최근 인프라 스터디를 진행하면서 엘라스틱서치의 기본 개념에 대해서 발표를 하게 되었다. 사실 그렇게 관심있는 주제는 아니었지만 그래도 이왕 맡았으니 다른 스터디원들을 위해서 열심히 개념 조사를 하고 자료를 만들었다. 어찌저찌 만들고 나서 주변 사람들에게 보여주니 첫 개념 잡는데 괜찮았다고 말을 많이 해줘서 블로그에도 한번 게시하기로 결정했다. 부디 이 글을 읽고 엘라스틱서치에 관심있는 단 한명의 뉴비라도 "아!! 엘라스틱서치가 이런거구나"라고 이해할 수 있었으면 좋겠다.
여담으로 내가 공부할때 사용한 리소스의 대부분은 김종민님께서 만든 문서와 유튜브 동영상이다. 사실 내 글을 볼 필요도 없이 이분 유튜브 영상만 봐도 개념 잡는데 전혀 이상은 없다. 포스팅 마지막에 출처를 기입해둘테니 관심 있는 사람들은 꼭 보길 바란다.
1. 엘라스틱서치란?
분산시스템 기반의 검색 엔진
불필요한 수식어를 모두 제거하고 엘라스틱 서치가 뭐냐라고 누군가 물어본다면 나는 딱 저렇게 대답하겠다. 저 문장에서 핵심적인 키워드 2개를 꼽으라면 "분산 시스템"과 "검색 엔진"이다. 이것들이 정확히 뭔지 하나씩 찢어서 살펴보자.
1-1. 검색엔진이 뭔데?

검색 엔진하면은 대부분의 사람들의 머릿속에 저것들이 떠오를 것이다. 나도 그렇다. 알고싶은 키워드를 초록창에 넣으면 그에 해당하는 정보를 뚝딱 반환해주는 것들이 우리가 아는 검색엔진이다. 그런데, 우리 같은 개발자들이 왜 검색엔진을 사용해야할까? 모든 개발자들이 네이버나 구글에서 일하는 것도 아닌데 말이다.
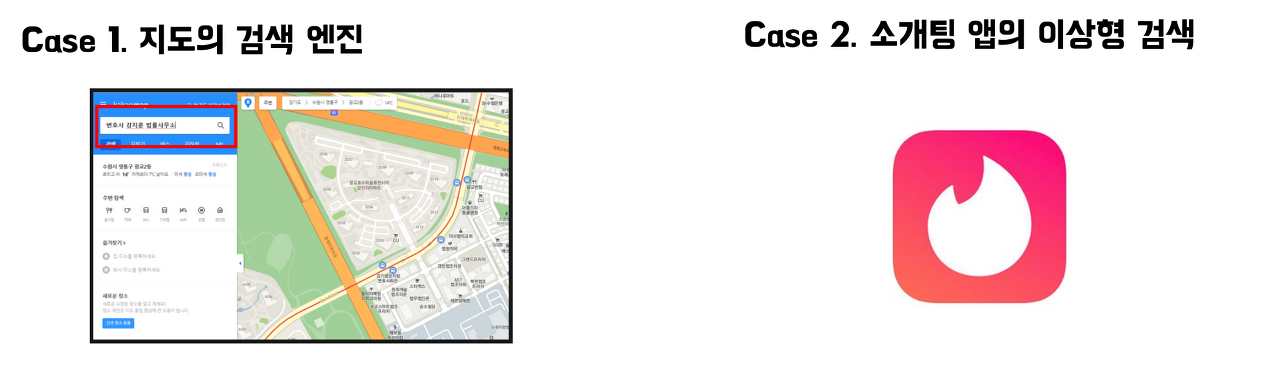
포괄적으로 보면, 위의 케이스들도 검색이라고 볼 수 있다. 목적지를 입력하면 최적의 장소를 반환하는 지도 앱이나, 내 조건과 이상형을 넣으면 이에 해당되는 사람들을 척척 제시해주는 것도 일종의 검색이다. 즉, 검색은 사용자가 원하는 정보를 적절히 필터링해서 제공하는 것이라고 생각할 수 있다.
