Abstract - LoRA : LLM finetuning을 효율적으로 해보자
LoRA(Low-Rank Adaptation) : 사전학습모델 freeze 시키고, inject 학습가능한 rank decomposition matrices → 파라미터 10,000 times 증가, GPU memory 3times 감소
기존 adapter와 달리 no additional inference latency
no additional inference latency란? 기존 adapter 적용 시 input이 들어오면 모델에서 생성하는데 시간이 더 걸리는 경향이 있었다. 하지만 LoRA에서는 거의 computational resourse에 차이가 없다 싶을 정도로 설계되었기 때문에 생성하는데 걸리는 시간이 차이가 없다.(거의 변화 X)
Introduction
이전 adaptation 의 단점
- adaptation은 주로 fine-tuning에서 사용되는데 모든 파라미터를 업데이트 시키는 경향이 있다. 하지만 LLM(Large Language Model)에서는 많은 연산량을 필요로 해 불편한 점이 존재한다.
- 또한 새로운 task에 대해 파라미터를 수정하는 경우 추가적인 task specific parameter load하고 store하는 과정이 필요하게 된다.
- 또한 p-tuning 등 에서는 sequence length 가 줄어들고, adaptation은 model depth를 증가시켜 inference latency를 발생시킨다.
LoRA는 low intrinsic dimension(실제 사이즈보다 적은 사이즈로 해당 모델을 표현할 수 있다) 라는 기존 연구들을 바탕으로 아이디어를 받아 model 은 frreze(모델 파라미터 변경 X)시키고 몇 개의 dense layers 를 indirectly 하게 학습시켜 rank decomposition matrices of the dense layers’ change 를 만들어냈다(dense layer 최적화 해서 adaption시켰다)
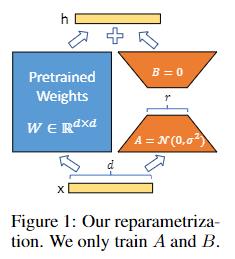
Problem statement
: AR(autoregressive) 모델에서의 parameter라고
: 사전학습된 weight
: 파라미터 변화량
기존 수식에서는 를 maximize 시키는 방식으로 학습 시켰다.
full fine-tuning 방식에서 와는 달리 를 maximize 시키며 pretrained된 weight에 추가적인 파라미터를 더한 부분만 업데이트 를시키는 방식으로 진행하였다.
이때 에 비해 는 0.01% 만큼 작게 설정할 수 있다고 논문에 나와있다.
Aren’t existing solutions good enough?
Adaptation의 기존 2가지 방법
- adding adapter layer : pretrained model위에 추가적인 레이어(모델)를 쌓고 학습시키는 방법
- optimizing some forms of the input layer activations : input text에 initial preprocessing 하는 것
기존 방식들은 Adapter Layer부분에서 Inference Latency가 존재한다.
Prefix 방식의 경우 train parameter update가 non-monotonically하다 (최적화 시키기 어렵다는 뜻)
Our method
4.1 Low-Rank parameterized update matrices
랭크에서 r은 주로 1 or 2를 사용(논문 실험에서는 64까지 존재)하고 ****부분은**** 로 스케일링 시켜준다. (는 상수(learning rate와 같은 수를 사용), r은 rank matrics 에서 사용하는 숫자)
+) 사견 : BA부분의 영향도가 pretrained된 것 과 같으면 변동성이 심해지기 때문에 스케일링 시켜줬다.
Applying LoRA to transformer
메모리 공간 감소에 가장 큰 장점이 있다. VRAM이 2/3까지 감소할 수 있다. if r<<
GPT3 full fine-tuning 과 비교했을 때 속도도 25% 차이가 발생한다.
LoRA 에서 말하는 한계 : batch 단위 처리를 할 때 동적으로 LoRA 모듈을 바꿔줘야 한다. 한 LoRA모듈로 모든 task를 수행할 수 없다는 뜻
Empirical experiments
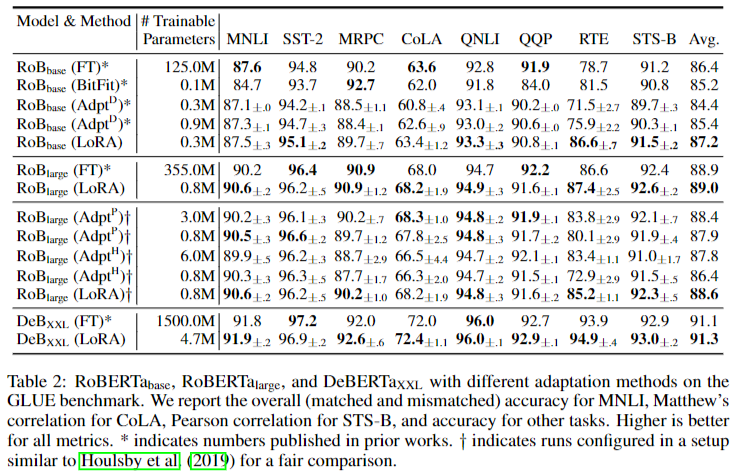
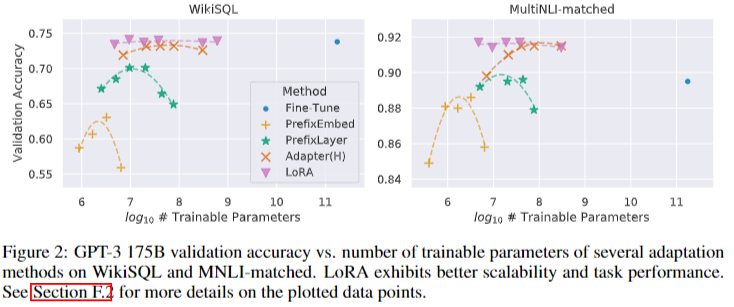
+) training parameter 가 많다고 이점이 있는 것이 아니다. prefix-layer tuning(prefix-tuning 확장 버전)에서 special tokens을 더 넣었을 때 성능이 하락한다.