트랜스포머 구조를 이용한 고정된 길이의 한계점 → 더 긴 의존성을 이용할 수 있는 방법 제시
XLNet과 동일한 저자 작성.,, → Transformer-XL 많은부분 XLNet에서 이용
q 의미 : 입력 시퀀스에서 관련부분 찾기위한 벡터 (source)
k 의미 : 연관도 구하기위함. q와 비교하기위해 사용하는 벡터 (Target)
v 의미 : 특정 key에 해당하는 입력 시퀀스의 정보를 가중치로 구하는데 사용 (value)
Main Idea
- 이전 transformer 문제점 지적
세그먼트의 고정된 최대 길이 내에서만 학습이 이뤄지므로 해당 범위를 벗어나는 long-term dependency를 학습할 수 없다. 의미 단위로 나눈 것이 아닌 단순하게 연속적 symbol의 조각으로 구성 → 시그먼트의 처음 몇개의 symbol들을 예측하기에 정보양이 부족한 context fragmentation 문제가 발생한다.
고정된 윈도우 크기의 self-attention: 기존 Transformer의 self-attention 메커니즘은 입력 시퀀스 내에서 모든 단어 쌍에 대해 가중치를 계산하게 됩니다. 그러나 이 때, 메모리와 계산 리소스의 제약으로 인해 전체 시퀀스를 동시에 처리할 수 없어서 윈도우(window)라는 특정 범위 내에서만 처리할 수 있게 됩니다. 이 고정된 윈도우 크기로 인해 long-range dependences나 너무 멀리 떨어진 단어 간의 관계를 학습하기 어렵습니다.
불연속적인 문장 학습: 기존 Transformer는 각각의 미니배치를 독립적으로 처리하도록 구성되어 있습니다. 이러한 방식은 긴 문장의 경우 맥락의 연속성이 끊어지는 현상을 초래하며, 이전 미니배치의 정보가 다음 미니배치에 전달되지 않습니다. 결과적으로, 먼 거리의 의존성을 연결하거나 전체 맥락을 이해하는 것이 어려워 집니다.
Transformer XL
transformer 구조의 순환한 형태를 제시함 연속되 세그먼트 모델링 할 때, 각 세그먼트를 독립적 모델링 하는 것이 아닌 특정 세그먼트의 모델링에 이전 세그먼트의 정보를 이용하는 방법
→ 여러 세그먼트 사이의 의존성 파악 가능 및 고정된 길이의 의존성 문제 해결 가능
본 모델은 특정시점(t) 이전의 토큰이 주어졌을 때 t시점에 등장할 토큰을 auto regressive한 방식으로 나타낼 수 있고 p(x)의 분포를 추정한다.
-
t시점 이전의 정보들을 고정된 크기의 벡터로 만든다.
Transformer XL에서는 기존 Transformer 대비, 긴 시퀀스를 처리하기 위해 segment-level recurrence(세그먼트 수준의 순환)라는 개념을 도입. 이를 통해, 특정 시점(t) 이전의 정보들이 다음 시점에 전달될 수 있도록 한다. 이때의 고정된 크기의 벡터는 t 이전의 정보들을 요약하여 저장하는 역할을 한다.
-
이 벡터와 word embedding을 곱해 logit을 만든다.
각 단어의 word embedding과 고정된 크기의 이전 정보(벡터)를 결합해 다음 단어를 예측하기 위한 입력값으로 사용한다. 곱셈 결과로 logit이 생성되는데, logit은 각 토큰이 나타날 로그 확률로 간주할 수 있다.
-
softmax함수를 이용해 logit을 다음 단어에 대한 확률 분포로 만든다.
logit 값을 각 토큰에 대한 확률 분포로 변환하기 위해 softmax 함수를 적용한다. softmax는 logit 값을 0과 1 사이의 값으로 정규화하고 전체 합이 1이 되도록 만든다. 결과적으로, 예측된 다음 단어에 대한 확률 분포가 생성
Segment-Level Reccurence with State Reuse
학습이 진행되는 동안 각 세그먼트의 연산 결과들을 다음 세그먼트가 이용할 수 있도록 저장
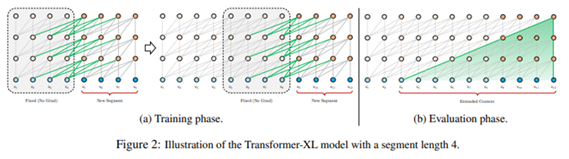
현재 세그먼트에서 모델링을 직전 세그먼트의 정보를 이용할 수 있다. → 즉 위 그림의 왼쪽 부분과 같이 하나의 시그먼트를 모델링 하기 위해 두 개의 연속된 세그먼트의 정보를 이용한다.
