개요
- CNN은 supervised image classification에서 괄목할만한 성능 향상을 이끌어냈습니다.
- 그러나, unsupervised learning, 특히 image generation task에서는 여전히 저조한 성능을 보이고 있습니다. (2015년 기준)
- 이에, 좋은 이미지 생성 성능을 보인, GAN과 CNN을 결합하여 더 선명한 이미지 생성 모델을 설계하고자 하였습니다.
Model Architecture
1. spatial down sampling 함수를 Strided convolution 사용
2. FC layer를 제거
3. Batch normalization 사용
4. Generator의 activation function으로 Relu를 사용
5. Discriminator의 activation function으로 Leaky Relu를 사용
Spatial down sampling 함수로 strided convolution 사용
- CNN에서는 이미지의 차원을 점진적으로 축소하기 위해, layer를 거듭하며 down sampling을 진행합니다.
- 이를 위한, 대표적인 방법으로는 max pooling이 있습니다.
- 그러나, max pooling으로 일부 픽셀을 drop시, back propagation 과정에서 일부 셀들의 gradient가 소실되는 문제가 발생합니다.
소스 : Backpropagation in CNN / CNN의 역전파 / cmu 11785 lecture12
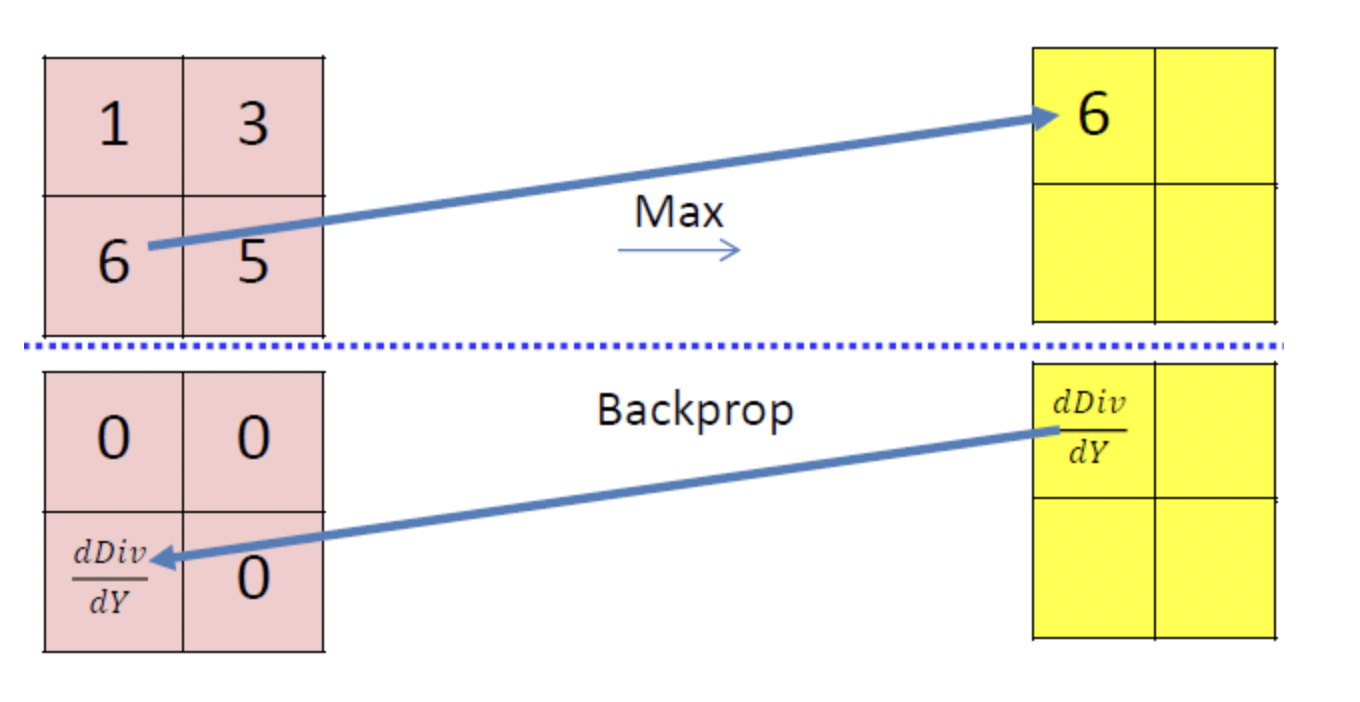
- 그렇기 때문에, DCGAN에서는 max pooling 대신 strided convolution을 사용하여, spatial down sampling을 진행합니다.
- 이를 통해 backpropagation 과정을 통해 이미지의 특징을 잘 학습할 수 있도록 하였습니다.
FC layer를 제거
- 2015년 기준, 당시 이미지 분류 모델들은 FC layer를 제거하고 convolutional layer로 대체함으로써 성능을 향상시켰습니다.
- 이에 DCGAN도, FC layer를 제거하고 이를 convolutional layer로 대체함으로써 모델이 이미지의 특징을 더 잘 학습하도록 하였습니다.
Batch normalization 사용
- 딥러닝의 layer 수가 깊어질수록 gradient가 소실하는 경향이 있습니다.
- 이는 학습 초기의 weight에 큰 영향을 받으며, 이 때문에 딥러닝 초기에는 weight initializing이 중요한 연구 주제 중 하나였습니다.
- 몇몇 연구자들은 이러한 학습의 불안정성이, 학습 과정이 진행되면서 변화하는 분포에 있다고 보았습니다.
- 이를 일정히 해주기 위해, layer 입력 전 평균과 분산을 동일하게 normalizing 해주는 과정을 거치게 되며, 이를 batch normalization이라고 합니다.
- 또한, generator가 local minima에 빠져 특정 cheat sample만 생성하는
mode collapse에도 batch normalization이 효과가 있음을 empiricial 하게 확인하였습니다.
Relu 및 LeakyRelu 사용
- Generator의 activation function으로, Relu를 사용합니다.
- 다만, G의 마지막 layer는 tanh로 설정하여, output image를 생성합니다.
- Discriminator의 activation function으로는 LeakyRelu를 사용하였습니다.
- 이러한 과정들은 수학적 증명을 통한 것이 아닌, 연구자들이 여러 실험을 거치며 empirical하게 얻어진 결과입니다.
Training configuration
- tanh의 범위인 [-1, 1]로 픽셀 값 scaling
- 이외의 전처리는 진행하지 않았습니다.
- batch size : 128
- optimizer : Adam
- learning rate : 0.0002
- LeakyRelu scope : 0.2
- weight initialize : 평균 0, 표준편차 0.02
분류 성능 평가
unsupervised learning의 성능 평가 방법 중 하나로, 학습 모델을 feature extractor로 사용 후, linear classifier를 통해 분류 성능을 측정하는 방법이 있습니다.
DCGAN을 feature extractor로 사용하여 CIFAR-10 데이터 분류
- 기존의 k-means 알고리즘을 기반으로 한 feature extractor + 1 layer classifier는 80.6%의 성능을 보였습니다.
- 위 모델을 baseline으로 설정 후 DCGAN을 통한 feature 추출의 성능을 확인해보고자 하였습니다.
- DCGAN을 imagenet 데이터에 학습하여 feature 추출기로 활용하였습니다.
- DCGAN으로 feature 추출 후, linear L2-SVM 모델에서 분류한 모델은 82.8%의 정확도를 보였습니다.
- imagenet 데이터로 학습한 DCGAN feature extractor도 CIFAR-10에서 매우 좋은 성능을 보임을 확인하였고, 더불어 data domain에 specific 하지 않은 강인함을 증명하였습니다.
네트워크 내부 분석 및 시각화
비지도 학습 모델, 그 중에서도 embedding을 기반으로 한 생성 모델들은 다음의 조건을 만족하도록 학습이 진행되어야 합니다.
1. 모델이 이미지를 외운 것이 아닌 제대로 생성해야합니다.
2. embedding space에서 작은 이동이 결과 이미지에서 큰 차이로 이어져서는 안되며, 점진적인 변화를 보여야합니다.
walking in the latent space
- GAN에서 generator의 입력 노이즈 는 생성하고자 하는 이미지의 의미 정보를 담고 있습니다.

