MapReduce
Map side와 Reduce side로 나뉜다.
Map은 HDFS에서 데이터를 읽어온다.
Mapper가 데이터를 저장할 땐 각각의 Mapper의 Filesystem disk에 intermediate data 저장하게 되며 Reducer에 데이터를 복사한다.(네트워크로 전송)
Reducer의 결과는 HDFS에 저장된다.
- Map output은 HDFS에 쓰여지는 것이 아닌 local disk에 쓰여짐
- map output은 intermediate output(중간 출력)이다.
- 최종 output 생성을 위해 reduce task에 의해 처리되며, job 완료 시 map output이 버려질 수 있음
- 따라서 map output을 replica와 함께 HDFS에 저장하는 것은 과도한 작업
- 일반적으로 single reduce task의 input은 모든 mapper의 output
- → Reduce task에는 data locality의 이점이 없음
- 정렬된 map output은 네트워크를 통해 reduce task가 실행중인 node로 전송되어야 함
- 그 후 merge를 수행하고, user-defined reduce function으로 전달
- reduce output은 일반적으로 reliability를 위해 HDFS에 저장됨
- reduce output의 각 HDFS block에 대해 첫 replica는 local node에 저장되며, 다른 replica는 reliability를 위해 off-rack node에 저장됨
- 따라서 reduce output의 write 작업은 network bandwidth를 사용하지만, 일반 HDFS write pipeline만 사용함
- reduce task의 수는 input size에 의해 정해지는 것이 아닌, 독립적으로 지정됨
MapReduce logical data flow
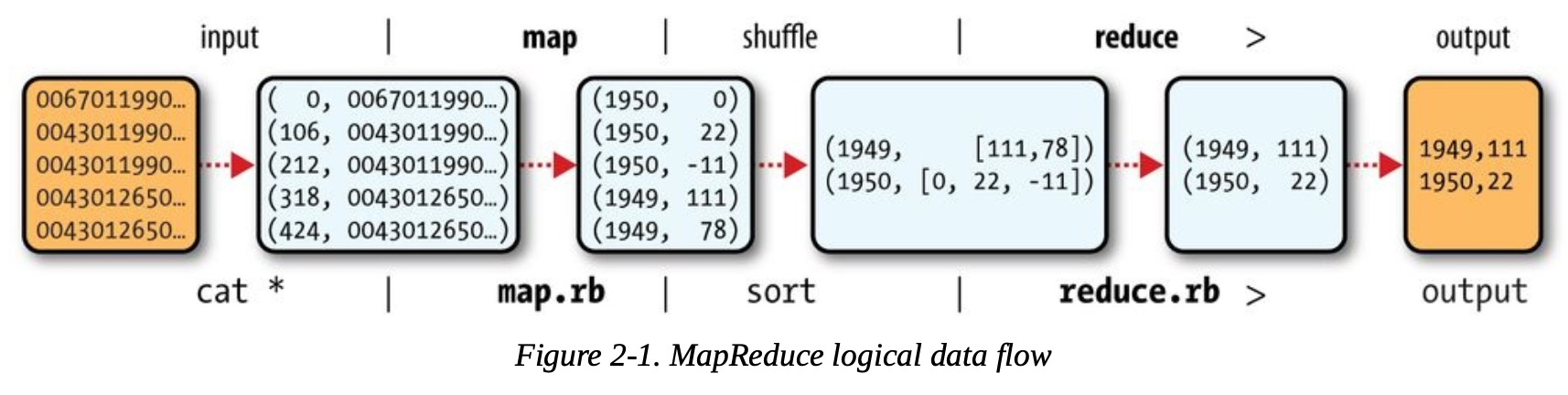
- 위는 Weather Dataset 병렬 처리 비교 시에 사용된 Hadoop 처리 구조를 도식화한 그림
