이번에 Agentic AI에 관해 공부해야 할 일이 생겨 관련 자료들을 살펴보며 전체적인 흐름을 정리해 보았다.
Agentic AI에 관해 살펴보기 전, 먼저 전통적인 AI Agent, 현재의 AI Agent, Agentic AI의 차이에 관해 살펴보자.
AI Agent과 Agentic AI의 차이
Traditional AI Agent
전통적인 AI Agent는 사전에 정의된 규칙에 기반해 특정 작업만 수행하도록 설계된 시스템을 의미한다.
Traditional AI Agent의 한 예시로는 전문가 시스템이 있으며, 이는 전문가의 지식을 규칙이라는 형태로 지식 베이스에 저장하고, 이 규칙들을 통해 추론을 수행했다.
하지만, 이러한 구조는 데이터에 기반한 학습보단 Symbolic Reasoning, Rule-based Logic, 스크립트 기반 행동에 의존하므로 제한적인 자율성을 지니며, 동적인 환경에 대한 적응력이 존재하지 않아 역동적인 산업 환경에 적응하기 어렵다는 단점이 존재했다.
이러한 이유에서 Traditional AI Agent는 예측 가능하고 구조화된 환경에서 가장 효과적이었다.
참고 사항
Traditional AI Agent의 제약사항을 정리해 보면 다음과 같다.
- 명시적인 지시 필요
- 단기적이고 제한적인 과업 수행
- 직접적인 명령에만 반응
- 업데이트 시 수동으로 재프로그래밍 필요
AI Agent
Generative AI와 LLM의 발전으로 전통적인 규칙 기반 AI Agent는 더욱 발전하였고, 현대에 이르러서는 LLM을 기반으로 외부 API나 데이터베이스를 호출해 단일 목적의 작업을 수행하는 단일 개체 시스템을 AI Agent라고 한다.
다시 말해, LLM + 외부 도구(tool)을 사용하여 특정 작업을 수행하기 위해 만들어진 시스템을 AI Agent라고 한다고 이해하면 된다. AI Agent는 목적을 이루기 위해 정해진 작업만을 수행하며, 다른 장치들과는 협업하지 않는다.
Agentic AI
Agentic AI는 AI Agent의 개념에서 한 단계 더 진보된 개념이다. 이는 사람의 개입 없이도 스스로 목표를 설정하고, 판단하고, 실행하며 결과를 학습하는 자율형 AI를 의미한다.
고차원 목표를 달성하기 위해 여러 전문 에이전트가 협력하는 멀티 에이전트 시스템(MAS)으로, 오케스트레이션을 구축하고, Multi-Agent 구조를 통해 복잡한 문제를 에이전트 간 협업을 통해 해결하는 것에 중점을 둔다.
이해를 위해 조금 더 쉽게 정리해 보면, 단일 작업을 수행하는 시스템은 AI Agent이고, 여러 개의 AI Agent들이 모여 서로 협업하고 계획을 세워 더 복합적이고 범용적인 작업을 수행할 수 있도록 하는 시스템을 Agentic AI라고 이해하면 된다.
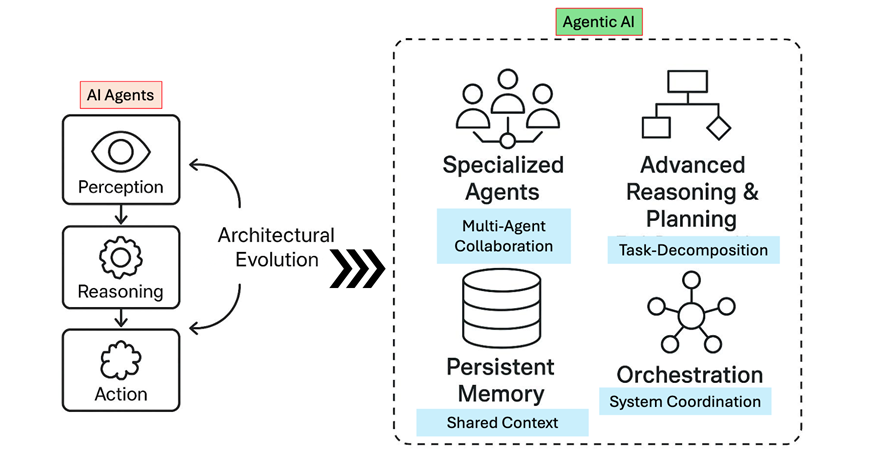
사실 이렇게 개념으로만 보면 받아들이기 어려운데, 예시로 보면 다음과 같다.
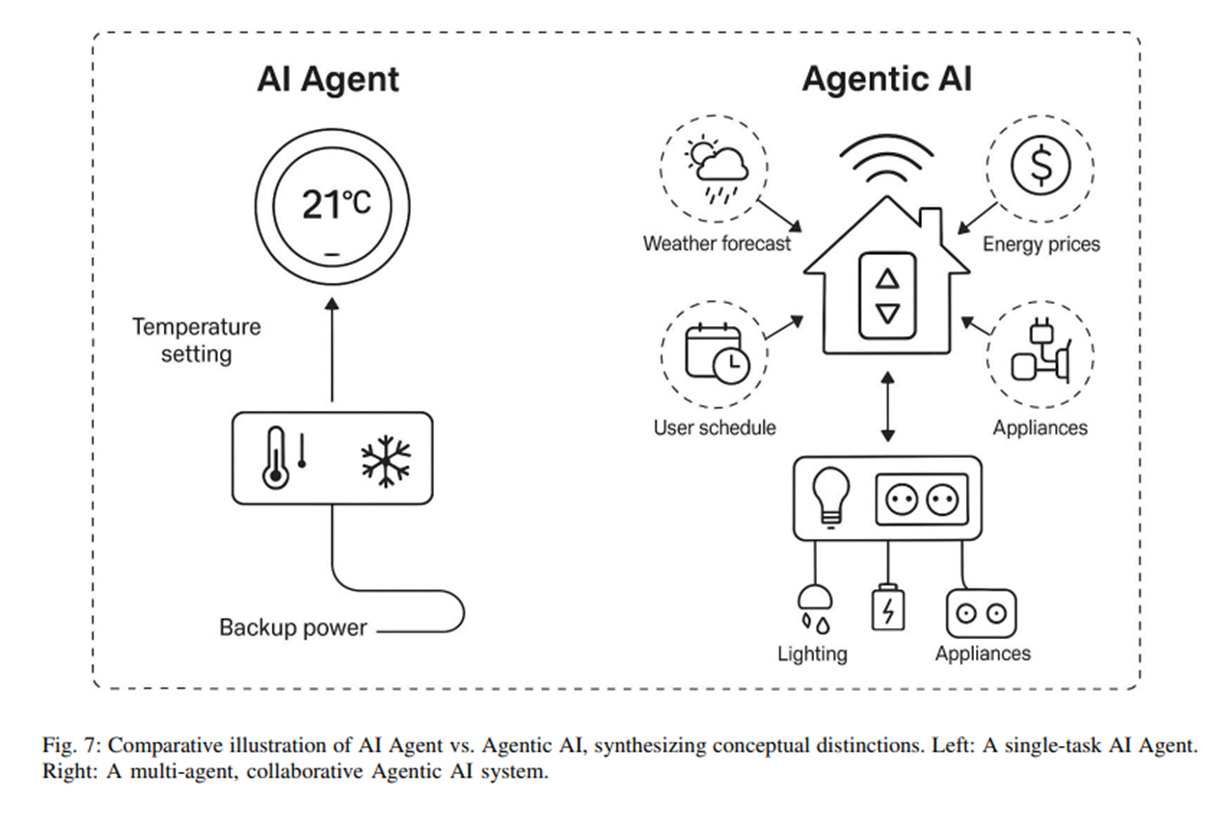
AI Agent는 스마트 온도 조절기처럼 사용자 지시에 따라 혼자서 난방/냉방을 조절하는 구조로, 난방/냉방 조절이라는 정해진 작업 하나만을 수행하고, 다른 장치들과는 협력하지 않는다.
