🌪 AWS에서 최소한의 비용으로 구현하는 멀티리전 DR 자동화 구성
재해복구

비즈니스가 재해에 얼마나 영향을 받는지 파악하고 복구 계획 수립 필요
- 비즈니스 지속성
- 희귀하지만 대규모 장애상황 발생 가능
- 자연재해
- 기술적 이슈
- 휴먼 액션
- 개별 장애에 대한 목표 측정
- 복구 시간(Recovery Time)
- 복구 시점(Recovery Point)
복구시점 및 복구시간 목표
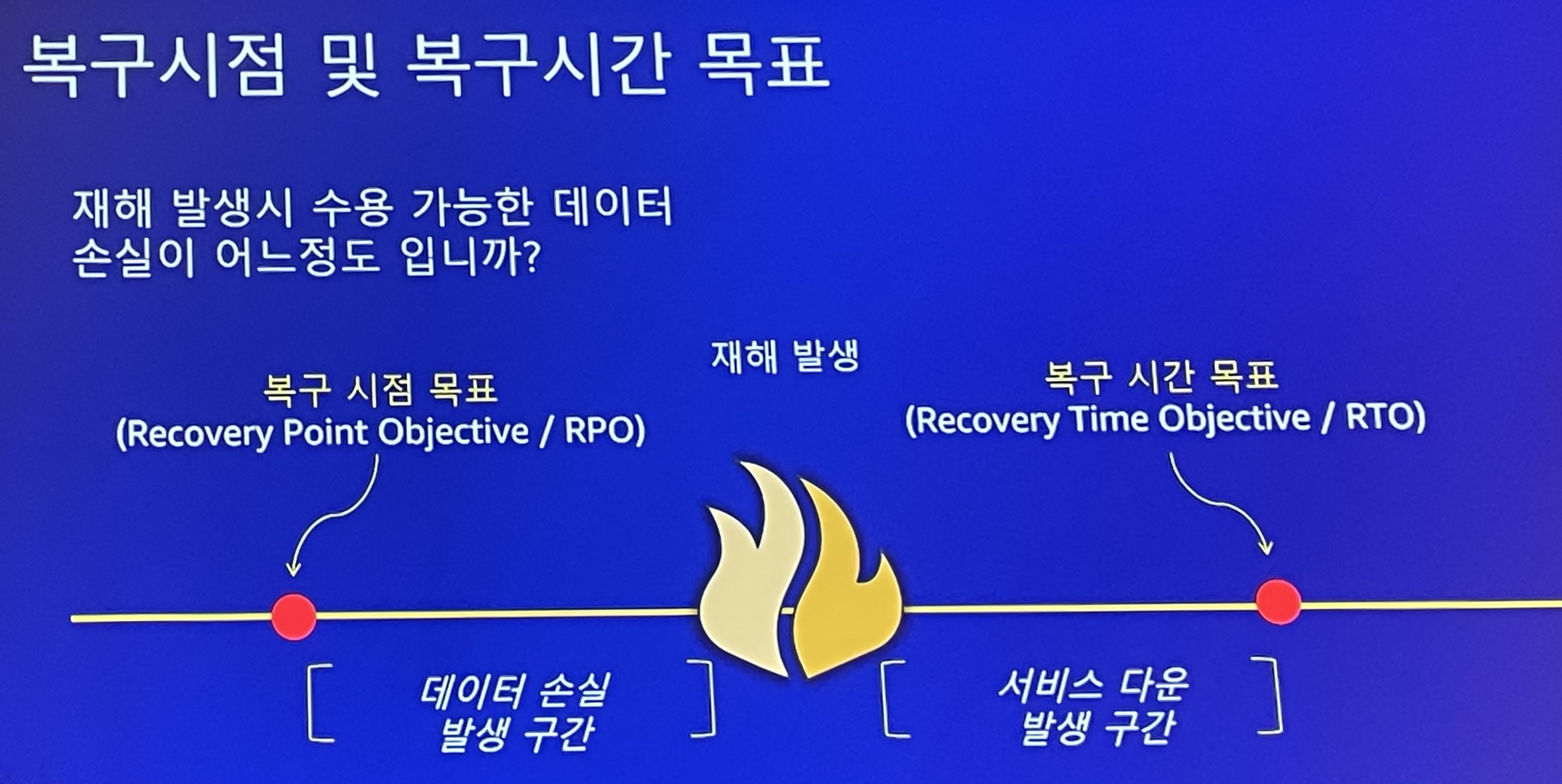
재해 발생 시 수용 가능한 데이터 손실은 어느정도인가?