- Unix tools: 42 minutes
- Hadoop: 6 minutes using ten EC2 machines
single reduce task의 경우
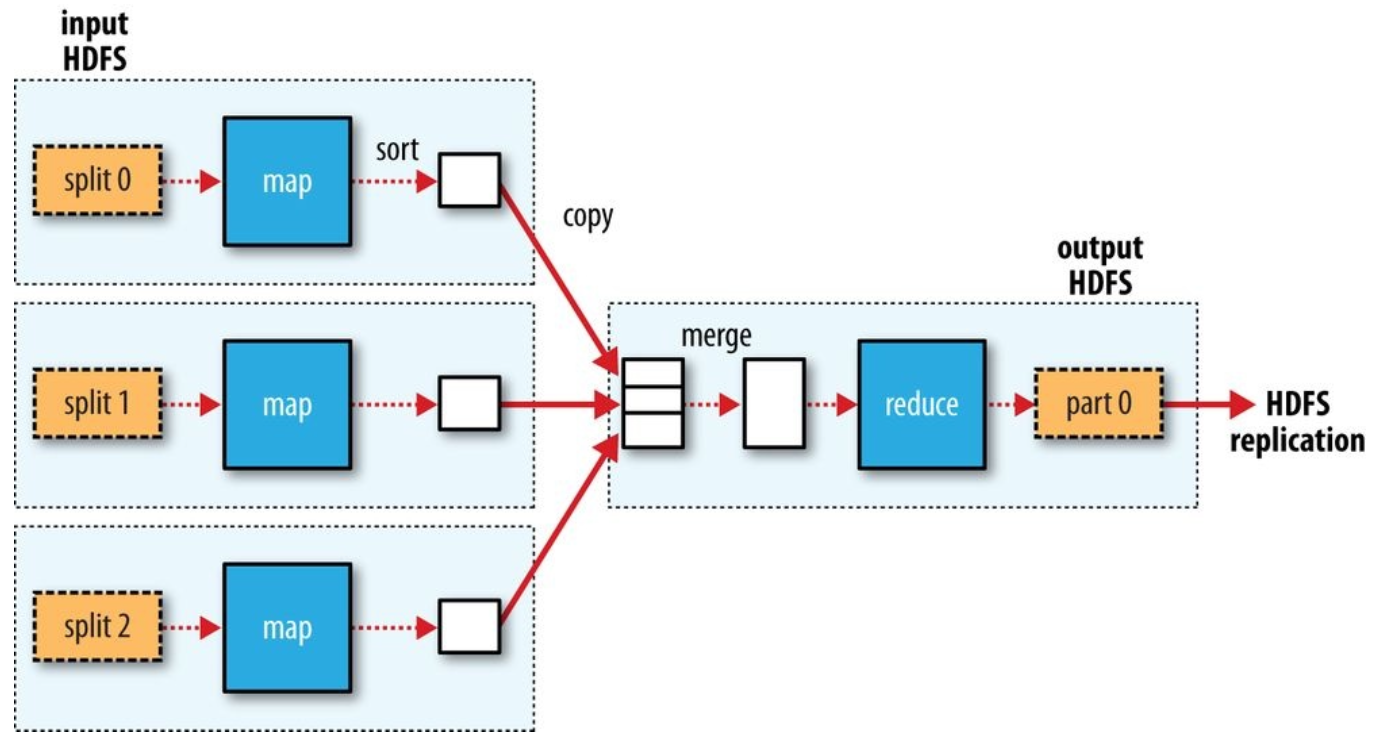
- 점선 상자: node
- 점선 화살표: node에서의 data transfer
- 실선 화살표: node간 data transfer
multiple reduce tasks의 경우
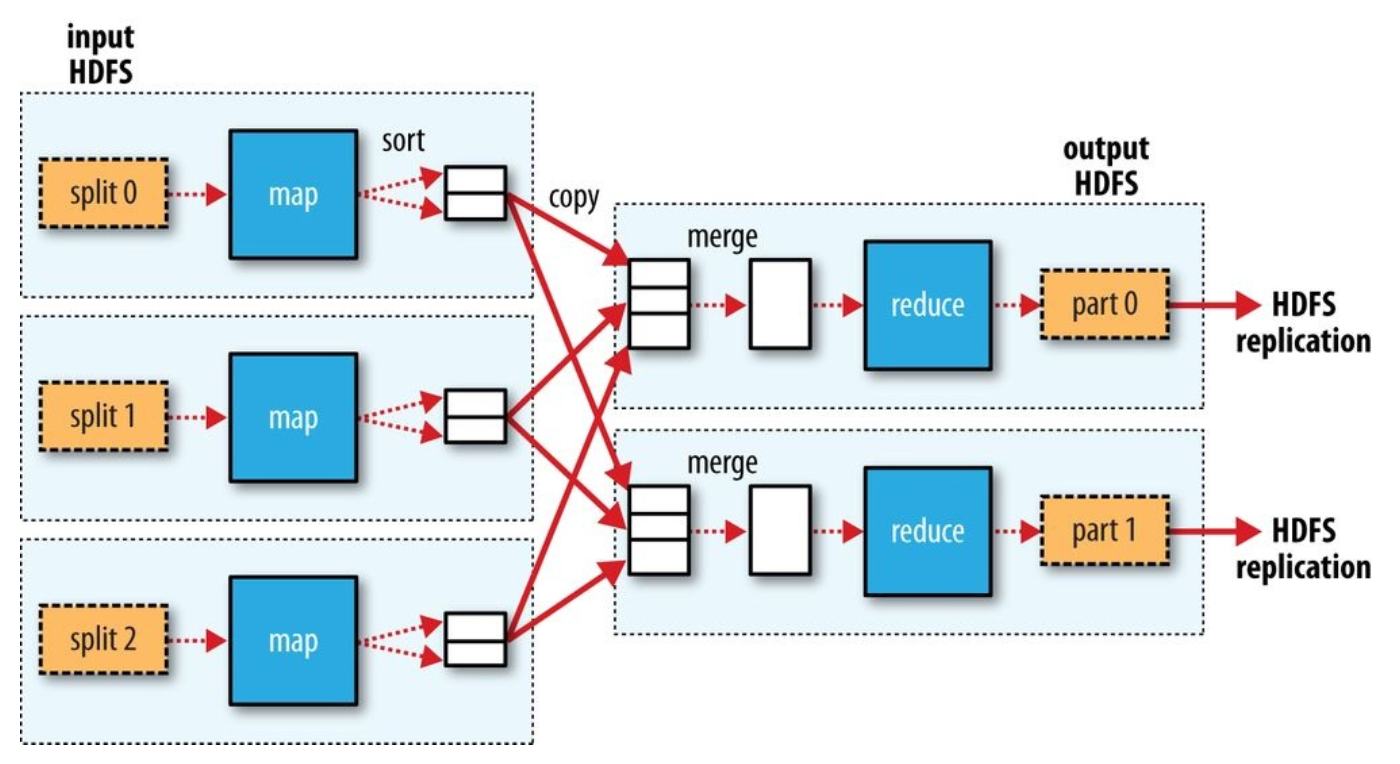
- reducer가 여러개인 경우, map task는 output을 partitioning함. reducer당 partiton 하나
- 각 partition에는 여러 key(및 해당하는 value)가 있을 수 있지만, key에 해당하는 레코드들은 모두 single partition 안에 존재
- partitioning은 user-defined partitioning function을 지정할 수 있지만, 일반적으로 default partitioner를 사용 (hash function을 사용하여 key를 bucket)
zero reduce task의 경우
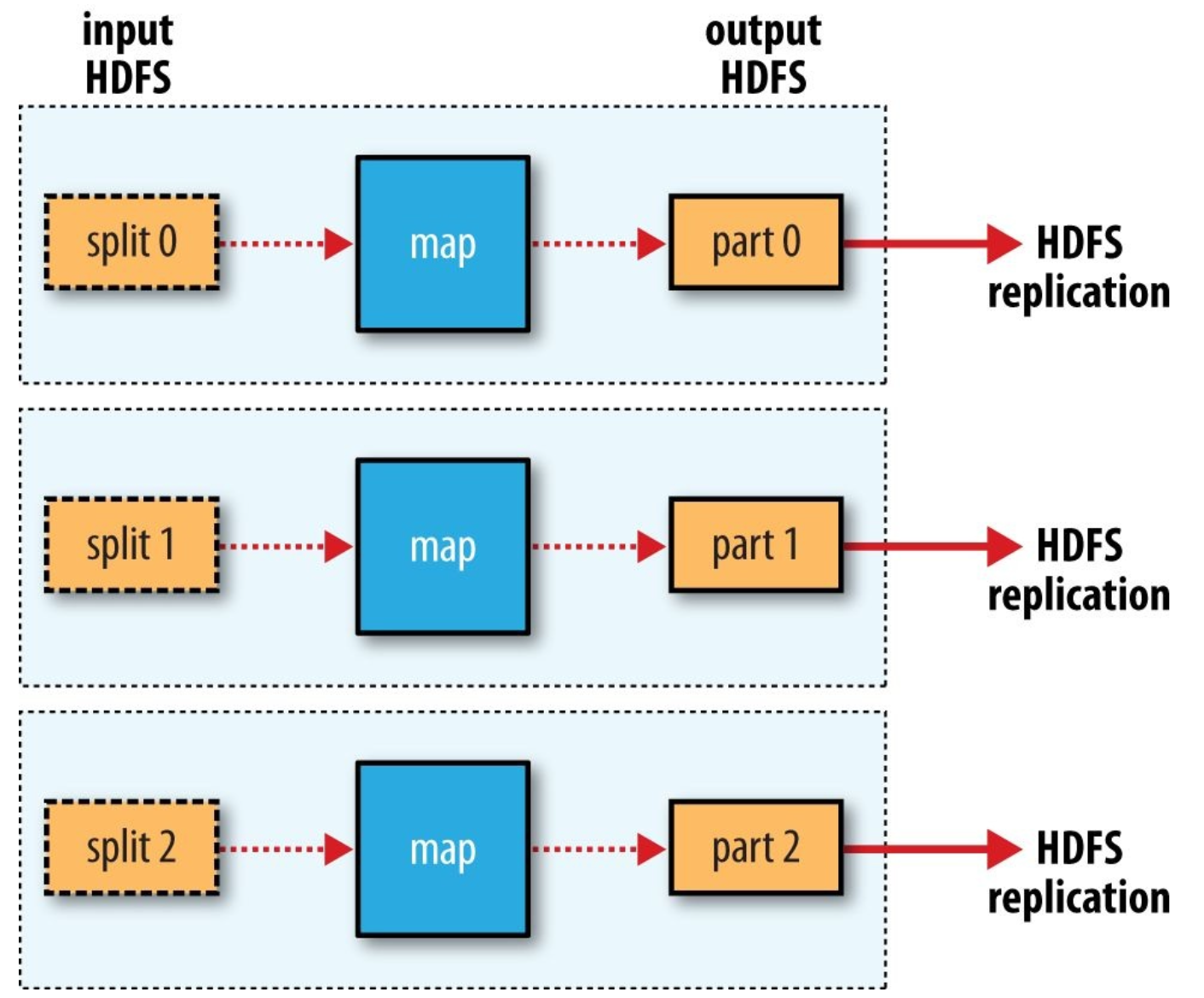
- process가 완전히 병렬로 수행될 수 있으므로 Shuffle이 필요하지 않은 경우 사용 가능
- 이 경우, 유일한 off-node data transfer는 HDFS에 write하는 작업
MapReduce는 map task와 reduce task 간의 data transfer를 최소화해준다.
Combiner function
-
Hadoop에서는 map output에 combiner function을 사용자가 정의할 수 있음
-
ex) 최고 온도 예제에서 1950년도의 데이터가 2개의 map에 의해 처리되었다고 가정
- Map 1 output
(1950, 0)
(1950, 20)
(1950, 10) - Map 2 output
(1950, 25)
