데이터셋 주소: https://github.com/ofirpress/self-ask/tree/main
prompt를 이용한(follow up~) - Compositionality gap해결.
Abstract, Introduction
본 저자는 언어모델이 답변을 만들어내기 위한 sub problem으로 질문의 구성요소 추론이가능한지 확인해보려 하였다. 해당 방식의 평가를 multi-hop questions로 진행. 답변은 multiple facts + answer로 구성.
Compositionality gap: 구성 추론 테스크에서 sub-problems들에 대한 answer의 정확도와 전반적인 solution generate 간의 퍼포먼스 차이
본 논문의 저자는 모델은 사이즈가 커져도 구성성 격차(Compositionality gap)이 존재한다 라고 주장. 이는 모델이 올바른 전체 솔루션에 도달하기 위해 여러 정보를 효과적으로 결합하는데 어려움이 있다는 것을 보인다.→ 모델 커진다고 여러 문장을 바탕으로 추론하는 능력은 하나의 QA를 수행하는 것과 대략 40%정도의 Compositionality gap 이 존재한다.
또한 언어모델을 기계적으로 다음단어를 암기하도록 학습되고, 추론에 능하지 못함. 또한 얼마나 대량의 데이터를 기억하는지 얼마나 추론능력이 좋아서 QA task를 수행하는지 명백하지 못하다.
본 저자는 해당 문제를 해결하기 위해 Self-ask prompt 를 제안하면서 CoT와 비교함. 또한 Bamboogle(2-hop questions, small)와, CC(Compositional Celebrities-similar to Musique and 2WikiMultiHopQA) 라는 데이터셋을 바탕으로 평가를 진행
Compositionality Gap
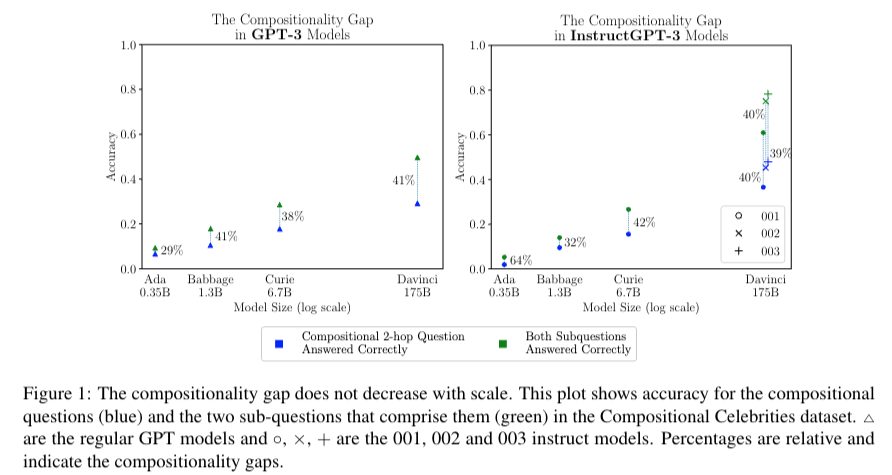
Compositional Celebrities (CC) dataset은 Compositionality Gap을 측정하기 위한 데이터 셋으로 2-hop questions로 구성되어 있다.
{"Q1": "What is the birthplace (country only) of Rumi?",
"A1": ["Afghanistan"],
"Q2": "What is the capital of Afghanistan?",
"A2": ["Kabul"],
"Question": "What is the capital of the birthplace of Rumi?",
"Answer": ["Kabul"], "birth_country": "Afghanistan",
"capital": ["Kabul"], "person": "Rumi",
"category": "birthplace_capital", "person_id": 0}기존 GPT의 경우 아래의 figure와 같이 Compositional 2-hop Question Answered Correctly 부분(위와같이 2-hop 상황에서 question에 대한 대답을 올바르게 했는지), Both Subquestitons Answered Correctly(하위 질문 Q1, Q2를 올바르게 답변했는지) 이 두개의 차이를 Compositionality Gap이라고 하며 대략적으로 40%가 지속됨을 보였다.
Self-ask, Experiment
두 차이를 줄이기 위해 본 저자는 Self-Ask prompt(논문에서 elicitive prompt)를 제시했다. 아래의 그림은 1-shot prompt 예시이다.

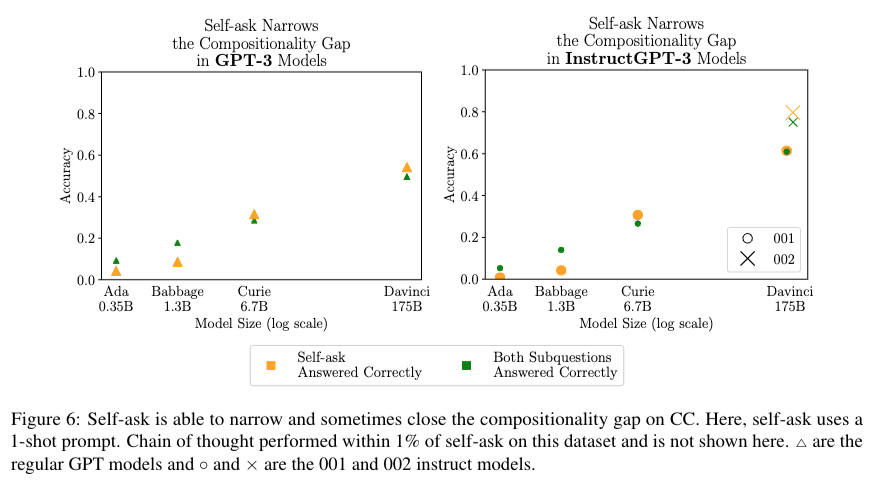
본 실험의 결과는 기존 Compositional 2-hop Question Answered Correctly 부분을 self-ask answered correctly 로 적용했을 때 Compositional Gatp이 줄어듬을 보였다.
위의 프롬프트에서 Follow up 부분 질문을 query로 넣고 반복적으로 answer을 생성하는 방식으로 검색엔진을 이용한 실험도 진행 했을 때의 결과이다.
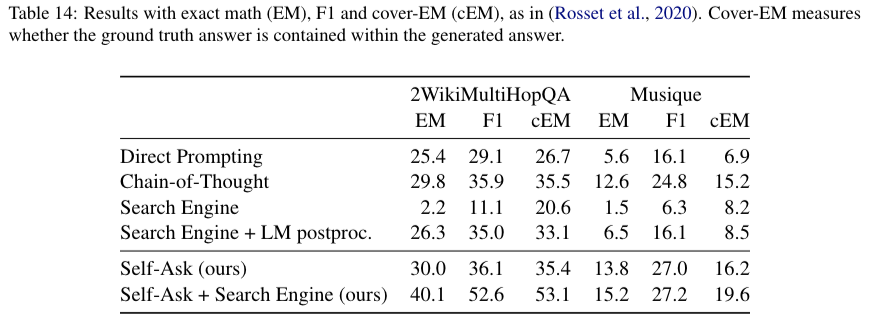

유용하네요