- 복구 시점 목표 (RPO / Recovery Point Objective)
- 비즈니스에서 손실을 감당할 수 있는 데이터의 양
- RPO가 짧을수록 목표가 높은 것
- 복구 시간 목표 (RTO / Recovery Time Objective)
- 서비스 중단 시점을 기준으로 얼마나 빨리 재개할 것인가
클라우드에서의 재해 복구 전략
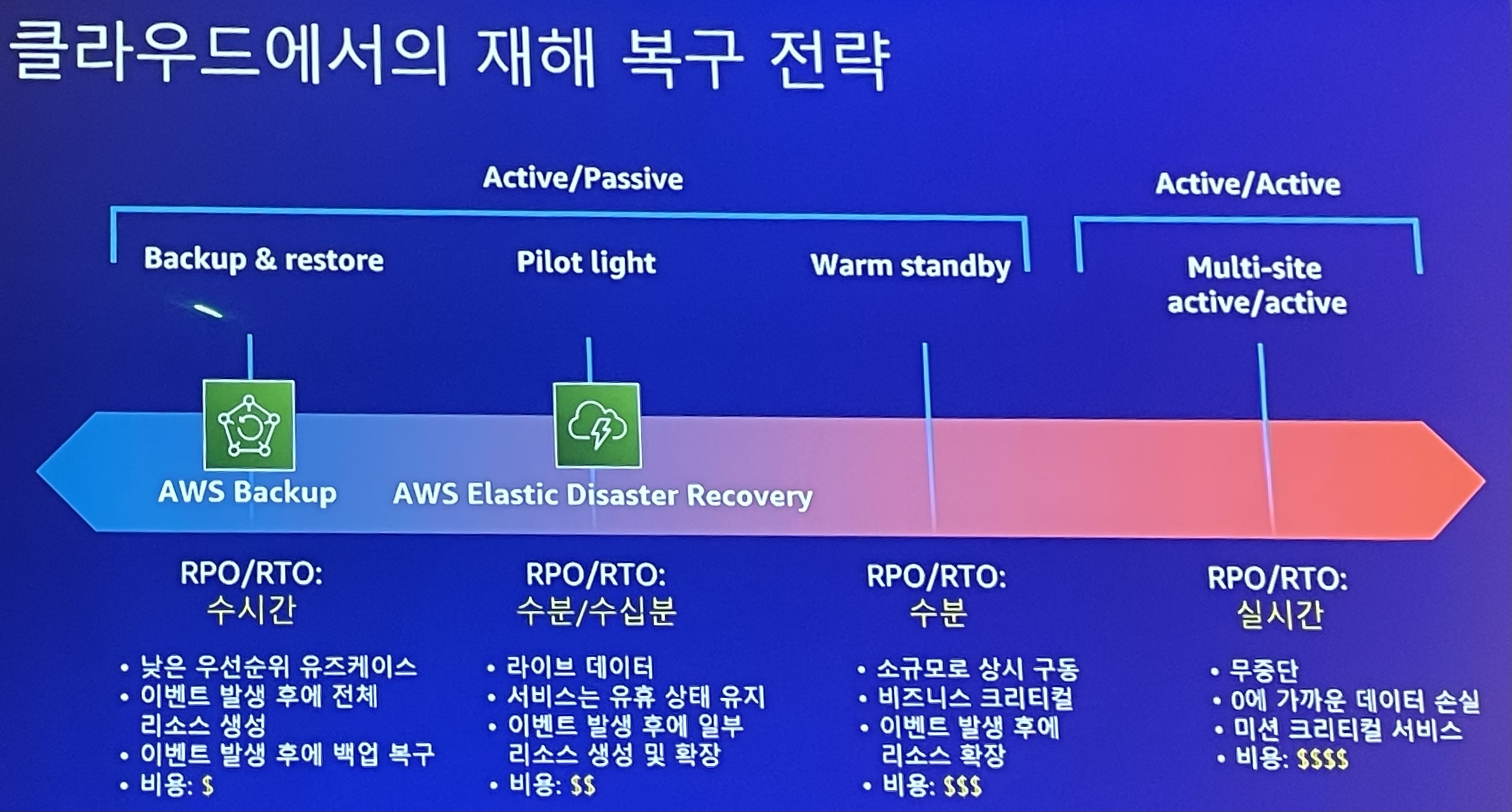
- Backup&restore
- Active/Passive
- 복구까지 수시간 소요
- 낮은 우선순위 유즈케이스인 경우에 사용
- 이벤트 발생 후에 전체 리소스 생성
- 이벤트 발생 후에 백업 복구
- 비용이 가장 저렴하다
- AWS Backup
- Pilot light
- Active/Passive
- 복구까지 수분/수십분 소요
- 데이터는 준실시간으로 복제 (라이브 데이터)
- 서비스가 유휴 상태를 유지해도 되는 경우에 사용
- 리소스는 미리 다 만들어두지 않고 최소한으로 필요한 것만 미리 생성하고 필요할때 생성
- 이벤트 발생 후에 일부 리소스 생성 및 확장
- AWS Elastic Disaster Recovery
- Warm standby
- Active/Passive
- 복구까지 수분 소요
- 소규모로 상시 구동해야하고 비즈니스 크리티컬한 경우에 사용
- 서비스를 할 수 있는 최소한의 리소스를 미리 생성. 이벤트 발생 후에 리소스 확장
- 재해 발생 시 서비스는 가능한 상태이지만 풀스케일링이 필요할 때 사용
- Multi-site active/active
- Active/Active
- 실시간 복구 가능