이에 반해 Agentic AI는 여러 에이전트가 협력하는 스마트홈 생태계처럼 날씨 에이전트가 더위를 감지하면 에너지 에이전트가 미리 냉방 시작, 보안 에이전트는 외출 시 감시 카메라 작동 등 서로 정보를 주보 받고 협업하며 전체적인 환경을 최적화한다.
이처럼 하나의 단일 작업만을 수행하는 것보단 좀 더 복합적이고 범용적인 작업을 스스로 계획하고 판단하고 실행하여 결과를 만들어 내는 이러한 시스템을 Agentic AI라고 한다.
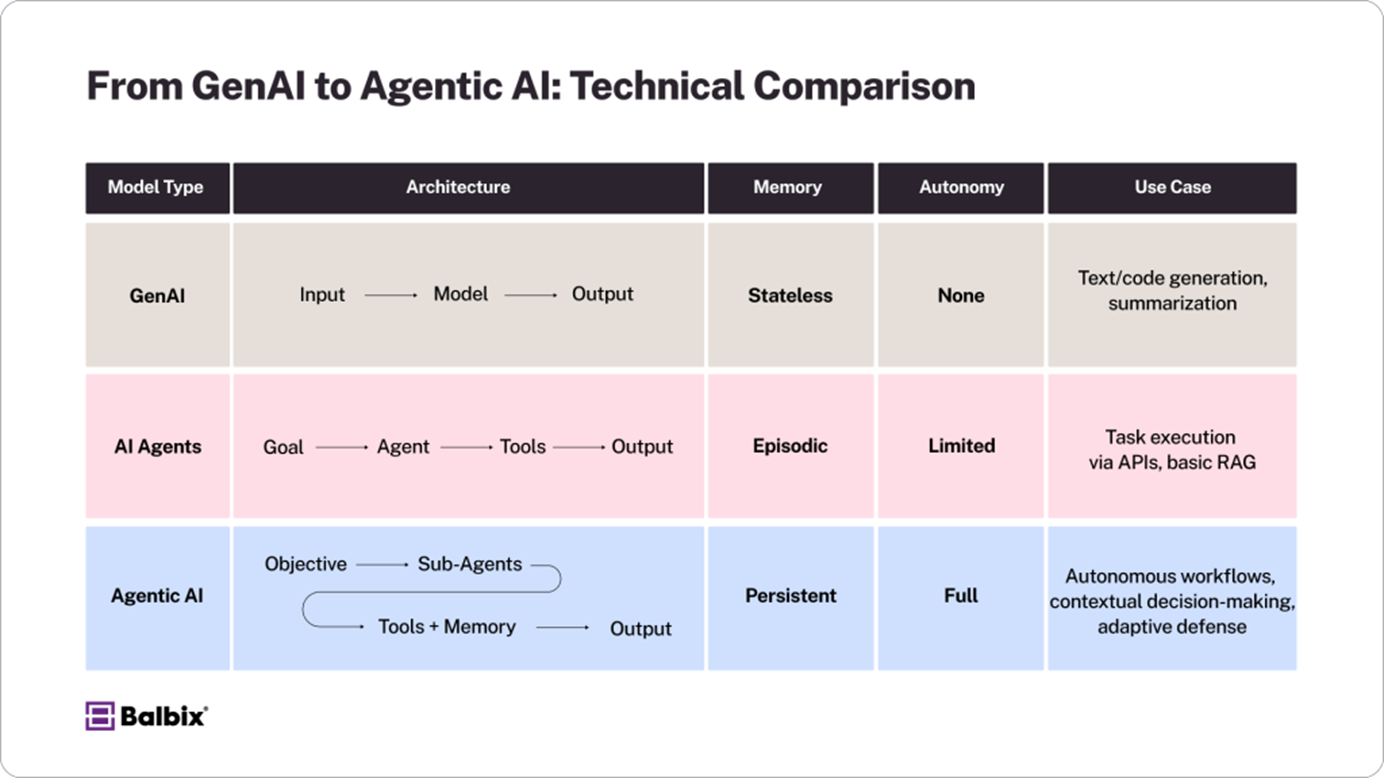
아래의 사진은 Generative AI -> AI Agent -> Agentic AI로 발전해 나가는 흐름을 잘 정리해 둔 자료라서 가져왔다.
Gnerative AI는 일반적으로 사용하는 ChatGPT, Claude 등의 LLM 기반 생성형 AI를 의미한다. 이는 컨텍스트를 기억하거나 도구를 직접 사용하지 않는다.
AI Agent는 LLM에 도구 사용 능력을 부여해, 사용자의 목표에 맞춰 자동으로 툴을 선택하고 작업을 수행할 수 있도록 하는 시스템이지만 자율성은 제한적이며, 장기적인 맥락 이해나 협업은 불가능하다.
Agentic AI는 여러 하위 에이전트들이 주어진 목적을 달성하기 위해 스스로 역할을 나누고 협업할 수 있도록 하며, 이 과정에서 지속적인 메모리 유지 및 동적 계획 수립, 유연한 도구 사용 등이 가능하다.
이러한 Agentic AI가 각광받는 이유는 다양하겠지만, 가장 큰 이유는 이전에는 도구로만 여겨지던 AI가 문제 해결의 주체로 전환된 것에 있다.
기존의 AI는 각종 도구들과 AI를 활용해 인간의 문제 해결을 돕기 위한 수단으로써 사용되었지만, Agentic AI는 사람의 개입 없이도 스스로 목표를 설정하고, 판단하고, 실행하며 결과를 학습할 수 있도록 하여 AI가 주체적으로 문제를 해결할 수 있도록 한다.