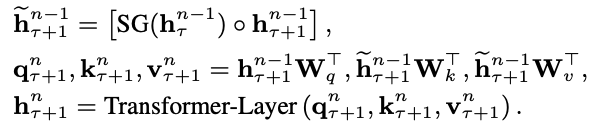
행렬식에서 SG는 stop-gradient를 의미하겨 [수식] 을 concat 시킨 형태이다. q, k, v 에서 q를 제외한 두 부분을 위의 concat 시킨 히든 스테이트 식과 dot product를 수행시키고 q는 남겨둔다. 이렇게 연산 후 다음 hidden-state를 구하는 연산을 진행한다. 아래의 식은 행렬 차원이 어떻게 구성되는지 나타낸 것이다.
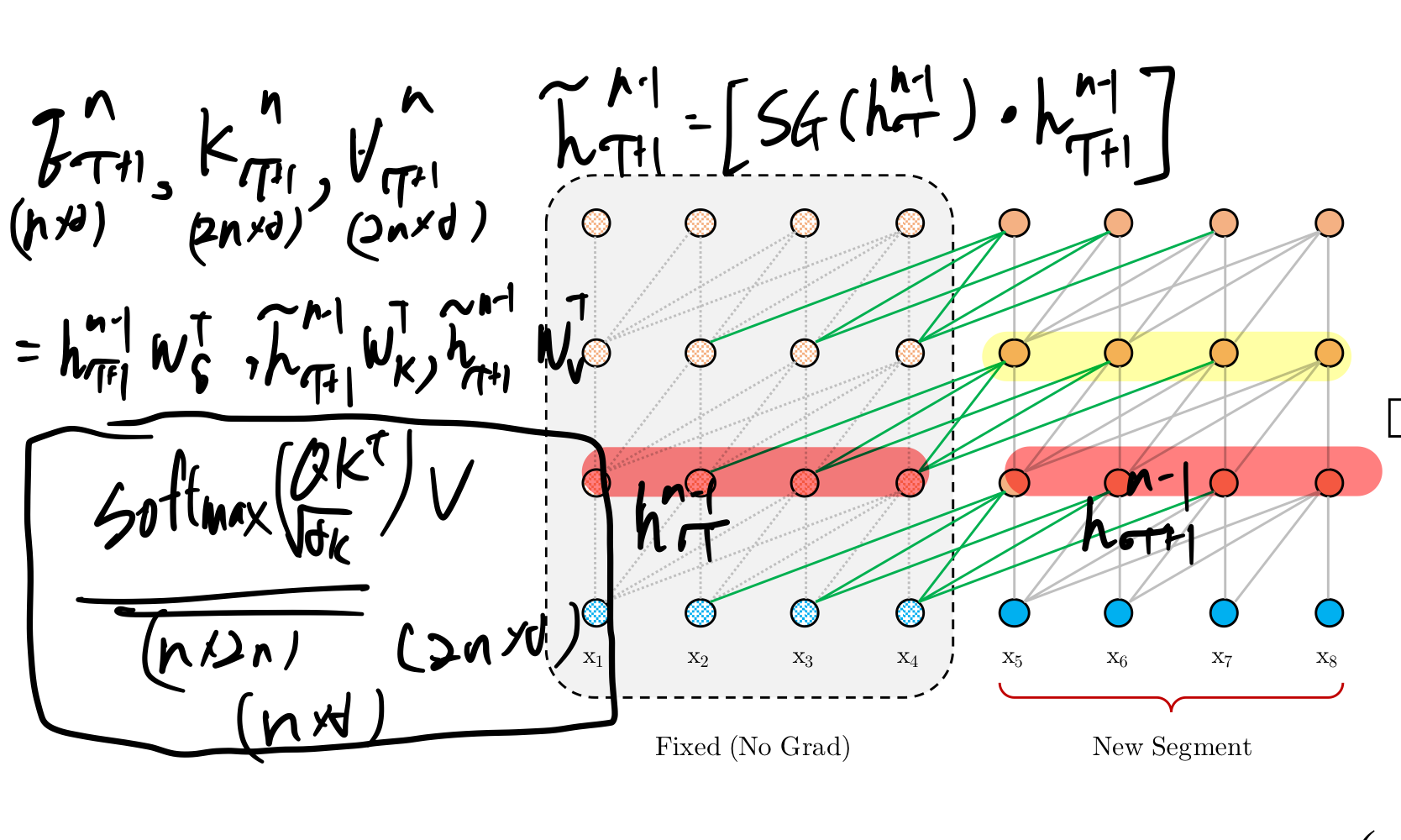
기존 RNN은 같은 hidden-state에서 순환했다면 해당 논문에서는 다른 state로 순환한다는 점이 다르다. 또한 GPU-RAM에 이전 cache를 저장시켜 빠른 연산이 가능하다고 설명한다.