(1950, 15) - reduce function은 모든 value의 list와 함께 호출됨
(1950, [0, 20, 10, 25, 15]) → (1950, 25)
- Map 1 output
-
하둡에서 combiner를 사용하는 경우
- max(0, 20, 10, 25, 15) = max(max(0, 20, 10), max(25, 15)) = max(20, 25) = 25
- 평균 계산에서는 combiner 적용 불가능
- combiner function을 적용할 수 있는 function이 제한되어있음
- combiner 추가 시 코드에서 한 줄 만 추가해주면 됨
job.setCombinerClass(MaxTemperatureReducer.class);
public class MaxTemperatureWithCombiner {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: MaxTemperature <input path> <output path>");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}Combiner
- shuffled data의 양을 줄이는데 도움
- shuffled: map에서 끝나고 reduce로 넘겨주는 과정 shuffled data
- 이때문에 MapReduce job에서 combiner를 사용할 수 있는지 고려해보는 것이 좋다
- combiner function이 reduce function을 대체할 수는 없음
Java MapReduce
- 최고 기온을 구하는 Mapper
// cc MaxTemperatureMapper Mapper for maximum teperature example // vv MaxTemperatureMapper import java.io.IOException; import org.apache.hadoop.io.IntWritable; // 자바 Integer에 해당 import org.apache.hadoop.io.LongWritable; // 자바 Long에 해당 