- 데이터 손실이 0에 가까워야 하고 미션 크리티컬한 서비스인 경우에 하용
- 기존 서비스와 동일한 수준으로 미리 구성해두고 데이터만 그때 복제
- 비용이 가장 비싸다
복구시간 목표(RTO) / 복구시점 목표(RPO)
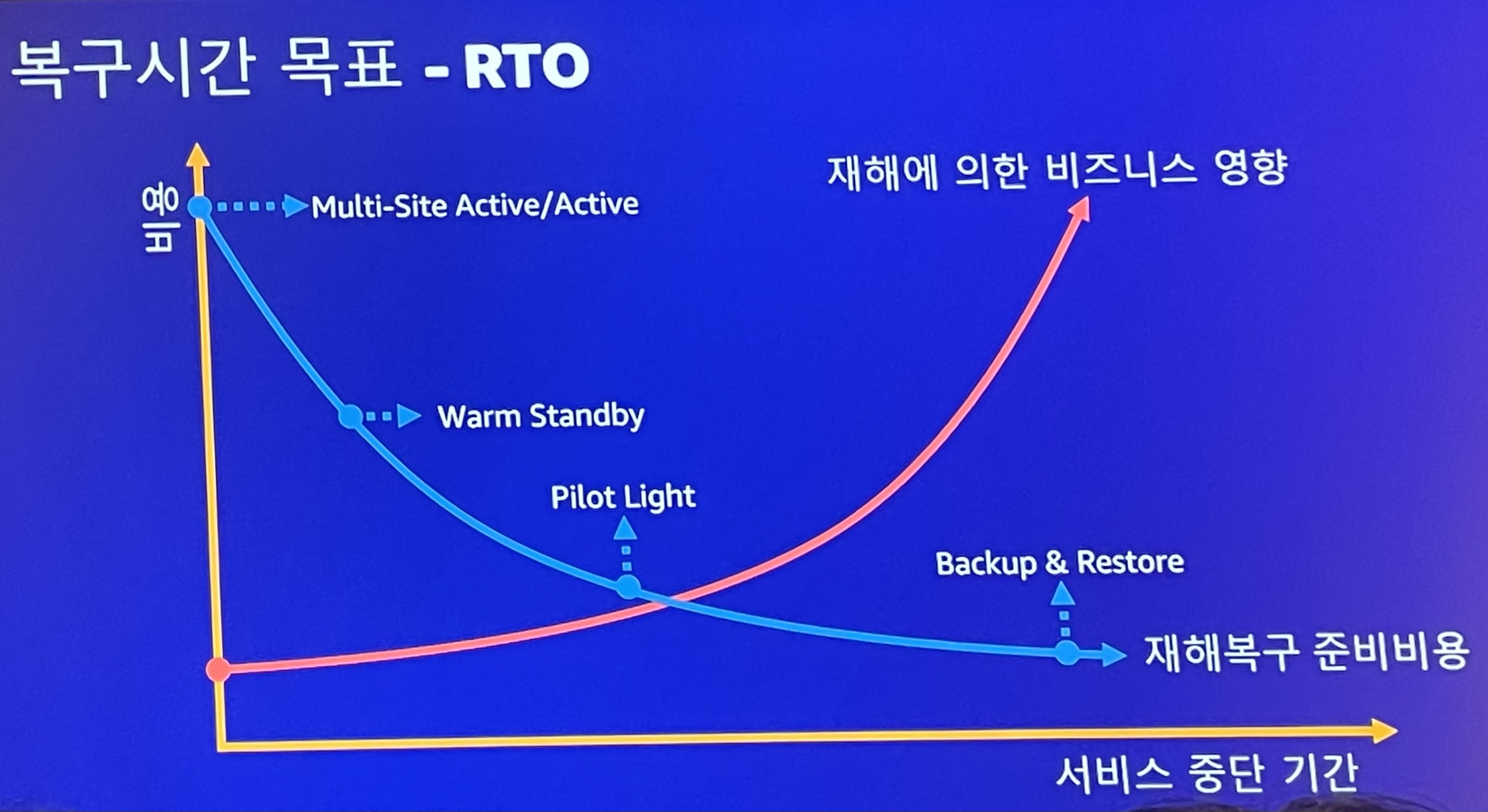
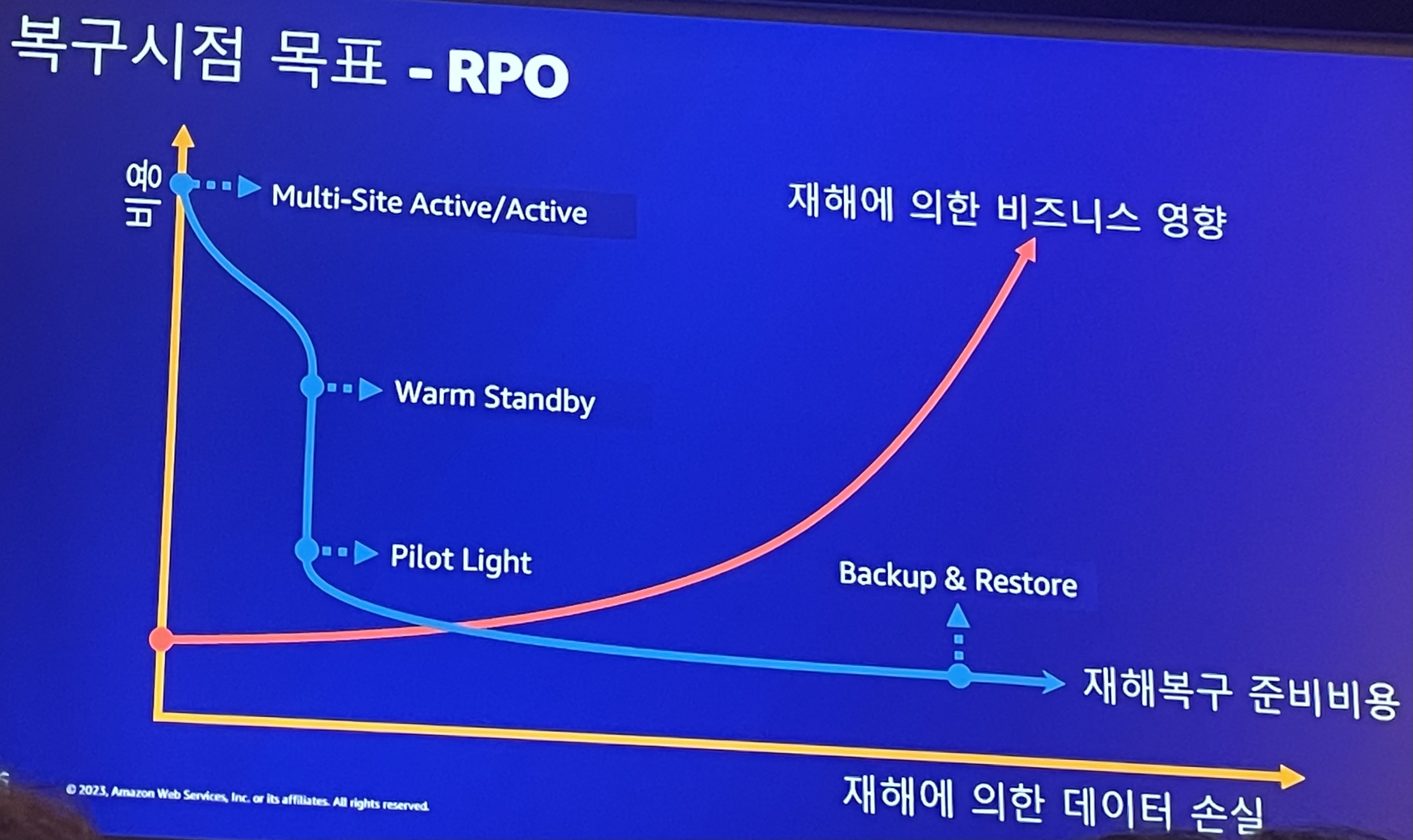
- 재해에 의한 비즈니스 영향이 중요
- 대규모 금융 트랜잭션을 처리한다면 짧은 기간 중단되더라도 리스크가 매우 큼
- 신입사원 교육용 애플리케이션같은 경우라면 중단되어도 수용 가능
- 중단이 매우 크리티컬하고 비용을 많이 투자할 수 있다면 multi-site active/active 사용
- 중단되어도 비즈니스에 영향이 별로 없다면 Backup & Restore 사용
- 재해에 의한 데이터 손실은 Pilot light와 warm standby가 거의 같음
- Pilot light가 거의 실시간으로 데이터를 복제함
- 빠른 복구 시간이 필요하다면 warm standby, 빠른 복구 시간까지 필요하지 않다면 Pilot light
재해복구를 위한 백업 대상
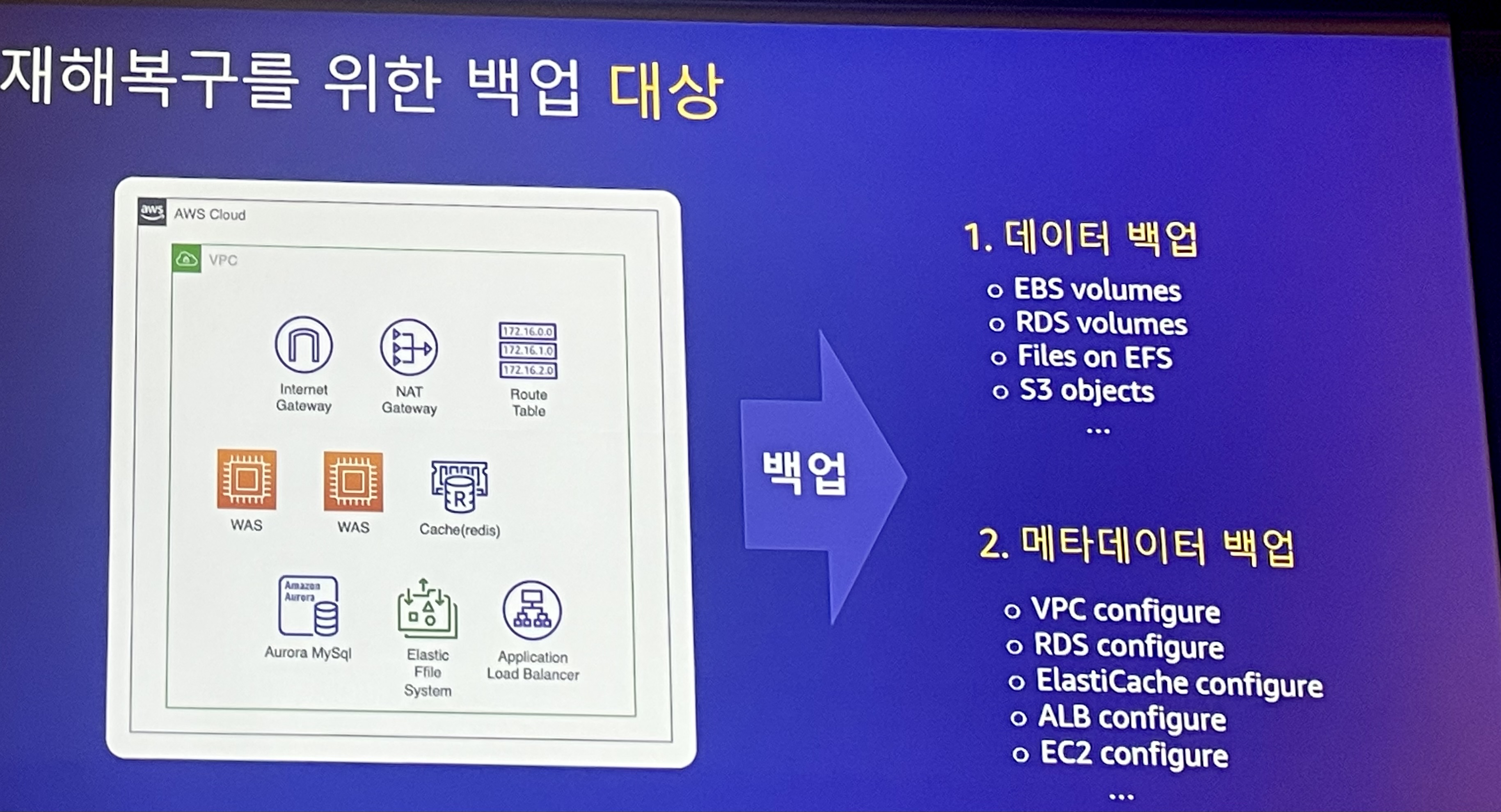
- 데이터 백업
- EBS volumes, RDS volumes, Files on EFS, S3 objects ...
- 데이터 백업 만으로 서비스 재개는 어려움 → 메타데이터 백업 필요
- 메타데이터 백업 (설정 파일 등)
- VPC configure, RDS configure, ElastiCache configure, ALB configure, EC2 configure ...
