Toss | SLASH 21 - MySQL HA & DR Topology
👉 https://www.youtube.com/watch?v=t96l6ry_qmw
MMM
- MySQL Multi-master replication Manager의 약자
- 토스의 Live MySQL 데이터베이스의 HA 솔루션으로 사용 중
- 구글에서 개발된 솔루션으로 버전 업데이트가 더 이상 제공되지 않아 자체적으로 업데이트 필요
MMM 기본 구성도
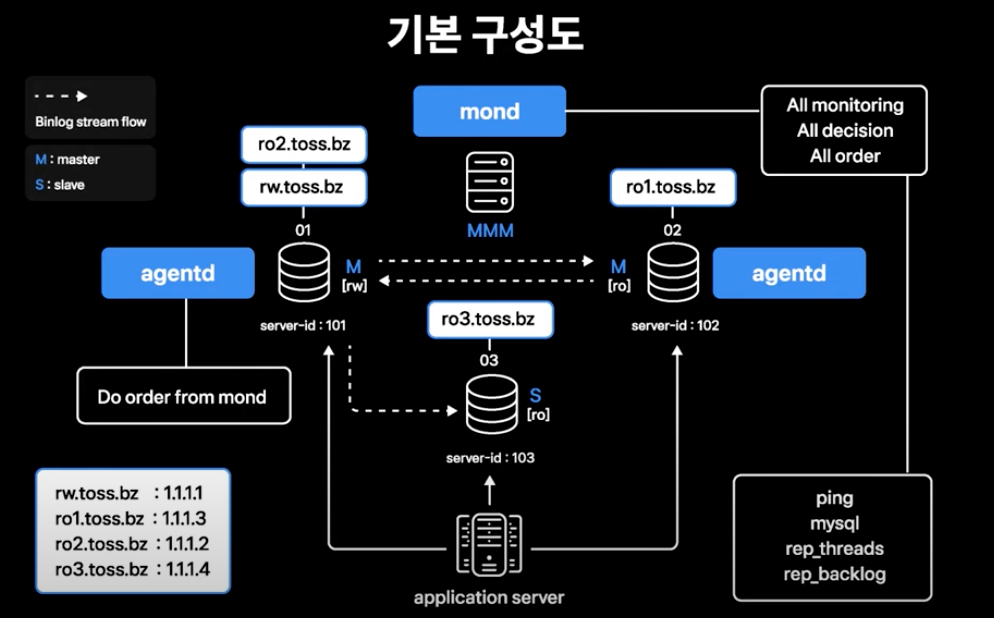
- Master-Master 01, 02 노드만 MMM이 관리하도록 구성하여 사용중
- 03번 Slave도 MMM 관리하에 포함시키는 구성이 가능하지만, 신규 Master로 failover하는 과정에서 대응되지 않는 몇 가지 케이스로 인해 Slave를 MMM 관리에 포함하여 사용하고 있지 않음
- Monitoring 데몬(mond)
- 별도의 호스트에서 모든 모니터링 및 의사 결정과 명령을 수행
- 주요 모니터링 항목
- ping : 호스트 자체가 살아있는지 확인
- mysql : MySQL 인스턴스가 살아있는지 확인
- rep_threads : 복제 스레드가 정상 작동 중인지 확인
- rep_backlog : 복제 스레드의 지연이 정해진 threshold를 넘어섰는지 확인
- 모니터링 항목 중에 문제가 있을 시 MMM이 standby Master로 failover를 진행
- Agent 데몬(agentd)
- 각 데이터베이스 서버에서 실행됨
- Monitoring 데몬에서 내려온 명령을 수행
- APP 서버 failover를 위해 각 데이터베이스 서버에 올라가는 서비스 IP(rw.toss.bz, ro1.toss.bz 등)
- MMM이 데이터베이스 Role 변경에 따라 이동시켜 APP 서버의 failover가 이루어지게 함
