Weather Dataset
- National Climatic Data Center
- http://www.ncdc.noaa.gov/
- 기상 센서들이 수집하는 대량의 로그데이터 → semi-structured, record-oriented
- 한 행이 하나의 레코드, 행 단위의 아스키코드 형식
- 기상관측소별로 측정된 정보는 gzip으로 압축되어 연도별 디렉토리에 위치함
- 수만 개의 기상관측소가 존재하기 때문에 전체 데이터셋은 상대적으로 작은 파일이 매우 많음
- 하둡의 특성상 소수의 큰 파일이 처리하기 쉽고 효율적
→ 다수의 파일을 연도를 기준으로 하나의 파일로 병합하기 위해 먼저 전처리 작업 수행 필요
- Dataset의 형식은 아래와 같음
0057
332130 # USAF weather station identifier
99999 # WBAN weather station identifier
19500101 # observation date
0300 # observation time
4
+51317 # latitude (degrees x 1000)
+028783 # longitude (degrees x 1000)
FM-12
+0171 # elevation (meters)
99999
V020
320 # wind direction (degrees)
1 # quality code
N
0072
1
00450 # sky ceiling height (meters)
1 # quality code
C
N
010000 # visibility distance (meters)
1 # quality code
N
9
-0128 # air temperature (degrees Celsius x 10)
1 # quality code
-0139 # dew point temperature (degrees Celsius x 10)
1 # quality code
10268 # atmospheric pressure (hectopascals x 10)
1 # quality codeAnalyzing the Data with Unix Tool
유닉스 도구 awk를 사용한 행 기반 데이터 처리
# NCDC weather dataset에서 연도별 최고 기온을 찾는 프로그램
#!/usr/bin/env bash
for year in all/* do
echo -ne `basename $year .gz`"\t" gunzip -c $year | \
awk '{ temp = substr($0, 88, 5) + 0;
q = substr($0, 93, 1);
if (temp !=9999 && q ~ /[01459]/ && temp > max) max = temp }
END { print max }'
done- 반복문으로 압축된 연도별 파일을 돌며 해당 연도를 출력한 후 awk를 이용해 각 파일을 처리
- awk 스크립트는 데이터에서 기온과 특성의 두 필드를 추출
- 기온에 0을 더하면 정수형으로 변환됨
- 기온이 유효한 값을 가지는지(9999는 누락된 값), 특성 코드가 측정 값을 신뢰할 수 있다고 보는지 점검 → 문제가 없다면 현재 최고 기온과 비교하여 갱신
- END 영역은 파일에 있는 모든 행이 처리된 후에 실행됨. 최종 최고 기온 출력
출력 결과
# 출력결과
% ./max_temperature.sh
1901 317
1902 244
1903 289
1904 256
1905 283...- EC2 High-CPU Extra Large Node 하나에서 한 century(100년)에 대해 전체 실행 시간은 42분 소요
- Operating in a parallel way? problems..