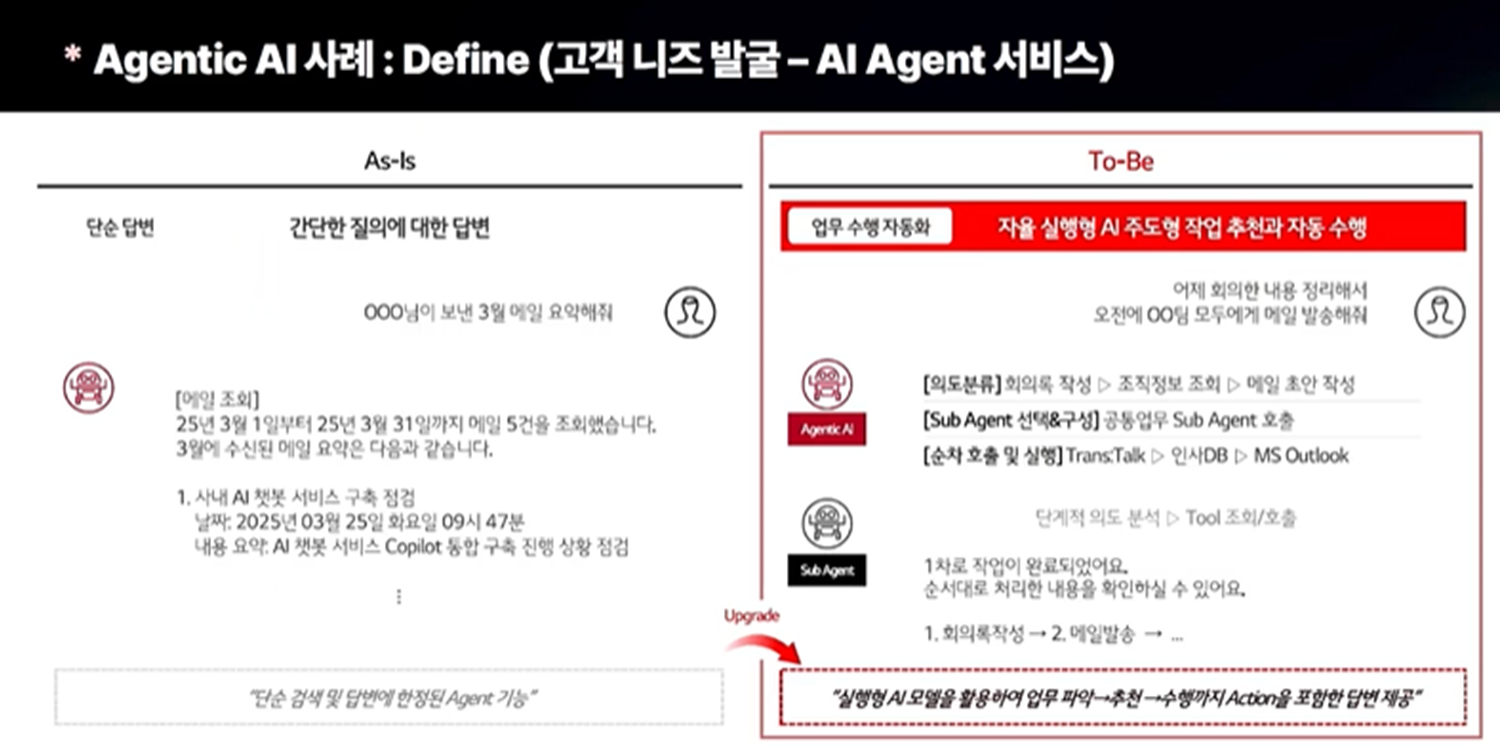
또한, 아래의 사례와 같이 기존 서비스를 좀 더 고도화 하는 데 사용할 수도 있다. 기존의 AI Agent가 단순 작업만을 수행했다면, Agentic AI를 활용한 시스템에선 사용자의 의도를 분석하여 사용자가 원하는 목표를 이루기 위한 계획을 세우고, 그 계획에 따라 서브 에이전트에게 역할을 분담하고, 이를 순차적으로 처리해 기존보다 더 고도화된 서비스를 제공한다.
Orchestration Layer
위에서도 말했듯, Agentic AI는 사람의 개입 없이도 스스로 목표를 설정하고, 판단하고, 실행하며 결과를 학습할 수 있도록 하는 시스템이다. 그렇다면 이러한 Agentic AI는 어떠한 방식으로 사람의 개입 없이 스스로 판단할 수 있는 것일까?
이것의 핵심에는 Orchestration Layer가 있다. 이는 여러 개 에이전트들이 유기적으로 협력해 목표를 달성할 수 있도록 역할을 분배하고, 순서, 병렬성, 도구 호출, 피드백까지의 과정을 조율하는 중간 제어 계층이다.
Agentic AI는 단일 Agent가 아니므로 목표를 분해하고, 작업을 나누고, 각 Agent가 서로 통신하고, 실행하고, 평가하는 일련의 과정들을 적절한 순서로 조율할 수 있도록 하는 게 중요한데, 이 역할을 담당하는 것이 Orchestration Layer이다.
Agentic Pattern
이러한 오케스트레이션 구조를 기반으로 실제 Agentic AI에선 다양한 방식의 협업 구조들이 나타나는데, 큰 틀에서 다음과 같이 4가지 패턴으로 나눠서 볼 수 있다.
그럼 이제 위의 네 가지 패턴에 대해 좀 더 자세히 알아보자.
Planning
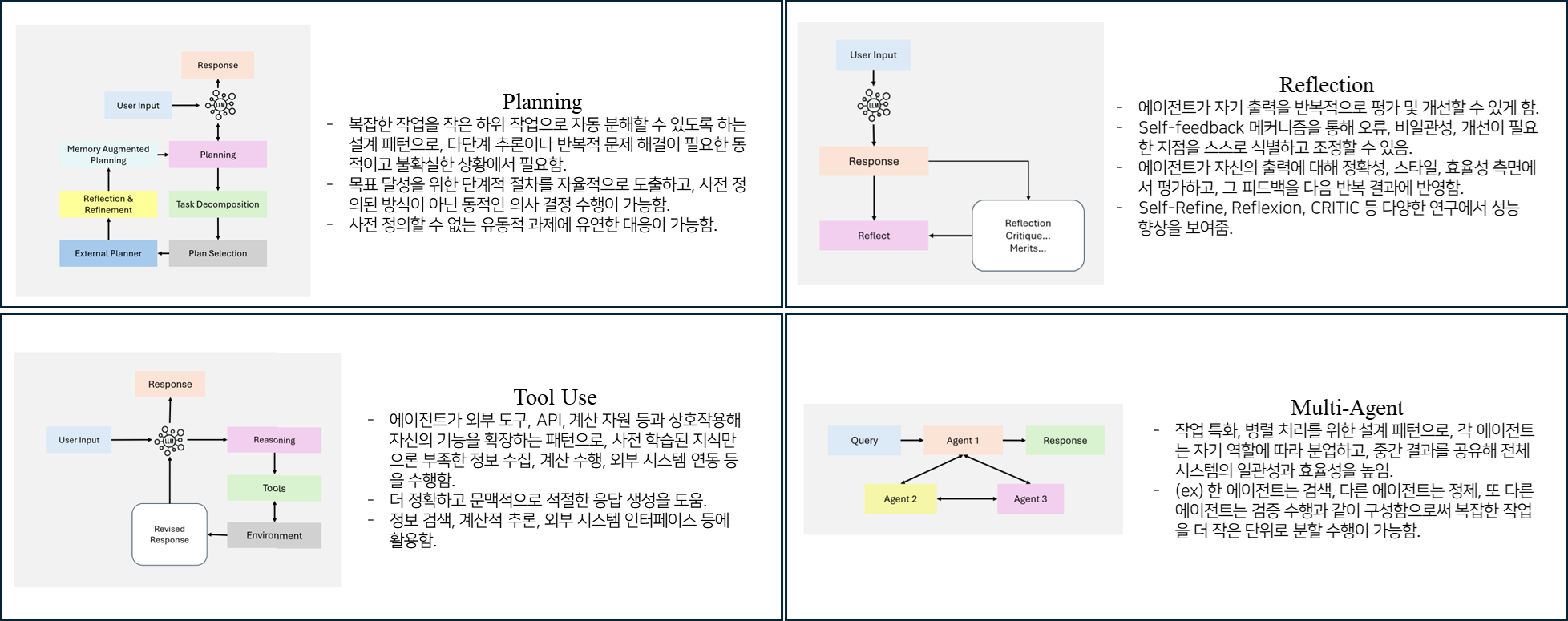
Planning은 크고 복잡한 작업을 더 작고 관리하기 쉬운 요소로 나누기 위한 패턴으로, 하나의 큰 작업을 수행하기 위해 어떤 순서로 에이전트를 실행할지 자율적으로 결정한다.
이 과정에서 아래의 사진처럼 하나의 목표 수행을 위해 한 번에 목표 달성을 위해 실행해야 하는 Sub-Task를 판단하고 실행 순서를 결정해 그 계획에 따라 순차적으로 실행하도록 할 수도 있고, Sub-Task의 결과 값을 받고, 그 결과 값에 따라 필요하다고 판단한 다른 Sub-Task를 호출하도록 할 수도 있다.

