강화학습이란?
강화학습은 순차적인 의사 결정 문제를 해결하는 방법을 의미하며, 실세계의 다양한 문제들은 순차적인 의사 결정 문제로 정의될 수 있다.
이러한 순차적 의사 결정 문제를 해결하려고 할 때 에이전트는 하나의 목표를 갖게 되고, 목표 달성을 위해 행동을 취하면 목표 달성에 얼마나 가까이 다가갔는지에 대한 피드백을 얻게 된다.
일반적으로 목표 도달을 위해선 여러 번의 순차적 행동이 필요하고, 행동은 주변 환경을 변화 시키고, 변화와 피드백을 모두 관찰해 그에 대한 대응으로 다음에 취할 행동을 결정한다.
이처럼 강화학습에서는 행동에 따른 변화를 확인하고, 이에 대한 피드백에 따라 다음에 취할 행동을 결정한다. 이때, 행동에 따른 변화를 확인하는 학습자를 에이전트(agent)라 부르고, 학습자를 둘러싼 모든 환경을 환경(environment)라고 하며, 강화학습은 인공 에이전트가 문제를 해결하기 위해 학습하게 하기 위한 방법을 연구한다.
강화학습 문제의 표현
강화학습 문제는 에이전트와 환경으로 구성되는 하나의 시스템으로 표현될 수 있으며, 환경은 시스템의 상태를 나타내는 정보를 만들어 내는데, 이를 상태(state)라고 한다.
에이전트는 상태를 관측하고 그로부터 얻은 정보를 활용해 행동(action)을 선택하여 환경과 상호작용한다. 이후, 에이전트의 행동을 통해 환경은 다음 상태로의 전이(transition)를 겪게 되고, 결과적으로 다음 상태와 보상(reward)이 에이전트에게 전해진다.
이렇게 상태 → 행동 → 보상의 순환 주기가 완성될 때, 시간 단계(time step)가 지나갔다고 표현하며, 이러한 순환 주기는 문제가 해결될 때까지 반복된다.
강화학습에서는 행동 생성 함수, 즉 상태로부터 행동을 도출하는 함수를 사용하는데, 이를 정책(policy)이라고 부른다. 행동은 환경을 변화시킴으로써 에이전트가 관측하게 될 것과 다음에 취하게 될 행동에 영향을 미치며, 에이전트와 환경이 서로에게 미치는 영향은 시간의 흐름을 따라 계속되므로 이를 순차적 의사 결정 과정으로 생각할 수 있다.
그리고 강화학습 문제는 목적(object)을 가지는데, 이는 에이전트가 받는 보상의 총합으로, 에이전트의 목표는 좋은 행동을 선택함으로써 이 목표를 최대로 달성하는 것이다. 에이전트는 시행착오의 과정 속에서 환경과 상호작용하고, 환경으로부터 받는 보상 신호를 통해 좋은 행동을 강화하여 행동 선택을 학습한다.
이를 통해 강화학습의 개념을 정리해 보면, 강화학습은 에이전트가 환경과 상호작용하면서 상태를 관찰하고 행동을 선택하여 보상을 받으며, 이 경험들을 통해 정책을 학습해 나가는 과정이다. 이러한 강화학습의 궁극적인 목표는 단순히 순간적인 보상을 얻는 것이 아니라, 장기적으로 누적 보상(return)을 최대화하는 방향으로 행동 전략을 개선하는 것이다.
쉽게 이야기 하면,
정책 = 행동을 선택하는 도구이자, 상태와 행동을 매핑하는 단순 함수 / 상태를 입력받아 행동을 출력하는 함수, 혹은 상태에 따른 행동의 확률 분포를 정의하는 도구
강화 학습의 목표 = 좋은 정책을 찾아 누적 보상을 최대화하는 것
강화학습 = 상태를 통해 정책 함수로 행동을 도출하고, 그 행동을 통해 얻는 보상을 장기적으로 최대화하는 과정
로 정의할 수 있다.
