BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
논문리뷰

BART = BERT(Bidirectional encoding) + GPT(Auto-Regressive) = seq2seq,, 기존 트랜스포머 모델 구조와 동일, 여러 사전 학습 테스트에 대한 분석이 큼
1. Introduction
이전 bert에서는 mask되어 있는 문장 복원하는 MLM(Masked language model)과 denoising auto-encoder 방식을 사용했지만 한정된 분야에서 적용된다는 단점이 존재한다.
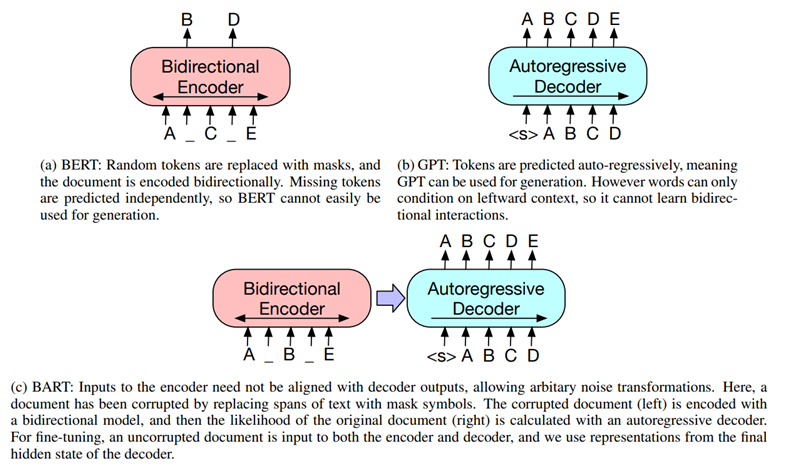
bert bidirectional encoder로 noise 된 token을 예측하는데 generation task 사용이 어렵다
GPT 는 autoregressive하게 다음 token을 예측해 generation에 사용 가능하지만 bidirectional 정보를 얻지 못한다.
bart의 경우 손상된 text를 입력으로 받아 bidirectional 모델로 인코딩하고, 정답 text에 대한 likelihood를 autoregressive 디코더로 계산한다.
이러한 설정은 noising이 자유롭다는 장점이 있다. → 논문에서 문장의 순서를 바꾸거나 임의 길이의 토큰을 하나의 mask로 바꾸는 등의 여러 noising 기법을 평가.
2. Model
2.1 Architecture
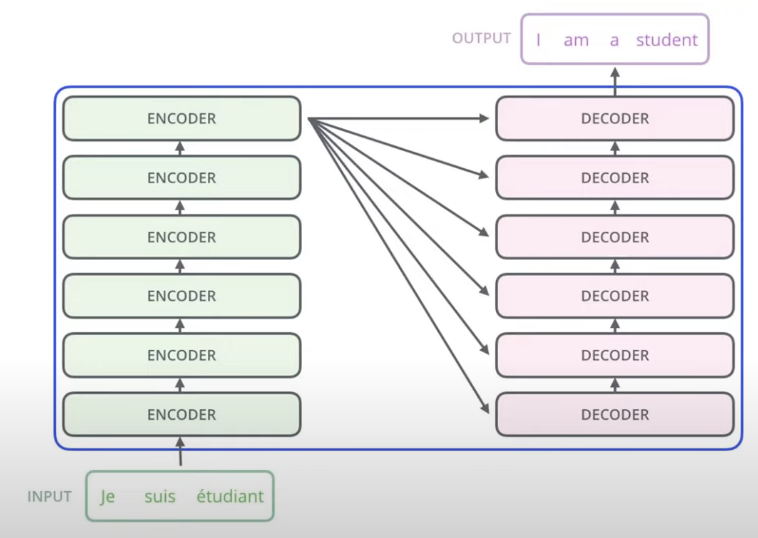
seq2seq 트랜스포머 구조, GeLU 사용, base model - 6Layer, Large model - 12 Layer. 디코더의 각 레이어에서 인코더의 마지막 hidden layer와 cross attention을 한다.
2.2 Pre-trained BART
BART는 손상된 text로 학습하는데 디코더의 출력과 원본 text의 loss를 줄이도록 한다. 다른 Auto-Encoder 모델과 다르게 모든 종류의 noise를 적용할 수 있다.