CoT (Chain of Thought)
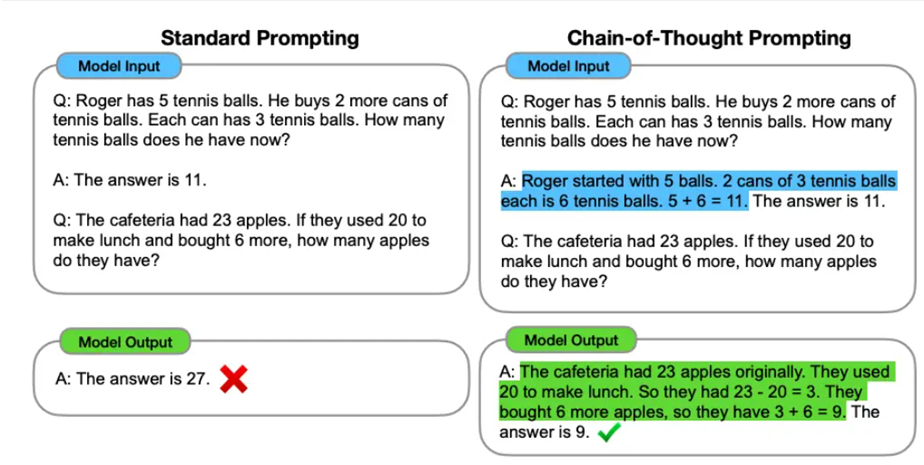
CoT는 하나의 에이전트가 단계적 추론을 통해 판단할 수 있게 하는 기법이다. 하지만 이는 문제 해결을 위해 논리적 단계를 거쳐 답변을 생성하도록 유도하긴 하나, 환경(외부 Tool)과 직접 상호작용하진 않는다.
외부 도구와 직접 상호작용하지 않으므로 내부 데이터에만 의존하게 되고, 그로 인해 외부 툴을 활용한 피드백이 어렵다. 이러한 이유에서 논리적 사고 유도에는 유용하지만, 행동 기반 상호작용에는 한계가 존재한다.
ReAct
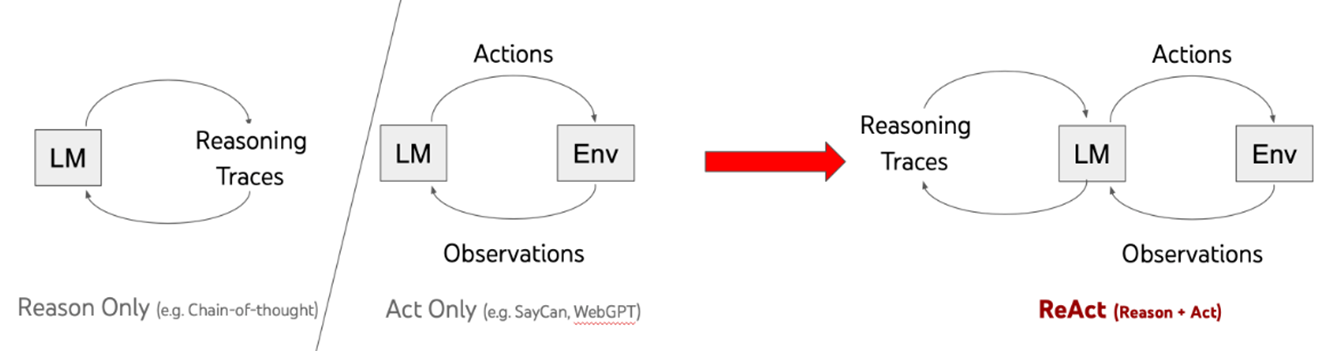
ReAct는 LLM이 복잡한 과제를 일련의 사고 과정, 행동, 관찰로 분해할 수 있도록 하는 기법을 의미하며, 추론(reasoning) + 행동(action) + 관찰(observation)의 반복을 통해 추론한다.
Reason Only와 Action Only를 결합한 접근 방식이기에 사고 과정을 명확히 할 수 있고, 왜 특정 행동을 선택했는지에 대한 이해도 가능하며, 내부 데이터에만 의존한다는 CoT의 한계를 극복한 방법론이라고 할 수 있다.
하지만, ReAct를 활용할 때 LLM은 한 번에 하나의 하위 문제만 계획하기에 전체 과제에 대한 전역적인 계획을 세우는 것은 어렵다. 따라서 문제 해결의 경로가 최적이 아닌 경로로 이어질 수 있다는 단점이 존재하고, 이로 인해 토큰 낭비가 발생할 수 있다.
ReWOO
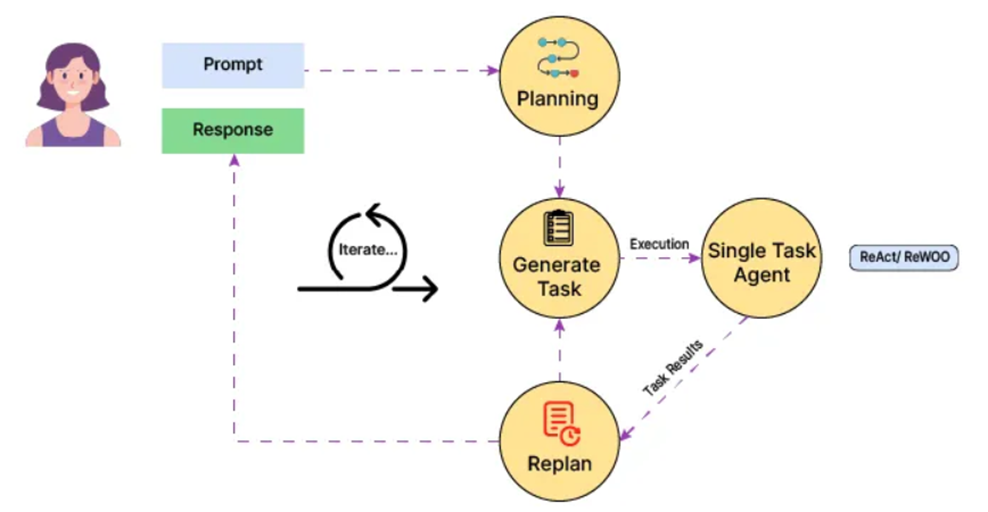
ReWOO는 전체 목표를 먼저 계획하고, 그 후 계획에 따라 하나씩 실행하는 방법으로, ReAct와는 달리 명확한 계획 수립 후 실행이 가능하므로 토큰 소모도 적고 빠르게 수렴하며, 작업자와 실행자의 분리를 통한 명시적 제어가 가능하다.
ReWOO의 주요 주요 구성 요소는 다음과 같다.
- Planner : 정해진 포맷으로 계획 생성
- Worker : 제공된 인수로 툴 실행
- Solver : 전체 계획, 도구 호출 응답을 바탕으로 최종 응답 생성
아래의 사진처럼, ReWOO 방식을 활용하면 Planner를 통해 어떤 도구를 호출해야 할지 전체 계획을 수립하고, 수립된 계획에 기반해 Worker가 작업을 수행하고 결과를 도출하면 그 결과에 기반해 Solver가 최종 답변을 낸다.
