
Hadoop Ecosystems
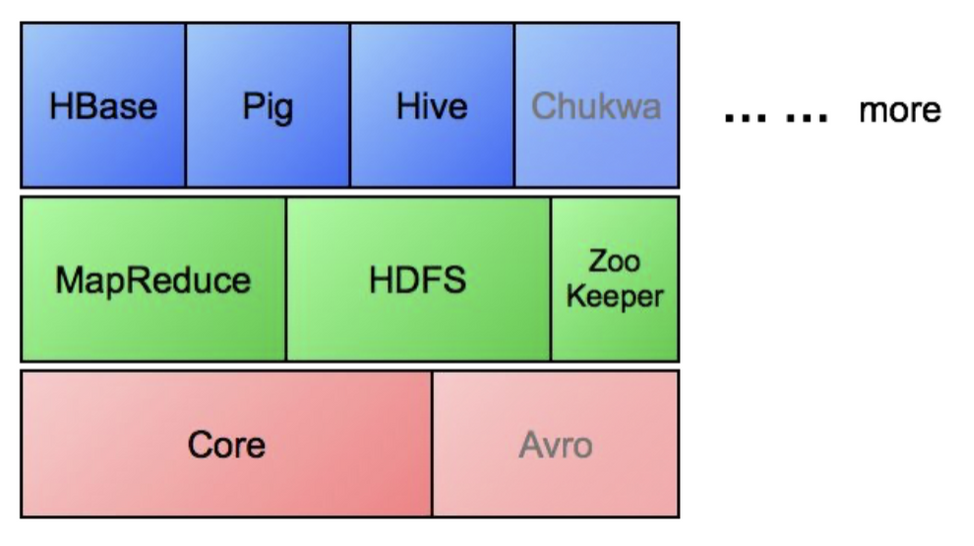
🔴 Core
- Filesystems and I/O
- Abstraction APIs. 추상화된 API
- 원격 프로시저 호출(RPC) / Persistence(지속성)
🔴 Avro
- Cross-language serialization
- 원격 프로시저 호출(RPC) 및 데이터 직렬화 프레임워크
- Persistence
- Google ProtoBuf, FB Thrift와 유사
🟢 MapReduce
- Distributed execution 분산 실행 (batch)
- Programming model
- Scalability 확장성 / fault-tolerance 장애에 대한 대응성
🟢 HDFS
- Distributed storage (read-option)
- Replication 복제 / scalability 확장성
- Google filesystem(GFS)과 유사
🟢 Zoo Keeper
- Coordination service. 코디네이션 서비스 시스템
- 분산된 시스템 간의 정보 공유
- 클러스터에 있는 서버들의 상태 체크
- 분산된 서버들간에 동기화를 위한 Lock 처리 (Locking)
- Google Chubby와 유사
🔵 HBase, Pig, Hive, ...
- Web-scale의 data-intensive application을 위한 범용 인프라 개발이 목표
HBase
MapReduce & HDFS
- 분산 스토리지 + computation
- batch processing(일괄 처리)에 적합
- 단점: 개별 항목에 액세스 또는 접근 불가
HBase
- HBase는 HDFS를 기본 저장소로 하는 key-value 저장소
- Batch & 랜덤 액세스 읽기/쓰기 가능
- Originally developed at Powerset
- Google의 Bigtable과 유사
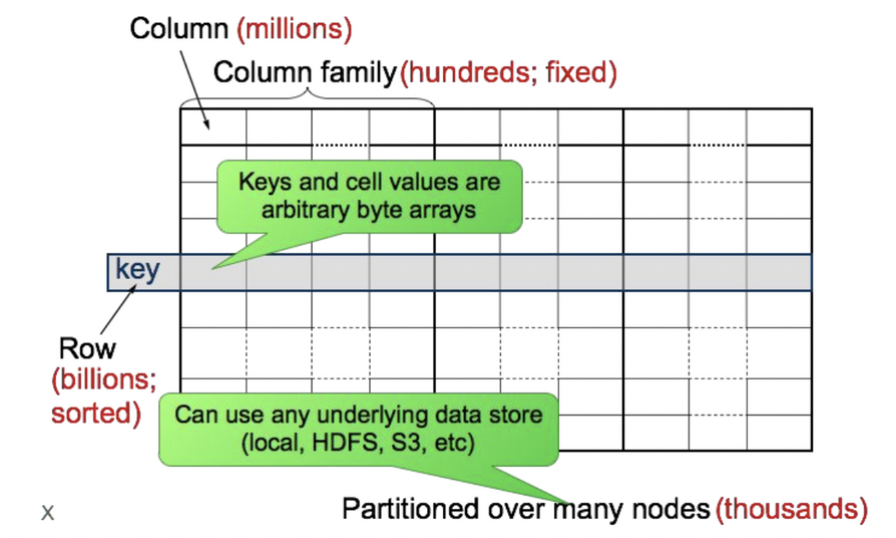
- Always access via primary key
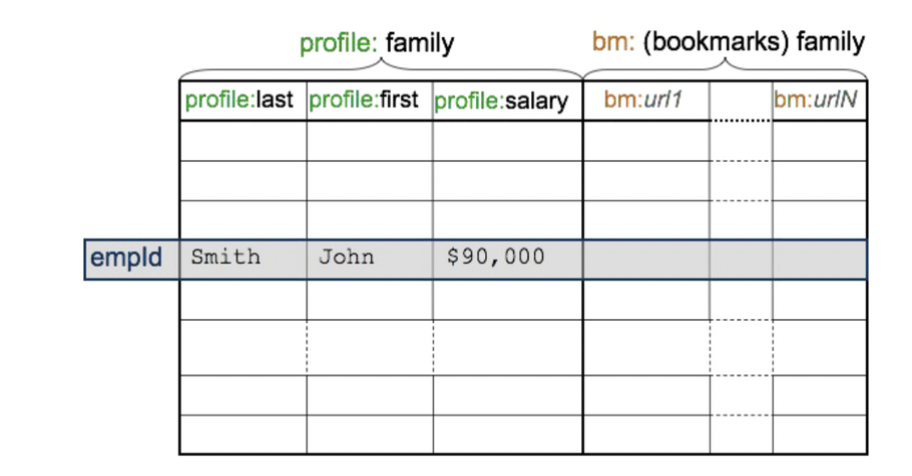
- Column-oriented database (컬럼 기반 데이터베이스)
