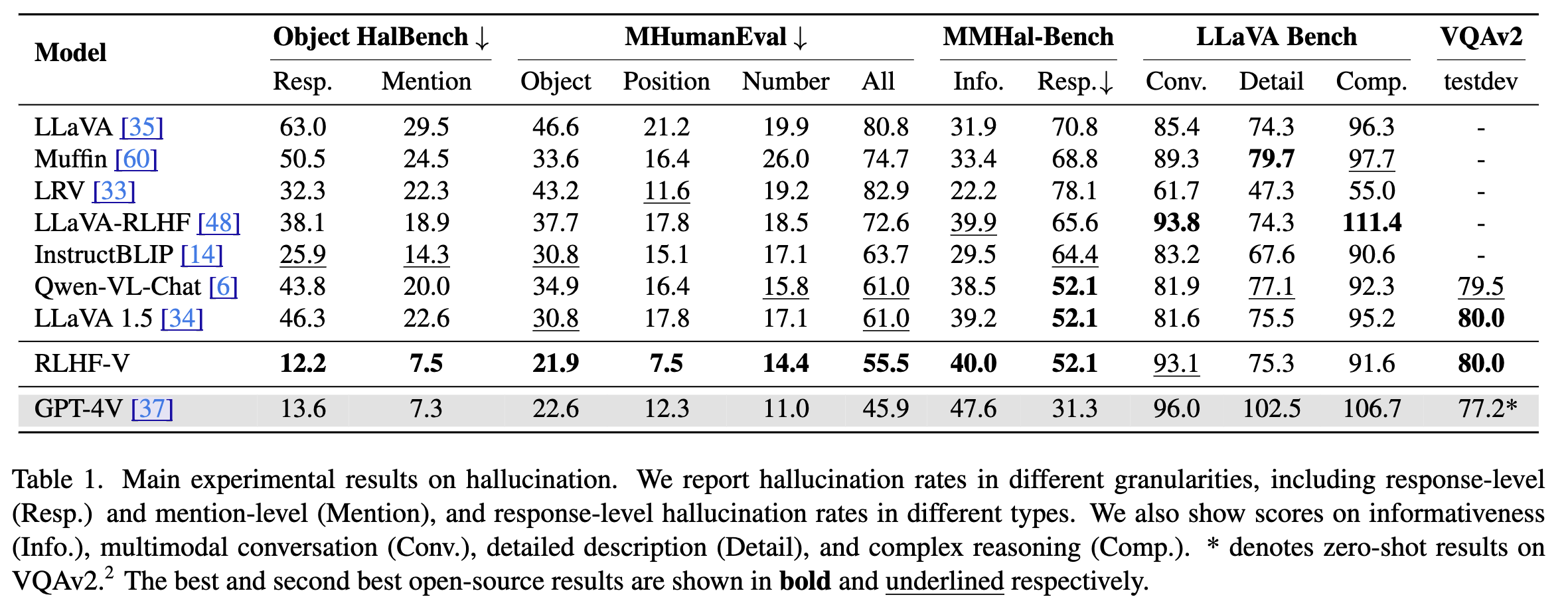
Multimodal 에 fine-grained correctional human feedback을 통해 MLLM의 신뢰성을 향상시키고자 한다. RLHF-V 는 1.4K annotated data를 통해 34.8% hallucination을 줄일 수 있었고 10K 데이터로 학습시킬 것 보다 더 성능이 좋았다는 결과가 나왔다. 학습 방식으로는 dense direct preference optimization (DDPO) 방식을 제안한다.
저자들은 MLLM 의 행동에 human preference 가 잘 반영되고 있지 않다고 주장한다. 이는 hallucination을 발생시킨다. GPT-4V의 경우 45.9% 의 hallucination을 포함한 응답 결과가 나오는 것을 볼 수 있다. 이에대해 저자들은 분명한 boundary를 가지는 pos/neg instruction human feedback의 부족으로 발생한다고 주장한다. 이러한 문제에 대해 2개의 key challenges를 (1) Annotation ambiguity: figure 1에서 시간과 같은경우는 명확하게 annotation하기가 힘들다. (2) Learning efficiency: coarse-grained ranking feedback은 정확하게 어느부분을 바탕으로 feedback이 만들어진 것인이 언어적 모호성과 다양성으로 인해 feedback이 명확하지 않다.
