비전 인공지능을 만들다보면 가장 공수가 많이 드는 작업은 단연 라벨링이다. 특히, segmentation task라도 맡게 되면 객체 위에 브러쉬로 꼼꼼히 칠을 하거나 외곽선을 따라 하나하나 정성스레 점을 찍어주는 미친 노가다를 해야한다. 하물며 객체가 일반적인 개, 고양이, 자동차라면 기존에 학습해둔 대형 모델의 덕이라도 볼 수 있을텐데 내 경우는 조금 이야기가 다르다. 매번 고객사로부터 기상천외한 새로운 공정 이미지가 들어오고 디펙의 양상도 모두 다르기 때문에 제로부터 하나하나 라벨링을 해줘야 한다.
이런 총체적인 난국에 난국이 더해지고 반복되는 라벨링 기계의 업무를 수행하다보니 심신이 지쳐버렸다. 이제는 조금 편하게 모델을 만들고 싶다는 니즈가 생겼다. 그러던 중 발견하게 된 것이 약지도 기반 세그멘테이션 방법론(Weakly Supervised Semantic Segmentation, 이하 WSSS)이다.
본 포스팅에서는 WSSS의 기본 개념과 이와 관련하여 어떤 연구가 있었는지 서베이 논문을 통해 내가 공부한 내용을 공유하고자 한다.
1. WSSS의 등장
앞서 내가 말했던 문제(segmentation을 위한 미친 라벨링 코스트)는 비단 나만 겪은 문제는 아니었다. 당연히 이 길을 걸었던 선배 연구자들도 똑같이 고통을 받았고, 그들 또한 답을 찾고자 노력했다. 우리 멋진 선배님들이 내놓은 결론은 다음과 같다.
상대적으로 라벨링 비용이 적은 Image level label이나 bounding box를 이용하여 segmentation task를 진행해보자
누군가는 "뭐야? 결국 라벨링을 해야하잖아?"라고 실망할 수도 있겠지만 그 사람은 분명 라벨링을 안 해본 사람이다. 한번이라도 세그멘테이션 라벨링을 해본 사람은 저 멋진 아이디어에 눈을 반짝일 수 밖에 없을 것이라 확신한다.
아무튼 선배님들의 아이디어는 결국 classification이나 object detection에서 사용하는 라벨을 이용하여 segmentation을 진행하겠다는건데, 이 대목에서 내가 들었던 생각은 딱 하나였다. "이게 가능해?" 당연히 완벽한 라벨을 통해 학습하는 Fully semantic Segmentation과 비교할 때 성능은 다소 아쉽다만 그래도 가능은 하다는 것이 선배님들의 결론이다. 본격적인 설명에 앞서 선배님들이 WSSS에 사용했던 라벨에 어떤게 있는지 먼저 살펴보자.

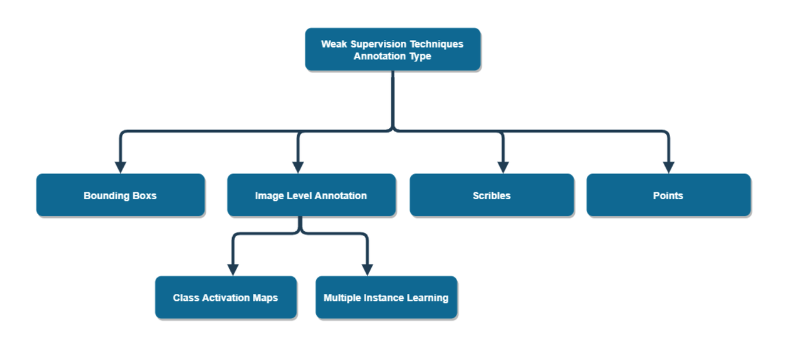
object detection과 classification용 라벨 이외에 scribble과 point라벨도 있다. point의 경우 최근 페이스북에서 발표한 segment-anything(SAM)을 사용해본 사람이라면 익숙할법도 하지만 scribble로 라벨링을 하는 경우는 처음 볼것이다. 나도 이 연구를 하면서 처음 봤다. 그냥 원하는 객체 위에 선을 찍찍 그어주는 다소 신박한 이 방식은 뇌빼고 라벨링이 가능하다는 특징으로 인해 선배 연구자들이 꽤나 애용했던 방식이었다. 이에 대해서는 뒤에서 자세히 설명하도록 하겠다.