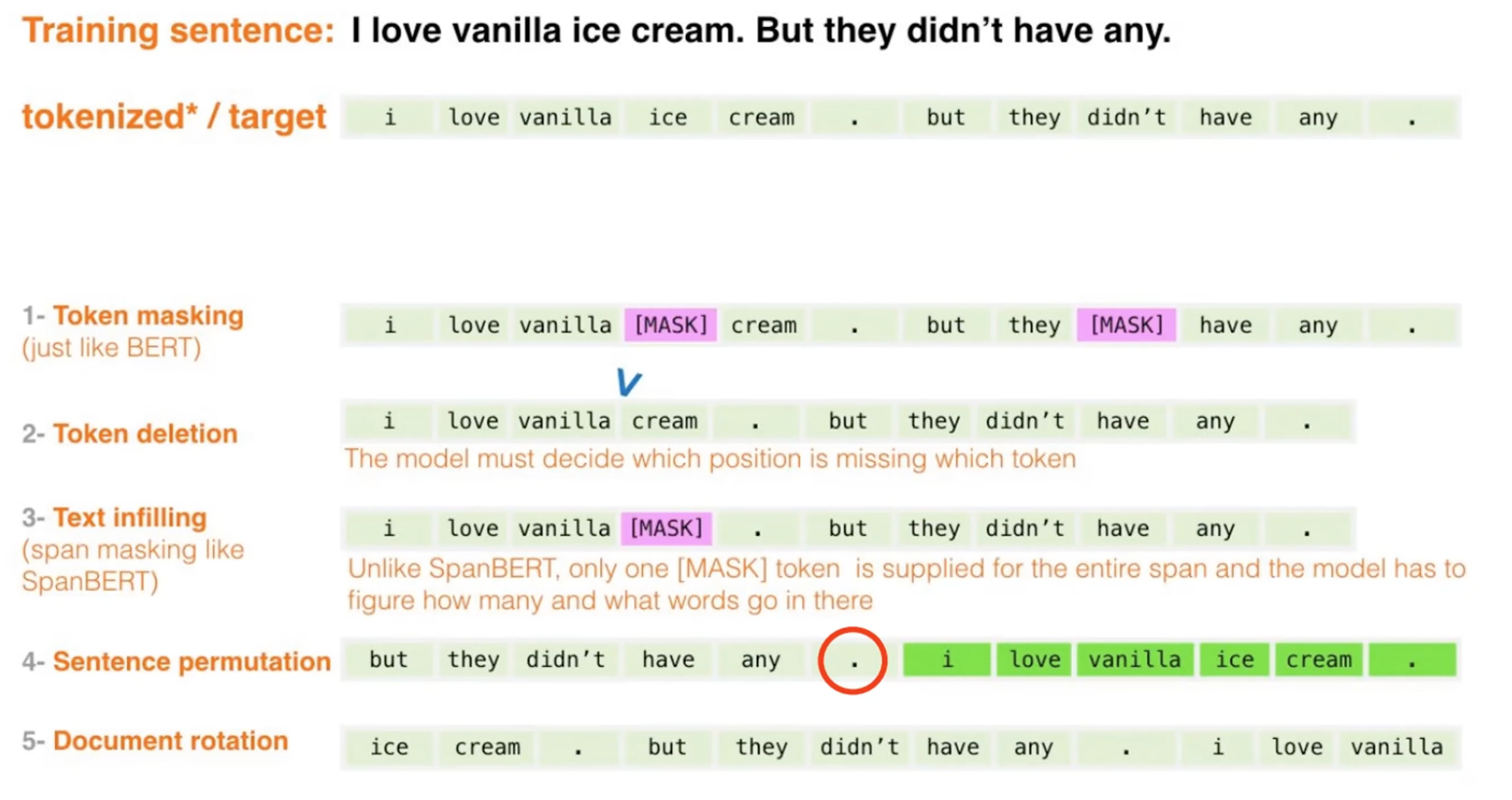
⇒ BART는 다양한 Token Masking, Token Deletion, Text Infilling, Sentence Permutation, Document Rotation 5가지의 사전학습방법을 사용했다.