그렇다면 우리가 검색 엔진에 대해 공부해야할 필요성이 생긴다. 야구 정보를 요약하여 정리하는 페이지를 운영하는 사람이라면 사용자가 특정 팀을 골랐을 때, 해당 팀의 정보만을 필터링해서 제공해야한다. 이것 또한 검색으로 볼 수 있다.
엘라스틱서치는 이러한 검색을 빠르고 효율적으로 할 수 있게 해주는 도구이다. 위의 설명을 본 사람들은 '어..? 필터링은 RDBMS로도 충분히 할 수 있는건데 굳이 검색 엔진이 필요해?'라고 물을지도 모르겠다. 뒤에서 후술하겠지만 이것과는 비교가 안될 정도로 월등히 효율적이다.
1-2. 분산시스템은 또 뭔데?
검색 시스템이 필요할 정도의 시스템이라면 꽤나 데이터의 수도 많고 어느정도 규모가 있는 프로덕트일 것이다. 그런 제품에서 고객의 데이터를 모두 하나의 저장소에 몰아서 저장해두면 어떤 일이 벌어질까? 대충 예상 가능한 시나리오 몇개만 훑어봐도 꽤나 끔찍하다.
1) 여러 사용자들이 데이터에 접근할 때마다 bottleneck이 생겨 빠르게 데이터에 접근하지 못한다.
2) 0.1초의 차이로 저친구보다 내가 검색을 늦게했는데 결과를 받기까지는 1초 이상의 차이가 난다.
3) 데이터가 저장된 서버가 꺼지거나 부서지면 데이터가 모두 유실된다...
이러한 이유로 대용량의 데이터는 절대 한곳에 몰아서 저장해두는거 아니다. 주식 투자에서 자주 사용되는 "계란을 한바구니에 담아두지마라"를 여기서도 사용할 수 있다.
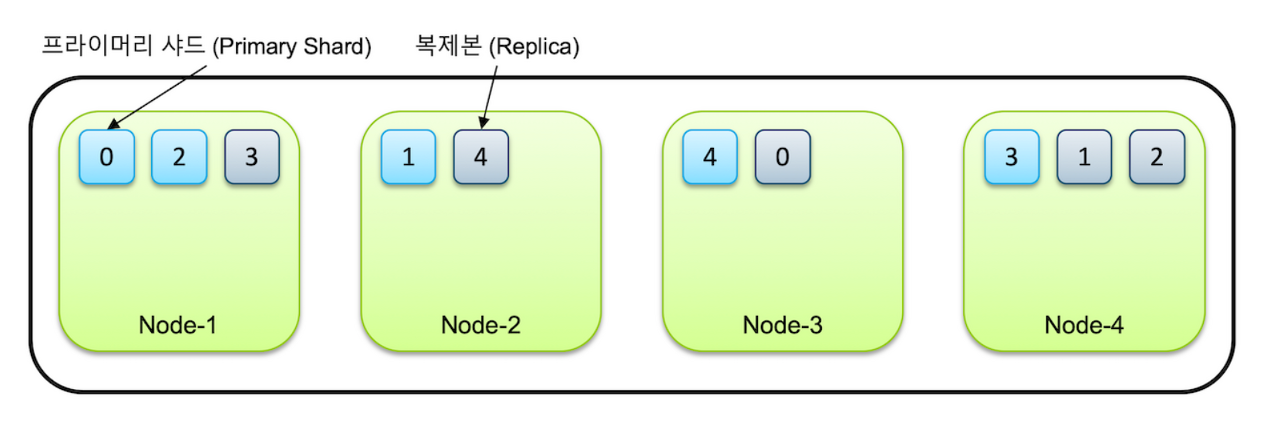
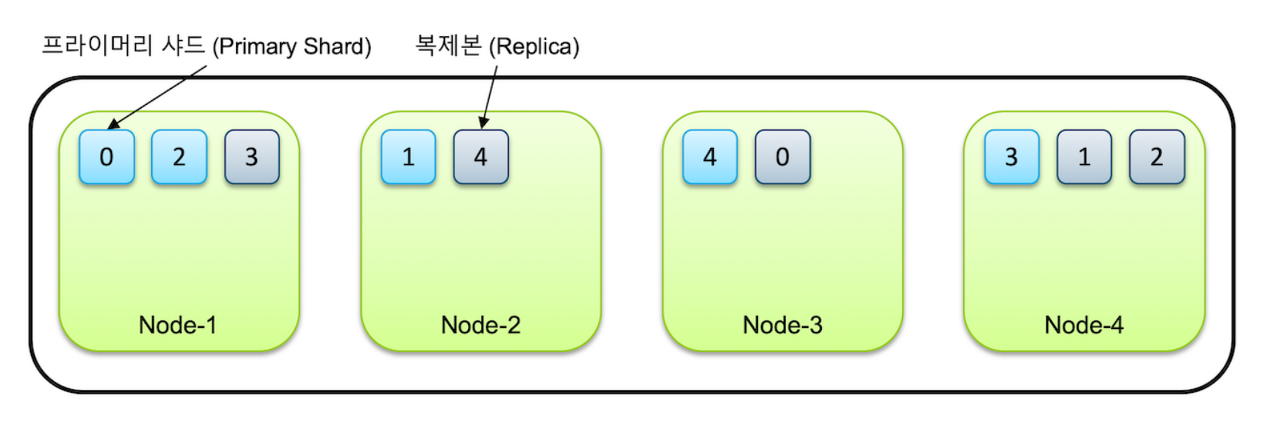
위의 그림은 엘라스틱서치가 검색용 데이터를 저장해두는 방식을 간단하게 표현한 것이다. 일단 지금은 Node를 컴퓨터, Shard(샤드)를 데이터저장소라고 생각해두자. 이에 대해서는 뒤에서 조금 더 자세히 설명하겠다. 엘라스틱서치는 여러 개의 컴퓨터에 데이터를 나눠서 저장한다. 특이한 점은 동일한 데이터의 복제본(Replica)을 만들어 다른 컴퓨터에 저장해둔다는 점이다.
