ABSTRACT, INTRODUCTION
본 논문은 LLM이 외부지식을 수용할 때 내부에 저장된 지식과 충돌하거나 같은 경우에 어떻게 수용하는지에 대한 논문이다. 논문에서는 외부지식이 일관성 있고 확실한 말을 할때 내부지식과 상반되는관점을 가져도 받아드리게 된다고한다. 반면, 외부지식과 내부지식이 같을 때는 강한 확증편향을 갖게된다고 한다.
LLM은 내부 파라미터의 메모리와 충돌할 때 외부 증거가 유일한 증거인 경우 외부 지식을 매우 수용하는 경향또한 나온다.
만약 LLM내부 지식에 지지적 증거와 모순된 증가가 모두 있는 경우 내부 지식에 집착하는 경향이 있으며 이는 LLM이 여러가지 상충된 증거를 편견 없이 조율하는데 잠재적 어려움이 존재한다는 것을 알 수 있다. 이는 생성형 검색엔진에서 흔히 발생하는 상황이다.
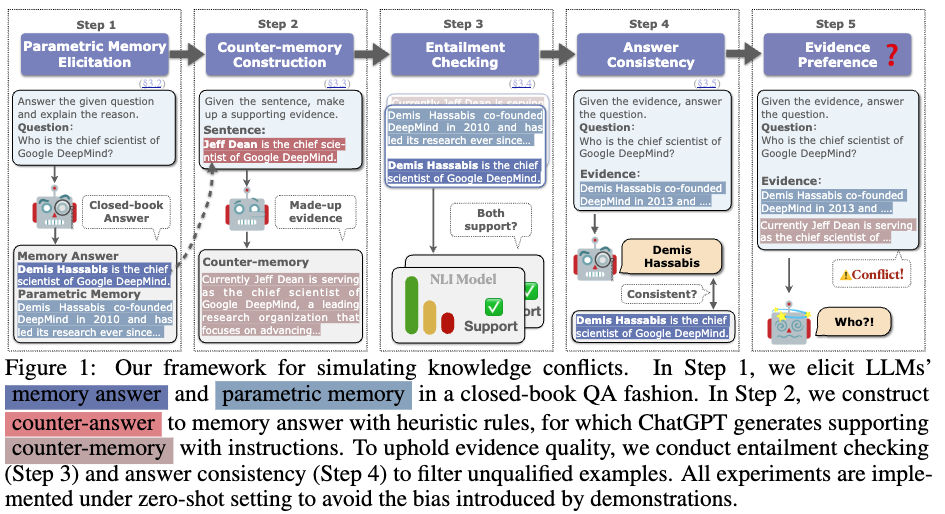
추가적인 정보를 바탕으로 지지적 증거 (parametric memory)와 모순된 증거 (counter-memory)를 만드는 과정
step1) model을 바탕으로 지지적증거를 만드는 과정
step2) 임의로 memory answer를 바꾸어 모순되는 answer (counter-answer)를 만들고 이를바탕으로 모순된 증거 (counter-memory) 를 만들어준다.
step3) 해당 부분이 잘 만들어졌는지 확인하기위해서 NLI task를 진행. memory answer이 parametric memory과 entail 한지 판단진행 → encoder model을 사용했고 99% 정확도가 나옴
step4) Concsistency를 확인하기위해 모델별로 일관성있는 대답을 하는지 figure 1의 step4와같은 형태로 input을 넣어주고 확인함. 이때 Consistency와 entail을 통과한 evidence를 데이터셋으로 만들어냈다.
step5) 실험 부분
아래 table은 final dataset이 만들어진 형태

EXPERIMENT
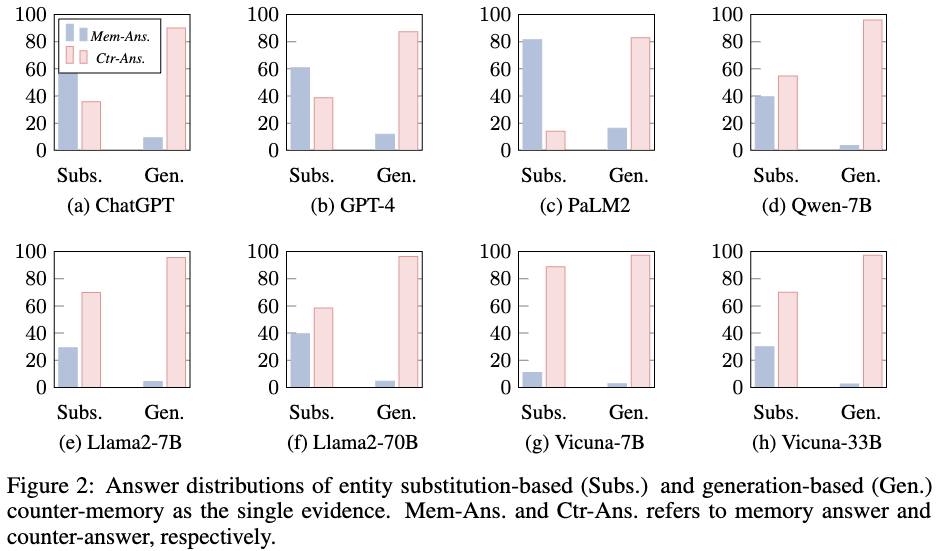
figure 2에서
Subs는 instruct model fine-tuning (X), 일관성있게 대답하는 지시 prompt (X)
Gen은 instruct model fine-tuning (O), 일관성있게 대답하는 지시 prompt (O)
이렇게 나온 결과에서 상대적으로 작은 모델들은 Subs결과에서 내부 파라미터 정보를 이용하지 않고 주어진 정보를 바탕으로 대답을 하는 경향이 존재한다. 반대로 큰 모델의 경우 잘못된 evidence를 넣어줘도 모델 내부 파라미터를 근거로 해서 올바른 답변을 생성하는 경향이 존재한다.
