논문: MapReduce: Simplified Data Processing on Large Clusters
MapReduce
: Simplified Data Processing on Large Clusters
Intoduction
- 처리해야할 데이터 양이 점점 많아짐
- 기존 솔루션은 직렬적인 솔루션이 많았음
- MapReduce는 병렬처리 프로그래밍 모델
- Map과 Reduce 함수를 사용
- 복잡한 디테일들은 라이브러리에 숨겨둠(parallelization, fault-tolerance, data distribution, load balancing)
Programming Model
- Map: input을 받으면 key/value의 쌍을 생성
- Reduce: key/value 쌍을 이용해서 output 생성
Implementation
- 환경에 따라 다양한 인터페이스 구현
- 소형 공유 메모리 시스템
- 대규모 NUMA mult-processor
- 네트워크화 된 큰 시스템 컬렉션
Excution overview
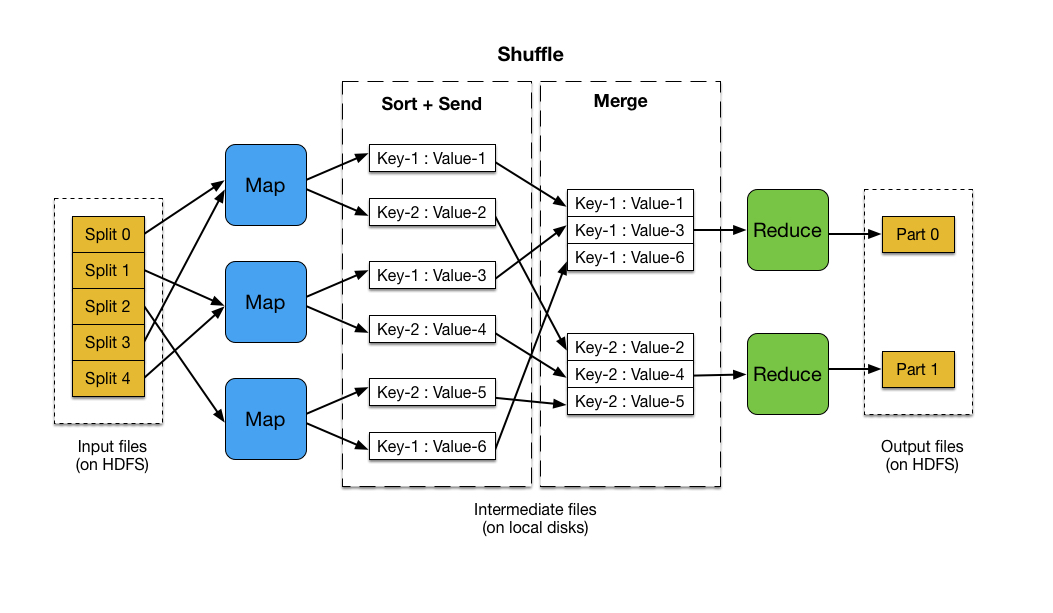
- Map invocations: input data를 partitioning하여 여러 시스템에 분산하면 M split set으로 분할됨
- Reduce invocations: intermediate key 공간을 R 조각으로 분할하여 분배
- intermediate key/value는 local에 저장됨
