Word embedding vs Contextual embedding
word embedding 발전 역사
https://velog.io/@tobigs-text1314/CS224n-Lecture-13-Contextual-Word-Embeddings
Contextual embedding의 등장
부제) attention 매커니즘의 등장
Traditional word embedding 방식은, fixed vocabulary가 있고 각 vocabulary마다 학습된 word embedding이 있는 형태다.
마치 사전처럼 각 단어마다 그 단어의 word embedding이 있어서 원하는 단어의 index만 알면, 그 단어의 word embedding을 가지고 올 수 있다. 반면, 이 단어의 word embedding은 항상 고정된 상태로(static) 바뀌지 않는다. 문제는 동음이의어의 단어를 embedding 할 때이다.
Sentence 1: The mouse ran away, sqeuaking with fear.
Sentence 2: Click the left mouse button twice to highlight the program.
위와 같은 문장에서 두 개의 mouse는 정확히 똑같은 embedding을 사용한다. 이 한계를 극복하는 모델이 바로 contextual embedding이다. Elmo나 BERT, GPT 등이 이런 embedding을 사용하는 대표적인 모델이다. contextual embedding은 input이 문장 전체이고, 문장 전체가 주어지면 그에 따라 다른 embedding을 output한다. 아무래도 Transformer에 있는 self-attention 때문에 그렇게 되는게 아닐까 싶은데 어쨌든 이 경우, 같은 단어라 할지라도 어떤 문장에서 등장하냐에 따라서 다른 embedding이 주어진다.
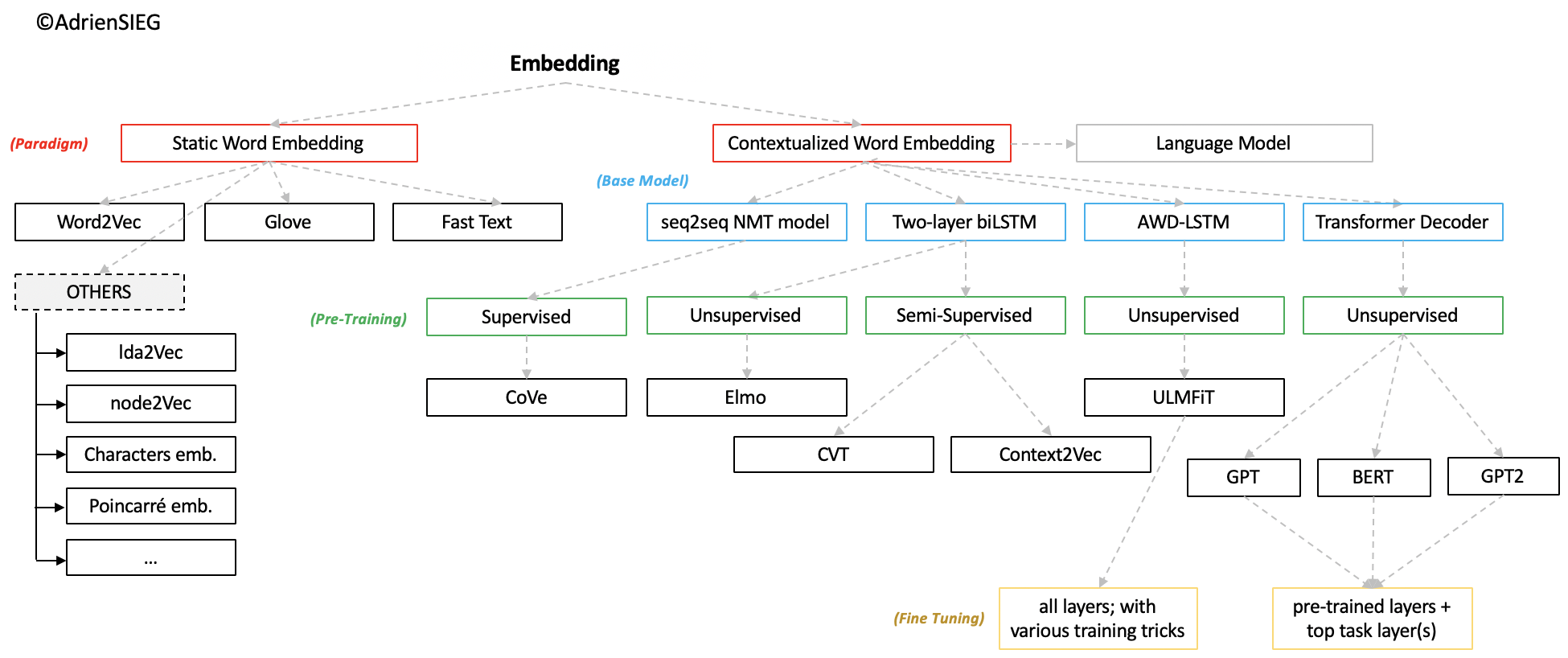
Static Word embedding
- Skip-Gram & CBOW
- Glove
- fastText
- Exoticd: Lda2Vec, Node2Vec, Characters Embeddings, CNN embeddings,...
Contextualized(Dynamic) Word Embedding(LM)
- CoVe(Contextualized Word-Embeddings)
- CVT(Crss-View Training)
- ELMO(Embeddings from Language Model)
- ULMFiT(Universal Language Model Fine-tunning)
- BERT(Bidirectional Encoder Representations from Transformers)
- GPT & GPT-2(Generative Pre-Training)
- Transformer XL(meaning extra long)
- XLNet(Generalized Autoregressive Pre-training)
- ENRIE(Enhanced Representation through kNowledge IntEgration)
- FlariEmbeddings(Contextual String Embeddings for Sequence Labelling)