메타데이터 - 인프라 구성 정보
어떻게 추출하여 백업할 것인가?
- 온프레미스
- CMDB(구성관리데이터베이스)
- 호스트 서버에 설정 정보 등이 저장됨
- 수기, 엑셀 파일, 전용 시스템 등
- AWS 클라우드
- CMDB: 온프레미스와 동일하게 사용하거나 클라우드와 연동되는 CMDB
- AWS API: API로 리소스 제어 가능
- IaC(Infrastructure as a Code): 인프라 자체를 코드로 관리. 서드파티 등 활용
- AWS CloudFormation, Terraform, AWS Cloud Development Kit
Backup & Restore 기반 재해복구 자동화
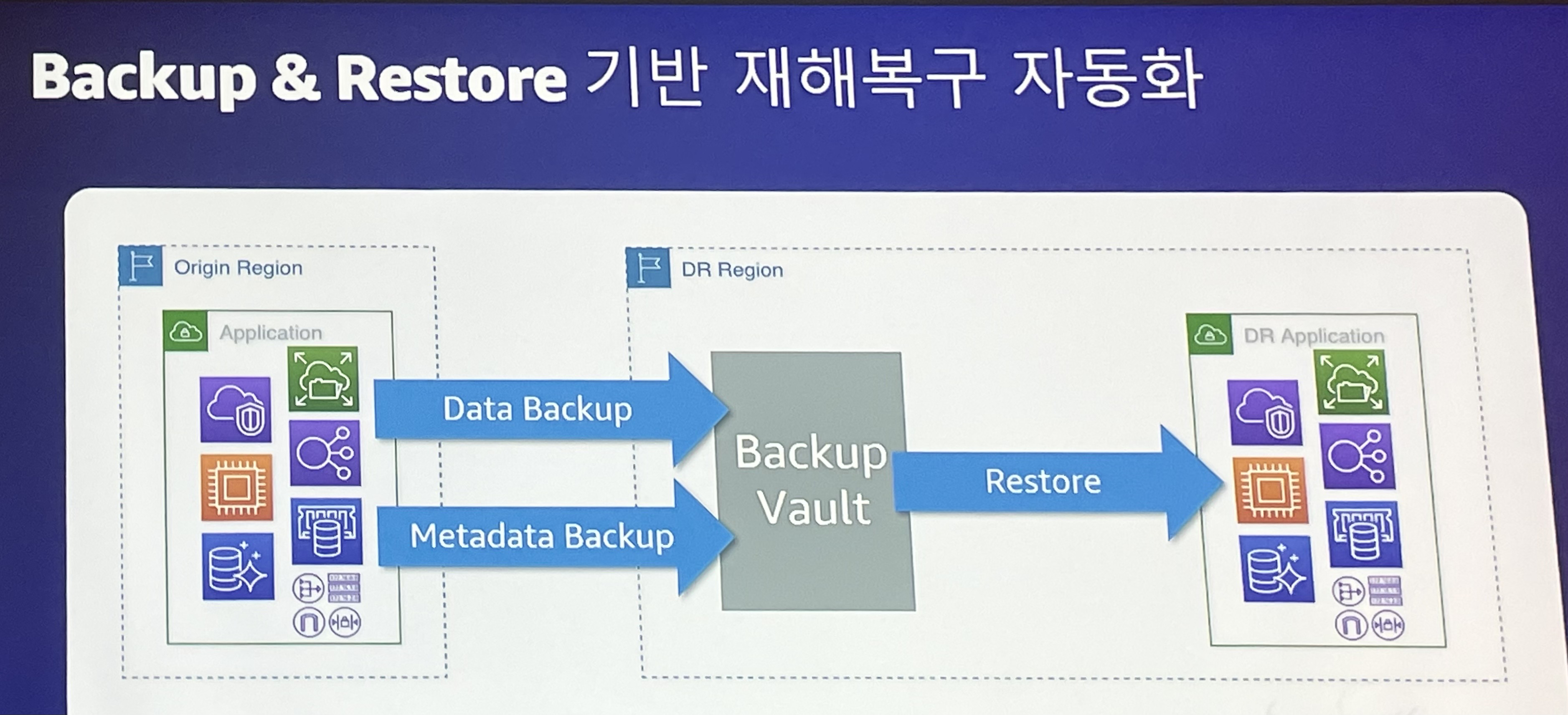
- 재해 발생 시 DR 리전에 백업해둔 데이터와 메타데이터를 조합하여 원본과 동일하게 구성
- 각각의 백업 방식이 있음. 자동화가 필요하다면 각각 구현 필요
- AWS 백업 제품 활용 가능
AWS Backup을 이용한 멀티리전 재해복구
AWS Backup이란?
- AWS Backup
- 완전관리형 정책 기반 백업 서비스
- 여러 AWS 서비스들에 걸쳐 자동화된 중앙 집중식 관리를 지원하는 백업 서비스
재해복구 자동화 구현 예시
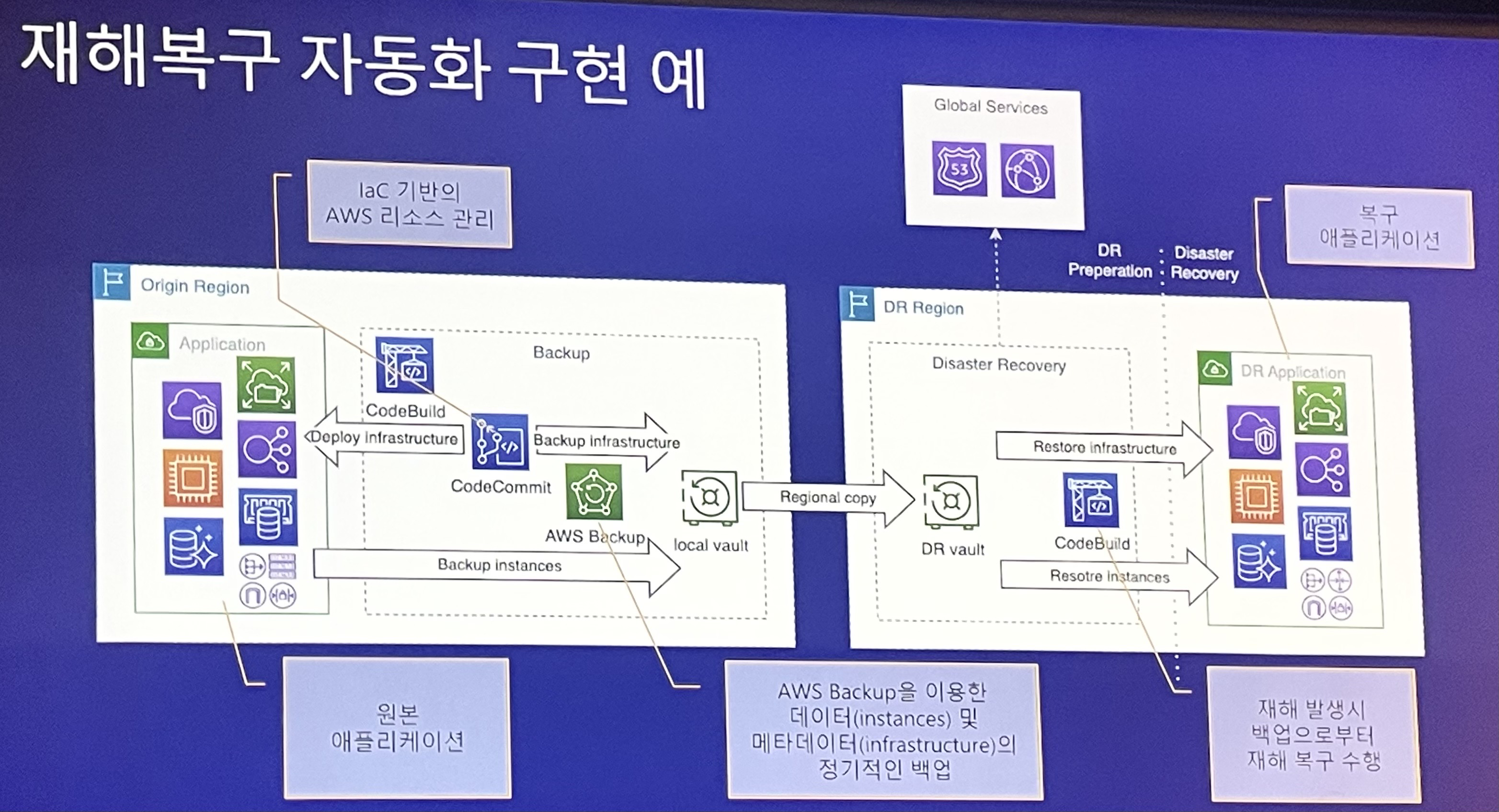
- 모든 데이터와 메타데이터를 DR리전에 복제
- 코드빌드와 같은 CI/CD 도구로 자동 복구
1. IaC 관리 및 백업
- 형상관리 기반 IaC 코드 관리
- AWS CodeCommit - 관리형 git 서비스
- IaC 코드 백업 자동화
