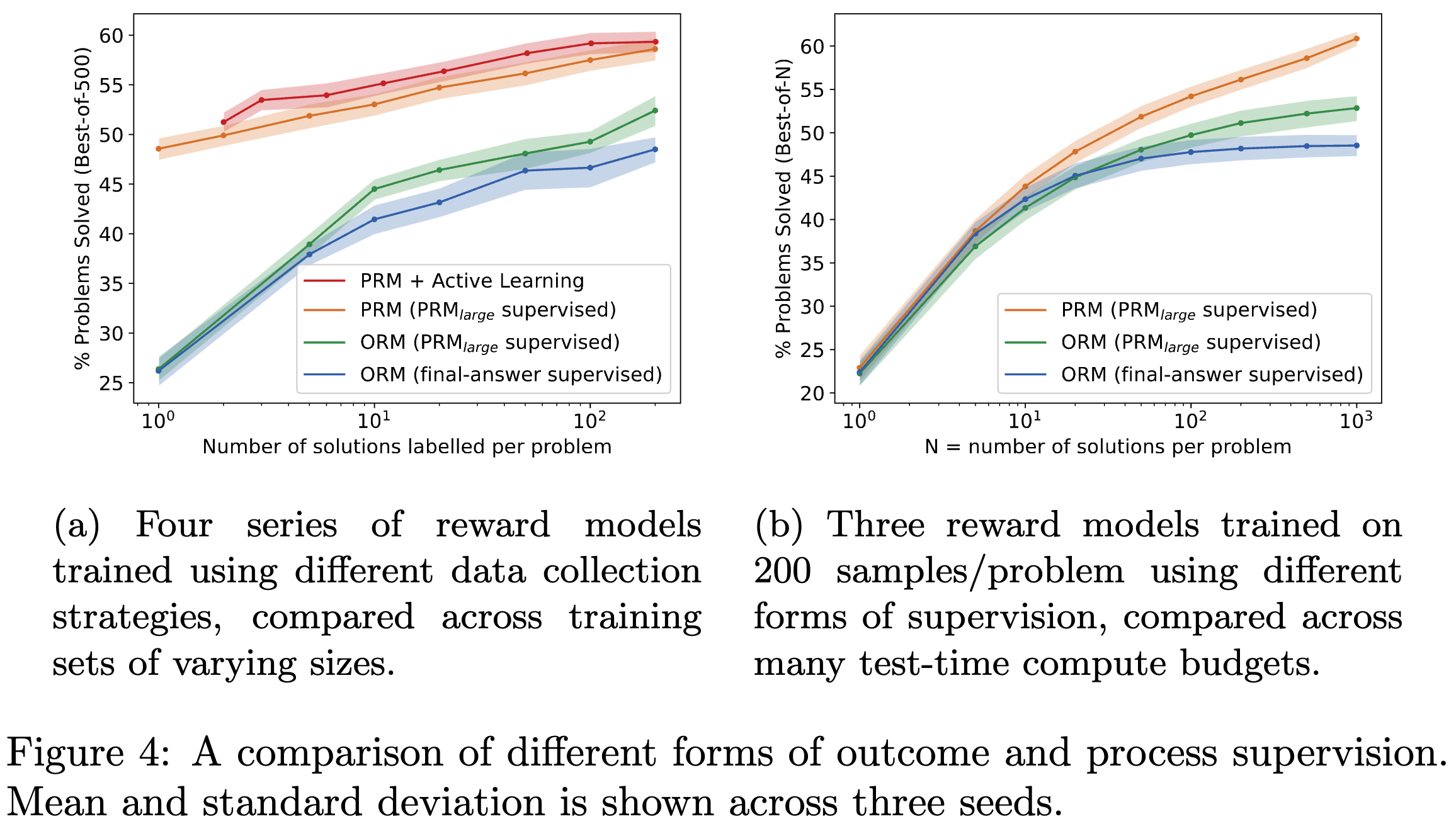
를 superviser 로 사용해 small scale로 PRM, ORM을 학습시킨 결과 (a, b). smaller model에 정답을 알려주는 용도로 사용했다고함 (final answer 까지)개인적인 생각으로는 이런 방식은 PRM에 편향적으로 학습될 것 같다고 생각하고 이 또한 동등한 비교가 아닌 것 같음.
Active Learning
본 학습을 위해서 모델을 바탕으로 데이터를 만들었다. 각 문제당 1000개의 sample을 score을 매기게 하고 모델이 높은 점수를 매겼지만 틀린 데이터에 대해서 학습샘플로 넣어주게된다. 해당 과정을 통해 2.6x 더 효과적으로 labeling할 수 있다고 주장한다.
OOD Generalization
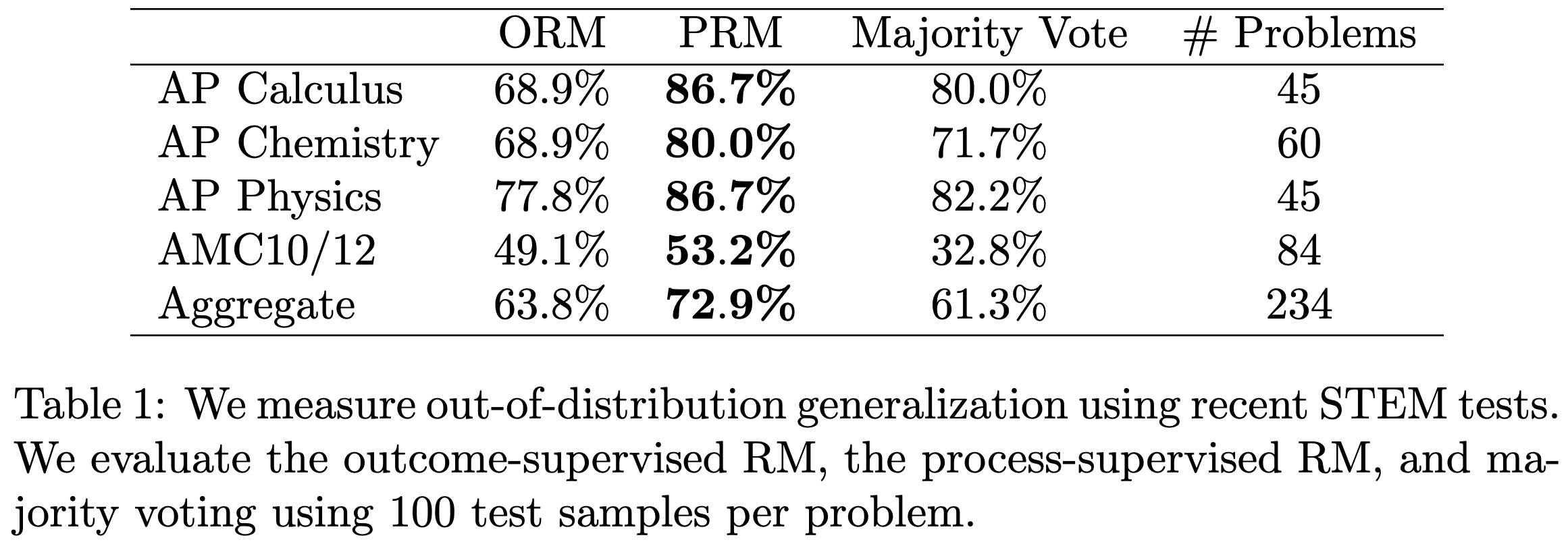
STEM dataset에 대해서 ood 평가를 진행했을 때도 PRM이 가장 좋은 성능이 나왔으며 ORM은 대부분 Majority Voting 보다 낮은 성능이 나온다.