0번 샤드를 예로 들면, 0번 샤드의 원본 데이터는 컴퓨터 1에 저장되어 있고 그 복제본은 3번 컴퓨터에 저장되어 있다. 이런 식으로 데이터를 분산 저장하면 어떤 장점이 있을까?
- 검색을 병렬적으로 할 수 있어 검색 속도가 빨라진다.
- 여러 사용자가 몰리더라도 각 컴퓨터(노드)에서 나눠서 처리하므로 부하가 분산된다.
- 불의의 사고로 특정 컴퓨터가 다운되더라도 데이터를 보존할 수 있다.
위에서 언급한 문제점들을 분산 시스템을 통해서 멋지게 해결했다.
이쯤에서 다시 엘라스틱서치가 뭔지 간단히 정리하고 가자.
분산시스템 기반의 검색 엔진
(여러 노드(컴퓨터)에 데이터를 안전하게 나눠 저장해두어 병렬적으로
원하는 데이터를 빠르게 취합할 수 있게 해주는 도구)
2. 엘라스틱 서치 용어 정리
| 용어 | 뜻 |
|---|---|
| Shard(샤드) | 데이터가 나눠져 저장된 엘라스틱서치의 최소 저장 단위 |
| Node(노드) | 데이터의 저장과 처리를 담당하는 서버. 특수한 상황을 제외하곤 그냥 컴퓨터 1대라고 봐도 무방함 |
| Cluster(클러스터) | 여러 노드가 모여 동작하는 하나의 엘라스틱서치 |
3. 엘라스틱서치의 데이터 저장 방식
엘라스틱서치가 무엇이고 왜 써야하는지 봤으면 이제는 엘라스틱서치가 데이터를 어떻게 저장하는지 살펴보자. 앞서 단순 필터링의 경우 RDBMS로도 가능하지만 엘라스틱서치는 이와 비교도 안될 정도로 효율적이라고 말을 했었다. 이번 챕터에서 내가 왜 그렇게 말을 했는지 설명해보겠다.
우선 들어가기전 검색엔진으로서 엘라스틱서치의 특징 두가지에 대해 빠르게 이야기하고 지나가겠다.

이 두가지를 일단 머릿속에 넣어두고 가자. 저것들이 뭔지는 설명하면서 알게될것이다.