++) 시간 단계와 경험, 에피소드, 궤적에 대한 정리
- : 신호가 발생하는 시간 단계
- : 경험 (상태, 행동, 보상)
- 에피소드 : t = 0에서부터 환경이 종료되는 시간 수평선까지의 구간
- : 궤적, 한 에피소드에 걸친 경험의 연속 (일반적으로 에이전트가 좋은 정책을 학습하기 위해선 수백 개에서 수만 개에 이르는 에피소드가 필요함)
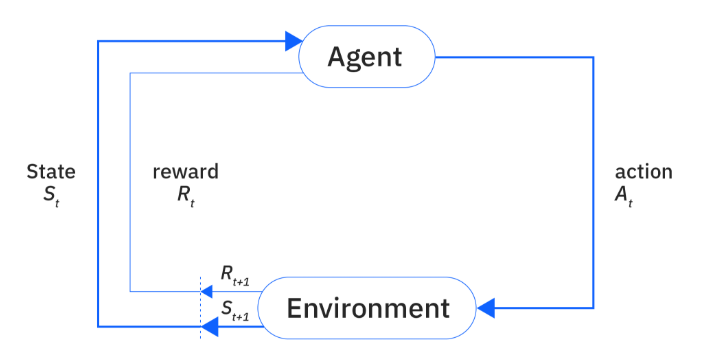
MDP로서의 강화학습
강화학습에서는 순차적 의사결정을 위한 수학적 모델인 MDP로 전이 함수(transiton function)를 활용한다. 상태 로부터 로 환경이 전이할 확률을 에피소드 안에서 지금까지 발생했던 모든 상태(s)와 행동(a)에 따라 결정되는 방식으로 구하는 것은 매우 어렵기 때문이다.
따라서 강화학습에서는 보통 마르코프 결정 과정(MDP)으로 모델링된다. MDP에서는 현재 상태와 행동에 따라 다음 상태로 전이될 확률을 전이 함수로 정의한다.
이때 중요한 가정은 마르코프 특성(Markov Property)으로, 이는 미래 상태가 오직 현재 상태와 행동에만 의존하며, 과거의 모든 이력에는 의존하지 않는다는 것을 의미한다. 다시 말해, 어떤 시간에 특정 상태에 도달하든 그 이전에 어떤 상태를 거쳐왔든 다음 상태로 갈 확률은 항상 같다는 것이 마르코프 특성이다.
~ # 은 이 확률 분포 안에서 샘플링된다는 의미
MDP는 4개의 튜플로 정의되며, 는 상태의 집합, 는 행동의 집합, 는 환경의 상태 전이 함수, 은 환경의 보상 함수이다. 또한, 에이전트가 전이함수 또는 보상 함수를 모른다는 가정이 존재하며, 에이전트는 환경 속에서 스스로 경험하는 를 통해서만 두 함수에 대한 정보를 얻을 수 있다. (POMDP가 아닌 MDP이므로)
강화학습 문제를 표현하기 위해 에이전트가 최대로 달성해야 하는 목적을 하나의 에피소드로부터 발생한 궤적을 통해 정의하면 다음과 같다. (다시 말해, 누적 보상 함수/목적 함수를 정의한 것이다)
여기서는 하나의 궤적 안에서 발생한 보상의 할인 값을 모두 더한 것으로 이득을 정의하므로 ∈ [0, 1]은 할인율을 나타낸다. 이는 보상에 대한 가중치로 이해할 수 있으며, 먼 미래의 보상까지 예측하려면 값이 커져 계산의 어려움이 생기므로 이를 활용한다. 이면 즉시 보상을, 1이면 미래 보상까지 거의 동일한 중요도로 고려한다.
목적(objective)은 많은 궤적의 이득에 대한 기댓값으로 다음과 같이 표현할 수 있다.
강화학습에서 학습하는 함수
정책 는 주어진 환경 속에서 목적을 최대로 달성하기 위해 에이전트가 취해야 하는 행동을 알려주며, 강화학습 제어 루프에서 에이전트는 모든 시간 단계에서 상태 를 관측한 후 어떤 행동을 취해야 하는데, 제어 루프를 작동시키는 행동이 정책으로부터 만들어지기에 정책은 제어 루프에서 필수적이다.
이러한 정책은 동일한 상태에 대해 확률적으로 다양한 행동을 도출할 수 있으며, 이 경우 주어진 상태에 대해 행동이 도출될 확률을 로 나타낼 수 있으며, 정책으로부터 추출된 행동을 와 같이 표현할 수 있다.
아래의 식 는 상태의 좋고 나쁨을 나타내며, 이는 에이전트가 상태에서 현재의 정책 를 따라 행동한다 가정했을 때 기대할 수 있는 이득을 나타낸다.
아래의 식 이득 는 상태-행동 쌍의 좋고 나쁨을 평가하며, 상태에서 행동을 취함으로써 얻게 되는 이득의 기댓값을 나타낸다. 이 또한 와 마찬가지로 이득은 현재 상태로부터 에피소드가 끝날 때까지의 구간에서 계산되므로 상태 s 이전의 모든 보상을 무시하기에 미래 지향적인 값이다.