기존 DR 구성
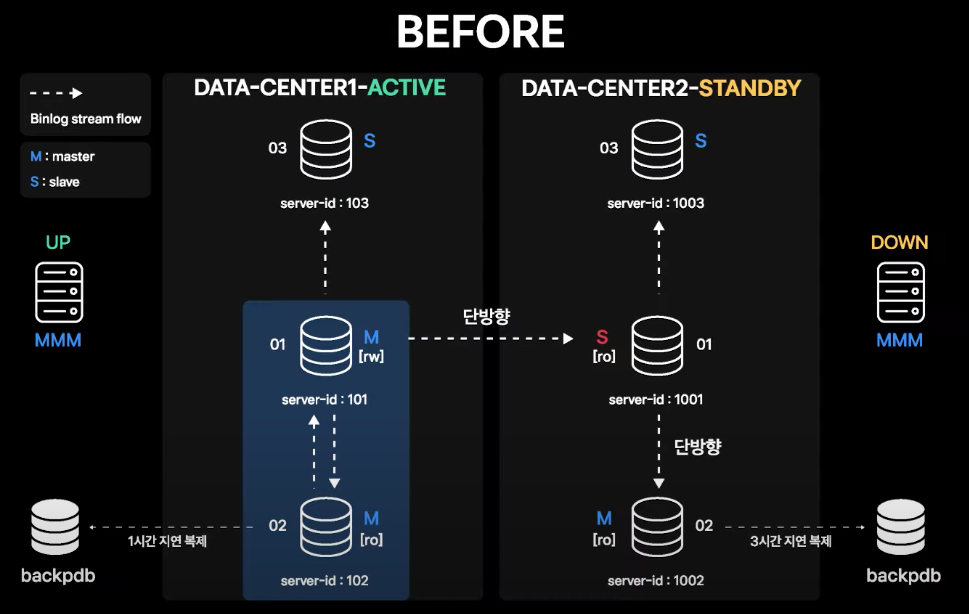
- 데이터센터1이 Active, 데이터센터2가 Standby
- Standby 데이터센터의 Master가 Active 데이터센터 Master의 Slave인 형태로 단방향 복제로만 구성되어 있음
기존 DR 구성에서의 Failover
- 데이터센터간에도 단방향 구성, Standby 데이터센터 내의 local Master 간에도 단방향 복제 구성이므로 데이터센터 failover 시에 Role 전환 작업 필요
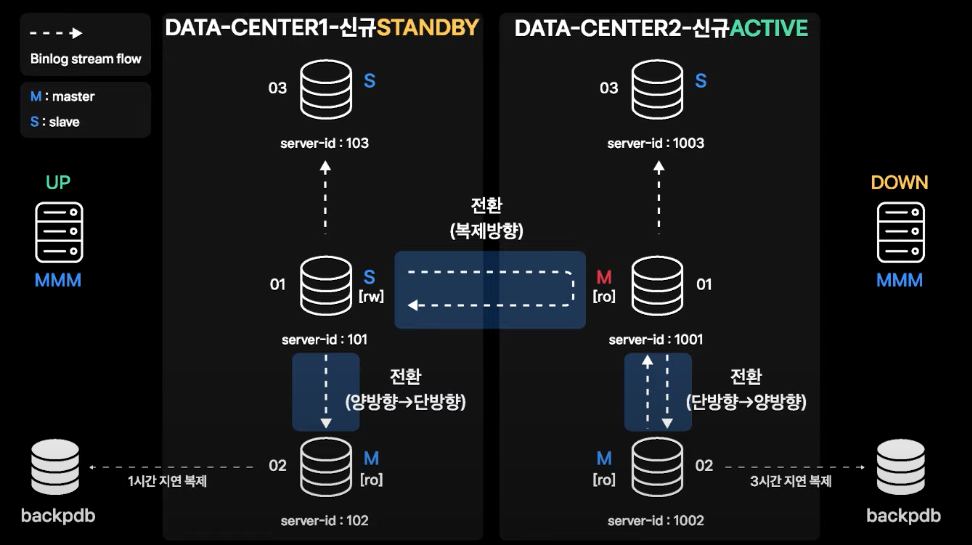
- 신규 Active 데이터센터의 MySQL 서버를 Master-Master 구성으로 전환이 필요하고, 데이터센터간 MySQL 서버의 Master-Slave 관계도 전환 필요
- 신규 Standby 데이터센터의 MySQL 서버는 Master-Slave 단방향으로 전환 필요
문제점
- 각각의 작업은 어렵지 않지만, 은근 번거롭고 부담스러운 작업이 됨
- DR 센터의 본 목적이 재난 시 비즈니스 연속성 보장이므로 데이터센터 failover가 필요한 상황이 거의 발생하지 않을 것이라고 예측하고 위와 같이 구성
- 하지만 무중단 운영의 필요성이 점점 커지며 대규모 네트워크 작업이 무중단 데이터센터 롤링 작업으로 계획되었고, 이에 데이터베이스 서버도 데이터센터 failover가 필요하게 됨
- 데이터센터 롤링 시마다 데이터베이스 Role 전환 작업에 대한 부담이 늘어나고, 작업 시 실수로 복제가 깨지는 경우도 발생하게 됨
- 그 외에도 다운타임이 필요하거나 온라인으로 하기에는 위험부담이 큰 작업이 발생
👉 데이터센터 전환 과정의 간소화 필요
희망 DR 구성

- 양쪽 데이터센터를 대칭으로 만들어 데이터센터 failover 시에 APP 서버 커넥션만 옮겨다니고 데이터베이스 레벨에서는 따로 작업할 것이 없는 구조를 구상