3-1. Inverted index
다음과 같은 형태의 데이터가 들어왔다고 가정하자. RDBMS로 이 데이터를 저장하면 아래와 같이 테이블의 형태로 저장해둔다.
| Doc id | contents |
|---|---|
| 1 | The bright blue butterfly hangs on the breeze |
| 2 | Under blue sky, in bright sunlight, one need no search around |
반면 엘라스틱서치는 아래와 같이 키워드를 기준으로 해당 키워드가 어느 문서에서 나왔는지를 저장해둔다.
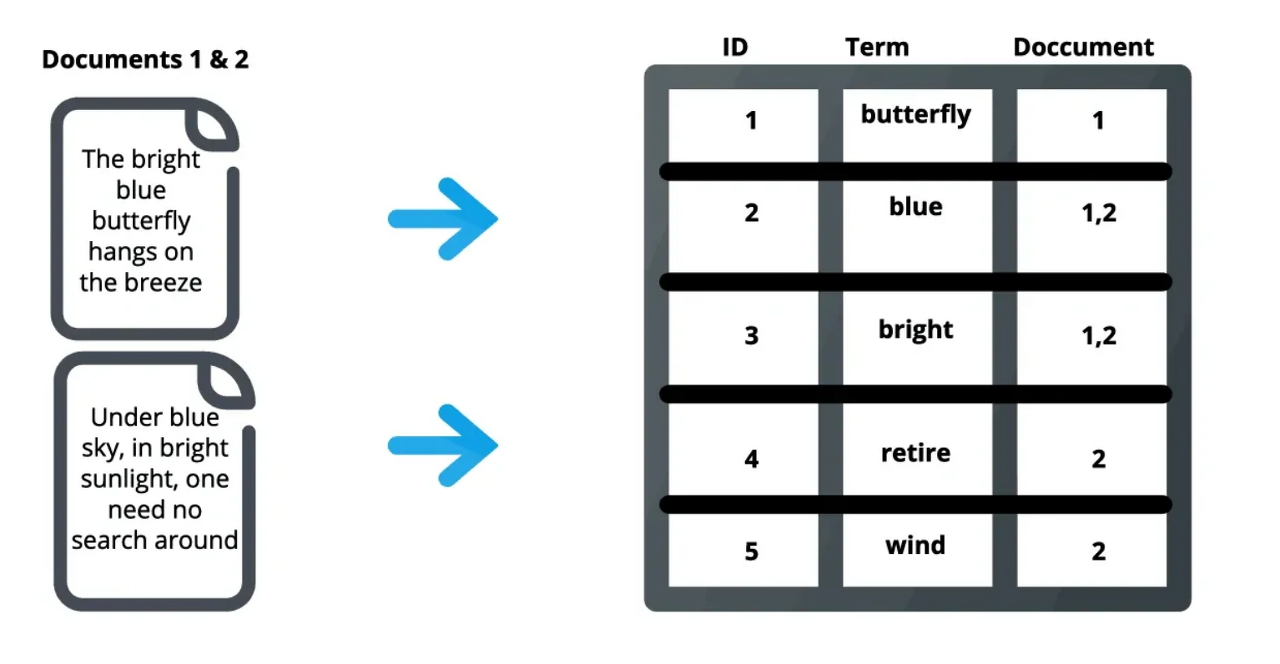
어느쪽이 검색에 더 효율적인지는 너무 자명하다. 본인이 검색엔진이라고 생각하고 위의 이미지에서 내 요청을 직접 처리해보길 바란다.
bright라는 단어가 나오는 문서가 몇번인지 알려주세요.
이 간단한 예시를 통해 왜 엘라스틱서치가 강력한 검색엔진인지 이해하게 됐을것이라 본다.
앞에서 엘라스틱서치의 검색엔진으로서의 주요 특징으로 inverted index가 있다고 했다. 흔히 index하면 책 뒤에 있는 그것을 많이 떠올린다. 특정 단어가 몇페이지에 나왔는지 정리해둔 그거말이다. index는 문서들의 집합속에서 특정 단어를 빠르게 찾기 위해 삽입되어 있다. 엘라스틱서치는 이와 반대로 특정 단어를 제시하면 그것이 포함된 문서를 빠르게 찾는 방법이다. 그렇기에 인덱싱의 반대 과정이라는 의미로 inverted index라는 이름이 붙었다.

그렇다면 엘라스틱서치는 어떤 과정을 거쳐 저런 식으로 데이터를 저장할까? 위의 그림을 통해 간단히 설명해보겠다.
