RAG 시스템
RAG는 각 질의에 대해 적절한 컨택스트를 구성하는 방법에 관한 것으로, 모델이 외부 데이터 소스에서 관련 정보를 검색하여 모델의 생성을 향상시키는 기술이다.
청킹 (Chunking)
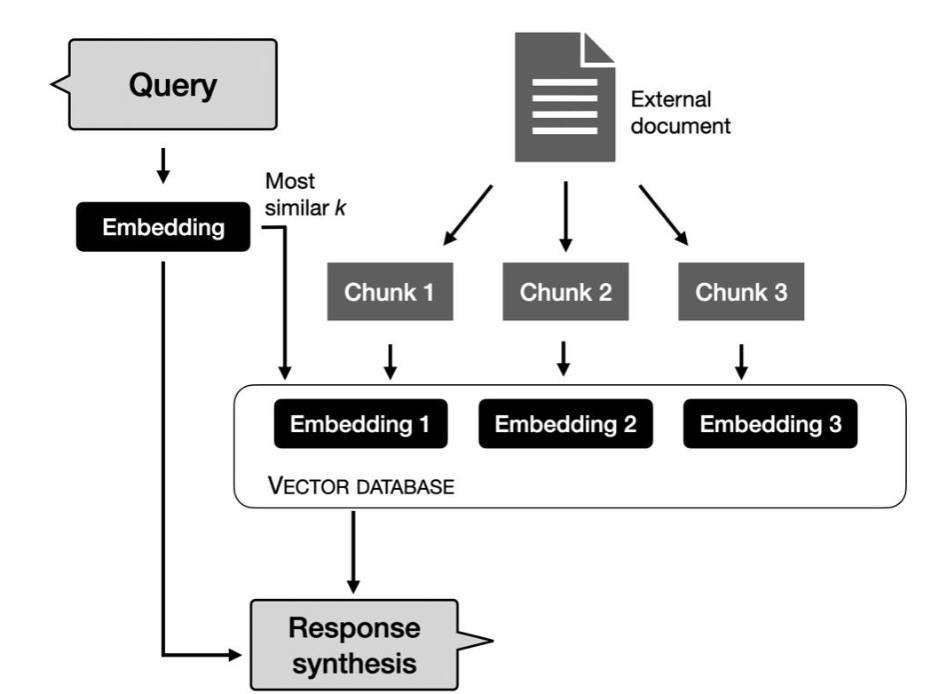
RAG 시스템은 외부 메모리 소스에서 정보를 검색하는 검색기와 검색된 정보를 기반으로 응답을 생성하는 생성 모델로 구성된다.
외부 메모리 소스의 문서는 10개의 토큰이나 100만 개의 토큰일 수 있으므로 문서 전체를 그냥 검색하면 컨택스트가 지나치게 길어질 수 있다. 이를 방지하기 위해 각 문서를 더 관리하기 쉬운 청크(Chunk)로 분리하며, 이를 청킹 (Chunking)이라고 한다.
청킹 전략
청킹의 가장 단순한 전략은 특정 단위를 기준으로 문서를 동일한 길이의 청크로 나누는 것이다. 주로 문자나 단어, 문장, 단락 같은 단위를 사용한다.
- (ex) 각 문서를 2,048자 또는 512단어 청크로 나눔. / 각 청크가 고정된 수의 문장(예를 들어 20문장)을 포함하게 함. / 각 단락을 하나의 청크로 삼음 등의 방식으로 문서를 분할할 수 있다.
또한, 각 청크가 최대 청크 크기 안에 들어올 때까지 점점 작은 단위를 사용해 문서를 재귀적으로 분할할 수도 있다.
- (ex) 문서를 먼저 여러 절로 나누고, 절이 너무 길면 단락으로, 단락이 길면 문장으로 나누는 방식
그리고 생성 모델의 토크나이저가 나누는 토큰을 기준으로 문서를 청킹하는 방법도 있다. 이는 token limit을 효율적으로 관리하므로 모델과의 작업이 더 수월해진다는 장점이 있으나, 다른 토크나이저를 사용하는 생성 모델로 바꾸면 데이터를 처음부터 다시 색인화해야 한다는 단점이 있다.