- 기존 단방향 DR 복제 채널과 DR 센터 내에 Master-Slave 복제 채널이 Master-Master 양방향으로 바뀌는 완전한 대칭이 되는 구성
- 하지만 이는 아래와 같이 두 가지 문제점을 지니고 있음
1. binlog 중복 전송 문제
- 01, 02번의 경우
log_slave_update옵션을 키고 운영을 하게 됨log_slave_update: sql_thread가 적용한 트랜잭션도 binlog에 기록하는 옵션
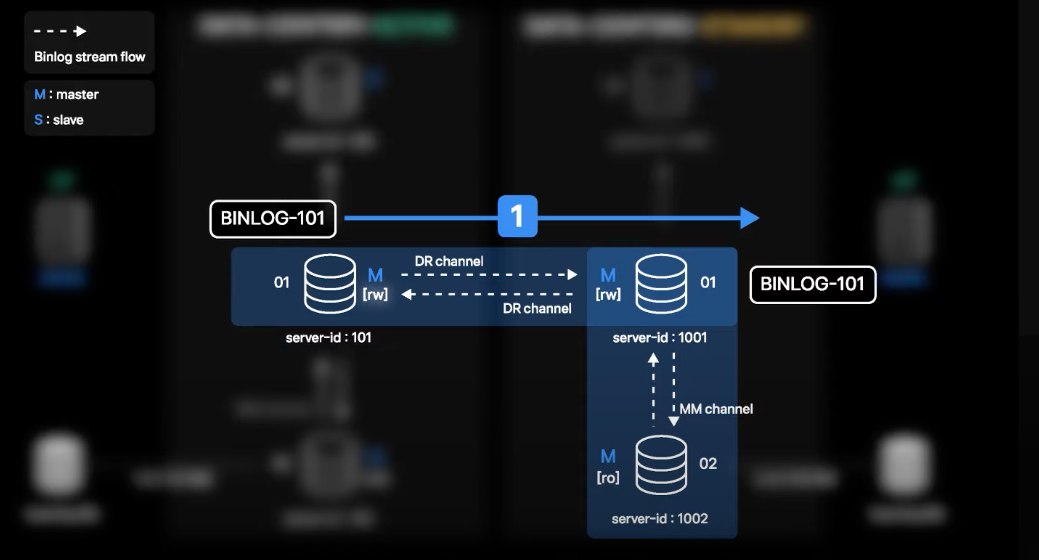
- Active 데이터센터 01번에서 발생한 트랜잭션의 binlog가 생성이 되면 DR 채널을 따라 Standby 데이터센터 01번으로 전송되고 적용됨
- 적용 이후 Standby 데이터센터 01번 서버는 해당 트랜잭션에 대한 binlog를 생성
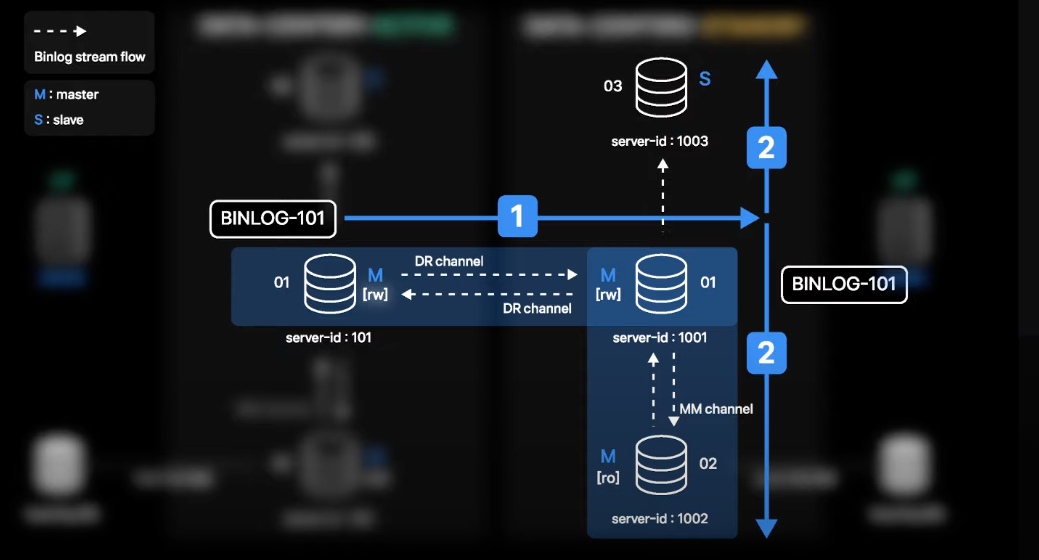
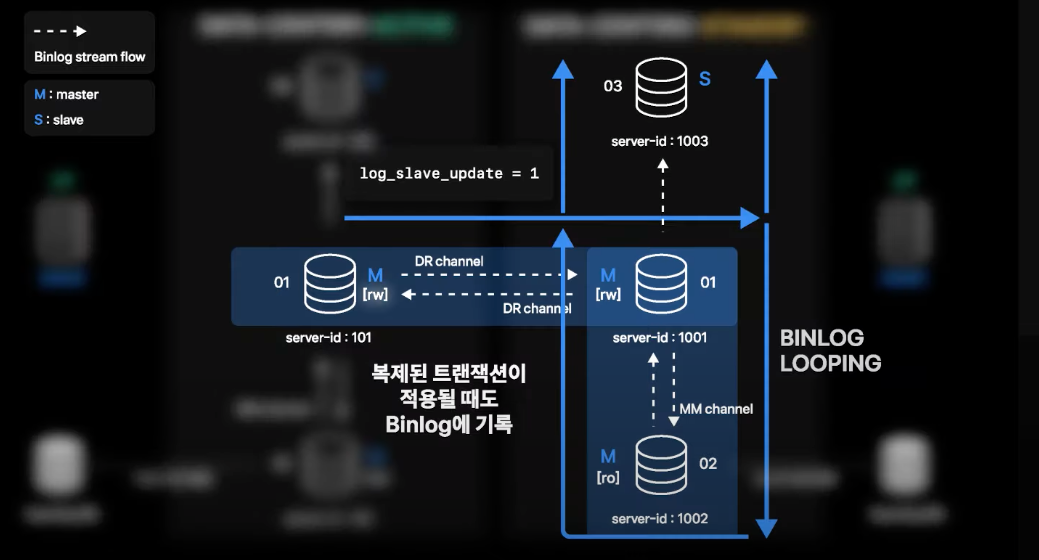
- 이때 01번의 Slave로 있는 02, 03번에서 생성된 binlog를 복제하고 적용
- 여기까지는 단방향 구성과 동일한 binlog 복제 흐름
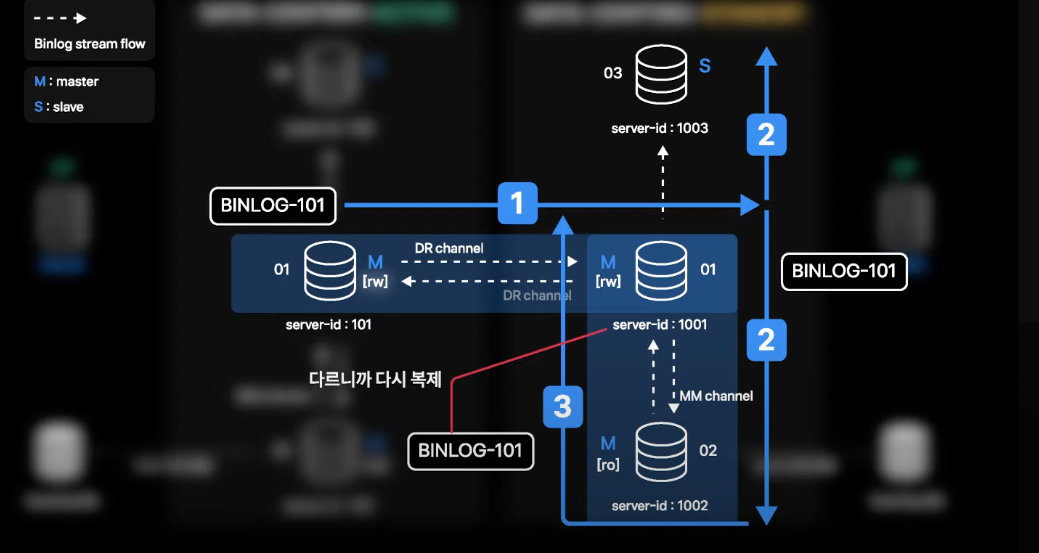
- 하지만 02번에서 최종 적용한 binlog가 자체 binlog로 생성되고, 01번은 02번의 Master이면서 Slave이기 때문에 해당 binlog를 복제해야 하는지 판단하게 됨
- 판단은 해당 binlog가 처음 생성된 서버의 server-id와 자신의 server-id가 다른지 비교하고 다른 경우 복제를 수행하게 됨
- 해당 binlog는 Active 데이터센터 01번에서 처음 생성되었기 때문에 server-id 101을 계속 유지하고 있는 상황이고, server-id 1001인 Standby 데이터센터 01번으로 다시 복제됨