"The quick and fast brown fox jumps over the dog"라는 단어가 들어오면 먼저 각 단어를 토큰화한다. 즉 하나의 문장을 잘라 단어의 집합으로 나누는 것이라고 보면된다. 그 후, 모든 단어들을 소문자로 통일시킨다. The와 the는 같은 단어인데 대소문자 차이로 인해 다른 단어로 볼 수 없기 때문이다. 그리고 불용어를 제거한다. 불용어란 의미없는 쓰레기 단어를 의미한다. 영어에서 is, a, the와 같은 단어들은 모든 문장에서 쓰이는 범용적인 단어들이다. 그렇게 큰 의미를 가지고 있지는 않지만 문장을 구성하기 위해 꼭 필요한 핵심 부품같은 느낌이다. 막말로 누가 한국어에서 "나는"이라는 단어만 단독으로 검색하겠는가? 그렇기에 저런 불용어들을 모두 제거해준다. 이때 불용어는 미리 정의된 불용어 사전을 이용하거나 사용자가 직접 몇몇 단어들을 불용어로 지정하여 제거한다.
그리고 단어들에 형태소 분석을 적용한다. 형태소 분석이란 다른 형태(품사)를 가진 단어들을 하나의 기본 단어로 통일하는 과정을 말한다. 예를 들어, 한국어에서 "먹었다", "먹고 있다", "먹었니" 이 3개 단어들은 모두 형태는 다르지만 숟가락, 젓가락을 들고 밥을 퍼서 입에 넣는 행위를 의미한다. 이런 동일한 행위를 의미하는 단어들을 모두 다른 단어로 보고 저장하는 것은 용량의 낭비일뿐만 아니라 검색하는 당사자들도 저런 식의 피말리는 타이트함은 원치 않는다. 위의 예시를 보면 jumps 라는 단어를 기본형인 jump로 변형해주었다.
