MongoDB란?
- MongoDB는 Document 기반의 NoSQL 데이터베이스이다.
- Database > Collection > Document > Field 계층으로 이루어져 있다.
- 레코드는 key-value 쌍으로 이루어지고, value에는 다른 document나 array 등이 포함될 수 있다.
- MongoDB의 document는 JSON과 유사하다.
- 관계형 DB가 아니므로 RDBMS와 다르게 Schema-less 구조이며 JOIN이 존재하지 않는다.
- 라이선스는 메모리 사이즈를 기준으로 판매되며, MongoDB Korea에서 기술지원을 받을 수 있다.
- 인덱스가 설정된 경우에는 빠른 성능을 보이지만, 인덱스가 설정되어 있지 않다면 그 어떤 DB보다 느리다.
RDB와 MongoDB 비교
| RDB | MongoDB |
|---|---|
| database | database |
| table | collection |
| tuple/row | document |
| column | key / field |
| table join | Embedded Documents |
| Primary Key | Primary Key (_id) |
| database server | Client |
| mysqld | mongod |
| mysql | mongo |
Replica Set
MongoDB는 고가용성을 위해 Replica Set이라는 Replication 기능을 제공함
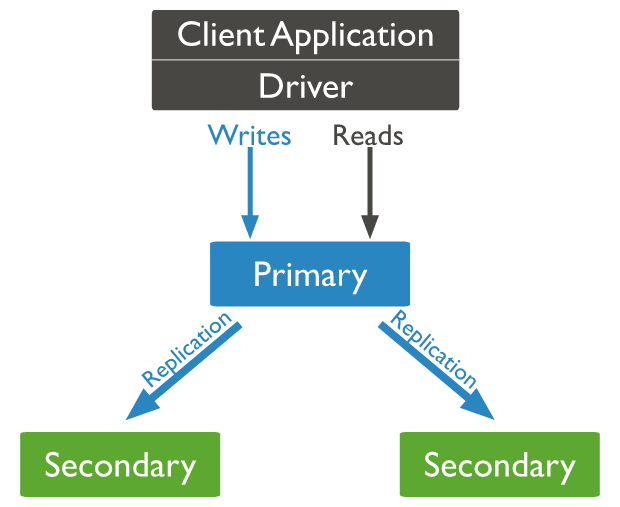
이미지 출처: MongoDB Manual - Replication
- 데이터가 모두 동일하게 저장되어 한 대가 죽어도 데이터가 유지됨
- Replica Set 구성 시 최소 3대로 구성됨
- 서로 heartbeat을 주고 받으며, 장애 발생 시 투표를 위해 과반수가 살아있어야 하므로 홀수 개로 구성해야 함
- Failover 시에 자동으로 투표를 통해 Secondary 중 하나가 Primary가 됨
- 동일한 크기의 데이터를 저장할 때, RDB와 비교하여 장비 수가 매우 많이 필요하고 메모리도 더 많이 필요함
- 하나의 Replica Set에 데이터를 2TB까지만 저장하는 것을 권장하며, 그 이상일 때는 Sharding으로 장비를 나누도록 권장됨
PSS 구성: Primary, Secondary, Secondary

이미지 출처: MongoDB Manual - Replication
- Secondary는 Primary의 oplog와 dataset을 복제함
- oplog: Replica Set의 데이터 동기화를 위해 내부에서 발생하는 모든 동작의 로그를 기록한 것
- Primary가 사용불가능한 경우 새로운 Primary가 될 Secondary를 뽑기위해 투표를 진행하게 됨
- Secondary 동기/비동기 복제 설정 가능
PSA 구성: Primary, Secondary, Arbiter

이미지 출처: MongoDB Manual - Replication
- Primary와 Secondary 하나가 있지만 비용 제약 등으로 인해 Secondary를 더 추가할 수 없을 때 Arbiter로 mongod 인스턴스를 Replica Set에 추가할 수 있음
- Arbiter는 데이터를 가지지 않지만 Primary 장애 시 투표에만 참여
- Arbiter는 항상 Arbiter이지만 Secondary는 투표를 통해 Primary가 될 수 있음
- 참고)
- 만약 무중단 서비스가 매우 중요한 상황인 경우에서 Primary와 Secondary 하나에 장애가 발생하여 Secondary 하나만 남은 경우 임시 처치로 Secondary의 남는 메모리에 Arbiter 2개를 띄워서 Online으로 만들 수 있음
참고) PSS 구성에서 MongoDB 버전 업그레이드하기
- Secondary node 중 하나를 한 단계 버전 업하여 재부팅하면 온라인 상태인채로 자동으로 데이터가 복제됨
- 그 후 다른 Secondary node를 한 단계 더 높은 버전으로 작업한 후 가장 최신의 버전을 Primary로 교체
- 원하는 버전까지 앞의 단계를 계속 반복
- 많은 시간이 걸리지만, 서비스 중단 없이 작업이 진행 가능하다는 큰 장점이 있음
Sharding