import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class MaxTemperatureMapper **extends Mapper<LongWritable, Text, Text, IntWritable>** { ⭐️ private static final int MISSING = 9999; @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String year = line.substring(15, 19); int airTemperature; if (line.charAt(87) == '+') { // parseInt doesn't like leading plus signs airTemperature = Integer.parseInt(line.substring(88, 92)); } else { airTemperature = Integer.parseInt(line.substring(87, 92)); } String quality = line.substring(92, 93); if (airTemperature != MISSING && quality.matches("[01459]")) { context.write(new Text(year), new IntWritable(airTemperature)); } } } // ^^ MaxTemperatureMapper- Mapper class는 generic 타입. 네 개의 정규 타입 매개변수(입력키, 입력값, 출력키, 출력값)
- 예제에서 입력키는 long integer type의 offset, 입력값은 한 행의 내용, 출력키는 연도, 출력값은 기온(int)
- 최적화된 네트워크 직렬화를 위해 내장 자바 타입 대신 자체 기본 타입 셋을 제공
- org.apache.hadoop.io 패키지
- Text를 substring()을 이용하여 String으로 변환하여 관심있는 column을 추출
- output을 write하기 위한 Context instance를 제공
- 연도(output key)를 Text Object로 write, 온도(output value)를 IntWriable로 wrap
- 온도가 있고 quality code가 정상임을 나타내는 경우에만 output record를 write
- 최고 기온을 구하는 Reducer
// cc MaxTemperatureReducer Reducer for maximum teperature example // vv MaxTemperatureReducer import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class MaxTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int maxValue = Integer.MIN_VALUE; for (IntWritable value : values) { maxValue = Math.max(maxValue, value.get()); } context.write(key, new IntWritable(maxValue)); } } // ^^ MaxTemperatureReducer- reduce 함수의 input type은 map 함수의 output type과 동일해야함
- reduce 함수의 output type은 연도(Text), 최고온도(IntWritable)
- The third piece of code runs the MapReduce job
import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MaxTemperature { public static void main(String[] args) throws Exception { if (args.length != 2) { System.err.println("Usage: MaxTemperature <input path> <output path>"); System.exit(-1); } Job job = new Job(); job.setJarByClass(MaxTemperature.class); job.setJobName("Max