- 사용자의 git push 이벤트에 따라 코드를 저장소(AWS CodeCommit)의 IaC 코드를 S3 버킷에 복제
- IaC 코드가 복제된 S3 버킷을 AWS Backup을 이용해 리전 간 복제 자동화
2. IaC 코드 의존성 분리
- 의존성 분리
- 재해 복구용으로 IaC 코드 이용을 위해 코드 내 원본 리전에 대한 의존성 분리
- 리전ID, ami 정보 등
- 정적 의존성 분리
- 복구 리전의 정적 정보가 포함된 IaC 코드는 사전에 작성
- 리전 정보, 가용영역 정보 등
- 동적 의존성 분리
- 복구 리전의 동적 정보가 포함된 IaC 코드는 복구 시점에 작성 → 자동화 검토
- EC2 인스턴스 복구용 AMI 정보, RDS 복구용 DB Snapshot 정보 등
3. 관리형 리소스에 대한 간접 접근

- 관리형 서비스의 엔드포인트 형태
- 많은 관리형 서비스들의 엔드포인트(DNS name)에는 리전이름과 고유ID가 포함됨
- ex) app-123456789.ap-northeast-2.elb.amazonaws.com, db.123456789.ap-northeast-2.rds.amazonaws.com
- 복구중 리소스 생성시 엔드포인트 변경됨
- 애플리케이션 코드나 설정 등, 애플리케이션 배포 번들에 엔드포인트 정보가 포함된 경우, 복구과정 중 수정 필요
- 엔드포인트에 간접적으로 접근하도록 구성 후, 복구 과정 중 생성한 리소스에 대한 엔드포인트 업데이트 자동화
- Amazon RouteS3 Private Hosted Zone 또는 AWS Systems Manager Paramater Store 등 활용 가능
4. 재해 복구 태스크의 실행 독립성 확보
- 복구 작업의 독립성