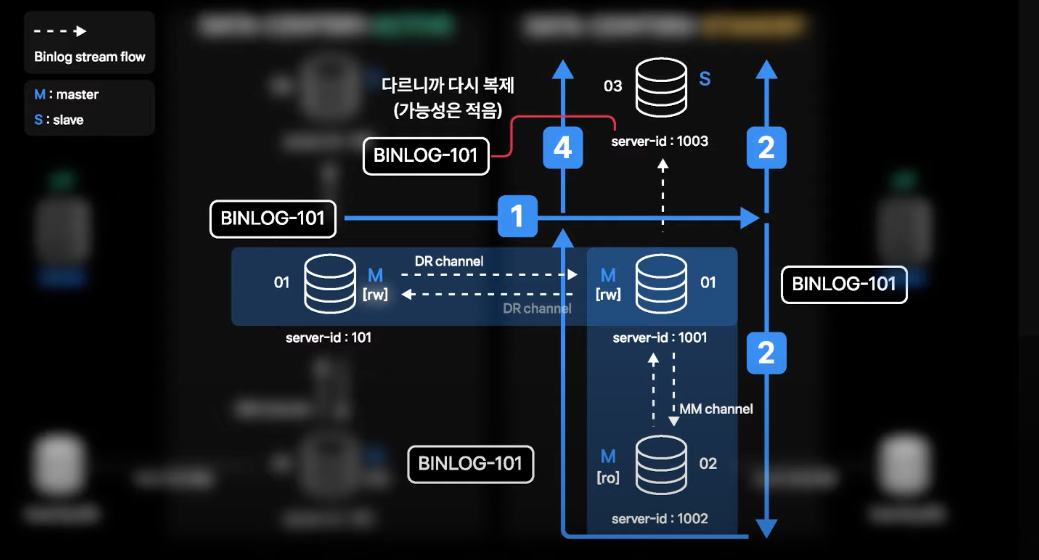
- 적용이 되면 또 다시 03, 02번으로 복제가 되는 상황이 발생할 수 있음
- 실제 값 변경이 없는 경우 binlog가 생성되지 않는데, 동일 binlog가 적용된 지 1초도 지나지 않은 상황이기 때문에 4번의 상황까지 나올 확률은 적음
- 하지만 이론적으로는 무한 Looping이 가능한 상황
해결방안
- Gtid로 중복 적용 막기
- 하지만 당시 바로 Gtid 전환은 어려운 상황이었음
- Gtid로 가더라도 binlog의 전송 looping(No IO Thread skip)은 발생하게 됨
- 다시 binlog position 방식으로 전환 시 이슈가 되므로 중복 전송 자체를 막을 방법이 필요
👉 binlog filter를 걸어 binlog looping 막기
2. MMM이 복제 채널을 구분하지 못하는 문제
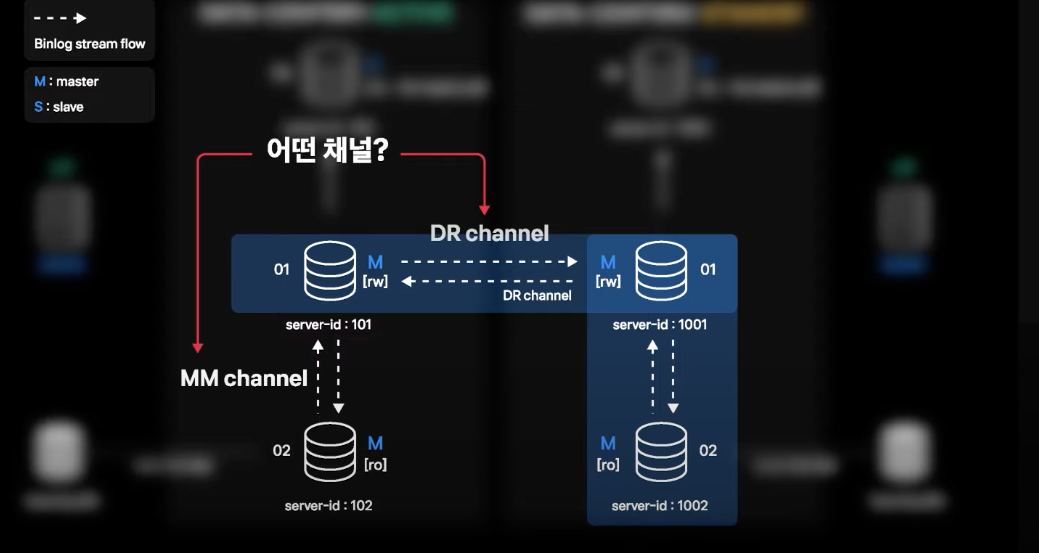
- 각 데이터센터의 01번 서버는 DR 양방향 복제 채널이 추가됨으로 인해 DR 복제 채널과 local Master-Master 복제 채널이 동시에 생성된 멀티소스복제 상태가 됨
- MMM은 자기가 모니터링 해야 할 채널이 어떤 채널인지 알지 못함
해결방안
👉 MMM이 MM 채널에 대해서만 모니터링하도록 소스 수정
현재 최종 DR 구성
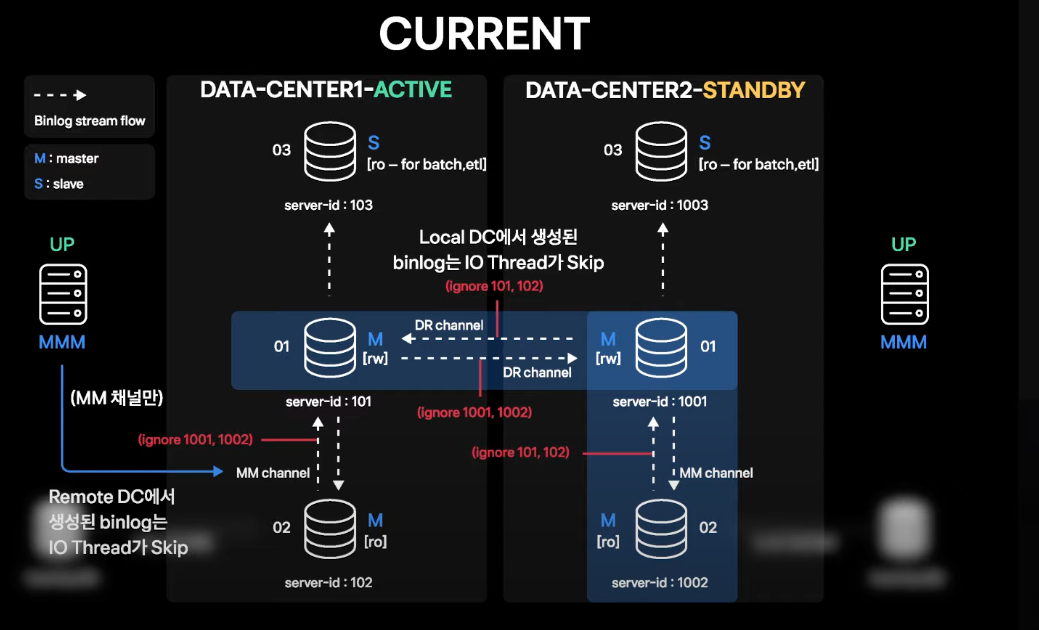
- binlog filter를 각 데이터센터의 01번에서 생성된 DR 복제채널, MM 복제채널에 설정
- 각 채널의 filter 설정 조건
- DR 채널의 경우) local 데이터센터에서 발생된 트랜잭션에 대한 binlog를 받지 않음 (IO Thread Skip)