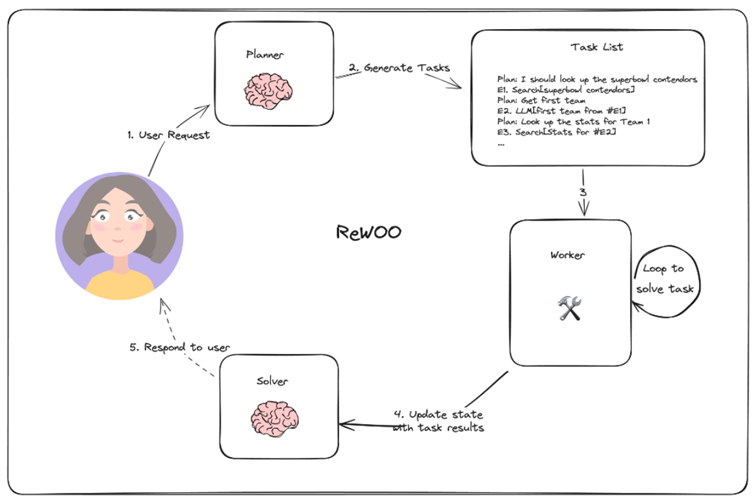
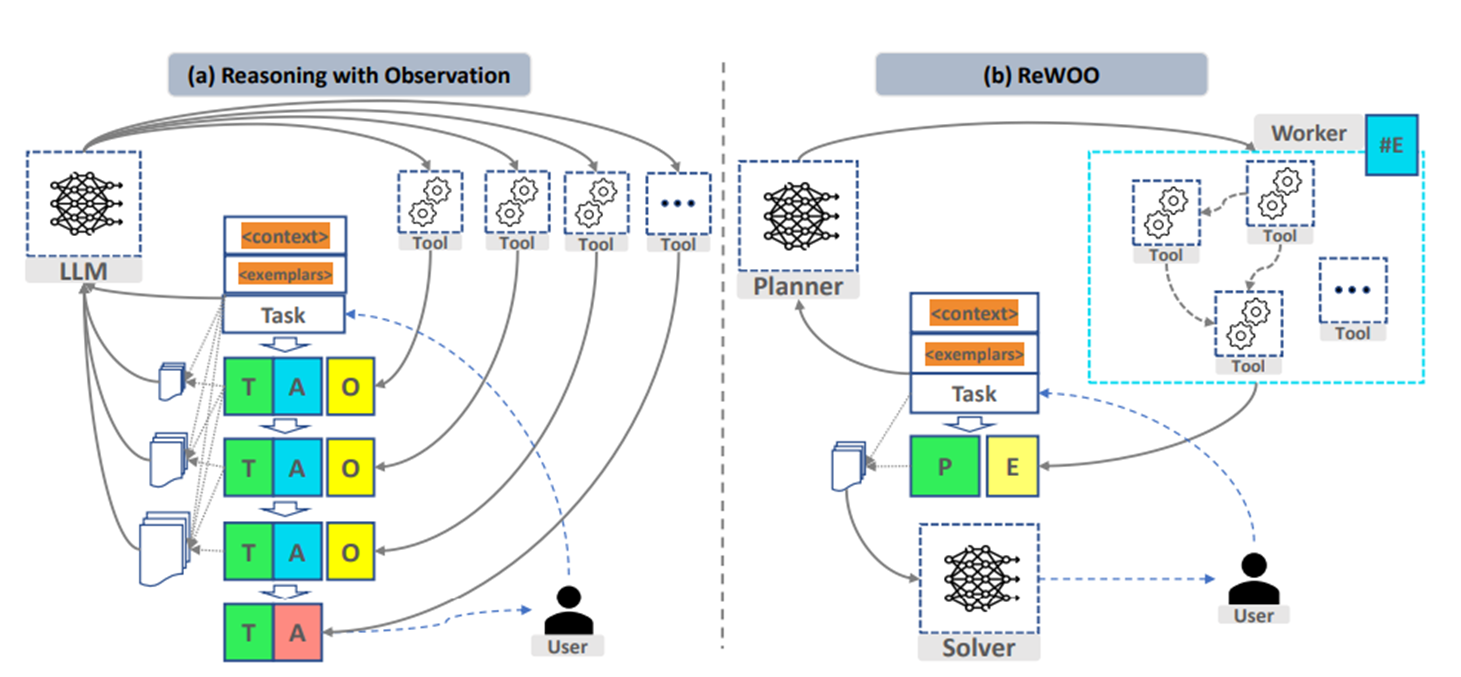
아래의 사진은 ReAct 방식과 ReWOO 방식의 비교이다. ReAct는 Thought (추론) -> Action (행동) -> Observation (관찰)의 반복으로 이뤄지지만, ReWOO는 Planner가 도구 호출 계획을 한 번에 세우고 Worker가 도구를 실행하면, Solver가 Planner의 결과 + Worker의 Execute 결과로 최종 답변을 생성한다.
아래의 표는 ReAct 방식과 ReWOO 방식을 비교한 것이다.

Reflection
Reflection은 스스로 산출물을 평가하고 개선하는 능력을 향상시키는 데 중점을 둔 패턴이며, 이는 프롬프트에 대한 초기 응답을 생성하고, 출력 품질과 정확성을 평가한 후, 자체 피드백을 기반으로 개선한다.
이와 관련해 Self-Refine, Reflexion, CRITIC 등 다양한 연구가 존재하며, 여기서는 각 연구에 대한 자세한 설명까진 다루지 않는다. (간략한 설명 정도... 다만, 더 자세히 알고 싶다면 아래의 논문들을 직접 읽어보는 것을 추천한다.)
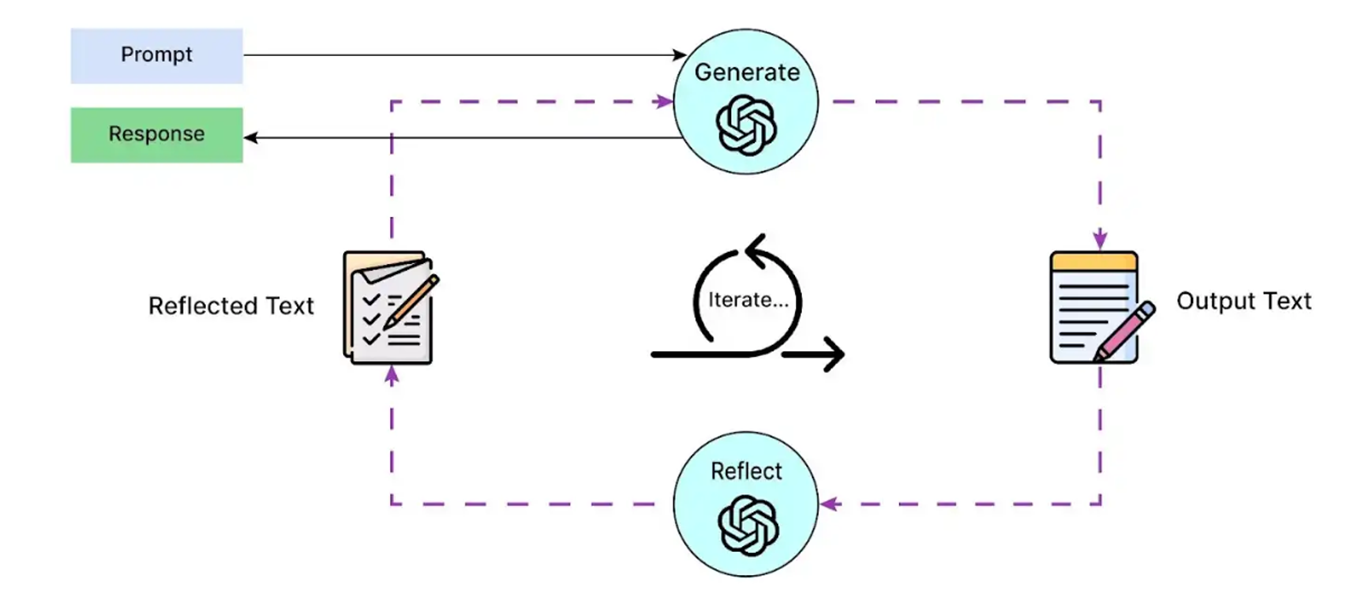
Self-Refine
Self-Refine은 단일 LLM을 활용해 지속적인 피드백 및 개선을 진행하는 기법으로, 모델 M이 자신의 응답을 다시 읽고 그 결과에 대한 자체 피드백을 생성하고, 그 피드백을 기반으로 응답을 개선하는 구조(이전 출력 + 피드백 = 새 출력)를 지닌다. 이 과정에서 추가적인 모델 학습은 필요하지 않다.
다만, 이는 단일 생성 추론 작업에 한정되며, 숨겨진 제약 조건, 의사결정, 이진 보상 및 메모리가 지원되지 않는다.

Reflexion
Reflexion은 강화학습과 유사한 구조를 지닌 기법으로, 언어적 피드백을 통해 언어 기반 에이전트를 강화하고 메모리와 자기 성찰을 활용해 에이전트가 과거의 경험에서 배울 수 있도록 한다.