하지만, 이러한 청킹 전략에 정답은 없다. 너무 작은 청크는 문맥이 부족할 수 있고, 너무 큰 청크는 검색 정확도가 떨어질 수 있기 때문이다. 따라서 실험을 통해 적절한 청크 크기와 방식을 찾는 것이 중요하다.
청크 간 겹침 (Chunk Overlap)이란, 문서를 청크로 나누는 과정에서 문맥이 손실되는 문제를 해결하기 위한 방식으로, 인접한 청크 사이에 일부 내용을 겹치게 만들어 문맥을 보존하는 방법을 의미한다. 다시 말해, 청크를 나눌 때 중복 구간을 유지하게 하는 것을 의미한다.
예를 들어, “트랜스포머 모델은 어텐션 메커니즘을 기반으로 하며, RNN의 순차적 한계를 극복하기 위해 제안되었다. 특히, 셀프 어텐션 구조는 문맥 정보를 효과적으로 통합한다.”라는 문장을 청크화하여 트랜스포머 모델은 어텐션 메커니즘을 기반으로 하며(청크1) / RNN의 순차적 한계를 극복하기 위해 제안되었다.(청크2) / 특히, 셀프 어텐션 구조는 문맥 정보를 효과적으로 통합한다. (청크3)로 나누었을 때, 청크1이 없는 채로 청크 2를 보면 청크2에서 제안된 것이 무엇인지 알 수 없다. 따라서 이를 해결하기 위해 청크를 나눌 때 중복 구간을 유지하여 청크 1의 마지막 부분이 청크 2의 시작 부분에 같이 들어가도록 하여 두 청크가 연결된 문맥을 일부 공유할 수 있도록 한다.
임베딩 모델
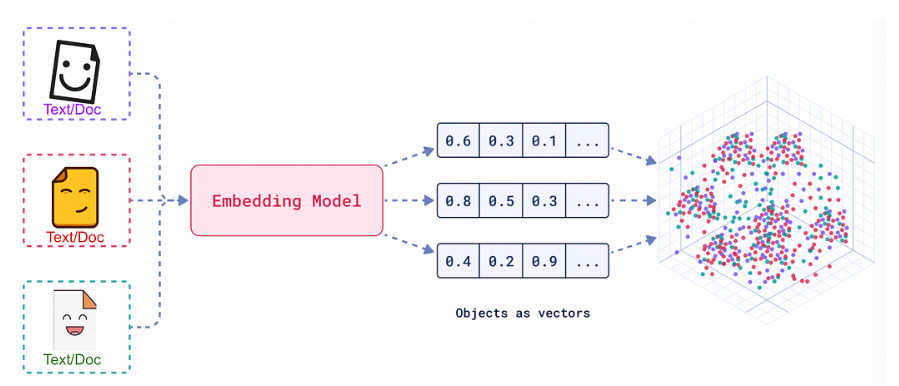
임베딩이란, 원본 데이터의 의미적 특성을 보존한 채 텍스트(단어, 문장, 문서 등)를 숫자 벡터로 표현하는 과정이다.
임베딩 모델은 이러한 임베딩 과정을 수행하기 위한 별도의 모델로, 텍스트 데이터를 고차원 벡터 공간에 매핑하기 위한 알고리즘을 의미한다. 주로 단어 또는 문장 같은 언어 단위를 수치적으로 표현하는 데 사용되며, RAG 시스템에선 임베딩 모델이 제대로 작동하지 않으면 임베딩 기반 검색도 제대로 작동하지 않으므로 중요하게 여겨진다.
임베딩 모델은 크게 단어 임베딩과 텍스트 임베딩으로 나눌 수 있으며, 단어 임베딩은 특정 단어를 고정된 차원의 벡터로 변환하여 단어 간 의미적 유사성을 반영하는 방법(Word2Vec, GloVe 등)을 의미한다.
텍스트 임베딩은 문장이나 문단과 같은 더 큰 텍스트를 벡터로 변환하며, BERT나 Sentence-BERT와 같은 모델을 통해 전체 문맥을 고려하여 문장 간 의미적 관계를 포착하는 데 중점을 둔다.