마지막으로 동의어들은 통일해준다. 위의 예시에서는 quick과 fast가 동의어로 취급되어 하나로 통합되었다. 이 과정을 모두 거치고 나면 위에서 보았던 inverted index의 형태로 데이터가 저장되게 된다.
위의 과정들 중 모든 과정을 거치는 것은 아니고 도메인 영역, 사용자 정의에 따라 몇몇 과정은 생략될 수도 있다.
3-2. Full text search
Full text search는 말그대로 Full text 채로 검색할 수 있다는 의미이다. 조금 더 정확하게 말하자면 빠르게 Full text search가 가능하다. RDBMS도 느리긴 하지만 Full text search가 가능하니 말이다. 엘라스틱서치에서 Full text search가 이루어지는 방식을 보면 다음과 같다.
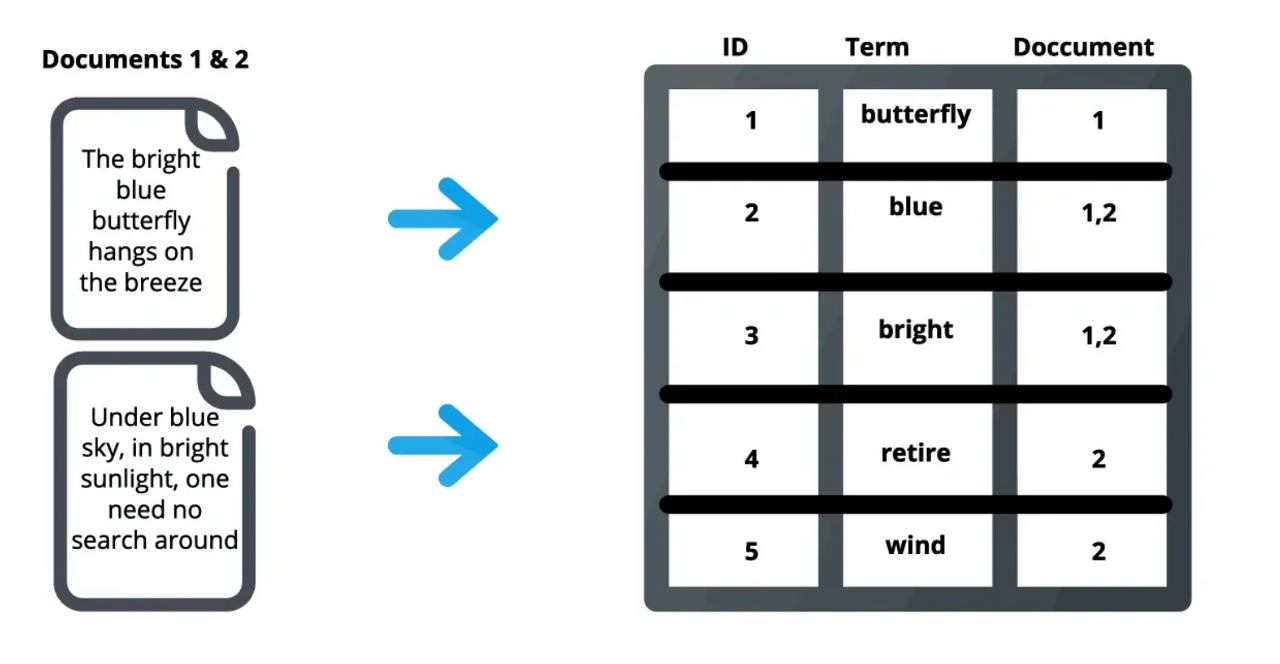
다시 위의 예시를 가지고 왔다. 이제 한 사용자가 다음의 문장을 검색한다고 가정해보자.
We need a blue sky.
지구온난화 관련 캠패인에 나올법한 문구이다. 저 단어채로 초록창에 넣으면 위에서 봤던 텍스트 처리과정을 거치게 된다. 그리고 최종적으로 "need", "blue", "sky"등의 단어를 샤드에서 찾을 것이다. 이를 통해 2번 문서를 반환하게 된다. 물론 실제 검색과정에선 유사도 점수도 함께 계산하여 반환하기 때문에 저 문서가 반환되는 일은 없을 것이다.
아무튼 결과적으로 위의 we need a blue sky라는 문장 전문을 넣어 이와 유사한 문서를 검색할 수 있다.
4. 엘라스틱서치의 데이터 검색 방식