또한, 이 방식은 자신의 응답에 대해 성찰하고, 자기 비판에 기반해 다시 실행하여 개선하기에 응답의 품질이 좋아지지만, 실행 시간이 증가할 수 있다.
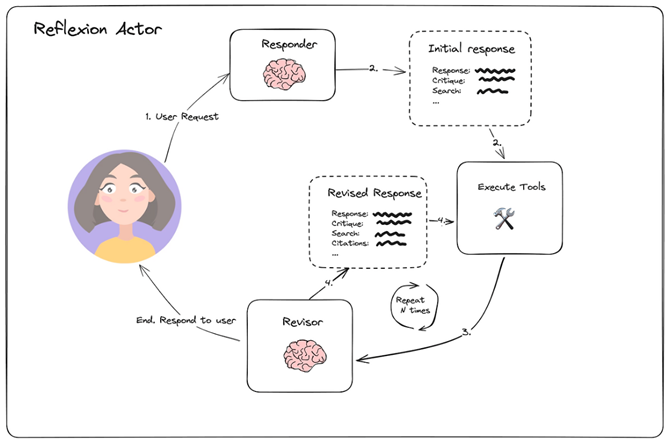
아래의 사진과 같이 Reflexion은 초기 응답을 생성하고, 그 응답에 대해 평가하고, 피드백하고, 다시 결과를 생성한다. 이를 통해 hallucination을 줄이는 효과도 있어 응답의 신뢰성을 높일 수 있다.
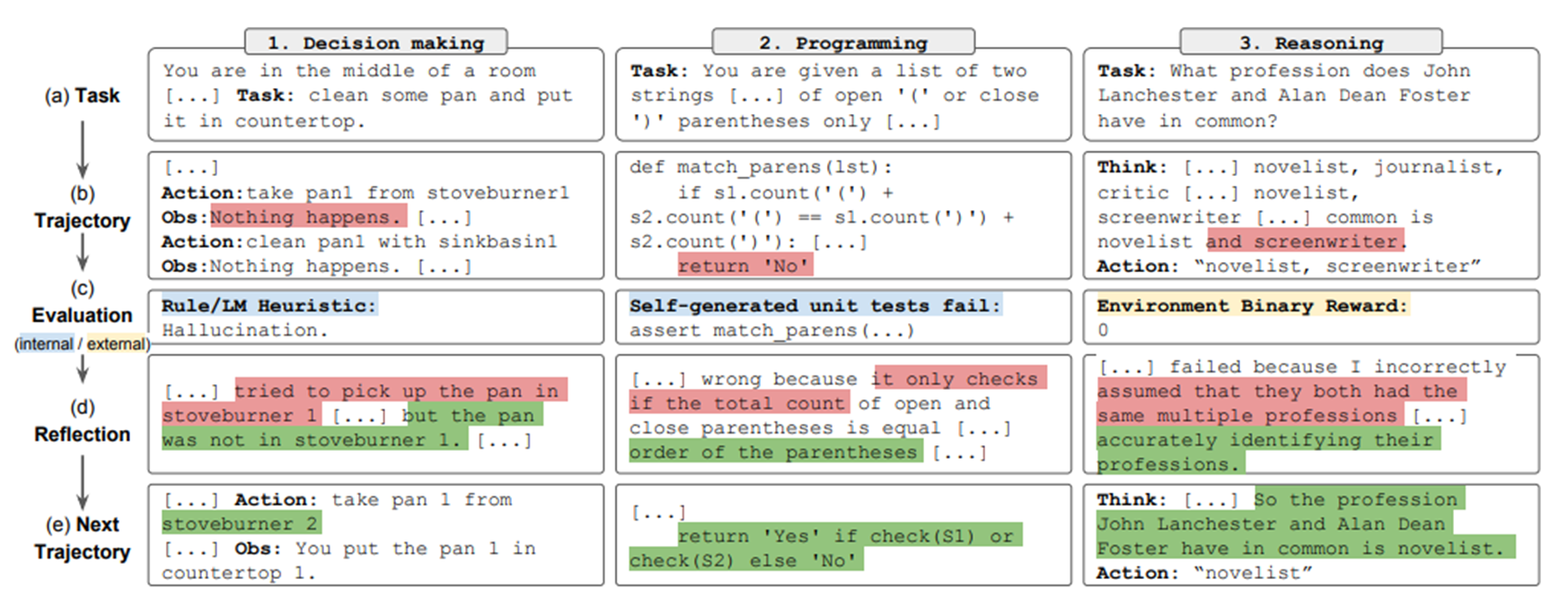
CRITIC
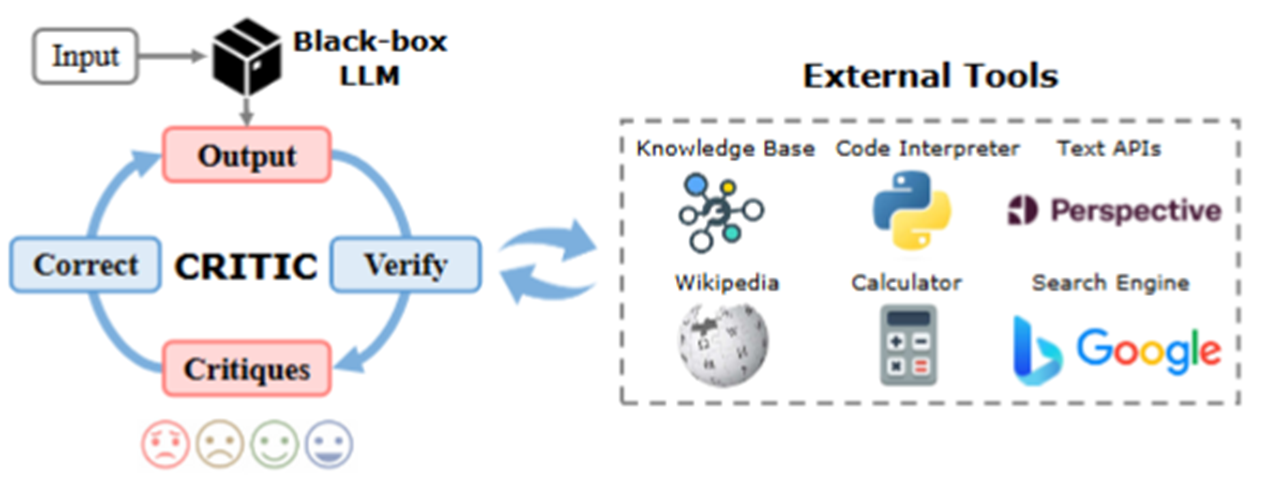
CRITIC은 LLM이 낸 출력에 대해 비판 -> 검증 -> 수정하면서 더 나은 출력을 만들어내는 구조를 의미한다. 이를 위해 LLM이 생성한 답변을 외부 Tool을 활용해 검증하고, 수정하는 과정을 거친다.
다시 말해, 초기 출력을 다양한 외부 툴을 활용해 검증하고, 그 검증 결과를 바탕으로 출력을 점진적으로 수정하겠다는 것이 CRITIC의 기본 아이디어이다.
Tool Use
Tool Use는 LLM이 외부 도구 및 리소스와 상호작용하여 문제 해결 능력을 향상시킬 수 있도록 하는 패턴이다.
어떠한 외부 도구를 사용할 것인지 정하는 방법에는 다양한 방법들이 있지만, 여기서는 3가지 정도만 살펴보고자 한다.
Gorilla
Gorilla는 툴을 어떻게 사용할지를 학습하기 위한 기법이다. 다시 말해, 정확한 API(툴) 호출 코드를 생성하기 위한 기법이다.