검색 시스템
검색은 주어진 질의에 대한 문서들의 관련성을 기준으로 순위를 매기는 방식으로 작동하며, 검색 알고리즘은 관련성 점수를 계산하는 방법에 따라 달라진다.
용어 기반 검색 (어휘적 검색, lexical retrieval)
- 질의와 관련된 문서를 찾기 위해 키워드를 사용하는 방법
- 자주 사용되는 용어 기반 솔루션에는 엘라스틱서치와 BM25가 있다.
엘라스틱 서치
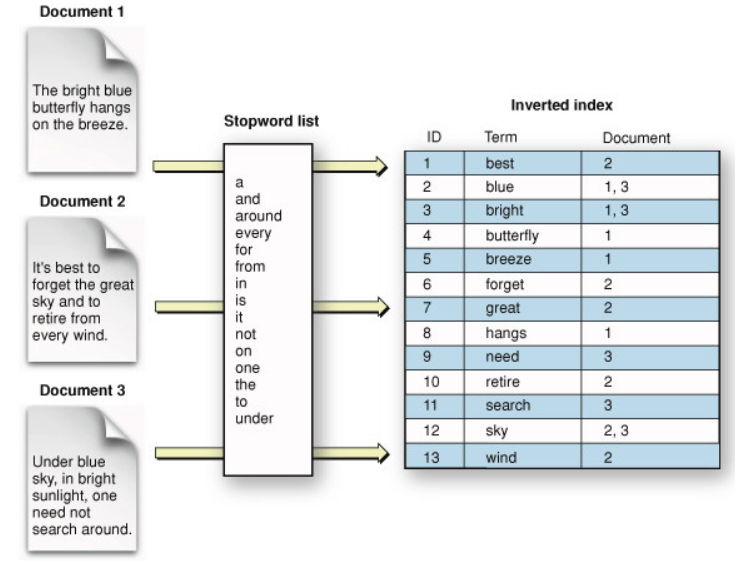
- 엘라스틱 서치는 역색인(Inverted index)이라는 데이터 구조를 활용하며, 이는 용어를 문서로 매핑하는 사전이다.
- 이러한 역색인은 텍스트를 단어(토큰) 단위로 나누어 각 단어가 어떤 문서에 나타나는지 기록하는 구조이다. (문서에 번호가 지정된 것이 아닌 단어마다 어느 문서에 들어가 있는지 기록하므로 역색인이라고 한다)
- 이러한 정보는 TF-IDF 점수 계산 시 유용하게 쓰인다.
참고 : TF-IDF (Term Frequency-Inverse Document Frequency)
TF-IDF란, 단어마다 중요도를 고려하여 가중치를 주는 통계적인 단어 표현 방법이다.
TF-IDF는 문맥이나 단어 간의 의미를 고려하지 않지만, 단어의 빈도와 희소성을 기반으로 문서의 중요성을 평가하는 데 유용하게 사용된다.
TF-IDF의 한계(문맥이나 단어 간 의미를 고려하지 않음)를 극복하기 위해 단어 간 관계를 학습하는 Word Embedding 기법이나 BERT를 사용할 수 있다.
- TF-IDF는 문서 내에서 많이 나온 단어의 중요도는 높게, 많은 문서에서 등장하는 조사 등의 단어의 중요도는 낮게 평가한다.
- 즉, 한 문장에서 자주 사용되는 단어는 중요하다 판단하지만, 다른 문장에서도 흔하게 사용하면 중요하지 않다고 단어를 판단하는 알고리즘이다.