앞서 엘라스틱서치는 분산시스템이라고 이야기했다. 그렇다면 데이터를 찾으려면 클러스터안에 있는 모든 노드(컴퓨터)들을 다 뒤져야하는 걸까? 그렇다면 너무 비효율적이다. 지금부터는 엘라스틱서치에서 사용자가 원하는 데이터를 검색하는 방법에 대해 설명해보겠다.
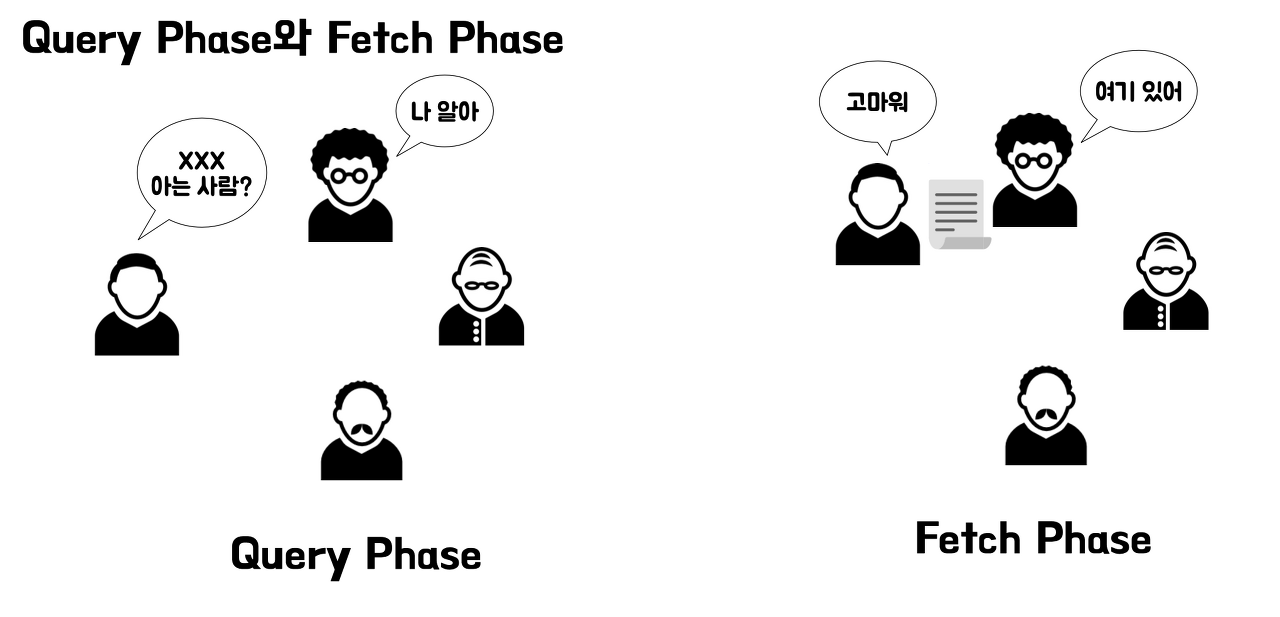
엘라스틱서치의 데이터 검색 단계는 크게 두 단계로 나뉜다. Query Phase와 Fetch Phase가 그것이다. 쿼리 페이즈는 여러 샤드 중에서 어느 샤드가 내가 원하는 데이터를 가지고 있는지 탐색하는 과정이다. 쿼리 페이즈를 통해 원하는 데이터가 어느 샤드에 있는지 파악이 완료되면 다시 해당 샤드에만 추가 요청을 보내게 된다. 그리고 이번에는 전체 데이터를 반환받게 된다. 이것이 페치 페이즈이다.
4-1. Query Phase
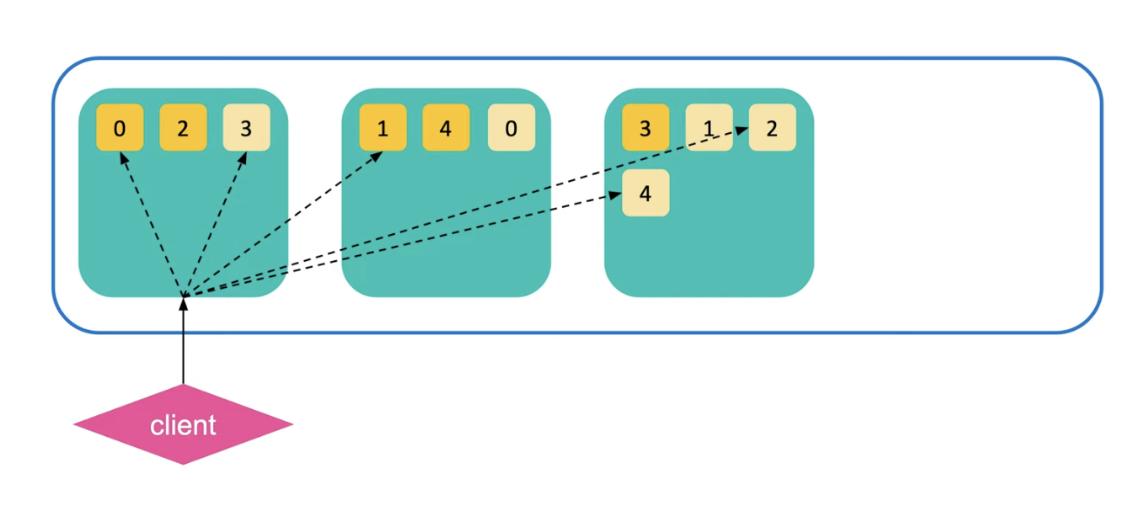
클라이언트가 특정 문장을 검색하기 위해 쿼리를 보내면 클러스터 내의 대표 노드에게 해당 쿼리가 전달된다. 위의 그림에서는 1번 노드가 대표 노드로서 클라이언트의 정보를 처리하고 있다. 하지만 반드시 1번 노드가 대표 노드가 되는건 아니고 어디까지나 랜덤이다. 여담으로 이런 대표 노드를 코디네이팅 노드(Coordinating Node)라고 부른다.
쿼리를 전달받은 대표 노드는 여러 노드들에 흩어진 샤드들에게 데이터 확인 요청을 보낸다. 위의 그림을 보면 0번부터 4번 샤드까지 모든 샤드들에게 요청이 간것을 확인할 수 있다. 그럼 요청을 받은 샤드들은 해당 데이터가 있는지 확인한 후 응답을 보낸다. 만약 데이터가 있다면 해당 데이터의 document Id와 유사도 점수를 반환한다.