transformer-xl 에서 abs PE 가 필요한 이유 : 다음 노드로 hidden state가 전달될 때 rel PE도 함께 전달되기 때문
Relative Positional Encodings
기존 transformer는 특정 위치의 토큰의 embedding을 계산할 때, 해당 토큰의 word embedding과 토큰위치의 positional encoding을 더해 각 위치마다 고유 embedding값을 갖는다.
→ 해결하기위해 토큰 간의 상대적인 거리를 이용한다. (저장된 hidden state를 사용해도 위치 정보가 유지된다.)


R이 'relative' 포지션 정보를 encoding한 matrix를 가리키며 기존에 쓰이던 U를 대체한다.
i, j 두 위치의 차이에 대한 포지션 정보를 담고 있다. 추가적으로 벡터 형태의 u, v 파라미터가 도입, 두 벡터는 query 단어의 위치와 상관없이 같은 값을 갖는다.(고정값)
Wk를 W_k,E와 W_k, R로 분리한다.
W_k,E는 token의 임베딩을 이용한 attention 계산에 쓰이고, W_k,R은 상대 위치 정보를 반영한 attention을 계산할 때 쓰인다.
(a) 컨텐츠 기반의 전달(addressing)
(b) 컨텐츠에 의존하는 positional bias
(c) 글로벌 컨텐츠에 대한 bias
(d) 글로벌 위치에 대한 bias
최종연산

전체적 알고리즘은 transformer와 동일하다.
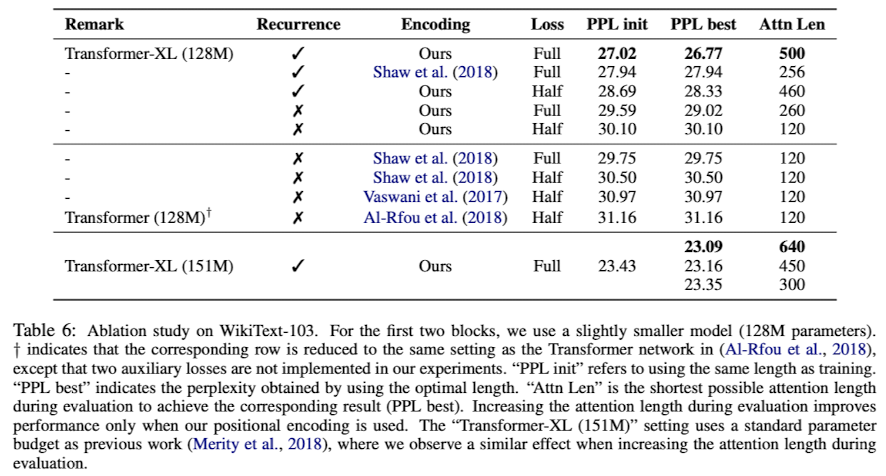
Ablation Study
REFERENCE
https://baekyeongmin.github.io/paper-review/transformer-xl-review/