- TF-IDF 가중치 계산 방법 : TF-IDF=TF∗IDF
- 단어 출현빈도(Term Frequency, TF) : 특정 문서에서 특정 단어의 출현 빈도
- TF(t,d) = 해당 단어 t의 등장 횟수 / 문서 d의 총 단어 수
- 역 문서 빈도(Inverse Document Frequency, IDF) : 특정 단어가 전체 문서 집합에서 얼마나 희귀한지를 나타내는 것
- IDF(t) = log(전체 문서 수 / 문서 수 d에서 t가 등장하는 횟수)
코드 예시
from collections import Counter import math # Step 1 : Sample documents # Each document is a string, representing some text content. # 샘플 문서 생성 documents = [ "text mining algorithms analyze text", "text data mining finds patterns in text", "patterns and algorithms are used in text mining", ] # TF(t,d) = 해당 단어 t의 등장 횟수 / 문서 d의 총 단어 수 # IDF(t) = log(N / DF) (N : 총 문서 수, DF : 단어가 등장한 문서 수) # Step 2 : Preprocess documents and calculate term frequencies (TF) # For each document, split it into words and count occurrences using Counter. # 각 문서를 단어로 분리하고, Counter를 통해 각 단어 출현 빈도 계산 (t) tf = [Counter(doc.split()) for doc in documents] # Step 3 : Calculate document frequency (DF) for each term # DF counts the number of documents containing each term. df = Counter() # Counter 객체 df 생성 for doc_tf in tf: df.update(doc_tf.keys()) # 전체 문서에서의 key 빈도(DF) 계산 # Step 4 : Calculate TF-IDF for each term in each document # Use the formula TF-IDF = TF * log(N/DF), where N is the total number of documents. N = len(documents) # N = 총 문서 수 tf_idf = [] # TF-IDF 점수를 저장할 리스트 # 각 문서에 대해 반복 for doc_index, doc_tf in enumerate(tf): doc_tfidf = {} # 현재 문서의 TF-IDF 점수를 저장할 딕셔너리 for term, count in doc_tf.items(): # 현재 문서의 각 단어에 대해 반복 idf = math.log(N / df[term]) # Inverse Document Frequency (IDF) / IDF 계산 doc_tfidf[term] = count * idf # 현재 단어의 TF-IDF 점수 저장 tf_idf.append(doc_tfidf) # 현재 문서의 TF-IDF 점수(딕셔너리 형태)를 리스트에 추가 # Step 5 : Display TF-IDF scores # Print TF-IDF scores for each documents. # enumerate( ) 함수 : 리스트의 값을 추출할 때 인덱스를 붙여 함께 출력하는 방법 # for index, value in enumerate(iterable 객체) for doc_index, scores in enumerate(tf_idf): print(f"Document {doc_index + 1} : ") # index는 0부터 시작하니까 index + 1 for term, score in scores.items(): # tf_idf는 딕셔너리 형태의 정보가 리스트로 저장되어 있으므로 items() 사용 print(f" {term}:{score:.2f}")
BM25
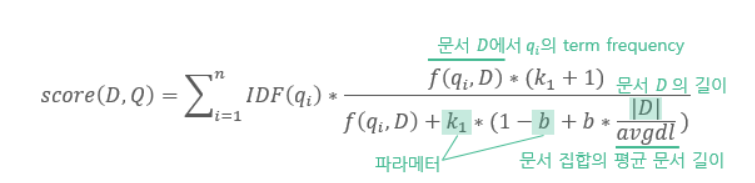
- BM25는 TF-IDF를 개선한 방식으로, TF-IDF와 달리 문서 길이를 고려해 용어 빈도 점수를 정규화한다. 긴 문서일 수록 특정 용어를 포함할 가능성이 높고, 용어 빈도 값도 자연히 높아지기 때문이다.
- BM25는 다음과 같은 기준을 통해 문서와 질의 간 관련성을 평가한다.
- ① 단어가 질의에 포함되어 있는가?
- ② 그 단어가 문서 안에서 얼마나 자주 등장하는가?
- ③ 문서가 너무 길지는 않은가?
- ④ 단어가 전체적으로 희귀한가?
: TF(단어 빈도)에 대한 민감도
: 문서 길이에 대한 보정 정도
임베딩 기반 검색 (의미 기반 검색, semantic retrieval)
용어 기반 검색은 의미가 아닌 단어의 형태만 가지고 관련성을 계산한다. 하지만, 텍스트의 겉모습이 그 의미를 제대로 반영하지 못하는 경우도 있다.
(ex) '트랜스포머 아키텍처' 검색 -> 결과 : 영화 <트랜스포머> 문서 반환
이와 달리, 임베딩 기반 검색기는 문서의 의미가 질의와 얼마나 가까운지를 기준으로 순위를 매기며, 색인화 과정에서 원본 데이터 청크를 임베딩으로 변환하는 과정까지 포함한다. 이렇게 생성된 임베딩을 저장하고 유사도 검색을 수행하는 데이터베이스를 Vector Database라고 한다.
