DA란?
Domain Adaptation과 Finetuning은 다른 개념이다.
Pre-trained 모델을 특정 분야(Domain)에 적합한 모델로 개선하기 위한 과정을 Domain Adaptation이라 한다. 종종 Domain Adaptation을 Further pre-training이라는 용어로 사용하기도 하는데, Domain Adaptation을 수행하는 방법이 Pre-trained model을 학습하는 방법과 동일하므로 Pre-training을 지속한다는 의미에서 이러한 용어를 사용하고 있다.
Domain Adaptation과 fine-tunning의 목적 및 방법에는 명확한 차이가 있다. 하지만 많은 사람들이 Domain Adaptation을 fine-tuning의 세부 범주로 이해하는 경향이 있다. Domain Adaptation은 특정 Domain에서 자주 사용하는 용어를 pre-trained model에 학습하는 방법이다. 반면 Fine-tuning은 text classification, NLI, Q&A등 Downstream task를 모델에 부여하는 방법이다.
fine-tuning의 범위는 어디까지일까?
일반적으로 Fine-tuning을 하는 행위는 Pre-trained Language Model(PLM)을 text classification, sentiment analysis와 같은 Downstream task를 수행할 수 있도록 훈련시키는 과정을 의미한다. 하지만 Fine-tuning에 대해 찾다보면 알고있는 방법과 다른 Fine-tuning 방법이 있는 것 같다는 느낌을 지우기 어렵다. 일반적으로 PLM을 활용해 데이터를 학습시키는 방법 전부를 fine-tuning한다고 간주하는 경향이 있는 것 같다. 그러다보니 Domain Adaptation 또한 Fine-tuning 방법으로 간주 되곤 한다.
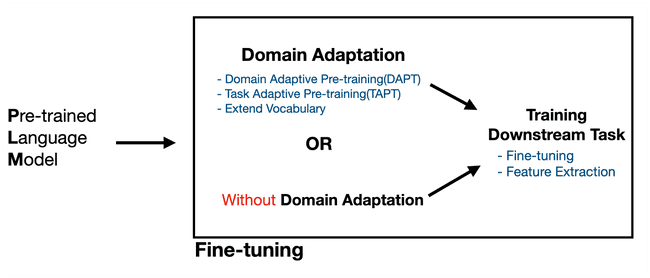
많은 경우 검은색 네모 박스 쳐져있는 영역을 Fine-tuning의 영억으로 판단하는 것 같다. 원래의 Fine-tuning은 Downstream task를 부여하는 방법이지만, Fine-tuning에 앞서 진행하는 Domain Adaptation(=Further pre-training) 또한 fine-tuning의 범주로 이해되고 있다.
Domain Adaptation은 선택사항
위 그림에서 볼 수 있듯 Further pre-training은 필수가 아니다. 해결하려는 문제의 domain이 전문 영역인 경우 관련 용어 학습을 위해 Further Pre-training을 권하지만, 학습에 필요한 domain 관련 corpus를 확보하지 못하거나, 일반 분야의 문제 해결 이라면 해당 과정을 생략하고 Downstream task 학습으로 넘어가도 무방하다.
Domain Adaptation 관련 용어 정리
지금까지 자료를 통해 이해한바로는 2020년에 발행된 Don't Stop Pre-training. Adaptive Language Models to Domains and Tasks이라는 논문이 나오기 전까지는 Further Pre-training이 곧 Domain Adaptation을 의미했다. 해당 논문에서 Task Adaptive Pre-training(TAPT)이라는 개념을 새로 소개하면서 Domain Adaptation을 Domain Adaptive Pre-training(DAPT)로 통일했고, 현재는 Domian Adaptation을 DAPT를 혼용해서 사용하고 있다.
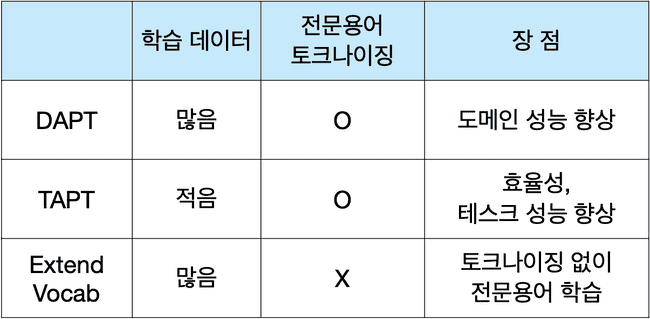
일반적인 경우 Domain Adaptation, Domain Adaptive Pre-training(DAPT), Further Pre-training, MLM fine-tuning은 모두 같은 방법을 의미한다. Domain Adaptation에는 TAPT나 Extend Vocab 방법도 존재하지만 흔히 활용하지 않는 방법이다. 그렇지만 TAPT는 효율성면에서 장점이 있고, Extend Vocab은 Vocab에 단어를 넣고 학습한다는 점에서 장점이 있다.