추가로 본 포스팅에서는 여러 방법론 중 image level annotation과 bounding box 기반 WSSS 방법론에 대해서 소개하도록 하겠다. 이 후 나중에 작성할 GraphNet 논문 리뷰에서 scribble 라벨 기반의 방법론에 대해서 공유하도록 하겠다.
2. WSSS 모델 설계 시 주요 고려 사항
원래 segmentation과는 전혀 관계가 없던 바운딩 박스나 classification 라벨을 가지고 segmentation을 하다보니 모델이 수렴하는데 어려움을 겪게 된다. 그리고 결과도 당연히 불만족스러울수 밖에 없다. 선배 연구자들도 이 과정을 그대로 거쳤을테고 수많은 좌절을 겪으신듯하다. 그리고 "야 그래도 우리가 쉽게 segmentation을 하겠다고 연구하고 있는데 적어도 이 문제만큼은 해결해야하지 연구 했다고 할 수 있지 않겠냐?"라고 할만한 몇가지 문제 사항을 본인들끼리 결정지으셨다.
- 동일한 객체인데 크기나 모양이 다른 경우가 많다. 이런 경우도 탐지할 수 있어야한다.
- 객체의 정확한 사이즈와 윤곽선을 추출하는 것이 너무 어렵다. 조금만 더 예쁘게 따보자.
- scribble이나 image level 라벨의 경우, 정확히 어떤 객체에 라벨링 된건지 혼동이 온다.
(위의 scribble 예시를 보면 말을 라벨링한 scribble이 사람의 팔 위로도 지나간다.) - 여러 이미지에서 공동 출연하는 객체가 많은 경우, 모델이 해당 클래스들을 구분하지 못할 가능성이 높다.
많은 연구자들이 이런 문제를 고민했다는 사실을 인지하고 이후의 포스팅을 보면은 이해하기 더 수월할 것이다.
3. Image level label based WSSS
먼저 첫 시작으로 이미지 레벨의 라벨을 먼저 보겠다. 위의 예시 이미지에서 볼 수 있듯이 가장 단순한 형태의 라벨로, 이미지 내에 '사람'과 '말' 객체가 있다면 라벨 역시 ['사람', '말']로 하면 되는 아주 심플한 방식이다. 다만, 그만큼 정보가 적다보니 실제 모델을 만드는데는 가장 많은 애로사항을 겪게된다.
단적으로 양불 분류를 예로 들면은 label은 "yes", "no"의 1x1 dimension을 가지게 된다. 그런데 이걸 이용해 segmentation 모델을 만들게 되면 이 1x1의 적은 정보만을 이용해서 이미지 사이즈 만큼의 probability map을 생성해야한다. 이게 가능한가? 라는 고민을 하고 있던 그때 연구자들의 눈에 든 것이 class activation map이다.
XAI 모델의 일종인 CAM은 분류 작업을 수행하고 난 후, 해당 객체가 있을법한 위치를 heatmap으로 시각화하여 보여준다. 선배 연구자들은 이 CAM을 어찌저찌 잘 지지고 볶으면 이걸로 segmentation 라벨을 생성할 수 있을 것으로 기대하였다. 이러한 방식은 Pseudo Supervision 방식이라고 부른다.