- MM 채널의 경우) DR 채널이 있는 Master 서버의 MM 채널은 원격 데이터센터에서 발생한 트랜잭션에 대한 binlog를 받지 않음 (IO Thread Skip)
- filter 적용 시 binlog 중복 전송이 방지되어 각 데이터센터의 local MM 구조와 데이터센터 간 MM 구조를 유지할 수 있음
- 해당 구조에서 데이터센터 failover 시 DB 레이어에서는 커넥션 모니터링 외에는 특별한 전환 작업이 필요하지 않음
- 무중단 운영 작업 시 예전에는 local 데이터센터 내에서의 롤링만을 고려했는데, 현재의 구성을 통해 적은 부담으로 데이터센터 failover가 가능해지며 좀 더 많은 무중단 운영이 가능해짐
- 하지만 Standby 데이터센터는 DR로서의 역할을 해야 하기 때문에 동시에 write를 양쪽 데이터센터에서 받지 않고 DR 센터의 모든 서버에 대해
super_read_only상태를 유지하여 혹시 모를 깨질 가능성을 차단
장애 Case별 failover 시나리오
Active 데이터센터 Master 인스턴스의 장애 발생
-
Active 데이터센터의 01번(Master 인스턴스)에 장애 발생
-
MMM Monitor가 장애를 감지하고 failover를 수행
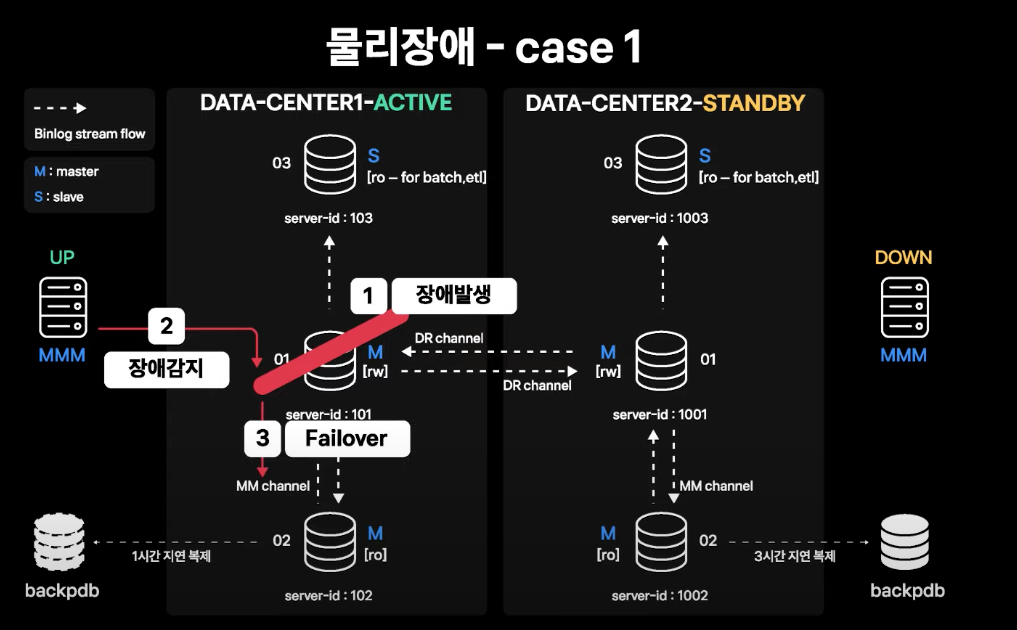
- Standby Master가 전송받은 모든 binlog를 적용한 것을 확인 후 Standby Master의
read_only를 해제 - 01번에 있는 Service IP를 Standby Master로 이동
-
앱 서버 커넥션이 Standby Master로 들어오면서 서비스가 정상화됨

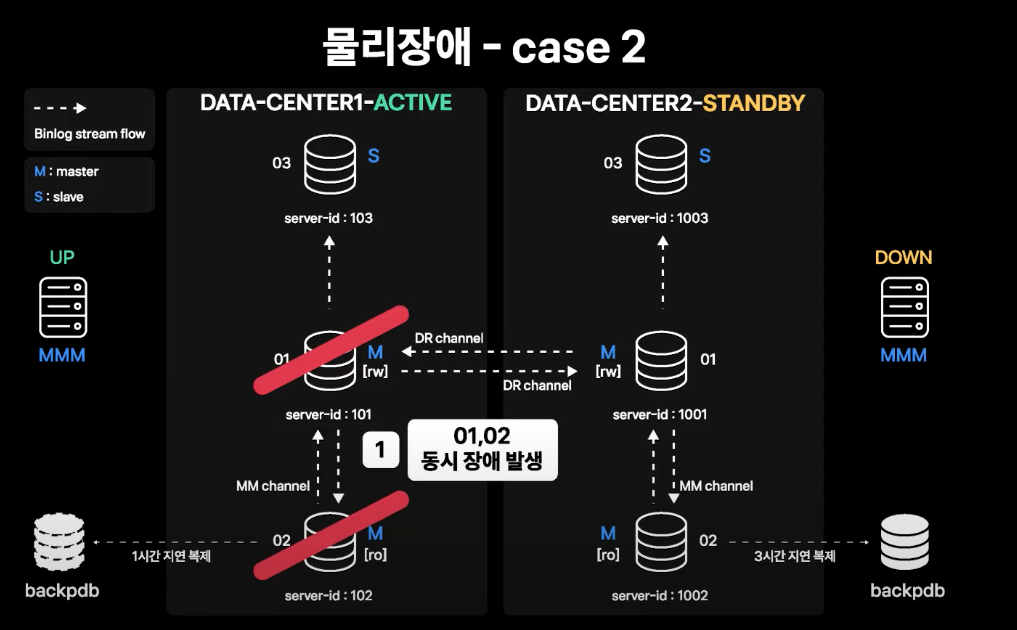
Active-Standby Master 양쪽 모두 장애 발생
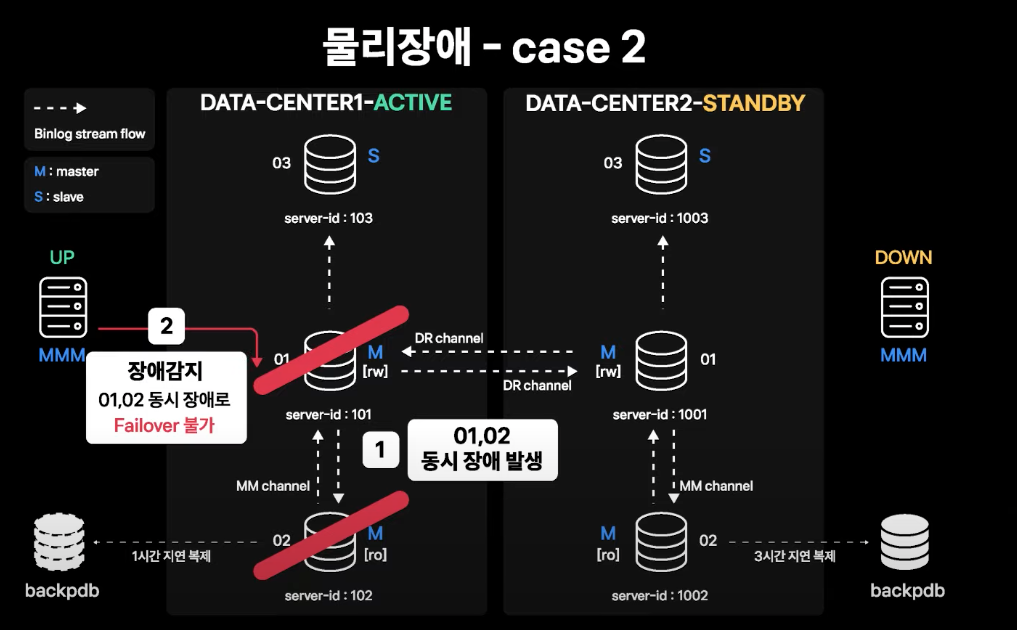
