학습 배경
프로젝트를 하면서 DB 인스턴스가 하나 밖에 없어서 불안했었다. 혹시나 어떤 실수를 해서 DB를 날리거나 정상작동 하지 않으면 대응을 할 수 없었기 때문이다.
또 조회용 DB와 데이터 쓰기용 DB를 분리하면 성능을 개선할 수 있다는 얘기를 들어서 궁금했다. 그래서 고가용성과 성능 둘 다를 위해 DB 복제를 해보기로 헀다.
장점
한 서버에서 다른 서버로 데이터가 동기화되는 것을 복제라고 한다. 원본 데이터를 가진 서버를 소스 서버라하고, 복제된 데이터를 가지는 서버를 레플리카 서버라고 부른다.
이렇게 레플리카 서버를 가짐으로써 여러 이점들을 누릴 수 있다.
- 스케일 아웃
- 트래픽이 증가하고 DB 서버 부하가 높아질 때 스케일 업 방식보다 빠르고 유연하게 대응할 수 있다.
- 데이터 백업
- 데이터를 원본 DB에서만 보관하는 경우 위험하다. 레플리카를 통해 데이터 백업 효과도 누릴 수 있다.
이 외에도 지리적으로 멀다면 애플리케이션 서버와 DB 서버를 가깝게 위치 시킬 수 있는 등 장점이 있다.
원리
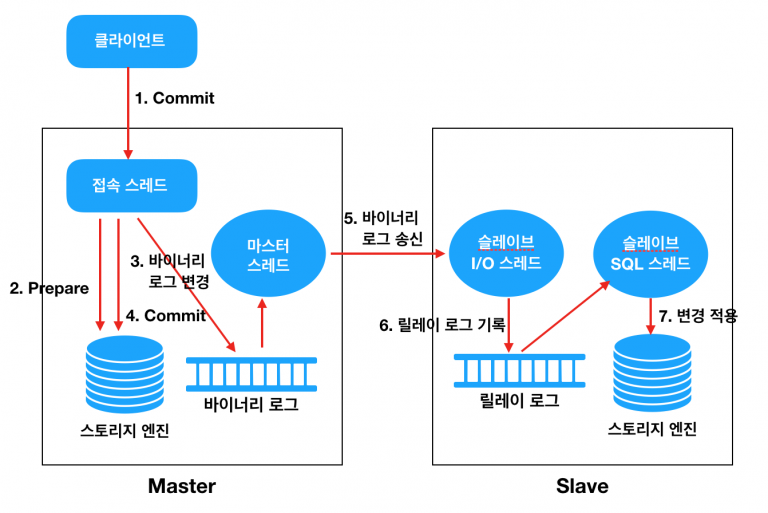
MySQL 서버에서 발생하는 모든 변경 사항이 바이너리 로그(Binary Log)로 저장된다. 소스 서버에서 바이너리 로그가 레플리카 서버로 전송되면, 레플리카 서버에서는 로컬 디스크에 따로 저장하고 데이터에 반영해서 데이터간 동기화가 이뤄진다. 이때 레플리카 서버에서 로컬 디스크에 따로 저장 해둔 파일이 릴레이 로그(Relay log)이다.
레플리카 서버에서 레플리케이션 IO 스레드와 SQL 스레드는 독립적이어서 IO 스레드는 소스 서버에서 빠르게 이벤트를 읽어오고, SQL 스레드는 느리게 적용하는 것이 가능하다.
또 소스 서버에 10개 이상의 레플리카를 붙이지 않는 이상 크게 성능이 느려지지는 않는다고 한다.
아키텍처
1. 싱글 레플리카
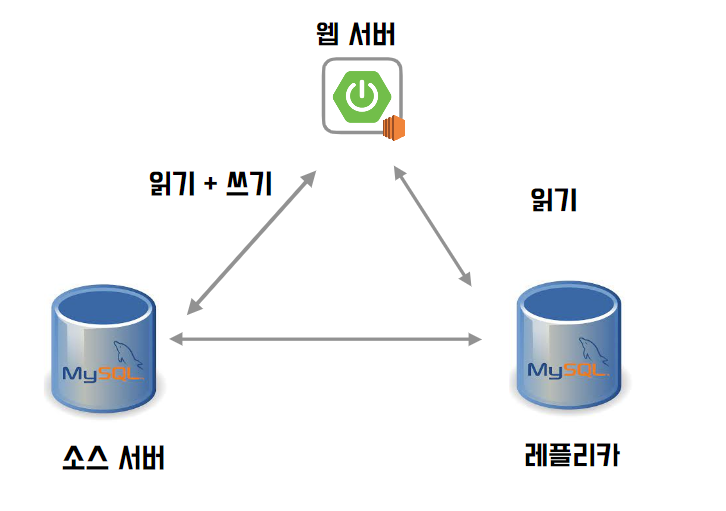
가장 기본적이고 많이 사용되는 형태라고 한다. 이때 레플리카는 평소에 사용하지 않고 장애가 발생했을 때의 백업용도이다. 만약 이런 아키텍처에서 레플리카에도 평소 서비스용 읽기 쿼리를 실행하면, 레플리카 서버에 문제가 발생하면 장애가 발생하기 때문이다.