- 원본 리전에 대한 모든 리소스를 사용할 수 없는 상황
- 복구 프로세스는 DR 리전(복구 리전)의 리소스만을 이용하여 복구 가능해야 함
5. 재해복구 시스템의 지속적인 검증 및 보완

- 재해복구는 원타임 구축 대상이 아님!
- 근간이 되는 인프라 스트럭처도 지속적으로 변화함
- 유사시 원활한 재해복구를 위해 지속적인 검증과 보완이 필수
- 빈번한 검증 및 보완 필요
AWS Elastic Disaster Recovery를 이용한 재해복구
온프레미스에서 AWS로 재해복구
클라우드 재해 복구 장점
필요할 때에만 사용할 수 있는 퍼블릭 클라우드의 장점은 백업, 재해 복구에 적합하다
- 온프레미스 재해 복구
- 막대한 선결제 및 지속적인 하드웨어 비용으로 비용적 부담이 큼
- 데이터 증가로 하드웨어 및 운영 비용 증가
- 비즈니스 중단 없이 테스트가 어려움
- 전 세계적으로 분산된 비즈니스를 위한 관리 및 인프라 오버헤드 발생
- 클라우드 재해 복구
- 테스트 또는 복구에 필요한 경우에만 프로비저닝
- 사용된 서비스에 대해서만 지불
- IT 관리 오버헤드 감소
- (훨씬!) 더 많은 자도오하
- 운영 환경을 종료하지 않고 쉽고 반복 가능한 테스트
- 몇 분 만에 시스템 가동
클라우드 재해 복구의 비즈니스 효과

- 견고한 운영 체계
- 최상위 복구 목표를 기반으로 안정적인 안정성과 가용성 달성
- 운영 효율성
- 중복 인프라 및 라이선스의 필요성을 줄임으로써 비용 절감을 확보
- 비즈니스 연속성에 대한 확신
- 운영 환경에 영향이 없는 쉬운 재해 복구 테스트를 수행하여 가동 중지 시간 및 데이터 손실을 최소화
AWS Elastic Disaster Recovery란?