이런 key challenges 에 대해 RLHF-V는 2가지 innovations를 제안한다. (1) Data level: 저자들은 fine-grained segment-level corrections 로 형성된 human feedback data를 제안한다. figure 1에서 사람에게 hallucinated segments를 모델 response 로부터 추출하게 한다. 해당 방법을 통해 언어적 variance와 non-robust bias를 완화할 수 있다고 주장한다. (2) DDPO: Method level에서 fine-grained segment단위의 데이터를 사용한 학습방법을 제안한다. dense 한 feedback을 통해 더 강한 feedback을 줄 수 있다고 주장한다.
저자들을 1.4k preference data를 사용해 hallucination rate를 base MLLMdptj 34.8%가량 줄일 수 있었다고 한다. 이는 10k 데이터를 사용한 LLaVA-RLHF 의 성능을 능가한다.
Human Preference Collection
을 preferred output이라 하고, inferior output이라고 하자 이를 로 notation 한다고 할 때 3가지로 분해한다. , 는 truly preferred behavior로 trust-worthy and helpful을 나타낸다. 는 non-robust bias를 나타낸다. 이는 human judgement와 관련이 없다.(더 specific word를 사용하는지 정도 ). 은 random noise factor로 linguistic variance of natural language 를 의미한다. (e.g. different ways of expressing the same meaning).
→ 정리
: 학습해야할 목표 행동. 진정한 선호 행동을 나타낸다. 인간이 선호하는 핵심적인 행동으로 신뢰성, helpful과 관련된 정보들 → 이미지에 대한 사실적인 묘사
: 학습에서 배제해야할 요소. 비견고한 편향. 데이터에 내제된 편향성으로 인간의 선호와 관련이 없음. 특정 단어의 빈도나 자주사용하는 단어, 표현 등. → 를 학습하면 reward hacking 문제가 발생할 수 있다고 지적함. - 단어 빈도등을 학습해버리기 때문
: 학습에서 피해야 하는 요소 (학습을 어렵게 만듬). 자연어 표현의 언어적 다양성 (동의어 등) random noise적인 요소로 human preference에 큰 영향이 없음. 완전한 제거는 어렵기 때문에 피해야하는 요소
데이터를 만들 때 annotator에게 3가지 요소를 고려해서 를 만들게 했음.
- 평균적으로 64.4 단어와 2.65개의 수정된 세그먼트를 포함하고 있다. 수정된 세그먼트는 객체(41.2%), 위치(20.3%), 숫자(16.5%), 속성(10%), 동작(5.3%), 기타(6.8%)
Method
DDPO 방식은 DPO 수식에서 수정된 segment 부분에 대한 weight를 더 준게 전부임.
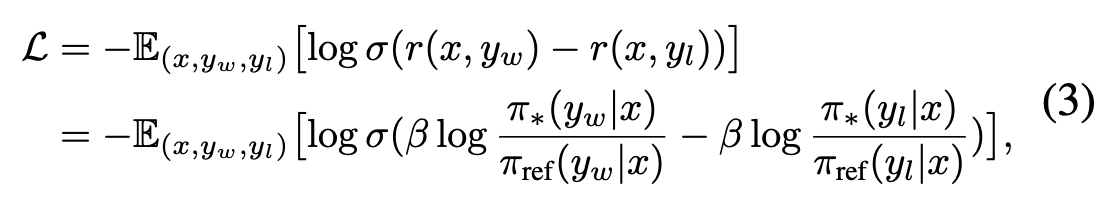
위 Eq. 3는 DPO 를 바탕으로 policy model 학습에 사용되는 objective function
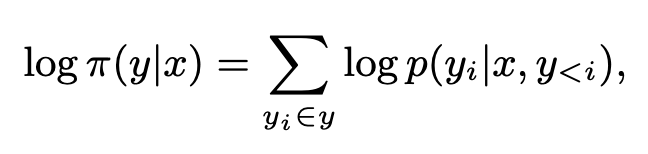
Eq 4. 는 model 학습에 기본적으로 사용되는 함수
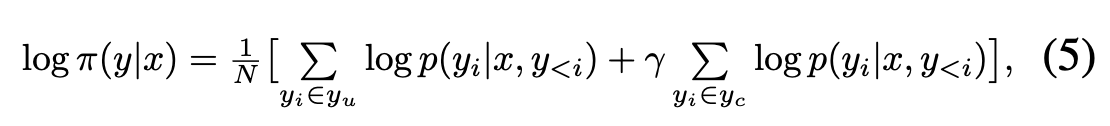
Eq 5. 가 저자들이 주장하는 DDPO 방식 는 unchanged segments를 나타내며 는 human annotator를 통해 변화된 부분의 segment. N 은 normalizing factor. (길이가 긴 응답에 좋은 score를 주는것을 방지하기 위한 목적)
Experiment