이러한 임베딩 데이터는 VectorDB에 저장되어, 아래와 같은 절차를 통해 RAG(Retrieval-Augmented Generation) 구조로 활용될 수 있다.
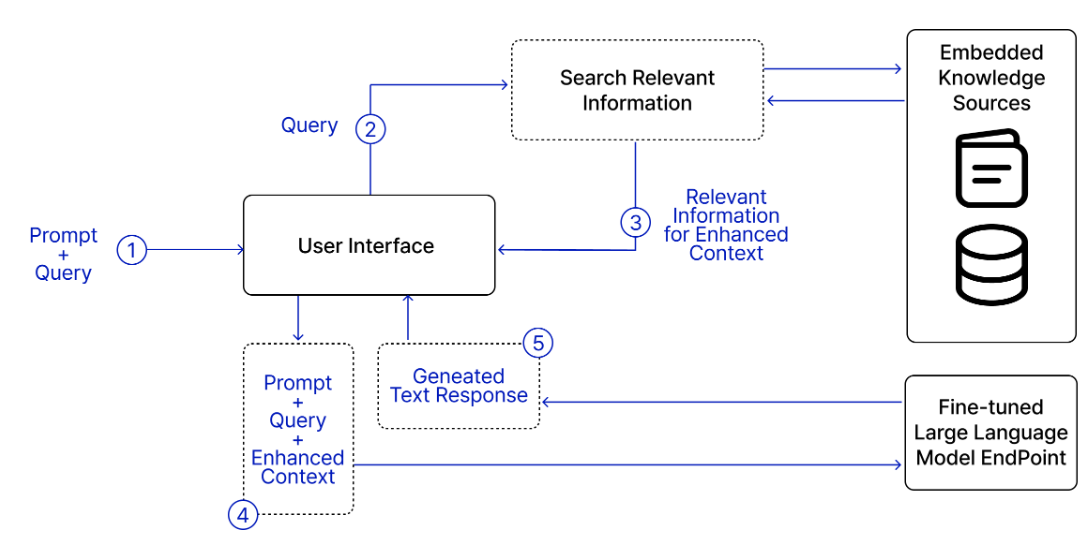
이때, 단순히 벡터를 저장하는 것은 쉬운 일이지만, 질의가 임베딩으로 변환되면 벡터 데이터베이스는 이 질의 벡터와 유사한 벡터들을 데이터베이스에서 찾아내는 벡터 검색을 수행해야 하는데, 이는 쉽지 않은 과정이다. 따라서 벡터들은 빠르고 효율적 검색이 가능한 방식으로 색인화되고 저장되어야 한다.
벡터 검색은 보통 최근접 이웃 문제로 접근하여 주어진 질의에 대해 k개의 가장 가까운 벡터를 찾는 방식으로 수행되며, 가장 기본적인 방법은 k-최근접 이웃 알고리즘이다.
K-NN 알고리즘은 다음과 같이 작동한다.
1. 질의 임베딩과 데이터베이스의 모든 벡터 간 유사도 점수를 코사인 유사도와 같은 지표를 사용해 계산한다.
2. 모든 벡터를 유사도 점수에 따라 순위를 매긴다
3. 높은 유사도 점수를 가진 상위 k개 벡터를 반환한다.
하지만, 이는 계산이 많이 필요하고 느리다. 따라서 작은 데이터셋에서는 K-NN을, 큰 데이터셋에서는 근사 최근접 알고리즘(ANN)으로 벡터 검색을 수행하며, 대표적인 벡터 검색 알고리즘에는 FAISS, ScaNN, Annoy, Hnswlib 등이 있다.
벡터 데이터베이스 선택 기준 가이드
https://discuss.pytorch.kr/t/2023-picking-a-vector-database-a-comparison-and-guide-for-2023/2625
검색기의 품질
검색기의 품질은 검색되는 데이터의 품질로 평가할 수 있으며, RAG 평가 프레임워크에서 주로 사용되는 두 가지 지표는 컨택스트 정밀도(Context Precision)와 컨텍스트 재현율(Context Recall)이다.