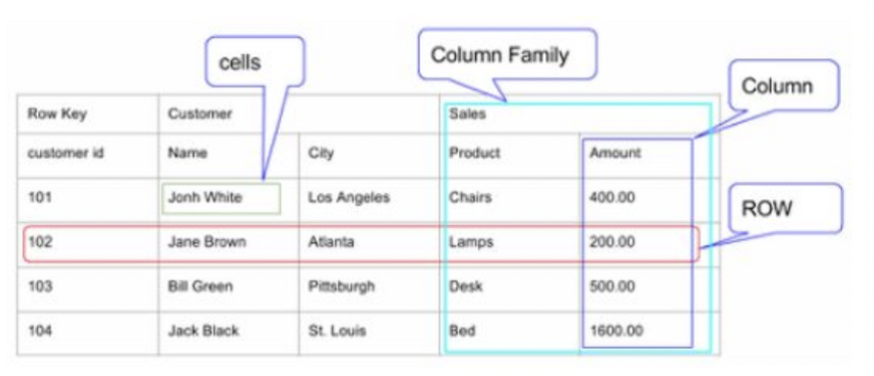
- Table: row의 집합
- Row: column family의 집합
- Column family: column의 집합
- Column: key, value 쌍의 집합
- 특정 컬럼의 전체 데이터 접근 시 효율적(sum, avg, ..)
ex) HBase, Cassandra
HBase vs RDBMS
- Different solution, similar problems
- RDBMS
- Row-oriented: 일부 데이터 접근 시 효율적
- 고정된 Schema
- ACID(Atomicity원자성, Consistency일관성, Reliability신뢰성, Isolation격리성)
- HBase
- Designed from ground-up to scale out, by adding commodity machines(여러개의 머신을 붙여 성능 향상)
- 단순한 일관성있는 Scheme: atomic row writes
- Fault tolerance (내결함성)
- Batch processing (일괄 처리)
- No (real) indexes
HBase vs MongoDB
- 대부분의 RDB 컨셉은 MongoDB 및 HBase와 유사성을 가짐
RDBMS MongoDB HBase Table Collection Table Row Documnet Column Family No Equivalent Shard Region GROUP_BY Aggrefation Pipeline MapReduce
Pig
- Data structures (multi-valued, nested)
- Pig-latin: Data flow language
- SQL에서 영감을 받은 절차적 언어(Procedural language)
- but imperative (선언적이지 않음)
- Execution enviroment
- “5줄 미만의 non-boilerplate code”
- boilerplate code: 최소한의 변경으로 여러곳에서 재사용되며 반복적으로 비슷한 형태를 띄는 코드
- 단일 MapReduce 작업 작성은 지루하다
- Boilerplates (mapper/reducer, create job, etc.)