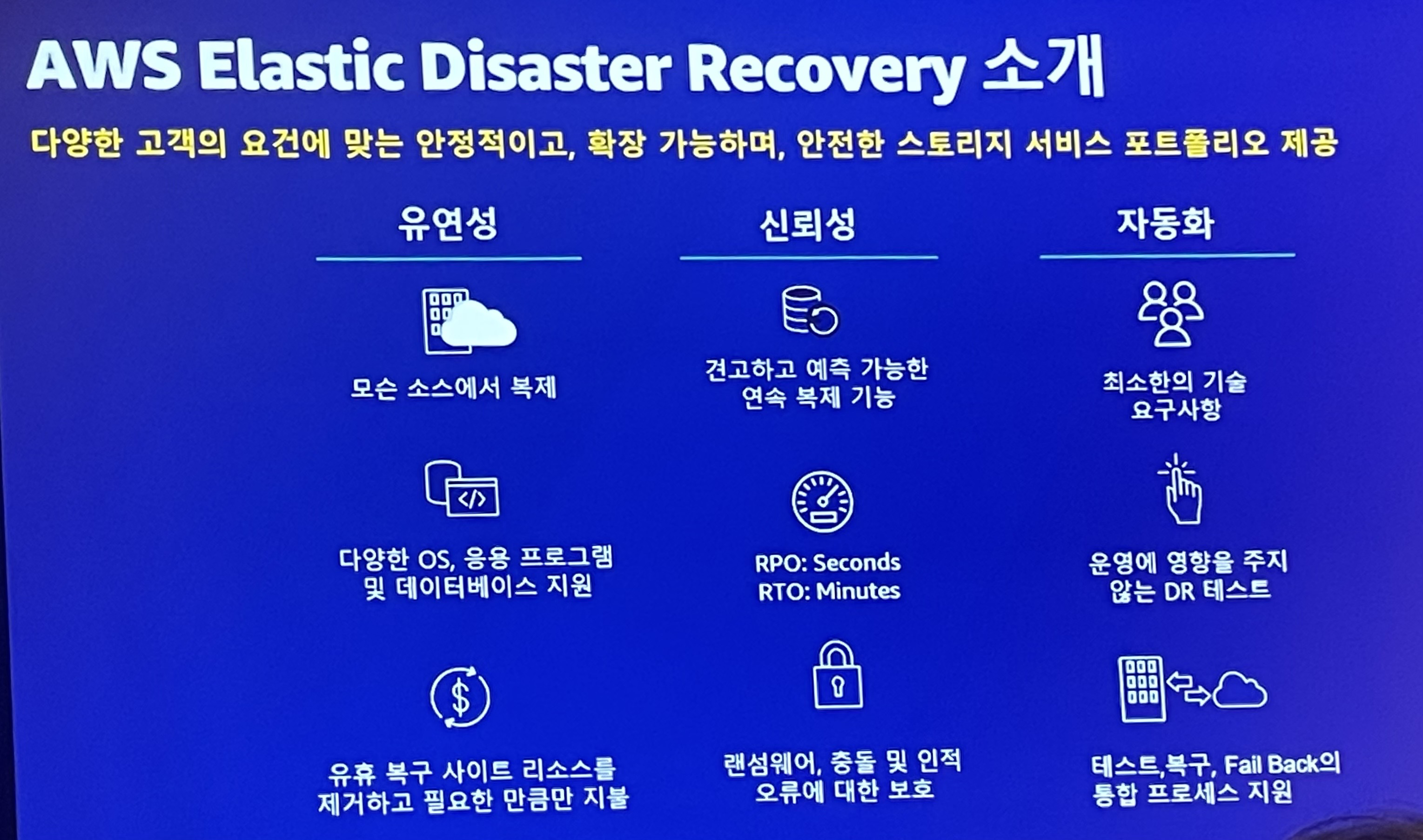
다양한 고객의 요건에 맞는 안정적이고, 확장 가능하며, 안전한 스토리지 서비스 포트폴리오를 제공하는 서비스. Pilot light에 해당됨
- 유연성
- 모든 소스에서 복제
- 다양한 OS, 응용 프로그램 및 데이터베이스 지원
- 유휴 복구 사이트 리소스를 제거하고 필요한 만큼만 지불
- 신뢰성
- 견고하고 예측 가능한 연속 복제 기능
- RPO: Seconds
RTO: Minutes - 랜섬웨어, 충돌 및 인적 오류에 대한 보호
- 자동화
- 최소한 기술 요구사항
- 운영에 영향을 주지 않는 DR 테스트
- 테스트, 복구, Fail Back의 통합 프로세스 지원
AWS Elastic Disaster Recovery 사용 패턴
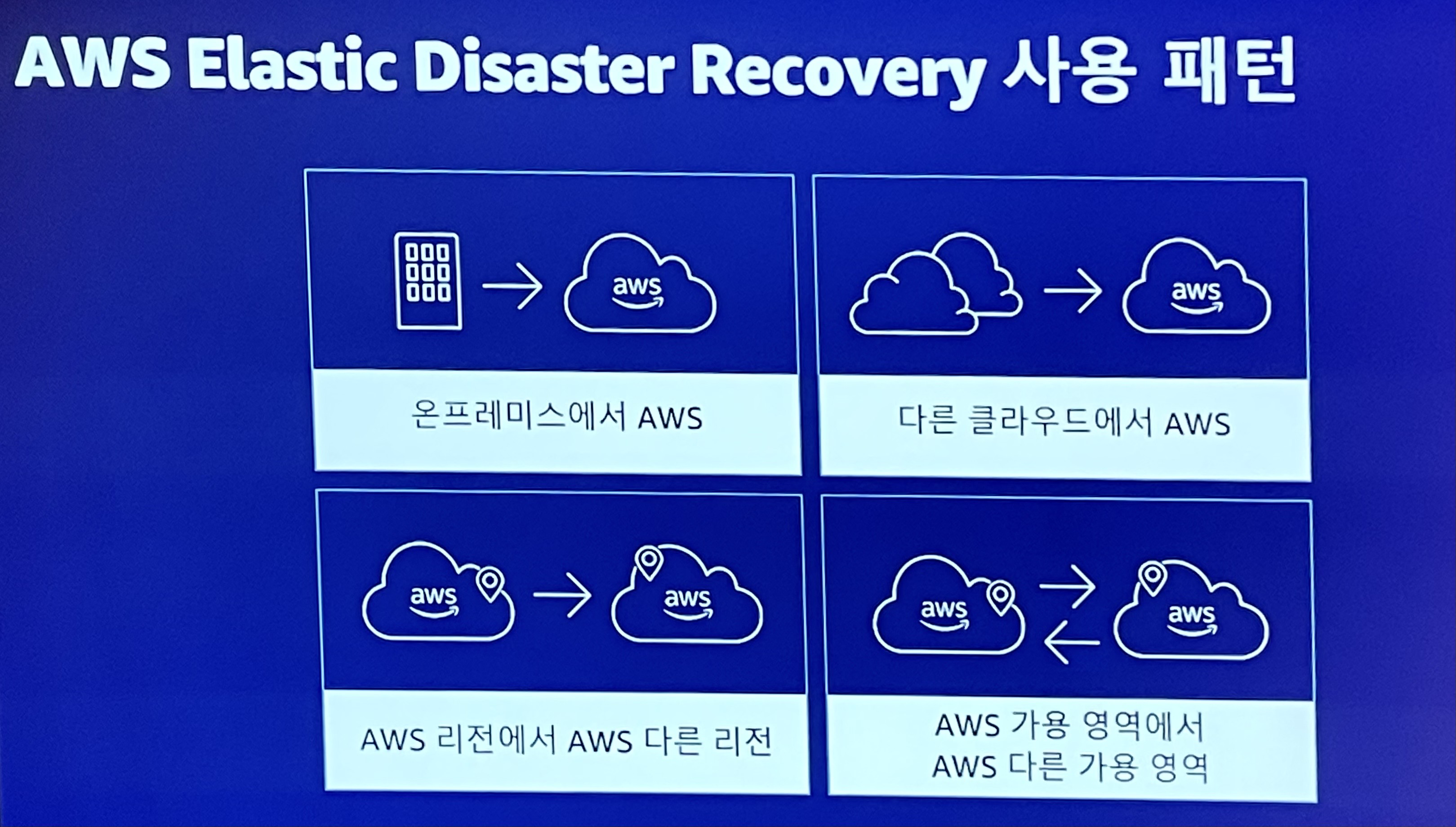
- 온프레미스 → AWS
- 다른 클라우드 → AWS
- AWS 리전 → AWS 다른 리전
- AWS 가용 영역 → AWS 다른 가용 영역
AWS Elastic Disaster Recovery 작동방식
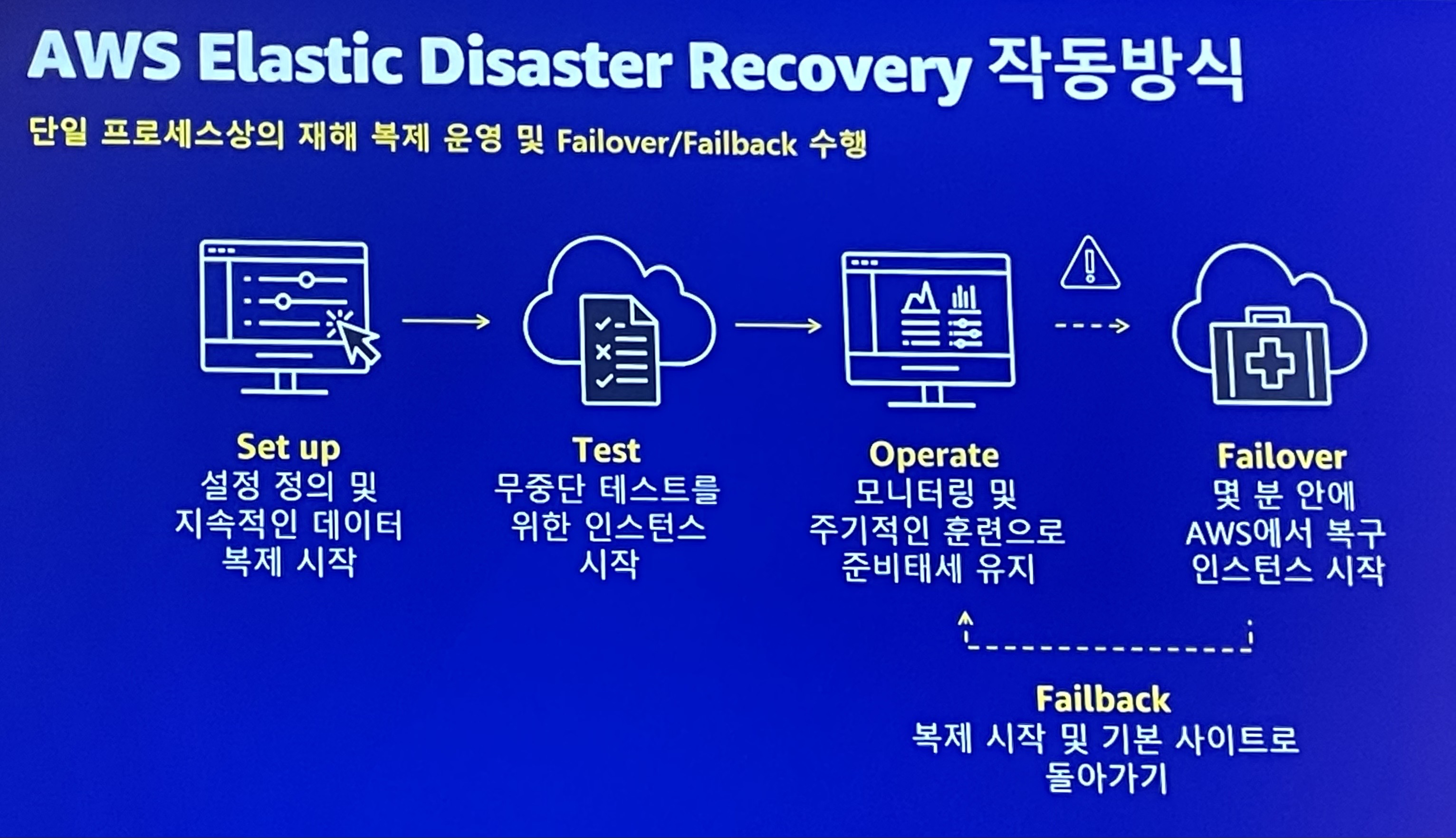
- 단일 프로세스상의 재해 복제 운영 및 Failover/Failback 수행