temperature"); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setMapperClass(MaxTemperatureMapper.class); job.setReducerClass(MaxTemperatureReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); System.exit(job.waitForCompletion(true) ? 0 : 1); } }- Hadoop Cluster에서 job 실행 시 코드를 JAR 파일로 패키징 (Hadoop이 Cluster에 배포)
- JAR 파일의 이름을 명시적으로 지정하지 않고 job의 setJarByClass() method를 통해 class를 전달
- Hadoop은 class를 포함하는 관련 JAR 파일을 찾음
- input path 지정
- input path는 FileInputFormat에서 static addInputPath() method를 호출하여 single file 또는 directory 또는 file pattern으로 지정
- addInputPath를 여러번 호출하여 여러 경로의 입력 사용 가능
- output path 지정
- output path는 FileOutputFormat의 static setOutputPath() method를 호출하여 파일이 쓰여질 directory를 지정
- 실행 전에 directory가 존재해서는 안됨 → Hadoop이 job을 실행하지 않음
- 파일 중복 시 하둡 정책 상 exception 처리. 덮어씌우기 없음. data loss 방지
- 이전 작업의 output을 실수로 다른 작업의 output으로 덮어쓰여질 수 있기 때문
- setMapperClass()와 setReducerClass()를 통해 사용할 map과 reduce type 지정
- setOutputKeyClass()와 setOutputValueClass()는 reduce의 output type을 제어
- reduce class가 생성하는 것과 일치해야 함