Further Pre-training이 가능한 이유: Subword embedding
Further Pre-training이 가능한 이유는 Bert 학습이 Subword 방식으로 이루어졌기 때문이다. Subword embedding은 Word Embedding에서 발생하는 OOV(Out of Vocabulary) 문제를 해결하기 위해 제안된 방식이다.
NLP 모델을 학습하기 위해서는 학습에 사용되는 데이터에서 단어집(Vocab)을 추출해야한다. 이렇게 추출된 단어집(Vocab)은 문장들을 단어로 분리하고, 이를 숫자로 encoding하는 과정에 활용된다. 이러한 특성상 Word embedding 방식은 단어집(Vocab)에 없는 단어의 경우 해당 단어를 UNK으로 토크나이징 한다.
이를 Out of Vocabulary(OOV) 라 하는데, 이를 해결하기 위해서는 단어집(Vocab)이 무수히 커져야 한다. 하지만 단어수가 증감함에 따라 필요한 연산 수도 증가하기도 하고, 이 방법으로는 끊임없이 변형되는 언어의 변화에 대처하는데에는 한계가 있다.
이러한 Word embedding 방식의 문제(OOV 문제)를 해결하기 위한 방법으로 Subword embedding을 사용한다. Subword embedding의 경우 단어를 한번 더 토크나이징하여 학습하는 특징이 있다. 단어집(Vocab)에 없는 단어라 할지라도 하위 단어의 조합을 통해 단어를 생성할 수 있어 OOV를 해결할 수 있다. 예로들어 '왼손', '왼편'은 '왼'과 '손', '편'의 합성이므로 '왼','-손','-편' 세 단어가 단어집(Vocab)에 있으면 '왼손', '왼편'을 단어집(Vocab)에 넣지 않아도 토크나이징 가능하다. 만약 '쪽'이라는 단어가 단어집(Vocab)에 없더라도 'ㅉ','ㅗ','ㄱ'으로 토크나이징을 수행하므로 어떠한 경우라도 OOV문제를 해결할 수 있게되는 것이다.
그 결과, 이러한 Subword의 장점으로 인해 단어집(Vocab)에 없는 단어라도 학습 가능해졌고 학습이 마무리된 모델에 대해서도 재학습이 가능해졌다.
Domain Adaptation 방법
Domain Adaptation은 학습을 이어나가는 방법이므로 PLM을 초기 학습시키는 과정과 동일하다. 대신 BERT는 초기학습 시 NSP(Next Sentence Prediction)와 MLM(Masked-Language Modeling) 학습을 필요로 하는데 반해, Domain Adaptation에서는 MLM만 수행하거나 또는 NSP만 수행할 수 있다.
Domain Adaptation을 수행하는 방법은 모델을 새롭게 학습할 때의 방식과 동일하다. 그러므로 PLM 학습에 활용된 Tokenizer를 불러와 활용해야한다. 임의로 Tokenizer를 만들거나 다른 모델 학습에 활용된 Tokenizer를 사용하면 단어별 맵핑된 정수가 다르기 때문에 전혀 다른 학습을 하게 된다.
DAPT, TAPT, Extend Vocab 차이
DAPT와 TAPT
용어의 유사성에서 보듯 DAPT와 TAPT의 차이는 domain과 task의 차이에서 비롯한다. domain은 Pre-train 수준의 방대한 학습, task는 Fine-tuning 수준의 효율적인 학습을 수행한다. 데이터 크기를 보면 두 방법의 차이를 느낄 수 있는데, DAPT로 학습하면 40GB 수준의 방대한 corpus를 활용하고 TAPT는 Fine-tunning을 위해 사용되는 데이터로 약 80kb 수준의 몇만건 정도 되는 데이터를 학습한다.
학습 데이터 크기만 보더라도 효율면에 있어서 Task Adaptive가 압도적임을 알 수 있다. 성능면에서도 효율 대비 성능이 좋다고 한다. 다만 task 특화된 사전학습 방법이므로 A task용 데이터로 학습한 모델에 B task를 부여하면 성능향상이 거의 없다고 한다. 이는 Text Classification에 필요한 학습 데이터와 Sentiment Analysis에 필요한 학습 데이터가 기본적으로 다르다는 점을 고려하면 이해 가능한 결과이다.