데이터센터 장애와 동일한 수준의 상황
- Active 데이터센터의 01, 02번(Active-Standby Master 인스턴스) 양쪽 모두에 장애 발생
- MMM에서 장애를 감지하지만, Standby Master도 장애가 발생하였으므로 failover 불가능
- DR 센터로의 failover
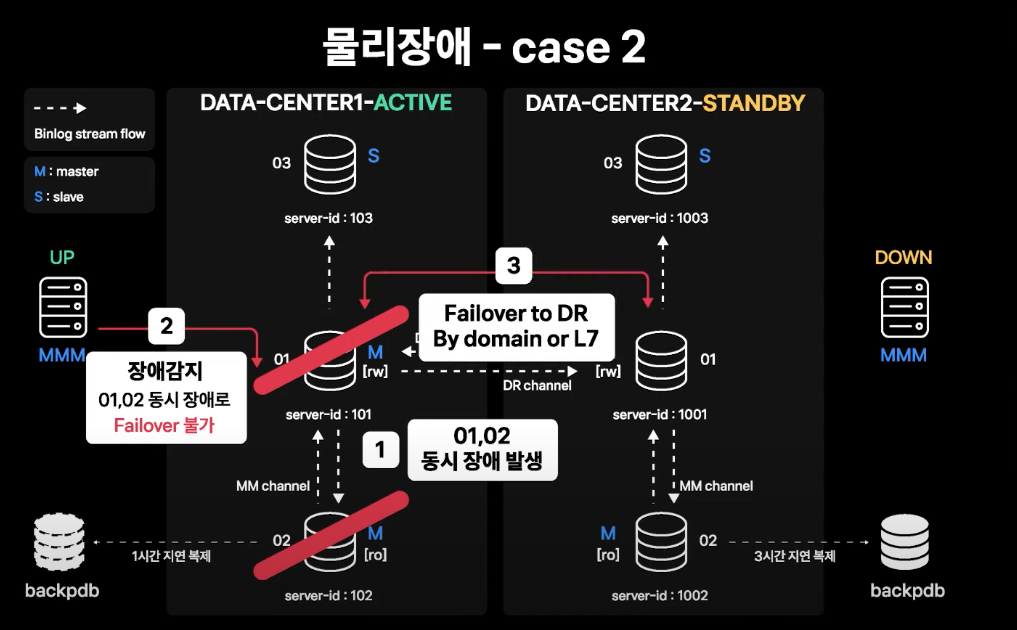
- 커넥션이 L7을 통해 DB 서버 커넥션을 맺고 있다면, L7 failover로 APP 서버의 커넥션은 바로 Standby 데이터센터로 넘어가게 됨
- 하지만 평상시에는 L7을 통해 DB 접속을 하고 있지 않으므로 Domain 타겟 변경을 통한 failover로 진행
- Domain 변경이 모두 적용되면 APP 서버가 DB로 재접속을 시도할 때 DNS resolve가 새로 되면서 커넥션이 Standby 데이터센터 Master로 맺어지게 됨
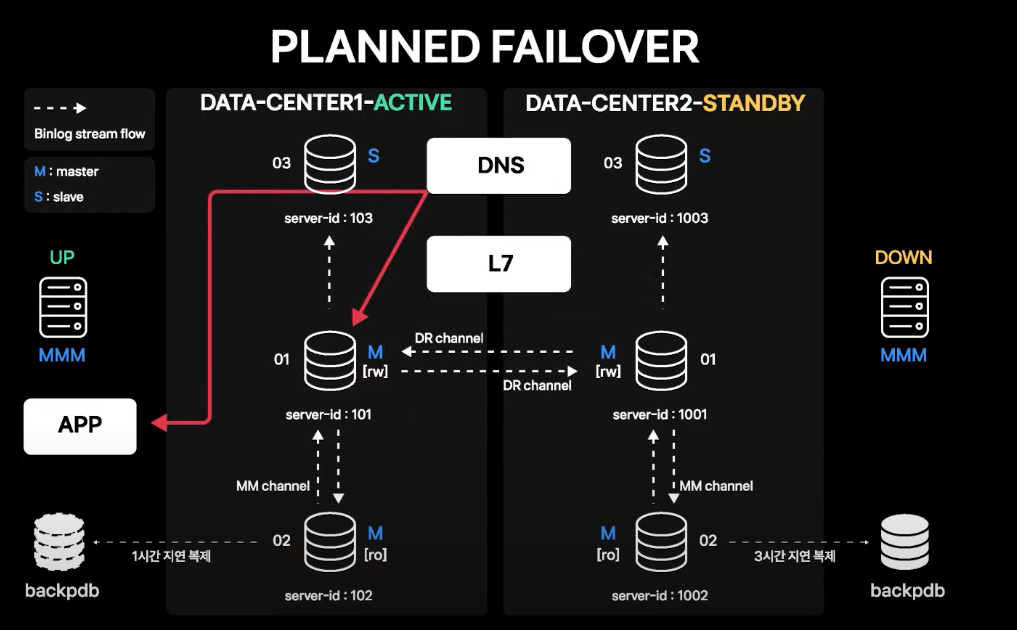
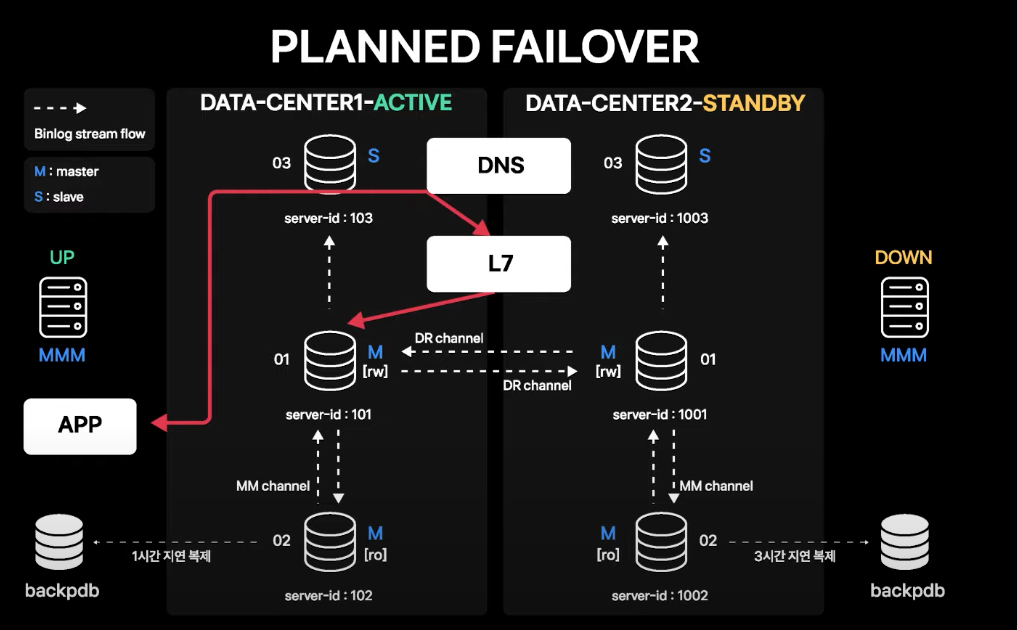
Planned Failover
-
평상시에는 APP 서버가 바라보는 DB 커넥션 도메인이 Service IP를 직접 가리키고 있음
-
L7 vip가 DB 서비스 IP로 Routing 되도록 설정하고, APP 서버의 커넥션 도메인은 L7을 가리키도록 DNS 변경 수행
-
모든 커넥션이 L7을 통해 맺어진 것이 확인되면, 계획된 시점에 L7 failover 기능을 통해 한 번에 커넥션을 Standby 데이터센터로 failover
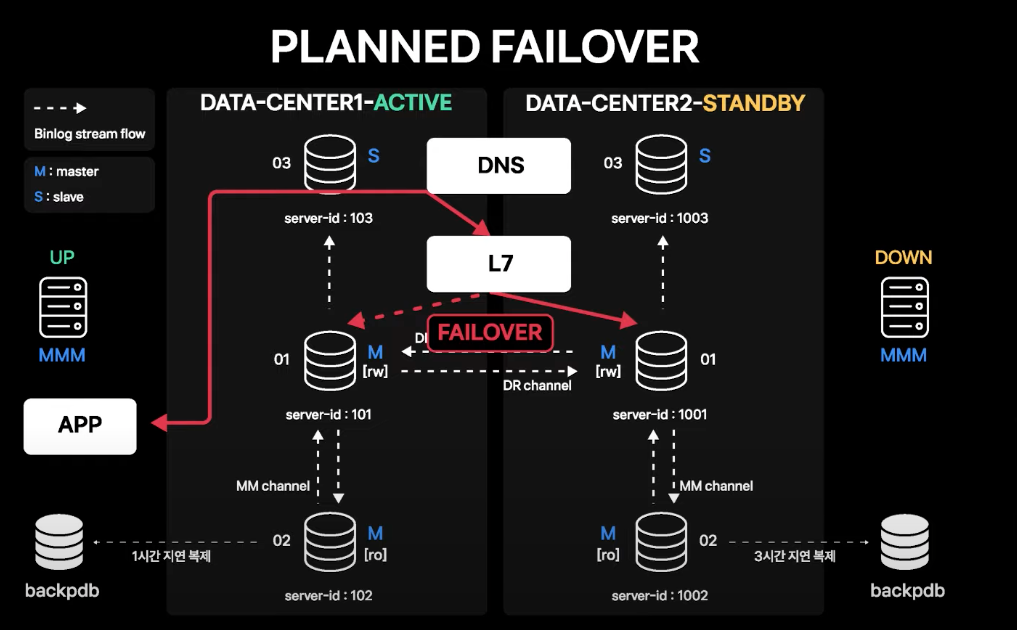
- Active 데이터센터에 맺어진 커넥션이 끊기고 재접속 시에 Standby 데이터센터로 맺어지게 됨