기존 LLM은 함수 이름이나 인자 등을 자주 틀려 API를 제대로 활용하지 못하기에 LLaMA 기반 모델을 API 호출에 특화해 fine-tuning한 결과 GPT-4보다 API 호출 정확도에 있어서 더 나은 성능을 보였다고 한다.
참고 사항
Toolformer와 Gorilla의 차이점
- Toolformer : 스스로 학습 데이터를 생성해서 어떤 상황에, 어떤 툴을 사용해야하는지, 즉 언제 쓸지를 학습하게 하자 !
- Gorilla : 정확한 방식으로 툴을 호출할 수 있도록 하자 !

MM-REACT
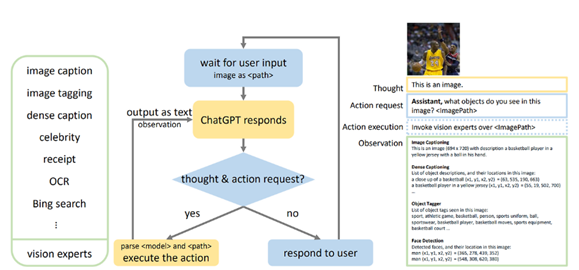
MM-REACT는 기존 ReAct 구조를 멀티 모달 환경을 위해 확장한 것으로 이해하면 된다. 이는 수많은 Vision Experts를 구성해 LLM에 Visual Understanding 기능을 부여하며, 이를 통해 텍스트 뿐만 아니라 이미지, 표, 영상 등을 처리할 수 있다
그리고 이 처리 과정에서 기존 ReAct 구조와 마찬가지로 LLM이 생각 -> 도구 선택 -> 행동 순서로 작동하도록 설계한다.
Chain-of-Abstraction
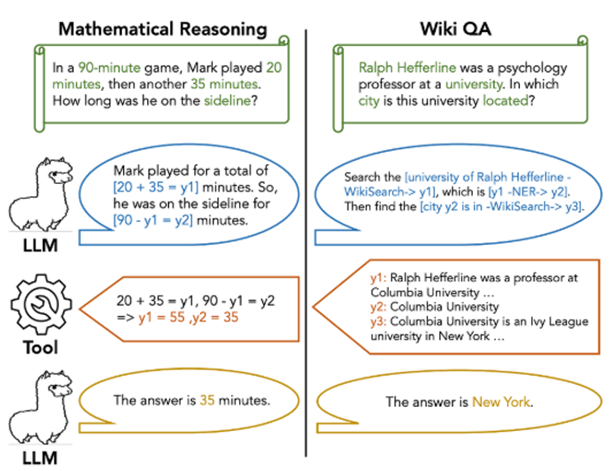
LLM이 툴을 사용할 때 순서를 잘못 정하거나 중간 값을 헷갈리는 문제가 존재한다. Chain-of-Abstraction은 이러한 문제를 해결하기 위해 추상적으로 전체 계획을 세우고, 도구 사용이 필요한 부분을 추상 토큰으로 남겨둔다. 그리고 모든 추상 계획을 세우고 난 이후 실제 도구를 호출해 값을 채우는 방식을 활용한다.
아래의 사진처럼 도구 호출이 필요한 부분에 y1, y2처럼 추상 토큰을 남겨두고, 계획 생성 이후 툴을 호출하여 추상 토큰 속 들어갈 값을 채워 답변을 생성한다.
Multi-Agent
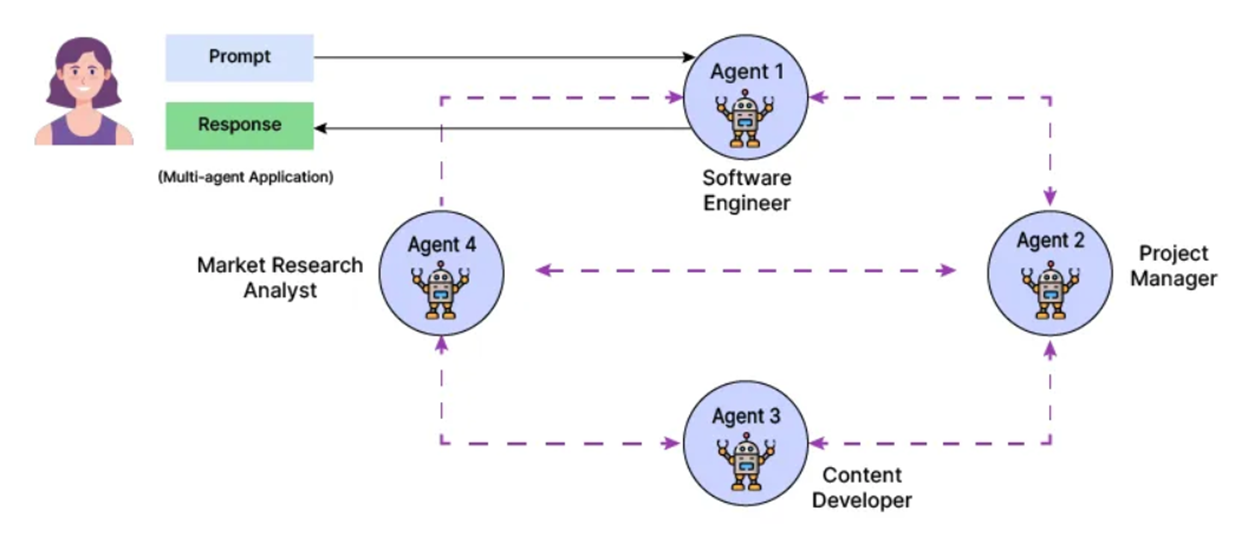
멀티 에이전트 패턴은 다양한 하위 작업을 처리하기 위해 여러 에이전트를 할당하는 패턴으로, 각 에이전트는 각자의 업무를 독립적으로 수행하는 동시에 공통의 목표 해결을 위해 소통하고 협업해 통합된 결과를 달성하는 것을 목표로 한다.
아래의 사진처럼 하나의 목표 달성을 위해 Software Engineer, Project Manager, Market Research Analyst, Content Developer 등 여러 역할의 에이전트로 나누고, 이들이 협업하여 개발하는 구조로 설계했을 때 하나의 LLM을 여러 번 호출하는 것일지라도 각 호출마다 역할을 분리해 호출하고 작업을 수행한 경우, 역할을 분리하지 않고 호출해 작업을 수행한 경우보다 그 성능이 좋은 경우가 많기에 이러한 구조를 사용한다.
