본 논문은 decoding 을 통한 optimal result얻는 과정을 해결하고자 한다. 이를 위해 형식화 + future-constrained 방법을 통해 undesirable behavior 최소화 하려고 한다. 본 논문에서는 past generation에 집중하며 기존의 방식(greedy decoding, beam search nucleus sampling) 보다 output 전반을 잘 통제 가능하고 만족스러운 결과를 가져온다. future constraint satisfaction을 위해 scoring mechanism 을 소개했다. 이는 scoring을 통해 뚜렷하고 식별가능하다는 장점이 있다.
ABSTRACT, INTRODUCTION
최근 연구들에서 instruction tuning등을 통해 decoding에서 좋은 성능을 낼 수 있지만, instruciton과 일치하지 않는 결과가 나오기도 한다.이를 위해 다양한 decoding 방식이 개발되었는데 기존의 방식들은 future cost를 고려하지 않는다는 공통점이 ( future cost는 text generation이 길어질 때 생기는 computation 문제를 고려하지 않고 즉각적인 단어 선택이나 시퀀스 확장에 중점이 있다. ) 존재한다. 저자는 해당 decoding 방식중 formalizing을 통해서 해당 문제를 해결하고자 하였다. future constrained satisfaction (= distance) 를 사용하는 것은 NP-complete 문제 (computation 문제) 가 존재한다. 본 저자는 future constraint satisfaction을 추정하는 방식또한 제안한다.
Method
decoding 종류
- deterministic decoding methods: greedy decoding, beam search
- non-deterministic sampling methods: top-k, nucleus sampling, temperature sampling
본 논문은 deterministic decoding 방식에 집중을 하고있다.

는 language description (prompt)를 의미 - 여기에 toxical text 생성하지마록, ~~느낌으로 생성해 달라 는 input 과 같음
는 future constraint satisfaction score를 의미하고 likelihood를 바탕으로 평가한다.
본 논문에서는 constraint를 sub constraints로 분해하고 각각의 future constraint satisfaction score를 통합하는 방식을 진행. 이를 통해 output이 constraints에 잘 적용되었는지 전체적인 이해를 잘 유도할 수 있다.
Estimation of Future Constraint Satisfaction
아래의 수식은 estimate the future constrain satisfaction score of 이다. using the log-likelihood
token은 delimiting the two sequences
Inference
beam search와 nucleus sampling (top-p sampling) 은 left to right 형식으로 생성하는데 이는 suboptimal output이 나올 수 있다.
는 set of all sequences 를 의미하고 는 weight coefficient를 의미한다. R은 estimation satisfaction score for constraint 를 의미한다.
위의 수식 즉 전체 sequence에 대해 R값을 구해서 다음 토큰을 예측하는 것은 computation problem이 발생한다. 이를 완화 하기위해 top-k 개의 best candidate tokens을 설정했다.
는 candidate output space at position t를 의미한다. 는 top 2 * k 개로 갯수로 설정 (R을 통해서 나온 영향도로 top5 개중에서만 보는 것이 아닌 10개를 후보 tokens로 놓는다. ) 본 저자는 라는 또다를 토큰 셋도 제안했다. 이는 keywords에서 찾아진 토큰으로 구성된 token set이다.
해당 과정을 디코딩 과정을 진행할때 반복적으로 한다.
EXPERIMENT
3개의 다른 테스크에 대해 실험을 진행함. 1) keyword constrained generation, 2) toxicity reduction, 3) factual correctness
Keyword-constrained generation
CommonGen dataset을 이용해서 어휘적 constrained가 있는지 집중함. metrics - BLEU, CIDER, constraint coverage score (coverage score은 제공된 instruct를 얼마나 잘 이해한 형태의 output이 나오는지 측정하는 metric,, 주요 개념이나 정보가 출력 문서에 포함되었는지를 평가) .
본 저자는 본인들이 만든 스코어가 의미가 있다는걸 증명하기 위해 각 테스크에 대해 ranking score를 측정하였다.
a: set of CommonGen, b: generated by chatGPT
→ Ranking Acc score of 1 if else 0
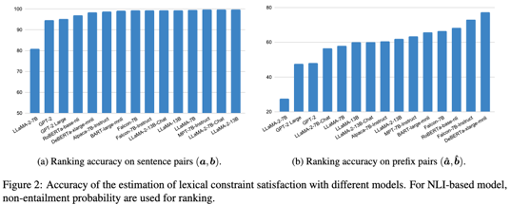
figure2에 (a)는 본 저자들의 future constraint satisfaction score 가 유의미한 auxiliary decoding term인지 보기위한 평가 방식의 결과이다. (b) 는 추정값으로 표현했는데 마지막 텀을 삭제하고 기존에 있는 text에서 랜덤으로 선택해서 넣었다고하는데 어떤 의도로 했는지는 잘 모르겠다.
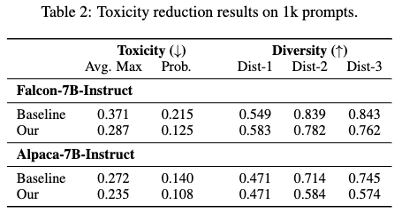
toxicity reduction
REAL TOSICITY POMRPTS benchmark에서 toxicity (human evaluation), diversity (n-gram) 을 이용해서 평가를 진행하였다.
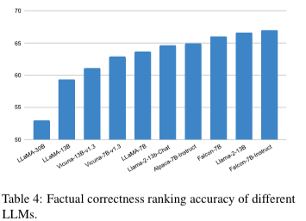
factual correctness
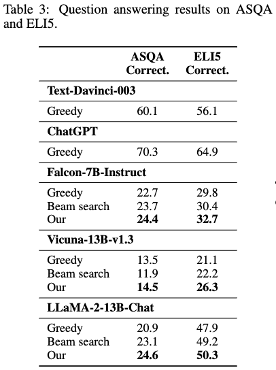
ALCE, ASQA, QAMPARI, ELI5 데이터셋을 바탕으로 fluency, correctness, citation quality 측정을 진행하였다.
FEVER, VitaminC 를 이용해 constraint satisfaction 추정이 타당한 방식인지를 평가를 진행했다.
a는 support evidence, b는 does not support evidence로 두고, 1 if R(a, C) > R(b, C) else 0 의 평가방식을 사용했다. 아래의 table은 본 저자들의 방식이 유의미하다는 것을 보여준 것이다.