- 따라서 APP 서버에는 기존에 맺어져 있던 DB 커넥션이 한 번 끊어졌다가 다시 맺어지는 정도의 영향성만 있음
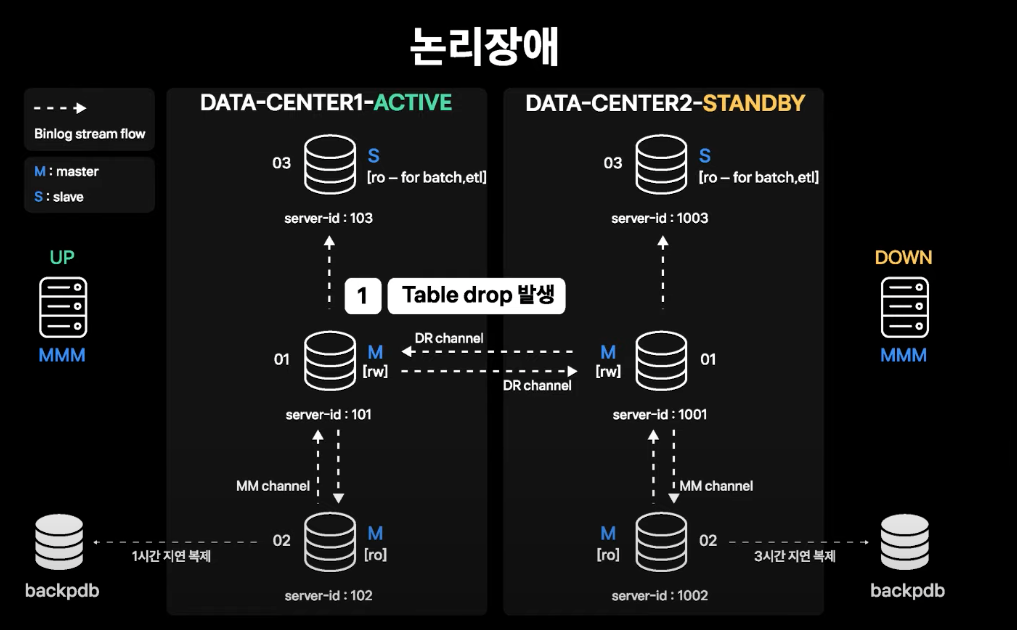
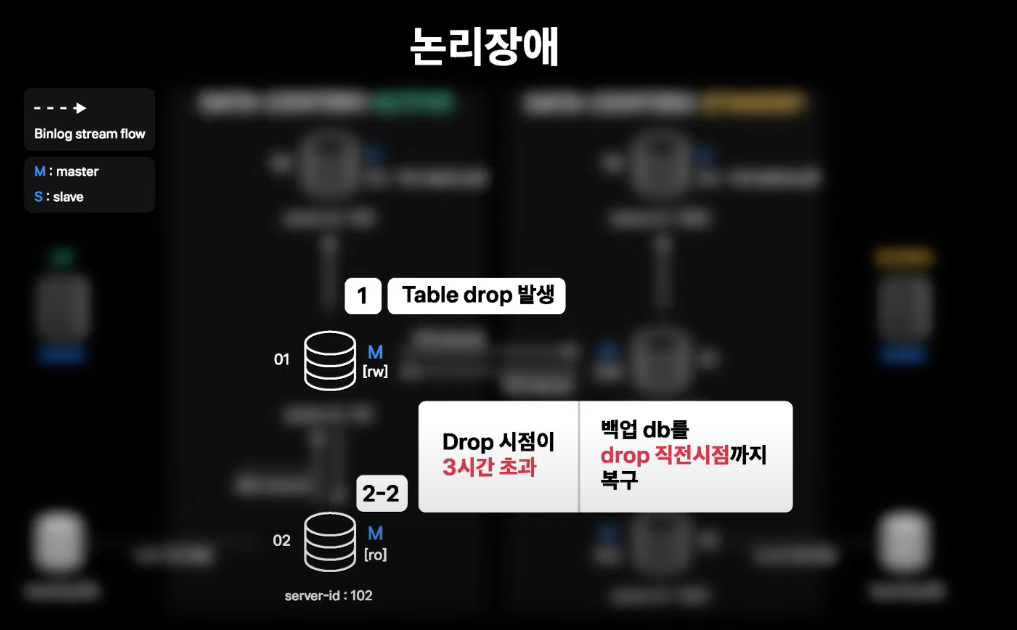
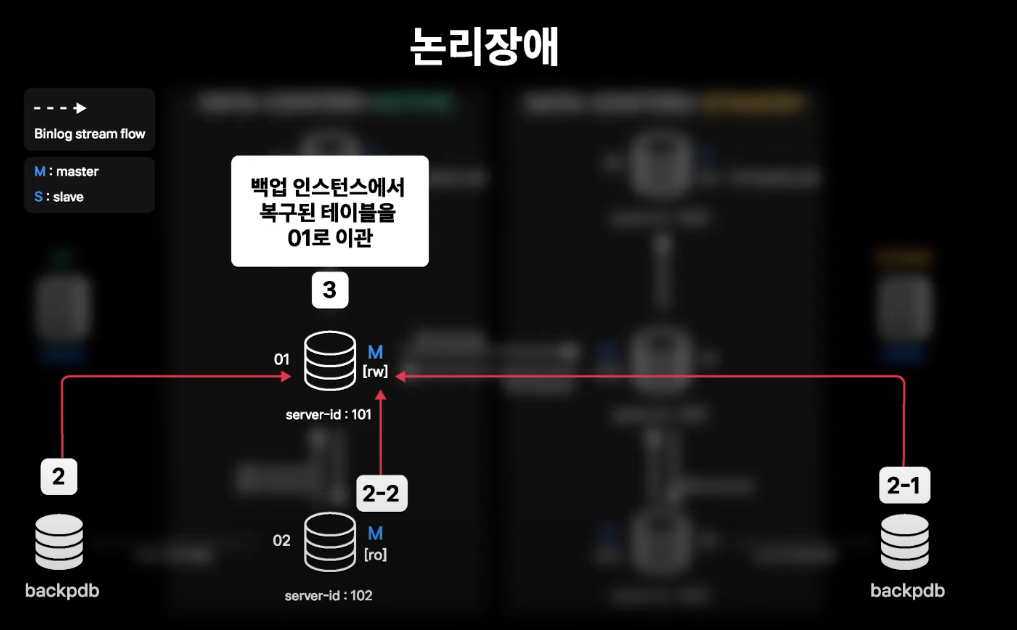
데이터 삭제 등 논리적 장애
- Table Drop이 발생하여 데이터 복구가 필요한 상황
- 백업을 위한 인스턴스가 각 데이터센터에 존재하고 해당 인스턴스는 지연 복제가 설정되어 있음
- Active 데이터센터는 1시간 지연 복제 설정
- Stadby 데이터센터는 3시간 지연 복제 설정
- Active 데이터센터는 1시간 지연 복제 설정
- 02번 서버에서는 Daily 당일 백업본을 유지하고 있음
- 복구를 위한 복제본과 백업본이 단계적으로 준비되어 있으므로 장애 이슈가 빨리 공유될수록 더 빠른 시간 내에 복구 가능
- 시점 복구가 완료되면 상황에 맞게 라이브에 적용하여 데이터 복구를 진행


데이터 불일치 상황에서의 failover 방지
MMM을 운영하며 발생할 수 있는 시나리오를 테스트한 내용
드물지만 실제 발생할 경우, 복구가 힘들어지는 장애 상황이므로 이에 대한 조치 사항을 정리한 내용
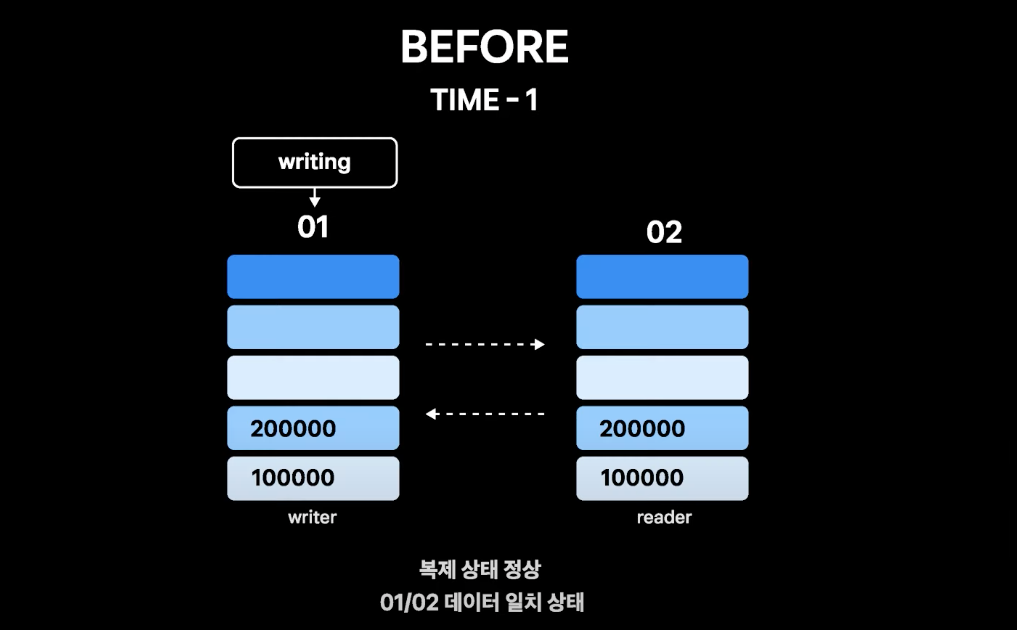
- 현재 01번이 read/write이고, 02번이 readonly
- TIME-1은 정상 복제 상황 01, 02번의 데이터 싱크가 유지되고 있는 상황
- TIME-2는 02번에서 장애가 발생하여 인스턴스가 죽었다 재시작되고 복제가 중지된 상황
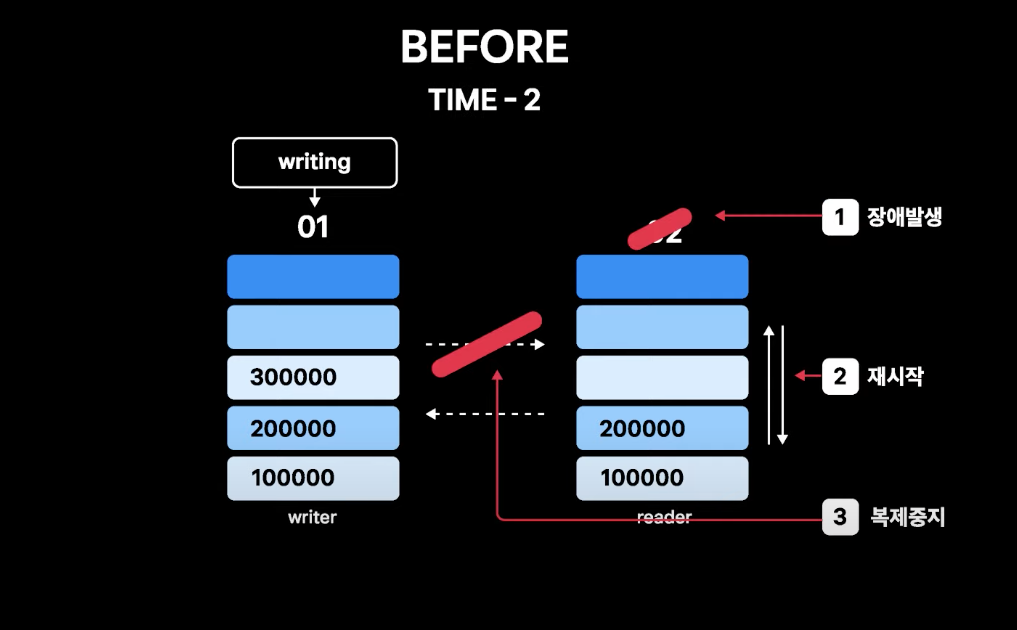
- 01번으로 write는 계속 들어오고 있고, 01번과 02번의 데이터 불일치가 점점 심해지고 있는 상황