- 컨택스트 정밀도 (Context Precision) : 검색된 모든 문서 중에서 실제로 질의와 관련된 문서의 비율은 얼마인가?
- 컨텍스트 재현율 (Context Recall) : 질의와 관련된 모든 문서 중에서 실제로 검색된 문서의 비율은 얼마인가?
이러한 지표를 계산하기 위해 테스트용 질의 목록과 각 질의에 해당하는 문서 집합으로 평가 세트를 구성하며, 각 테스트 질의에 대해 테스트 문서가 관련이 있는지 없는지 주석을 단다. (이 주석은 사람이나 AI 평가자가 달 수 있다) 그런 다음, 이 평가 세트에서 검색기의 정밀도와 재현율 점수를 계산한다.
RAG 파이프라인은 개별적으로, 그리고 조합하여 평가해야 하는 여러 구성 요소로 구성되므로 일련의 평가 지표가 필요한데, 고품질 검증 데이터셋을 인간이 직접 생성하는 것은 어렵고 시간이 많이 걸리며 비용도 많이 든다.
그래서 이러한 RAG 시스템의 평가를 위해 RAGAs를 활용할 수도 있다. 이는 RAG 시스템 평가를 위한 오픈 소스 프레임워크이다.
https://jihan819.tistory.com/entry/AI-RAGAS-%EA%B3%B5%EC%8B%9D-%EB%AC%B8%EC%84%9Cdocs-%ED%8C%8C%EC%95%85%ED%95%98%EA%B8%B0
https://medium.com/data-science/evaluating-rag-applications-with-ragas-81d67b0ee31a
아래의 글은 RAG 평가 방법에 관한 글이다.
https://velog.io/@cathx618/RAG-%ED%8F%89%EA%B0%80-%EB%B0%A9%EB%B2%95-%EC%A0%95%EB%A6%AC
만약 더 관련성 높은 문서가 상위에 나와야 해서 검색된 문서의 순위가 중요할 때는, 정규화된 할인 누적 이득 (NDCG), 평균 정밀도 (MAP), 평균 역순위(MRR)과 같은 지표들을 활용할 수도 있다.
검색 알고리즘 결합하기
검색 알고리즘마다 뚜렷한 장점을 지니기에 운영 환경의 검색 시스템은 보통 여러 접근 방법을 함께 결합해 사용하며, 용어 기반 검색과 임베딩 기반 검색을 결합하는 것을 하이브리드 검색(Hybrid Search)이라고 한다.
서로 다른 알고리즘은 순차적으로 사용될 수 있으므로 용어 기반 시스템처럼 비용이 적게 들지만 정확도가 낮은 검색기로 후보군을 추려내고, 그 다음 k-최근접 이웃과 같이 더 정확하지만 비용이 더 많이 드는 방식으로 이 후보 중에서 최상의 결과를 찾는다. 이 두 번째 단계를 재순위화(Re-ranking)이라고 한다.
앞에서도 말했듯 용어 기반 검색의 단점은 '트랜스포머 아키텍처' 검색 -> 결과 : 영화 <트랜스포머> 문서 반환과 같이 의미를 반영하지 않고 문서를 가져올 수도 있다는 것이다. 따라서 용어 기반 시스템으로 관련성 있는 후보군들을 추려내고, 여기서 의미적 중요도를 기반으로 한 번 더 걸러서 최상의 결과를 찾겠다는 것이다.
또한, 서로 다른 알고리즘을 앙상블 기법으로 결합할 수도 있으며, 이는 여러 검색기를 동시에 사용해 후보를 가져온 다음, 이 다양한 순위들을 하나로 결합해 최종 순위를 생성하는 방법이다. 이렇게 서로 다른 순위를 결합하는 알고리즘을 역퓨전(RRF)이라고 한다. (각 검색기의 점수 체계가 달라도 순위만 있으면 결합 가능하며, 두 검색기가 모두 높은 순위를 매긴 문서가 최종적으로 상위에 오르게 된다.)
- = 순위 목록의 수, 각 검색기에 의해 생성
- : 검색기 i에 의한 문서의 순위
- : 0으로 나누는 것을 방지하고 낮은 순위 문서의 영향력을 제어하기 위한 상수로, 일반적으로 60을 사용함.