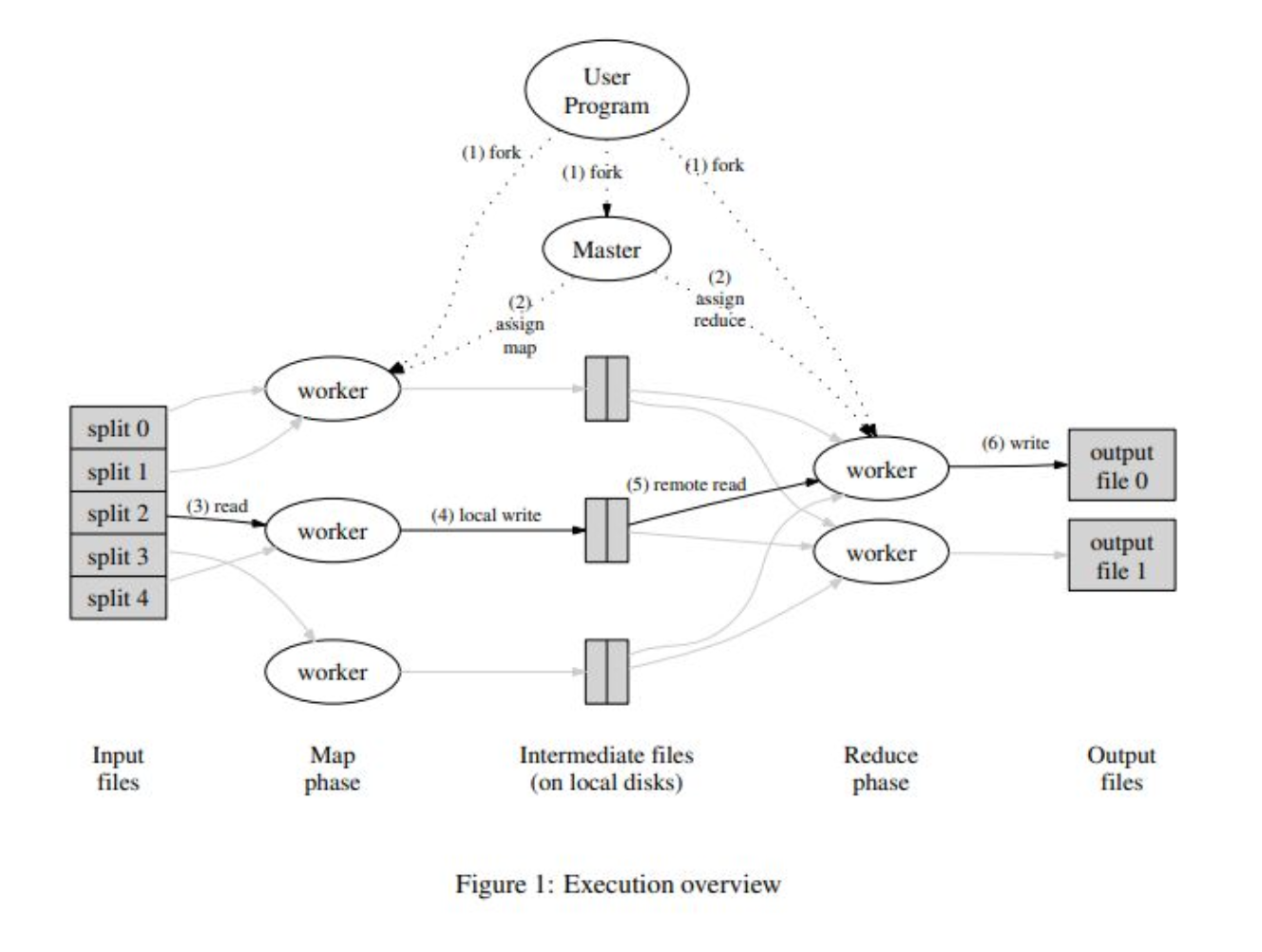
- Master worker: 각각의 worker가 어떤 일을 할 지, 메타데이터 등의 중요 정보들을 저장하고 관리하는 노드. 스케줄링
Master Data Structures
- 각 worker들의 상태 저장
- idle, 어떤 worker가 일하고있는지, 놀고있는지, 완료되었는지 등
- identity of the worker machine
- map 작업으로 생성된 R개의 intermediate file의 사이즈와 위치
Fault Tolerance
- Worker Failure
- master에서 worker들에게 계속 ping을 보냄
- ping에 응답이 없다면 해당 worker에 문제가 생겼다고 판단
- 해당 worker에게 보냈던 데이터를 다른 worker에게 보내서 처리하도록 함
- Master Failure
- Master는 주기적으로 checkpoint를 만든다
- 죽게된다면 가장 최근의 checkpoint로 복구
Locality
- 빠르게 데이터에 접근할 수 있도록 함
- 입력 데이터의 복제본을 만들면 마스터가 복제본에 따라 머신에서 각 worker를 initiate
Task Granularity
- 빠르게 처리 회복도 빠르게
- M과 R은 worker machine 수 보다 커야함
- 동적 로드밸런싱을 향상시키고 복구 속도를 높일 수 있음
Backup task
- backup task stabler?