- map output은 기본적으로 동일한 type으로 설정됨. mapper가 reducer와 동일한 type을 생성하는 경우 설정할 필요 없음
- 만약 map output type이 다른 경우 setMapOutputKeyClass()와 setMapOutputValueClass()로 map output type 설정 필요
- input type은 기본 TextInputFormat을 사용하므로 명시적으로 설정 필요 없음
- waitForCompletion은 job을 제출하고 완료될때까지 기다림
- 단일 argument는 진행률에 대한 상세 정보 출력 여부 설정 flag
- exit code 0 또는 1 (success or fail)을 return
- Hadoop Cluster에서 job 실행 시 코드를 JAR 파일로 패키징 (Hadoop이 Cluster에 배포)
- A test run
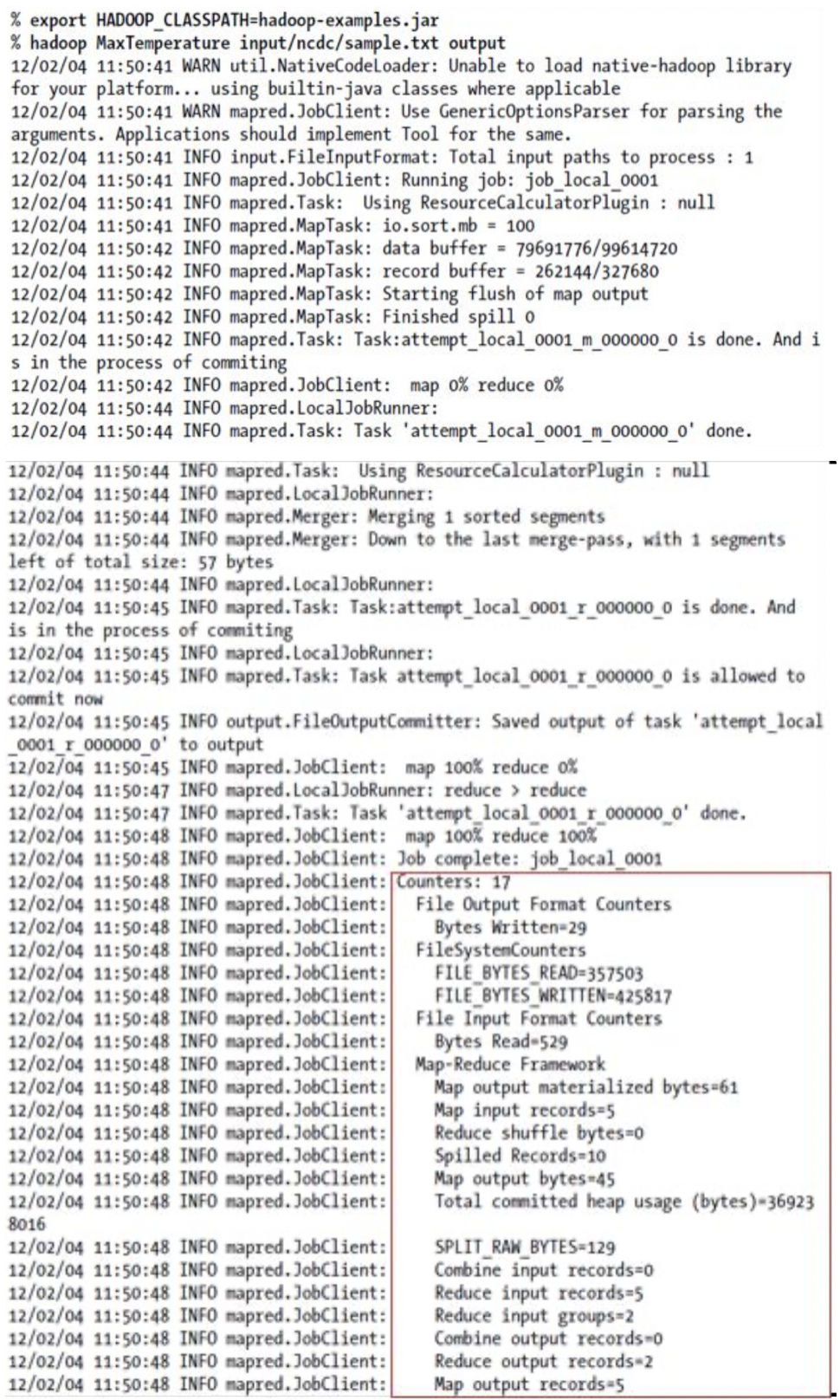
- Hadoop command가 classname을 첫번째 argument로 사용하여 호출되면 class를 실행할 Java Virtual Machine(JVM)을 실행
- Hadoop command는 Hadooop library를 classpath에 추가하고 Hadoop config를 선택
- application class를 classpath로 추가하기 위해 HADOOP_CLASSPATH 환경변수에 정의함
- local mode에서 실행 시 사용자가 HADOOP_CLASSPATH를 이러한 방식으로 설정 필요. command는 code가 있는 directory에서 실행
- The output from running the job provides some useful information
- job에 지정된 ID, 실행된 map task와 reduce task의 수와 ID
- job ID와 task ID를 알면 MapReduce job을 디버깅할 때 유용
- Counter값 분석
- Hadoop이 실행하는 각 job에 대해 생성된 통계를 보여줌