- Set up
- 설정 정의 및 지속적인 데이터 복제 시작
- Test
- 무중단 테스트를 위한 인스턴스 시작
- Operate
- 모니터링 및 주기적인 훈련으로 준비태세 유지
- Failover
- 몇 분 안에 AWS에서 복구 인스턴스 시작
- Failback
- 복제 시작 및 기본 사이트로 돌아가기
AWS Elastic Disaster Recovery 지원 대상
물리적, 가상 및 클라우드 서버에서 확장 가능하고 비용 효율적인 재해 복구 서비스

AWS Elastic Disaster Recovery 아키텍처
온프레미스 또는 기타 클라우드에서 AWS
DEMO Architecture
정리

💡 데이터와 메타데이터(구성정보)를 함께 백업하여 재해에 대비
💡 AWS Elastic Disaster Recovery를 이용하여 비용효율적으로 온프레미스 장비에 대한 재해 복구 구성
💡 재해복구는 원타임 구축 대상이 아니며, 지속적인 검증과 보완만이 비즈니스의 지속성을 보장할 수 있음
참고 자료
- AWS Backup 및 AWS Elastic Disaster Recovery 관련 워크샵 자료
- AWS 클라우드에서의 재해 복구 백서 및 안내서 자료
- AWS Skill Builder 무료 온라인 트레이닝