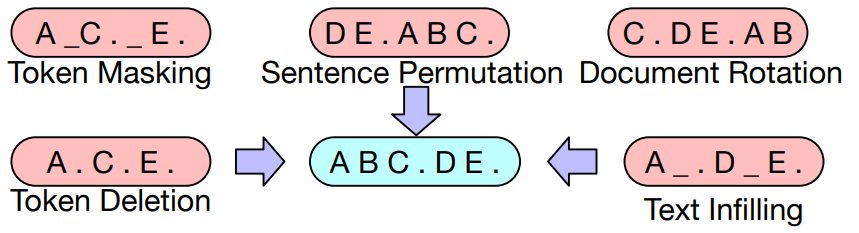
Token Masking
- 임의의 token을 [MASK]로 교체함
- BERT의 Masking을 따르기 때문에 input sequence는 유지
- [MASK] token이 무엇인지 예측해야 함
Token Deletion
- 임의의 token 삭제
- 삭제한 token의 위치를 찾아야함
Text Infilling
- Poissondist. 에서 span length를 뽑아 하나의 [MASK] token으로 대체
- span length가 0인 경우, 해당 [MASK] token을 추가함
- [MASK]로 대체된 token에 몇개의 token이 존재할지 예측해야 함
Sentence Permutation
- 문장의 순서를 랜덤으로 섞음
Document Rotation
- 하나의 token을 uniformly하게 뽑고, 그 토큰을 시작점으로 회전
- 모델이 문서의 start poing를 찾도록 학습
bart에서는 가장 좋은 노이즈 방법을 찾는것이 목적 → infilling 방식 사용
→ 로버타와 거의비슷하거나 좋은 성능을 보임
3. Fine-tuning BART
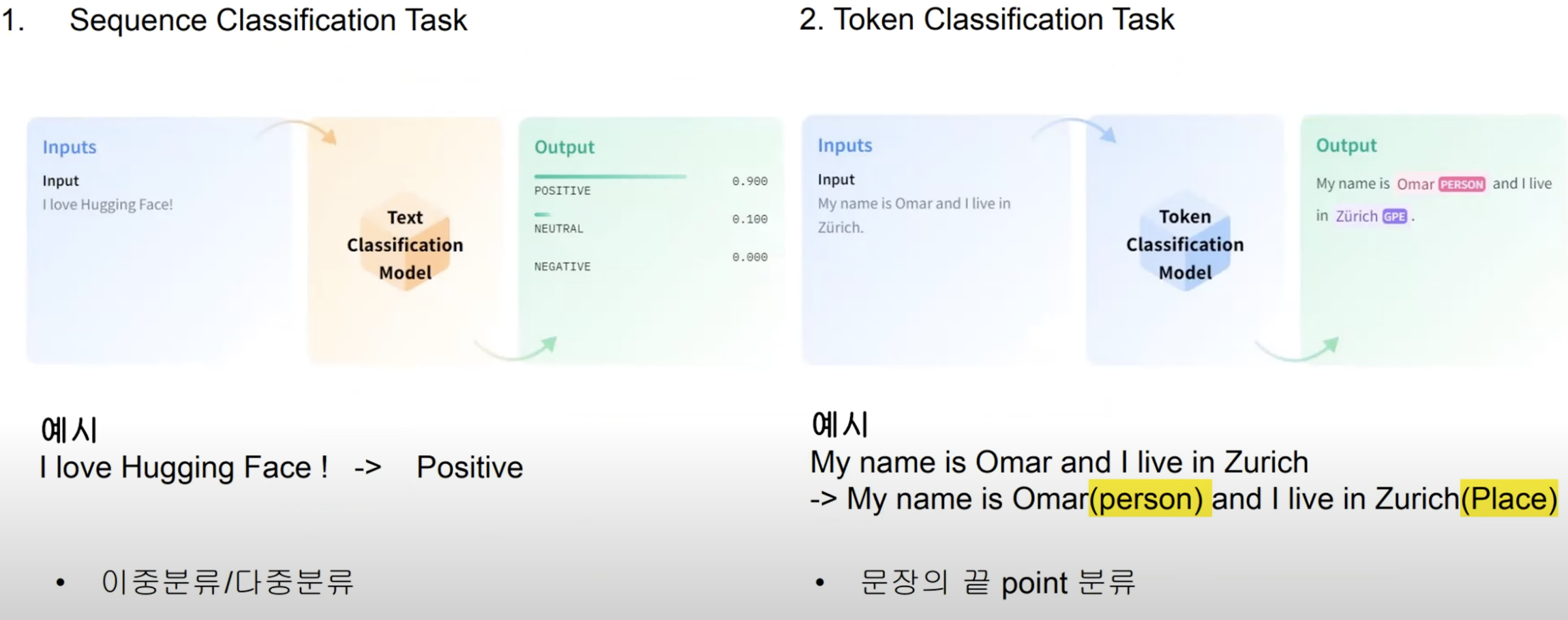
3.1 Sequence Classification Tasks
인코더, 디코더에 동일한 입력을 넣고 디코더의 마지막 토큰의 hidden state를 multi-class linear classifier에 넣고 분류를 진행.