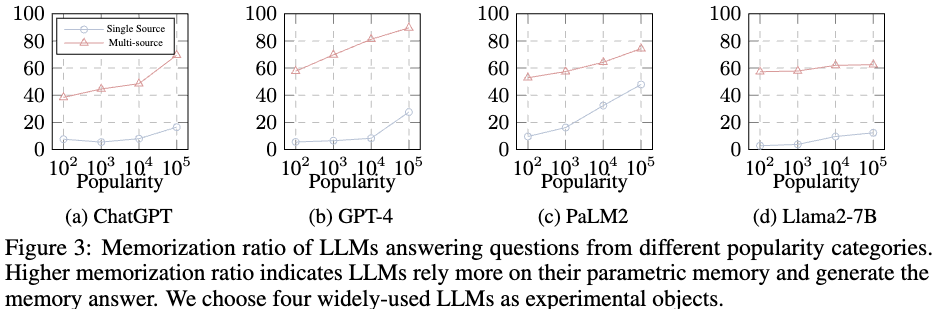
figure3 은 Memorization ratio를 바탕으로 답변을 생성했을 때 다양한 source를 주는 경우와 하나의 source를 주는 경우로 얼마나 유명한 데이터냐에 따라서 model의 Memorization ratio가 어떻게 변하는가를 본 결과이다.
해석:
1) single source, multi source 모두 유명한 내용일 수록 내부 파라미터에 저장된 정보를 더 많이 사용하는 경향이 존재한다.
2) multi evidence 가 주어졌을 때는 내부 파라미터의 정보를 더 많이 사용하고, single evidence가 주어졌을 때는 주어진 정보를 더 많이 사용하는 결과가 나온다.
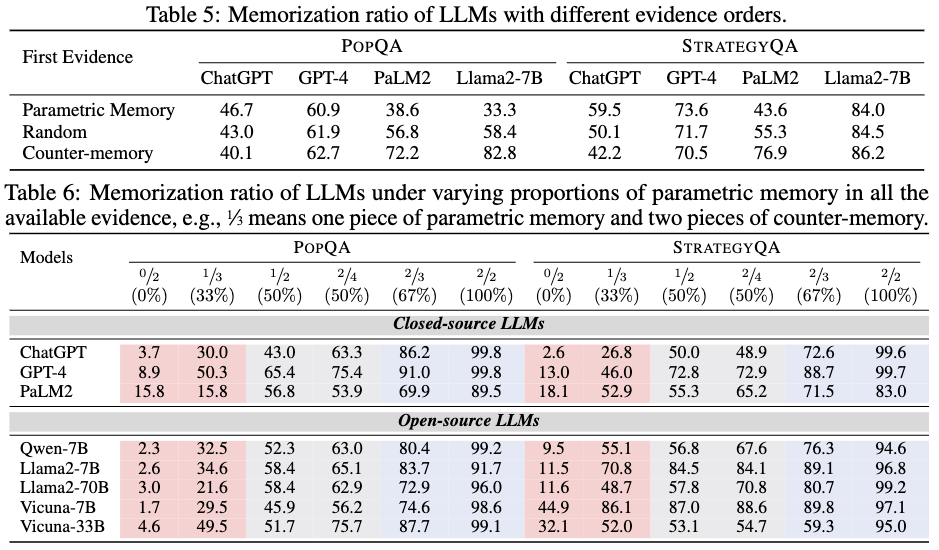
table5에서는 evidence의 순서에 따라서 어떤 결과가 나오는지 나타낸 실험이다.
위 table6에서는 내부 파라미터를 지지하는 evidence와 모순되는 evidence의 비율을 다르게해 모델에 넣을 때 Memorization ratio를 나타낸 것이다.
해석:
1) 모델은 evidence order에 민감하다.
2) LLMs 더 많은 evidence가 있는 쪽을 따라간다.
3) LLMs 은 관련없는 evidence의 방해에 취약하다.