- worker의 일이 끝나갈 쯤에 master가 백업(복제본)을 만들어두고 둘 중 하나가 먼저 끝나면 task 종료
- 잠깐동안만 계산량이 늘어나는 것이지, 전체 복잡도에 영향을 주지는 않음
Refinements
Partitioning Function
- Map에서 처리된 intermediate key/value를 각각의 Reducer로 보냄
- 생성된 intermediate key에 partitioning function을 이용하여 R Reduce task에 분할됨
- 해시함수 사용
- 데이터를 여러 위치에 분산하여 disk I/O performance 향상
- 매우 균형잡힌 결과를 보임
Ordering Guarantees
- 순서 보장
- 같은 단어끼리 묶어주는 것이 partition
- partition 내에서 intermediate key/value 쌍이 key 순서대로 처리되도록 보장
- partition별로 output file을 sort하고 suffle
- 검색 향상을 위해 sort 진행 (기본적으로 오름차순)
Combiner Function
- 맵에서 리듀서로 보내기 전에 미리 한 번 합쳐주는 것. Mini Reducer
- intermediate한 값들을 같은 키 값 기준으로 한 번 합쳐줌
Input and Output Types
- 다양한 input, output type 사용 가능
Side-effects 부작용
- output 결과가 reducer당 하나씩 발생
- 완료되었을 때 한 번 저장하는 것이 아닌 계속 임시적으로 저장
- 마지막으로 완전히 수행되었을때 덮어쓰는 느낌으로 저장됨
Skipping Bad Records
- 각종 버그들로 실행이 안되는 경우
- 유저 코드에 의해 오류 발생 시 어떤 오류가 발생했는지 오류 탐지 또는 탐지하는 것이 아닌 무시하고 실행 두 가지 중 선택 가능
- 무시하면 속도가 빨라짐
Local Execution
- 간단한 디버깅, 맵리듀스 자원 사용량, 작은 규모의 테스팅 사용 시 로컬로 머신 구동 가능
- 몇몇 task에는 제한 발생 가능
Status Information
- 웹 UI를 통한 모니터링 가능
- 완료되었는지, 어떤 에러가 발생했는지, 속도는 어떠한지
- 총 완료 시간 예상 등 가능
- 에러 버그 수정 가능
Counters
- 갯수 합산 ex) wordcount
- mapreduce 라이브러리의 counter class 사용 가능
- output 파일 뿐만 아니라 cmd 창에서도 결과 확인 가능
Performance
Grep
- 성능 평가 결과
- Grep: 유닉스에서 특정 문서에서 특정 단어나 문장을 찾아주는 기능
- 1746개 머신 사용, 기기당 2GHz 프로세서・4GB 메모리 사용
- 1테라바이트 크기에서 드물게 나타나는 3개의 문자열 패턴을 찾는 실험 수행
Sort
- 성능 평가 결과
- grep 실험과 동일한 환경, 데이터로 진행
- 머신 하나당 하나의 task를 가짐
- 한 번 먼저 처리 후 나머지 데이터를 처리
- 일반적인 경우 오버헤드 포함 891초 걸림
- 백업테스크를 하지 않는 경우 1283초 → 실패 감지, 재수행 진행 → 백업이 중요하다
- 백업테스크: worker가 일을 끝날때쯤 그대로 복제본을 만들어 두 개를 동시에 수행시키고 둘 중 먼저 끝나는 것을 채택하고 complete 후 task 종료
- 거의 끝났는데 종료되지않고 tail 발생: 에러로 인해 5개의 노드에서 실패, 종료 → 실패를 감지하고 처음부터 재수행 진행으로 인해 tail 시간 발생
- 200 task killed의 경우 933초 → 일반적인 경우와 크게 차이나지 않음
- input 과정에서 kill을 발생시킴
- kill이 발생해도 맵리듀스는 성능을 보장해준다