2. 멀티 레플리카
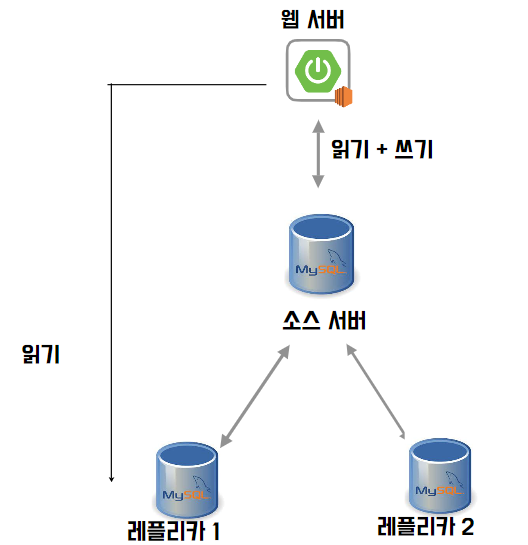
서비스가 커지고 트래픽이 증가하면 소스 서버 한대에서 쿼리 요청을 다 처리하기에 부담이 된다. 이렇게 레플리카에서 읽기 요청 처리를 분산할 수 있다. 레플리카 서버 한대는 예비용으로 남겨둬야 장애가 발생했을 때 복구할 수 있다.
프로젝트 적용
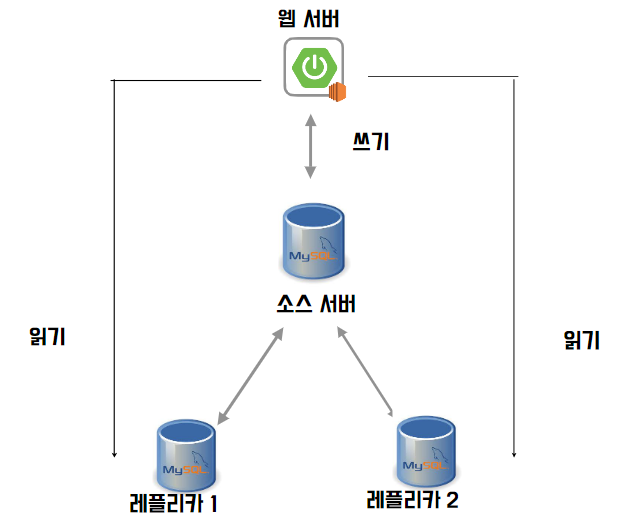
속닥속닥 프로젝트에는 이런 아키텍처로 적용을 했다. 고가용성 / 성능 둘 다 챙기고 싶었고, DB 서버 2대로 읽기를 분산하는 것이 낫다고 생각했기 때문이었다. 또 AWS를 사용하고 있기 때문에 사실 레플리카 2대 다 장애가 발생하지는 않을 것이라 생각했다. 하지만 학습을 하면서 본 것처럼 이런 구조라 할지라도 완전 예비용 레플리카 서버는 한 대를 추가로 놔둬야 조금 더 고가용성이 올라갈 것 같다.
학습 하면서 본 아키텍처에서는 소스 서버에 읽기 + 쓰기가 함께 일어나고 있었다. 완전히 쓰기와 읽기를 분리하는 것이 성능상 유리하다고 생각했는데, 쓰기는 아예 소스 서버에만 쓰고있고, 읽기는 레플리카에서만 하는 상황이라면 소스 서버와 레플리카의 싱크가 제대로 맞지 않을 때 쉽게 알아채기 어려울 수도 있을 것이라는 얘기가 나왔다.
출처
- RealMySQL 8