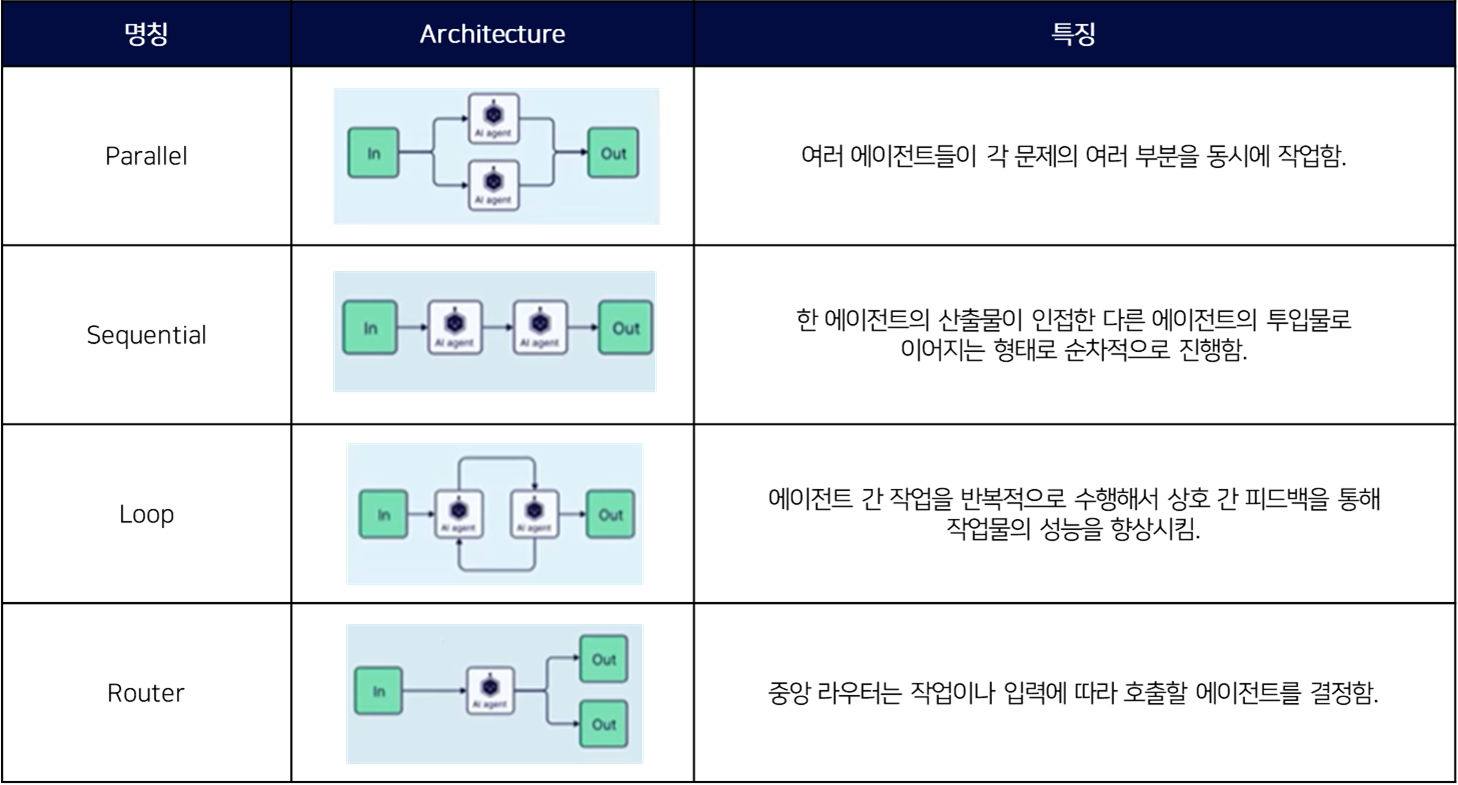
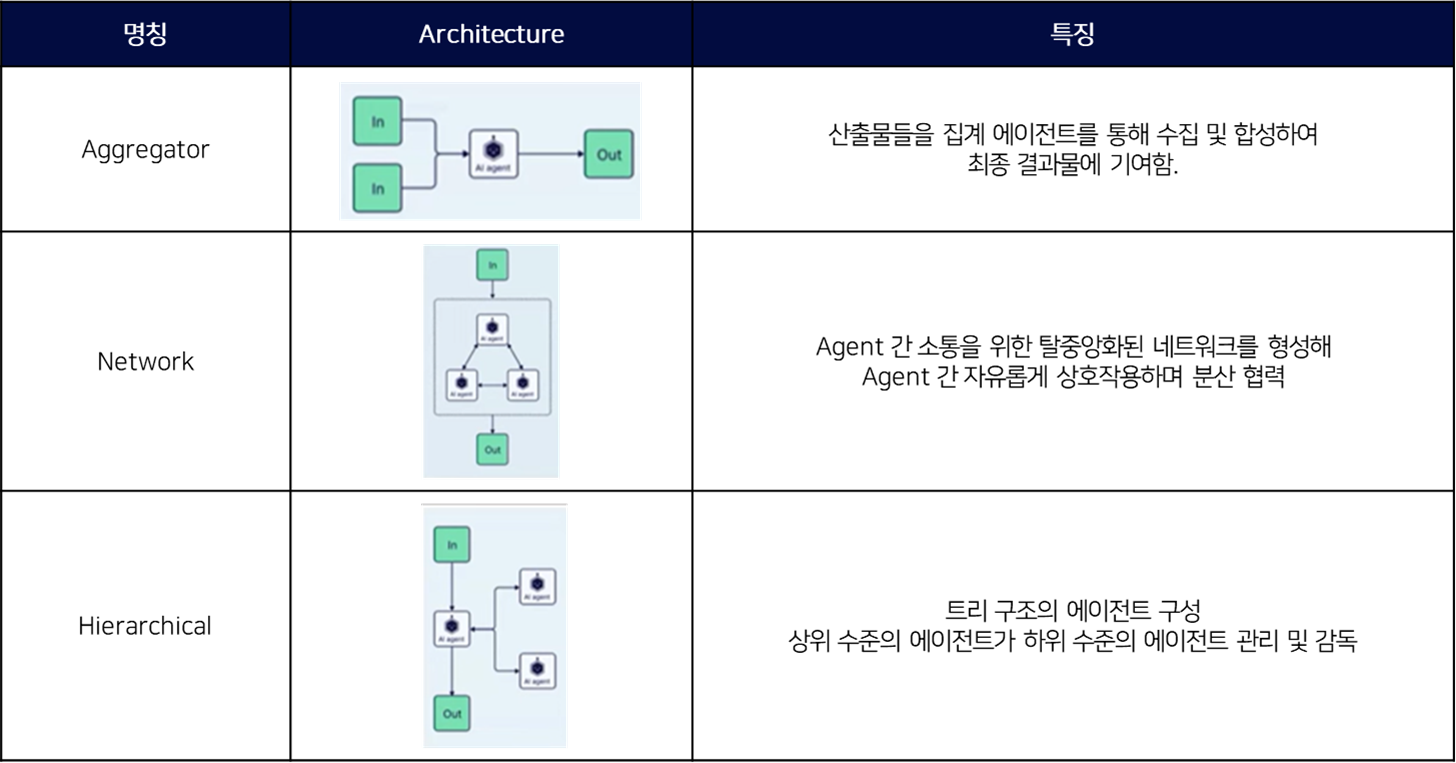
Multi-Agent 패턴에 관한 자세한 설명은 아래의 표로 대체한다.
참고 자료
https://arxiv.org/pdf/2305.18323
https://arxiv.org/pdf/2305.11738
https://arxiv.org/pdf/2305.15334
https://arxiv.org/pdf/2402.02716
https://arxiv.org/pdf/2305.11738
https://arxiv.org/pdf/2303.11381
https://arxiv.org/pdf/2401.17464
https://arxiv.org/pdf/2505.10468
https://arxiv.org/pdf/2506.04980
https://arxiv.org/pdf/2501.09136
https://arxiv.org/pdf/2303.17651
https://www.deeplearning.ai/the-batch/agentic-design-patterns-part-2-reflection/
https://discuss.pytorch.kr/t/coa-chain-of-abstraction-efficient-tool-use-with-chain-of-abstraction-reasoning/3412
https://www.analyticsvidhya.com/blog/2024/10/agentic-design-patterns/
https://rudaks.tistory.com/entry/langgraphPlanning-Agents-Reasoning-without-Observation
https://velog.io/@jingyeom/SELF-REFINE-Iterative-Refinement-with-Self-Feedback-%EB%A6%AC%EB%B7%B0
https://velog.io/@dutch-tulip/reflexion
https://taewan2002.medium.com/reflexion-%EC%8A%A4%EC%8A%A4%EB%A1%9C-%EC%84%B1%EC%B0%B0%ED%95%98%EA%B3%A0-%EA%B0%9C%EC%84%A0%ED%95%98%EA%B8%B0-7541ecfb8d74
https://blogs.nvidia.com/blog/what-is-agentic-ai/
https://www.promptingguide.ai/kr/techniques/reflexion
https://www.youtube.com/watch?v=Dg4VXIKdTFo
https://youtu.be/fryDDMI3kfQ?si=ochJm5XbAUr4G8mw

이해가 너무 잘 되네요