- 처리 속도 향상을 위해 parallel로 수행할 필요가 있음
- 이론적으로는 한 대의 머신에 있는 모든 하드웨어 thread를 활용해 연도별 파일을 서로 다른 프로세스에 할당하면 되지만, 문제점이 있음
- 작업을 정확히 같은 사이즈로 나누는 것은 매우 어려움
- diff의 결과 합병을 위해 프로세스에서 추가 처리 필요
- a single machine의 processing capacity(처리 능력)가 제한적
- 병렬 처리가 쉬워보이지만 실제로는 매우 복잡하기 때문에 하둡과 같은 프레임워크를 사용하는 것이 좋음
Analyzing the Data with Hadoop
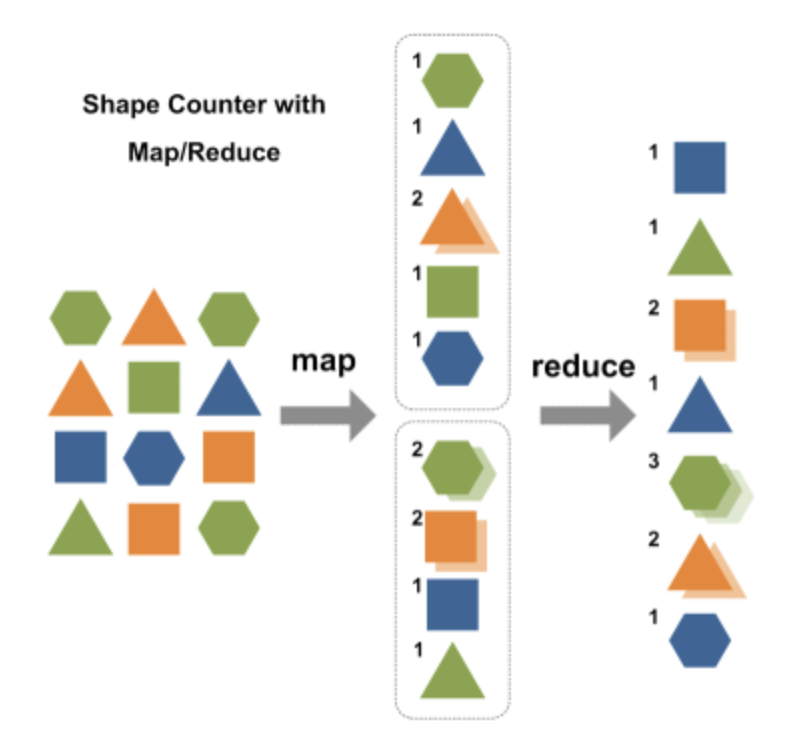
- MapReduce는 map 단계와 reduce 단계의 두 단계로 나누어 처리
- 각 단계는 입력과 출력으로 key-value 쌍을 가지며, type은 프로그래머가 선택 가능
- 프로그래머가 map 함수와 reduce 함수를 작성
- NCDC 원본 데이터
0067011990999991950051507004...9999999N9+00001+99999999999...
0043011990999991950051512004...9999999N9+00221+99999999999...
0043011990999991950051518004...9999999N9-00111+99999999999...
0043012650999991949032412004...0500001N9+01111+99999999999...
0043012650999991949032418004...0500001N9+00781+99999999999...Input to the map function
- 각 행의 타입을 텍스트로 인식하는 텍스트 입력 포맷 선택
- 값은 각 행(문자열)이고, 키는 파일의 시작부에서 각 행이 시작되는 지점까지의 오프셋
- 해당 데이터에서는 키가 의미가 없으므로 무시해도 됨
- 위와 같은 원본 데이터가 아래와 같이 key, value의 쌍으로 변환되고 map 함수의 입력이 됨
(0, 006701199099999**1950**051507004...9999999N9+**0000**1+99999999999...)
(106, 004301199099999**1950**051512004...9999999N9+**0022**1+99999999999...)
(212, 004301199099999**1950**051518004...9999999N9-**0011**1+99999999999...)
(318, 004301265099999**1949**032412004...0500001N9+**0111**1+99999999999...)
(424, 004301265099999**1949**032418004...0500001N9+**0078**1+99999999999...)Output from the map function
- map 함수는 연도와 기온(위에서 bold 처리된 숫자)을 추출하여 output으로 내보냄
- 기온은 정수형으로 변환됨
(1950, 0)
(1950, 22)
(1950, -11)
(1949, 111)
(1949, 78)Input to the reduce function
- map의 output이 reduce의 input으로 보내지는 과정은 맵리듀스 프레임워크에 의해 처리됨
- key(연도)-value(기온) pair는 key를 기준으로 정렬되고 그룹화됨
(1949, [111, 78])
(1950, [0, 22, -11])Output from the reduce function
- 연도별로 측정된 모든 기온값이 하나의 리스트로 묶임. reduce 함수는 리스트 전체를 반복하여 최고 측정값을 추출
(1949, 111)
(1950, 22)2022-2 KHU 빅데이터프로그래밍 수업을 기반으로 작성하였습니다.