- 이를 통해 vector space에서 연산이 가능해집니다.
- 예를 들어, 침실의 이미지를 생성한 noise 과 창문의 이미지를 생성한 noise 를 더한 벡터 를 generator를 통해 이미지 생성 시, 창문이 달린 침실 이미지가 생성되게 됩니다.
이를 통해, latent space의 벡터들이 단순히 이미지를 암기하여 mapping하는 것이 아닌 그 의미정보를 함께 기억하고 있음을 알 수 있으며, 이를 통해 실제로 이미지를 ‘생성'하고 있음을 알 수 있습니다.
visualizing the discriminator features

- 기존 CNN 모델의 가장 큰 단점은 설명력이 떨어지는 black box 모델이라는 것입니다.
- 2022년 현재, gradCAM(2016)과 같은 이미지 딥러닝에서의 XAI 기법들이 등장하였지만, DCGAN이 제안된 2015까지만 하더라도 CNN에서의 설명력은 저조하였습니다.
- DCGAN은 필터와 이미지를 통해, convolution 연산 시 필터가 집중적으로 학습하는 feature가 있음을 확인하였습니다.
Vector arithmetic on face samples

- 이미지, 텍스트와 같은 고차원 데이터를 저차원의 latent로 mapping 시키는 가장 큰 이유 중 하나는 이를 통해 연산을 할 수 있다는 것입니다.
- 가장 유명한 예시로 왕-여왕 연산이 있습니다.
- generator의 noise vector 의 연산을 통한 이미지 생성과정은 위에서 설명하였으므로 넘어가도록 하겠습니다.