- TIME-3은 02번의 복제 중지 상황이 해결되지 않은 상황에서 02번 인스턴스 장애의 원인이 된 쿼리가 01번으로 들어와 01번에도 장애가 발생하고 인스턴스가 재시작되어 MMM이 02번으로 failover를 실행
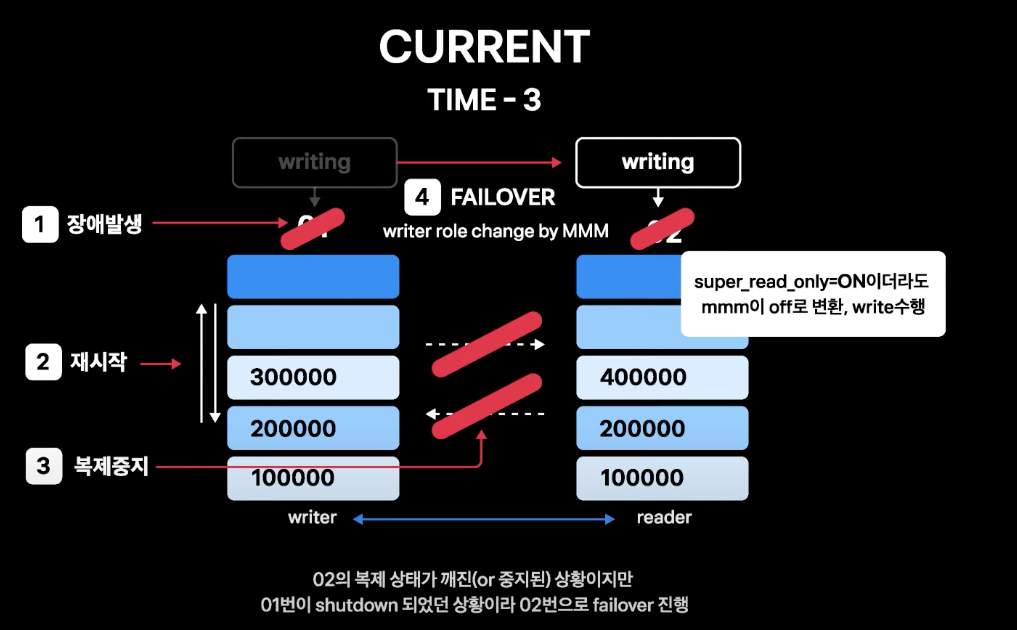
- 01번이 죽은 상황이기 때문에 MMM은 02번 상태에 상관없이 failover를 진행
- 02번은 복제 중지 이후 01번의 변경 내역을 싱크하지 못한 채로 write를 받게 됨
- 👉 불일치 데이터를 수동으로 모두 복구해야 하는 상황 발생
해결방안
- DB 인스턴스가 장애로 재시작될 때
super_read_only상태로 올라오도록 적용 - MMM이 failover 시에 DB가
super_read_only상태인 경우에는 이를 해제하지 못하고 failover 대기 상태에 머물도록 패치
- 해결방안 적용 이후 TIME-2에서 02번 장애로 인스턴스 재시작 시
super_read_only상태로 올라옴
- 복제는 중지 상태로 데이터 불일치는 점점 증가
- TIME-3에서 02번 복제 중지가 해결되지 않은 채 01번이 장애로 재시작
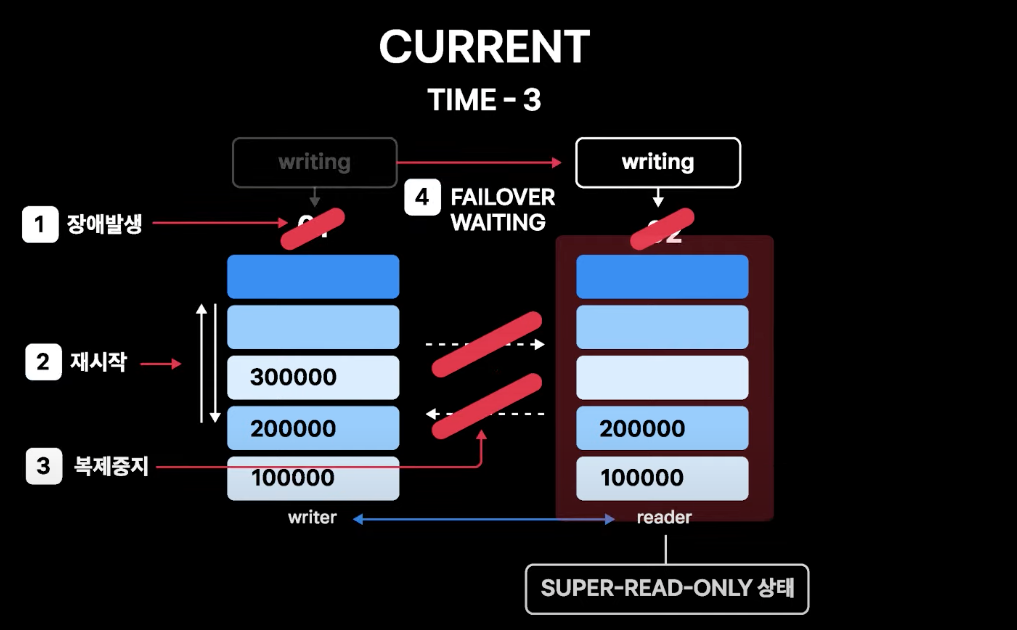
- 01번도
super_read_only상태로 올라오게 됨 - MMM은 02번으로 failover를 시도하지만 02번이
super_read_only상태임을 확인하고 failover를 진행하지 않음 - log에
super_read_only상태로 failover 불가하다는 메세지만 기록하고 failover 대기 상태 - APP에서 들어오는 write가 막히고 장애 상태가 지속되지만, 01/02번 데이터 불일치 상황에서의 write 발생으로 인한 복구 불가 데이터 불일치 상황은 막을 수 있음
- TIME-4에서 운영자가 개입하여 상황을 해결하고 서비스를 정상화