3.2 Token Classification Tasks
인코더와 디코더에 사용하고, 디코더 맨 위 hidden state값을 사용해 각 단어에 대한 representation으로 사용하여 분류 수행
3.3 Sequence Generation Tasks

문서 요약 및 MRC(Machine reading comprehension) 을통한 QA 문장 생성 → 인코더에서 시퀀스 입력을 통해 자동으로 디코더 부분에서 문장 생성가능하다.
3.4 Machine Translation
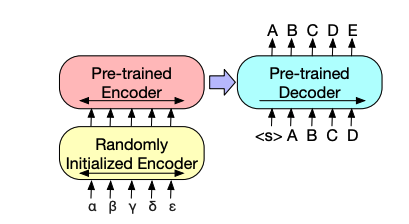
인코더 전 randomly initialized 인코더 추가해 embedding layer를 대체한다. +) 언어를 분리하는 용도로 사용된다.
학습은 먼저 randomly initialized encoder를 제외한 나머지는 freeze 시킨후 진행한다.
다음으로 적은수의 반복을 통해 미세조정을 진행한다.
다국어 to 영어로만 번역이 진행가능 ( pre-trained encoder, pre-trained decoder 가 모두 영어로 학습되었기 때문) → mbart, mt5 등이 생겨남
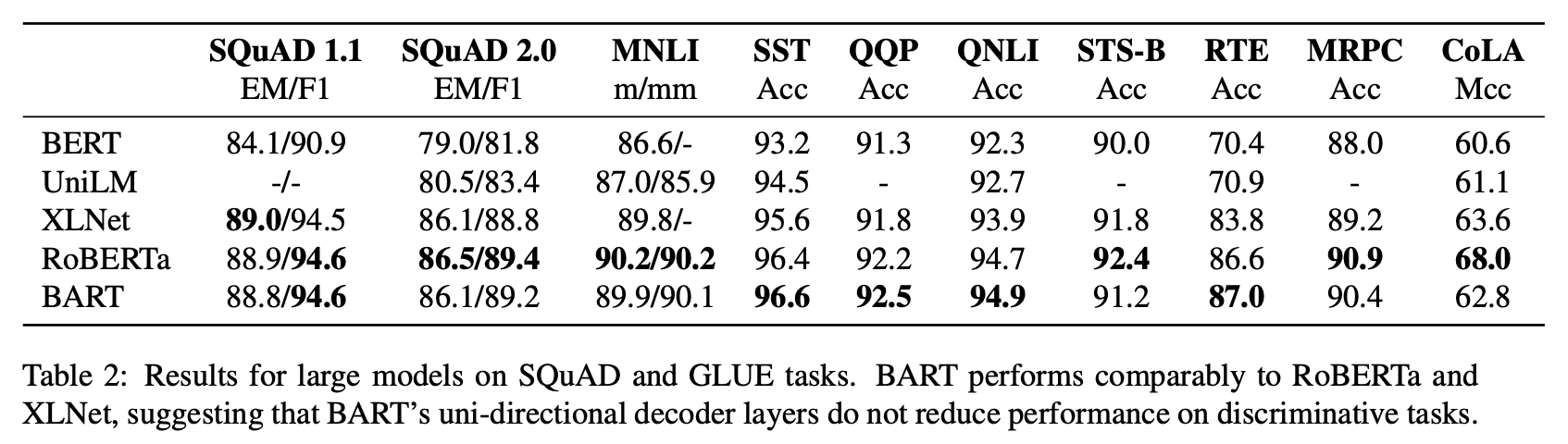
bart 논문의 목적은 다양한 노이즈 방법중에서 가장 좋은 노이징 방법을 찾는 것이 였고 아래 표에 나오듯이 text infilling 방식을 사용할 때 가장 좋은 수치가 나왔습니다.

아래는 text-infilling 방식으로 학습시킨 모델을 다른 모델들과 비교했을 때 RoBERTa와 비슷하거나 조금더 높은 점수를 나온다는 것을 확인할 수 있습니다.