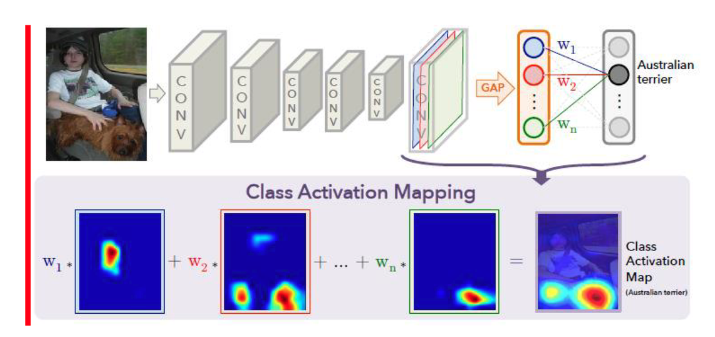

3-1. CAM 기반 mask 생성 과정의 문제점
얼핏보기에는 그럴싸해보이는 이 아이디어는 얼마 안가 난항에 부딪히게 된다. 바로 위의 강아지 마스크를 생성하는 예시를 봐도 알 수 있듯이 마스크가 sharp하지 못하고 경계가 불분명하다는 문제가 있었다. 또한 사람의 Activation 맵을 보면 얼굴과 상반신 일부 부분만 활성화 되어 있는 것을 볼 수 있다. 즉, 사람 마스크를 생성하게 되면 객체의 전체 영역을 활성화하지 못하고 신체의 일부 부위에만 마스크가 생성되는 문제도 있는 것이다.
이런 문제 속에서 우리 선배 연구자들은 너무나 상남자스럽고 가장 원론적인 답을 내놓는다. 바로
CAM을 잘 만들 수 있도록 feature를 잘 추출하자.
결국 돌고돌아 보편적인 딥러닝과 동일한 길(feature를 잘 추출해서 분류 및 탐지 성능을 높이는 방법)을 걷게 되었다. 역시 어디로 가나 정도(正道)는 모두 같다는 것을 알 수 있다.
4. Bounding box based WSSS
Bounding box는 object detection에서 주로 사용하는 라벨링 방식으로, classification 라벨보다는 상대적으로 많은 정보를 담고 있다. 최소한 얘는 객체가 있는 대략적인 위치라도 알려주기 때문이다.
bounding box를 이용한 WSSS는 꽤나 심플하다. 바운딩 박스 내에서 배경과 객체를 구분하는 pseudo label을 만들고 이를 Segmentation모델에 입력으로 넣어 점진적으로 마스크를 개선시키는 방식이다. 여기서 중요한 것은 바운딩 박스를 이용하여 초기 pseudo label을 잘 만드는 것으로, 이에 따라 최종적인 마스크의 퀄리티가 크게 달라진다.
그렇다면 어떻게 바운딩 박스에서 pseudo mask를 만드느냐? 라는 질문을 할 것이다. 선배 연구자들은 GrabCut, CRF 같은 픽셀 기반의 머신비전 방법에서 출발하여 BB-UNet(Bounding Box UNet)과 같은 딥러닝 기법까지 다양하게 사용하였다.
사실 Bounding box based WSSS에 대해서는 크게 할말이 없는게, 성능이 그리 좋지 못하다. 아무래도 앞서 말했던 라벨링된 객체의 애매함 문제가 가장 두드러지기 때문에 그렇지 않을까 싶다(예를 들어, 사람이 개를 안고 있는 사진에서 개에 바운딩 박스를 치고 WSSS 기법을 적용하면 뒤에 서있는 사람과 혼동할 수도 있다). 이러한 이유 때문인지 많은 연구들이 앞서 말한 CAM 기반의 방법론이거나 scribble 기반의 방법이 많으며, bbox 기반 방법론은 확실히 그 수가 적다.
5. 마치며
연구를 한참 하는 도중에 메타(전 페이스북)가 segment-anything을 발표해버리면서 이 분야의 판이 뒤집혀 버렸다. 이제는 간단한 포인트 라벨만으로 정확한 라벨을 추출할 수 있게 되면서 WSSS라는 분야가 다소 약세에 접어들었다는 사실은 부정할 수 없다. 다만, 바이오나 제조 분야처럼 일반적이지 않은 객체에서는 SAM이 정확하게 마스크를 추출하지 못하는 것도 사실이다. 때문에 아직은 이 연구가 유효할 것이라고 생각한다.
최근 연구 동향을 보면 프롬프트를 자동으로 생성하는 방법에 대해 많은 연구가 있는 듯하다. WSSS도 자동 프롬프트 생성에 좋은 대안이 될 수 있을 것이라 기대하며 이 포스팅이 WSSS에 처음 입문하는 연구자에게 좋은 나침반이 되면 좋겠다.