- 처리된 데이터의 양이 예상한 양인지 확인 가능
- Output
-
output은 output directory에 기록됨. reducer당 하나의 output 파일
% cat output/part-00000 1949 111 1950 22
-
Hadoop Streaming
- 하둡은 java 외의 언어로도 map과 reduce function 작성 가능하도록 MapReduce API를 제공
- 하둡과 프로그램 간의 interface로 Unix standard stream을 사용하기 때문에 다른 언어 사용 가능
- e.g. Python
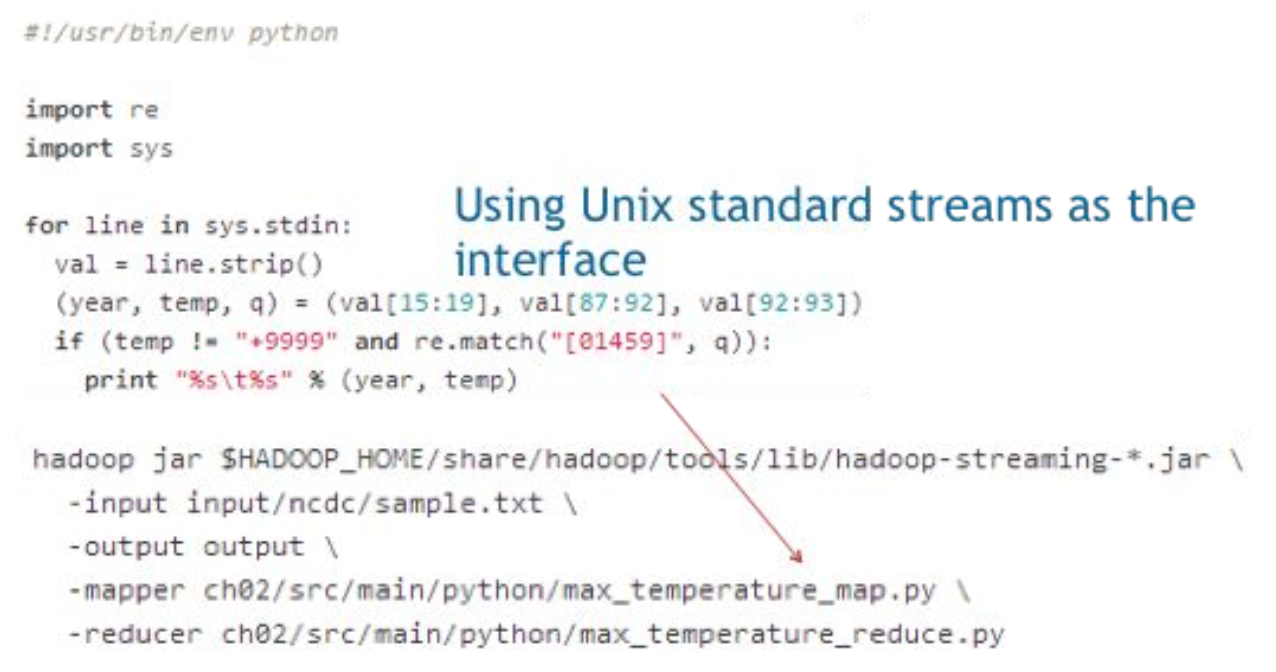
- e.g. Python
Hadoop Pipes
- Hadoop Pipes is the name of the C++ interface to Hadoop MapReduce
-
Using Sokets instead of standard streams
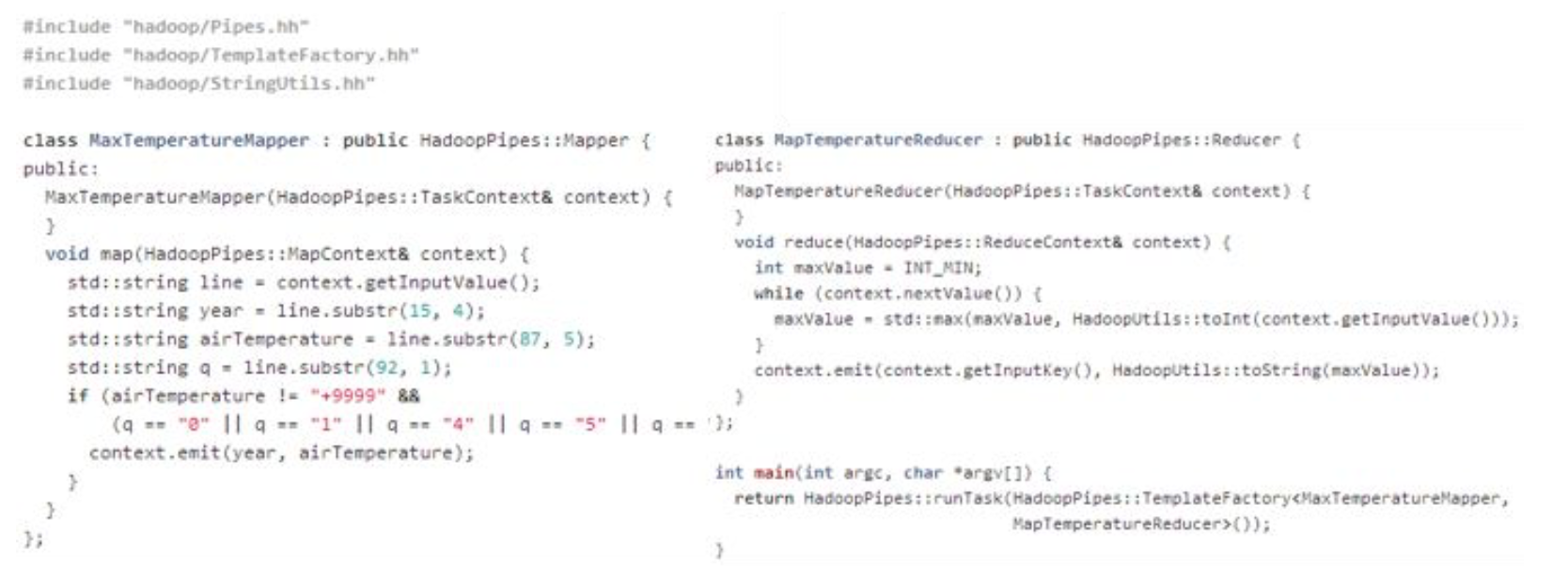
-
- Compiling and Running
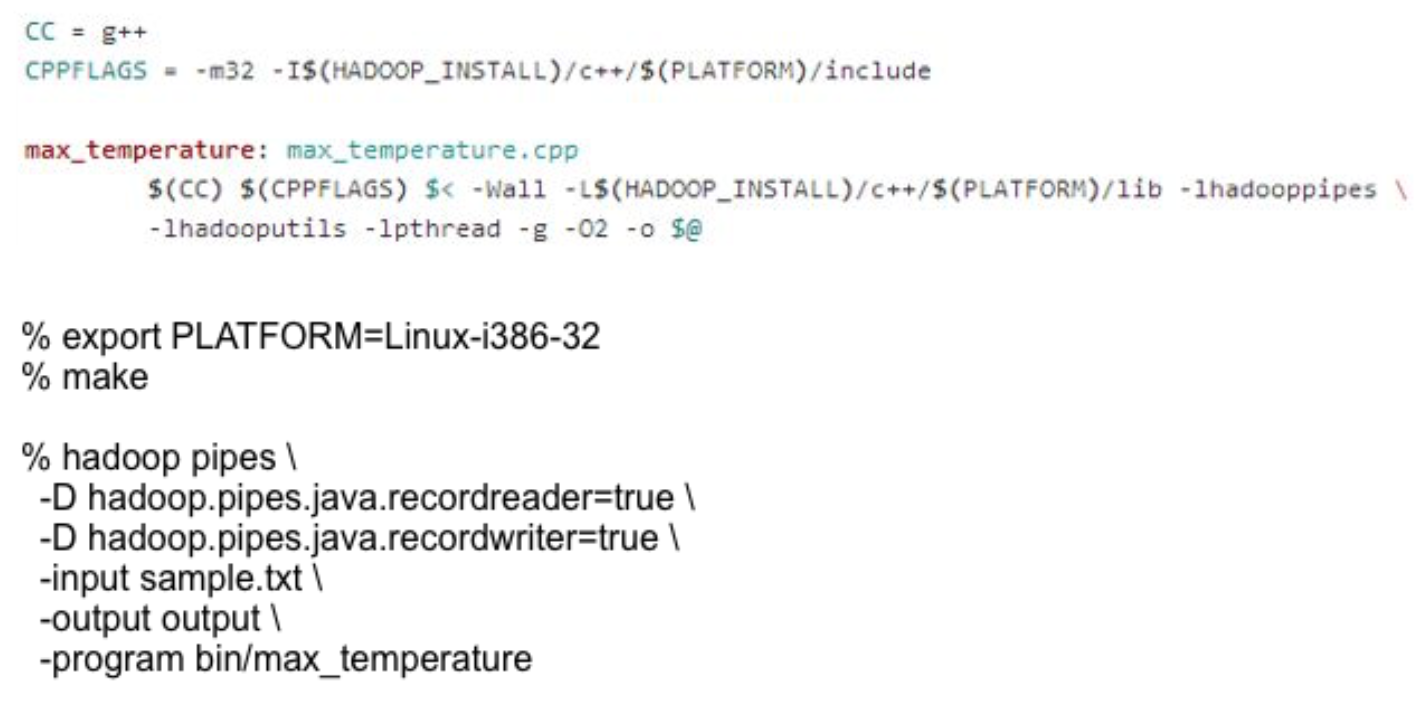
REVIEW
- MapReduce job은 클라이언트가 수행하고자 하는 작업 단위
- job은 input data, MapReduce program, config info로 구성됨
- Hadoop은 map tasks와 reduce tasks로 나누어 작업 실행
- YARN을 이용해 task가 스케줄링되고 Cluster의 node에서 실행됨
- fail 시 다른 node에서 실행되도록 자동으로 다시 예약됨
- job execution process를 제어하는 node는 두 가지 타입이 있음
→ jobtracker와 여러 tasktracker - Hadoop은 MapReduce job의 input을 input split 또는 split이라고 부르는 고정된 사이즈의 조각들로 나눔 → 각 split에 대해 map task를 하나씩 생성
2022-2 KHU 빅데이터프로그래밍 수업을 기반으로 작성하였습니다.