유사도 점수는 다양하게 계산할 수 있으나 최근에는 TF-IDF를 사용하는 것으로 알고 있다. TF-IDF에 관해서 설명하기엔 너무 포스팅이 길어지니 각자 구글링을 통해 찾아보길 바란다. 요컨대 두 문서 사이에 겹치는 글자가 많은지 여부를 통해 유사도를 계산하는 방식이다. 다만, 경제 관련 문서라면 economy, money등과 같이 자주 사용되는 단어들로 인해 실제로는 유사한 문서가 아님에도 유사도가 높게 책정될 수 있으므로 문서들의 갯수로 나눠서 정규화를 해준 지표라고 이해하면 된다.
4-2. Fetch Phase
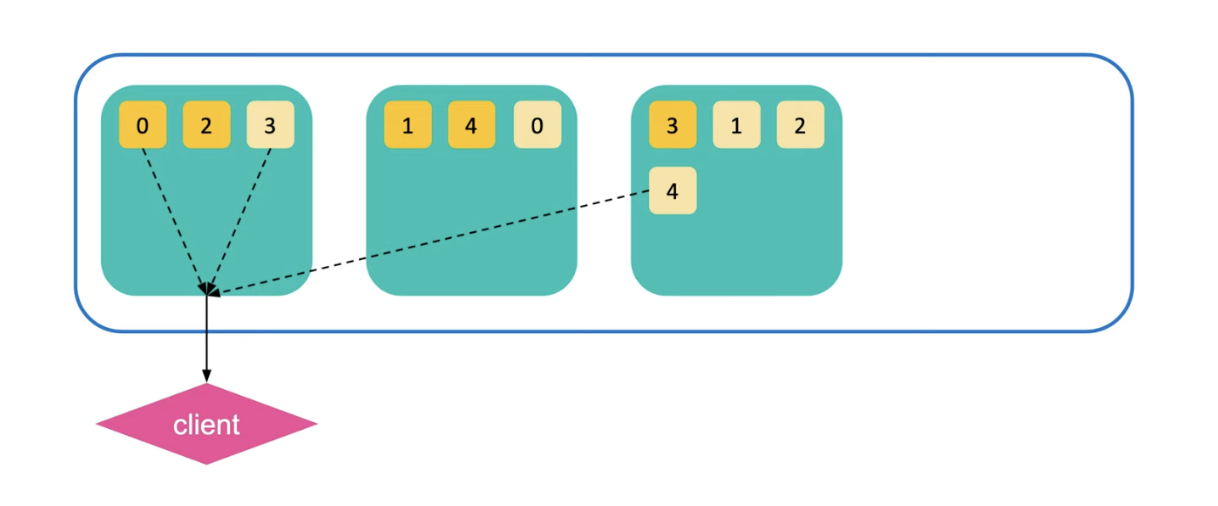
Query Phase를 통해 어느 샤드에 데이터가 있는지 파악했다면 이제는 전체 데이터를 불러오면 된다. 데이터가 있다고 응답한 샤드들에게 대표노드가 다시 요청을 보내게 된다. '아까 데이터가 있다고 했던 샤드들은 전체 데이터를 좀 보내줘' 라고 보내면 각 샤드들은 해당 문서를 반환해주게 된다. 그리고 사용자에게는 유사도를 기준으로 데이터가 정렬되어 출력된다.
5. 마치며
엘라스틱서치에 관심도 없는 데이터 사이언티스트가 급하게 공부하고 작성한 내용이라 전문성이 다소 떨어진다. 그래도 처음 엘라스틱서치에 입문하는 사람들이 복잡한 용어나 개념 때문에 혼선을 겪는 일이 없도록 최대한 쉽게 써보려고 노력했다. 처음 말했듯 단 한명의 개발자라도 이 글을 읽고 '엘라스틱서치 별거 아니네? 한번 도입해볼까?'라는 마음을 먹게 된다면 이 글은 자신의 역할을 다했다고 볼 수 있다. 혹시 그런 사람이 있다면 부디 댓글을 통해 알려주길 바란다.
6. 레퍼런스