- Input / Output formats
- 대부분의 task는 하나 이상의 MapReduce 작업이 필요
Frameworks Designs
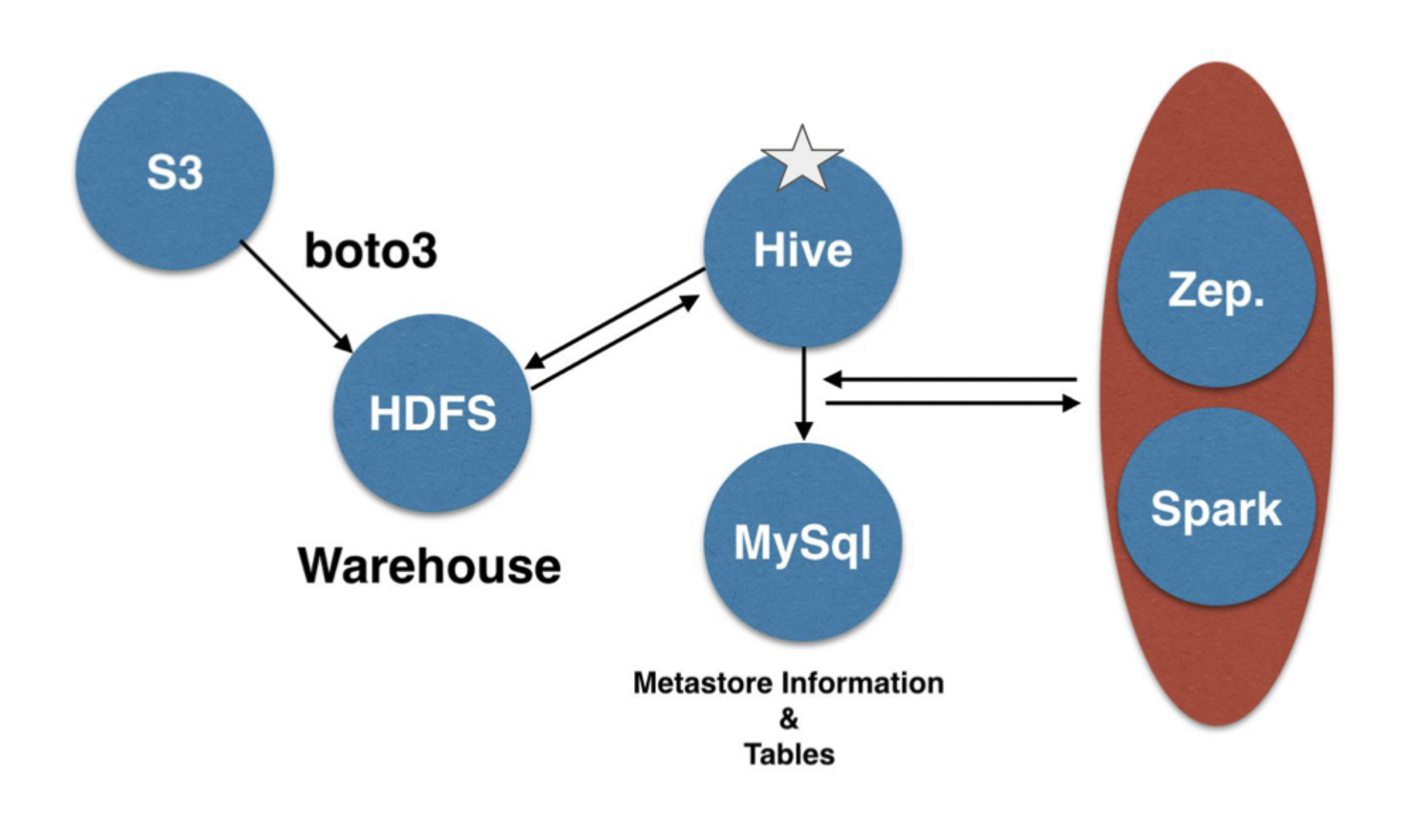
Hive
- Distributed data warehouse 분산 데이터 웨어하우스
- SQL-like query language
- Data mgmt 데이터 관리 / query execution 쿼리 실행
- Data가 table에 속해야함
- 하지만 기존 데이터도 사용 가능
- Data loading optional (like Pig) - 하지만 권장됨
- Partitioning columns
- partitioning: data 저장 시 물리적으로 잘 나눠서 저장. 추후 불러올 때 퍼포먼스 이득
-
paritioning이 없는 데이터에서 4-5월만 불러올 때 1-3월도 스캔 필요
-
데이터 저장 시 Hive에게 파티셔닝 지정 가능 → 4-5월의 위치를 알고있으니 풀 스캔 필요 없어짐
hive> show partitions kiwi OK year=2016/month=10/day=11 year=2016/month=11/day=17 year=2016/month=11/day=18 year=2016/month=11/day=28 year=2016/month=11/day=29 year=2016/month=12/day=13 year=2016/month=12/day=5 year=2017/month=1/day=5 year=2017/month=1/day=7 year=2017/month=1/day=9 year=2017/month=2/day=1 year=2017/month=2/day=2 Time taken: 0.337 seconds, Fetched 12 row(s)
-
- HDFS directory에 매핑됨
- E.g. (date, time) → datadir/2009-03-12/18_30_00
- partitioning: data 저장 시 물리적으로 잘 나눠서 저장. 추후 불러올 때 퍼포먼스 이득
- Data columns (the rest): HDFS file에 저장됨
- 가장 일반적인 데이터 타입 지원
- 플러그형 직렬화 지원
- Basic SQL
- FROM subqueries
- JOIN (only equi-joins)
- Multi GROUP BY
- Multi-table insert
- Sampling
- 확장성
- Pluggable MapReduce scripts
- User Defined Functions(UDF) - SQL에 삽입 가능
- User Defined Types
- SerDe (serializer / deserializer)
2022-2 KHU 빅데이터프로그래밍 수업을 기반으로 작성하였습니다.