이미지 출처: MongoDB Manual - Sharding
- 데이터를 여러 시스템에 분산시키는 방법으로 Sharding을 통해 수평적 확장이 가능함
- 구성요소
- Shard: Sharding된 데이터의 하위 집합을 포함하며 각 Shard는 Replica Set으로 구성됨
- Config Server: 어떤 데이터가 어디에 저장되어있는지의 정보를 가지며 Replica Set으로 구성됨
- mongos: 쿼리 라우터 역할을 하며 클라이언트에서 쿼리를 받아와 Config Server를 통해 데이터가 어디에 있는지 찾고 Shard에서 찾아온 데이터를 조합하여 클라이언트에 돌려줌
- Sharding 구성 시 총 서버는 최소 10대가 필요함
- Shard Key를 사용하여 Shard 간에 컬렉션의 도큐먼트를 알아서 분배하여 저장 ➡️ Auto Sharding
- 4.2 이하 버전까지는 Shard Key 지정 필수, 변경 불가
- 4.4 버전부터 Shard Key 미지정 가능, 기존 Shard Key에 suffix를 추가하여 세분화 가능
- 5.0 버전부터 Shard Key를 변경하여 컬렉션을 Resharding 가능
- 클라이언트에서 쿼리를 던지면 라우터 서버(mongos)가 Config Server를 통해 데이터가 어느 서버에 있는지 찾아온 후, Shard 서버에서 데이터를 찾아와 조합하여 클라이언트로 돌려줌
- 이때 라우터가 SPOF가 될 수 있으므로 Replica Set으로 구성하도록 함
- 클라이언트는 꼭 모든 라우트 서버의 IP를 가지고 있도록 설정하고 랜덤으로 쿼리를 던지도록 설정
- Config Server 전체 Set이 장애가 발생하면 데이터는 존재하지만 어디에 어떤 데이터가 존재하는 지 몰라 쓸 수 없게 됨
- Config Server는 PSA 구성이 아닌 PSS 구성을 사용하도록 권장됨
- Datanode는 데이터 공간으로 2테라 이상이 필요하므로 VM 보다는 물리머신 사용을 권장함
- Config 서버는 메타 데이터가 1기가가 잘 넘어가지 않고, 메모리도 많이 필요하지 않으므로 VM 사용 권장
- 하나 이상의 Shard Replica Set이 완전히 장애가 나도 그 외의 Shard에 대해 부분 읽기 및 쓰기를 계속 진행할 수 있음
- Sharding을 계속 늘릴수는 있지만 Sharding된 컬렉션을 Unshard 하는 것은 불가능함
Backup
OPS Manager
- 엔터프라이즈 버전에서는 OPS Manager라는 모니터링 관리 툴 사용 가능
- 그래프로 모니터링, 이메일 알람 수신 등 가능
- 전체 백업, 증분 백업 가능. 복원 쉬움
- OPS client를 DB 서버에 설치 가능
mongodump
- 커뮤니티 버전에서는 mongodump 사용 가능
- mysqldump와 동일
- insert문이 나열된 파일로 떨어짐
- 데이터는 1테라가 안되는 상황이어도 모든 데이터를 불러와 insert문을 만드므로 백업에 10시간이 걸림. 동일하게 복원도 10시간 소요
LVM
- 리눅스 서버 기능인 LVM 백업 사용 가능
- Local Volum Manager
- LVM은 파티션 대신 volume 단위로 저장 장치를 다룸
- 디스크 미할당 영역을 volume으로 만들고 volume을 복사 ➡️ 빠름
- LVM 스냅샷을 다른 곳에 복사
* PBM 백업 방법은 내부적으로 mongodump 사용하므로 느림
MongoDB 사용 시 주의사항
- Oracle이나 MSS에서는 메모리 사용량 제한을 걸 수 있는 환경 설정 변수가 존재하지만, MongoDB에서는 이러한 설정이 불가능함
- cache size에만 제한 설정이 가능하지만, 제한을 걸어도 다른 요소에서 그만큼 메모리를 더 사용하게 됨
- 메모리를 제한하려면 물리 서버에서 메모리를 뽑아내는 방법 뿐임
- 인덱스를 걸지 않으면 그 어떤 DB보다 느려지게 되는데, 또 인덱스 사이즈를 너무 크게 잡는다면 모두 메모리에 올라가게 되므로 그만큼 헤비하게 돌아가게 됨
- 장비에 메모리를 추가하거나, 튜닝을 통해 메모리 사용을 줄여야 함
- 메모리 추가 시, MongoDB 서버가 120대라면 그 120대 모두에 메모리를 추가해주어야 함
- Sharding 구성 시 IDC 이중화를 진행한다면 모두 다른 IDC에 배치하여야 함
- 대부분 3개의 IDC에 Datanode를 2/2/1로 나누어 구성하게 됨
- 결국 총 필요한 서버의 수는 18대가 됨
- MongoDB Sharding 구성 시 하드웨어 비용이 많이 들어가는 것을 주의하여야 함
- 참고
- MongoDB 6.0 메뉴얼: https://www.mongodb.com/docs/manual/introduction/
