1. Linear Regression
2. Ridge Regression
둘이 어떻게 연관이 되는 것일까,,
우선 Ridge Regression의 objective는 model의 overfitting을 막는 것.
어떻게?
우선 model의 overfitting이 왜 일어나는지 살펴보자.
1) When the number of parameters is large(parameter 수가 많을 경우)
- The funciton approximation focuses on memorizing training data rather than extracting patters
2) train set이 적을 경우
3) When the magnitude of parameters is large(가중치들이 넓은 범위의 값을 갖을 경우)
=> 이 상황을 제어함으로써 overfitting 방지 = Ridge Regression
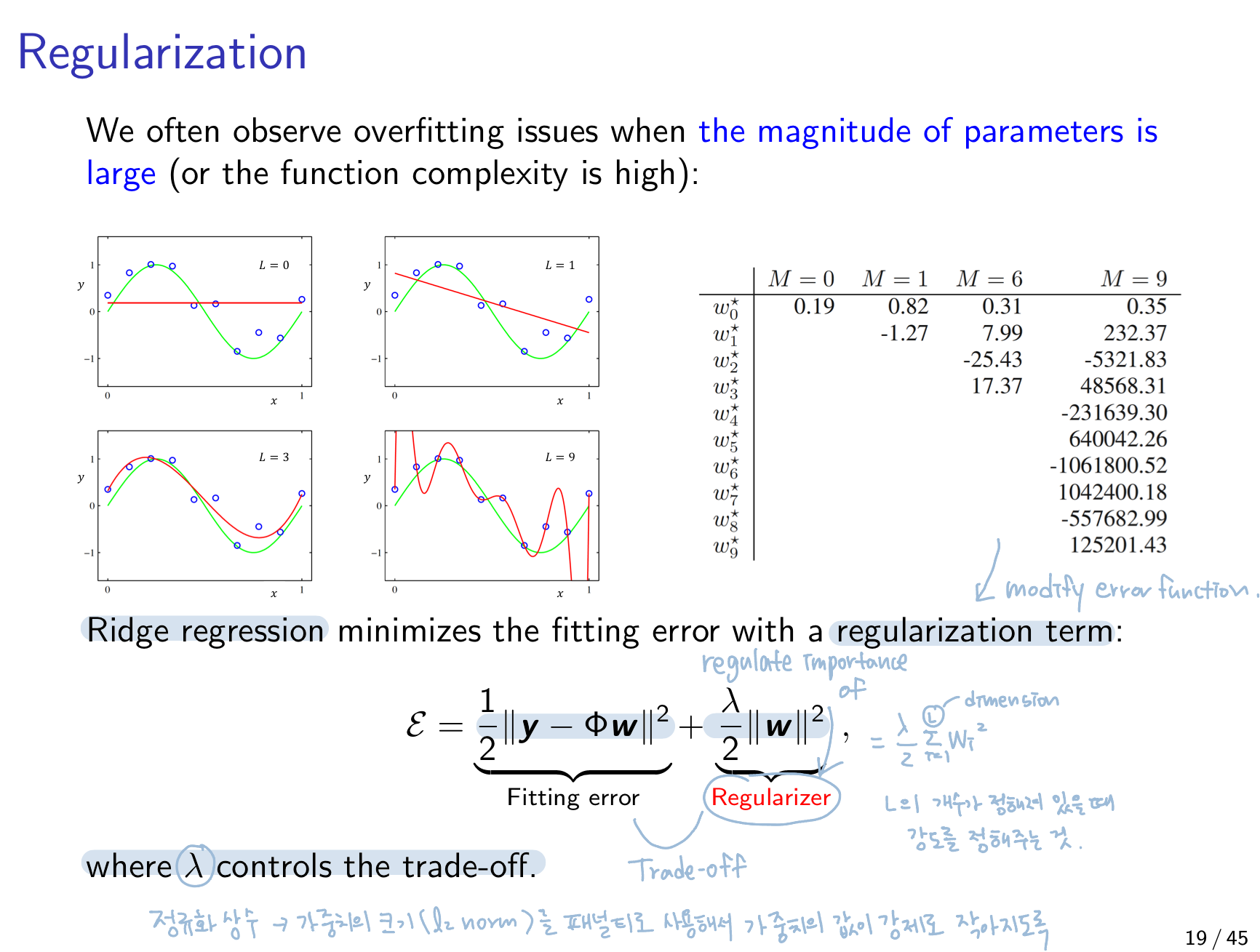
Ridge Regression은 model이 loss를 줄이는 onjective를 가지고 학습될 때 그 loss에 W magnitude를 추가해준다. W가 크면 loss 또한 커지도록 설정해줌으로써 W가 너무 커지지 않도록 regulate하면서 W(=model)를 학습할 수 있다.
** λ가 커질 수록 smoother prediction model
=>

그렇다면 이게 MAP와 무슨 연관이 있는 것일까?
Based on the belif that good parameter has small magnitude(=Ridge), i.e.prior , the posterior over w is given as:
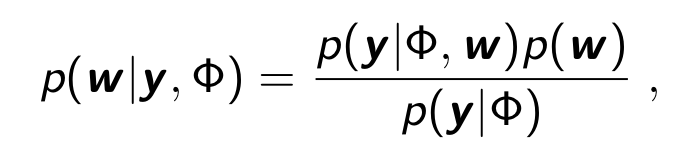 which is maximized at
which is maximized at
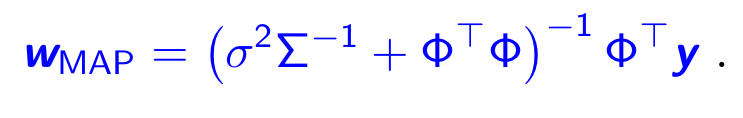
likelihood에 w의 분포를 prior로 줌으로써 posterior을 구할 수 있게된다. 즉, Linear Regression = p(y|Φ,w) = likelihood에 prior p(w) 을 줘서 posterior = p(w|y,Φ) 을 이용한 MAP optimize가 이루어진다.
하지만 이것이 이루어지려면 w가 작은 분산을 가진다는 조건이 꼭 충족되어야지만 최적의 값을 구할 수 있다. 따라서,

-
Logistic Regression