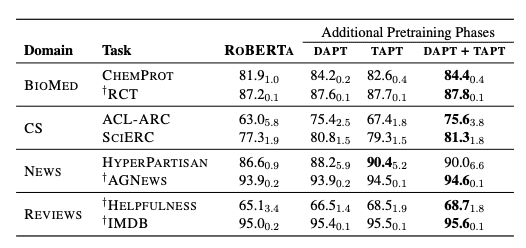
위의 표는 일반 모델(RoBERTa)과 DAPT, TAPT, DAPT+TAPT(DAPT 수행 후 TAPT를 수행한 모델)dml Downstream task에서의 성능 차이를 보여준다. 표를 통해 알 수 있는 사실은
- 어떤 방법이든 일반 모델보다 더 나은 성능을 보장한다.
- 거의 모든 task에서 DAPT+TAPT 성능이 우수하다.
- TAPT는 매우 효율적인 방법이다.(일부 task에서는 DAPT 보다 나은 성능을 보임)
특히 1번의 경우 모델의 Parameter가 커지고 학습량 또한 급증하는 추세임에도 Domain Adaptation이 여전히 효과적인 성능향상 방법임을 나타낸다.
DAPT와 Extend Vocab
Extend Vocab은 전문용어를 Tokenizing하지 않고 그대로 학습하기 위한 방법이다. 새롭게 추가하는 단어가 적은 경우 기존 Vocab에 추가해 학습하는 방법을 사용하고, 추가해야할 단어가 많은 경우 새로운 Vocab을 생성한 뒤 기존 Vocab과 Module로 연계하여 학습하는 방법을 사용한다.
추가할 단어가 적은 경우(Vocab 대비 최대 1%) How to add a domain-specific Vocabulary (new tokens) to a subword tokenizer already trained
단어 개수가 많은 경우 다음의 논문을 참고하여 학습 가능하다. exBERT: Extending Pre-trained Models with Domain-specific Vocabulary Under Constrained Training Resources
Pre-training from Scratch과 Further Pre-training
domain에 특화된 모델. 전문용어를 subword로 나눠서 학습하고 싶지 않은 경우, domain에 맞게 새로운 모델을 제작하는 방법. 실제로 많은 기업에서 자신의 domain에 특화된 PLM을 만들어 사용하는데, 해당 domain을 처음부터 학습시킬 수 있는 충분한 데이터가 축적되었고 이를 만들 수 있는 충분한 역량이 있거나, 특정 용어가 subword로 토크나이징 된 후 학습되는 것을 방지하기 위해 이 방법을 선택한다.
ex) 화장품 어플 '화해'
하지만 Vocab에 전문용어를 넣지 않아도 되는 경우 Domain Adaptation이 보다 효과적인 선택지가 될 수 있다. DAPT가 오히려 성능면에서 더 우수한 결과를 보인다는 논문 결과도 있으며, 비용면에서도 저렴한 방법이기 때문이다.
Domain을 위한 Language Model further Pre-training(Data Rabbit 블로그)
케이스
- 금융 Domain, FinBERT (2019)https://arxiv.org/abs/1908.10063
- 텍스트북 별 Domain적용(채점 문제), 별칭없음 BERT - (2019)https://www.aclweb.org/anthology/D19-1628/
- 법률, LEGAL-BERT (2020)https://arxiv.org/abs/2010.02559
- 그외 외 논문들에서 relative works에 참고된 것들
- BioBERT (2019)
- SciBERT (2019)
- Clinical BioBERT (2019)
위 BERT들 모두 다 further Pre-training 방식임. 아무도 pre training from scratch 하지 않음
결론
- Full Pre-training보다는 further Pre-training으로 Domain을 보다 효율적으로 주입. 그래서 대부분 further Pre-training을 함
- Further Pre-training은 domain knowledge를 LM(Language Model)에 부여하는 효과를 봄
복잡한 task일 수록 더 큰 효과를 봄 Binary classification < Multi label classification < Question & Answer- Domain을 한정 할 수록 한정된 Domain의 문제에서 더 큰 효과를 봄
- 작은 사이즈의 BERT 모델을 기반으로 Domain을 추가 학습한 경우가 풀 사이즈의 기본 BERT와 - - Domain 특정지어지는 문제에서의 성능은 비슷하지만 더 가볍기 때문에 효율적임
