이전 글에서 Replication 원리와 아키텍처에 관해 다뤘다. 이제 실제 어떻게 진행했는지 정리한다.
복제 타입
바이너리 로그 파일 위치 기반 복제
레플리카 서버에서 소스 서버의 바이너리 로그 파일명과 파일 내에서의 위치(Offset 또는 Position)로 개별 바이너리 로그 이벤트를 식별해서 복제가 진행되는 형태를 말한다.
바이너리 로그 파일 위치 기반 복제에서는 이벤트 하나하나를 소스 서버의 바이너리 로그 파일명과 파일 내에서의 위치 값(File Offset)의 조합으로 식별한다. 바이너리 로그 파일 위치 기반 복제에서는 모든 MySQL 서버들이 고유한 server-id 값을 가지고 있어야 한다.
바이너리 로그의 위치는 실제 파일의 바이트 수를 의미하는 값으로, 그냥 위치값이라 생각하면 된다.
글로벌 트랜잭션 아이디(GTID) 기반 복제
바이너리 로그 파일 위치 기반 복제는 문제가 있다 동일한 이벤트가 레플리카 서버에서도 동일한 파일명의 동일한 위치에 저장된다는 보장이 없다. 복제에 투입된 서버들마다 동일한 이벤트에 대해 서로 다른 식별 값을 가질 수 있는 것이다.
소스 서버에 발생한 이벤트들이 복제한 참여한 모든 MySQL 서버에서 동일한 고유 식별값을 가지면 더 편할 것이다.
데이터 덤프
소스 서버에서
sudo mysqldump -uroot --single-transaction --master-data --databases sokdak > source_data.sqlmysqldump로 데이터를 덤프할 때는 --single-transaction과 --master-data라는 두 옵션을 반드시 사용해야 한다.
--single-transaction은 데이터를 덤프할 때 하나의 트랜잭션을 사용해 테이블이나 레코드에 잠금을 걸지 않고 일관된 데이터를 덤프받을 수 있게 한다.
--master-data 옵션은 덤프 시작 시점의 소스 서버의 바이너리 로그 파일명과 위치 정보를 포함하는 복제 설정 구문이 덤프 파일 헤더에 기록될 수 있게 하는 옵션이다.
이제 소스서버에서 scp를 이용해서 레플리카 서버로 source_data.sql 파일을 보내주면 된다.
레플리카 서버에서
mysql -u root -p sokdak < source_data.sql위 구문을 실행하면 소스 서버와 똑같은 데이터베이스가 레플리카 서버에서도 생성되는 것을 확인할 수 있다.
처음에는 EC2 이미지를 복사하고 인스터스를 생성했으므로 데이터가 똑같을 것이라 생각했다. 그리고 우리가 눈으로 비교했을 때 데이터가 변경된 점이 없어 보여서 데이터 덤프를 뜨지 않고 Replication 구성을 했다. 하지만 이게 문제가 되어서 나중에는 싱크가 맞지 않았다. 지금 추측해보자면 운영 DB 였으니 충분히 그 사이에 데이터가 변경되었을 수도 있을 것 같다.
심지어 나중에는 레플리카1에서 읽어오는 데이터와 레플리카2에서 읽어오는 데이터가 너무 차이났다. 새로 고침을 했을 때 어떤 게시글이 보이다가 또 안보이기도 했던 것이다. 이게 라운드 로빈 방식으로 레플리카 1과 레플리카2에서 읽어오는데 데이터가 일치하지 않은 상태에서 Replication을 해서 발생한 문제였다.
결국 나중에는 운영 서비스를 잠시 정지시키고 데이터 덤프를 떠서 정합성을 맞추고 Replciation을 했다. 비록 이번에야 사이드 프로젝트여서 다행이었지만, 실제 운영 중인 서비스는 이럴 때 어떻게 데이터 덤프를 뜨는지 궁금했다.
Replication
Master
sudo vim /etc/mysql/mysql.conf.d/mysqld/cnf여기 들어와서 [mysqld] 아래 섹션을 수정하면된다.
[mysqld]
server-id = 1
log-bin = /var/log/mysql/mysql-bin.log
tmpdir = /tmp
binlog_format = ROW
max_binlog_size = 500M
sync_binlog = 1
expire-logs-days = 7
slow_query_log여기서 server-id는 각각 다르게 줘야한다.
sudo service mysql restart이제 replication용 계정을 생성하자.
select user, host from mysql.user;
CREATE USER {아이디}@'%' IDENTIFIED WITH mysql_native_password BY '{비밀번호}';
grant replication slave on *.* to {아이디}@'%';
flush privileges;
show grants for replica_user@'%';여기서는
%를 줬다. 모든 ip에 대해 허용한다는 뜻인데 보안을 더 신경쓰려면 ip를 특정해주는게 좋다.
Slave
find / -name "auto.conf"
find /var/lib/mysql -name "auto.cnf"
rm -rf /var/lib/mysql/auto.cnfEC2 이미지를 떠서 인스턴스를 생성했다. 그래서 DB 마다 고유한 uuid 까지 다 복사됐다. 이 파일을 지우고 다시 시작하면 고유한 UUID를 다시 갖게된다.
auto.cnf 파일이 자동으로 생성된다고 하더라도 UUID 값은 복제가 설정된 소스 서버와 레플리카 서버의 GTID 값에 사용되고 있는 값이므로, 아래에 나오는 GTID 방식을 사용하려면 중간에 삭제되지 않도록 주의해야 한다.
$ sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
log_bin = /var/log/mysql/mysql-bin.log
server-id = 2
read_only = 1
tmpdir = /tmp
binlog_format = ROW
max_binlog_size = 500M
sync_binlog = 1
expire-logs-days = 7
slow_query_log = 1server-id를 2로 줬다.
sudo service mysql restart;master
show master status\G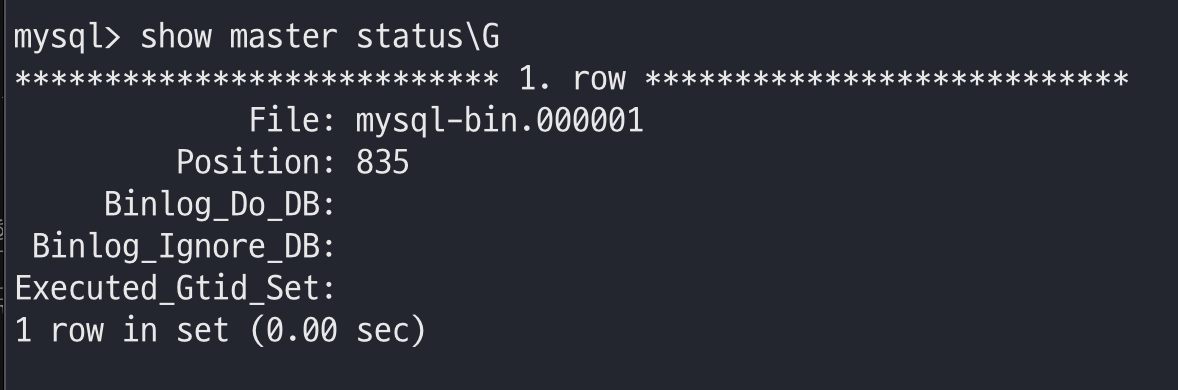
slave
reset slave;
CHANGE MASTER TO MASTER_HOST='{Master Private id}',
-> MASTER_USER='{마스터 DB에서 생성한 아이디}',
-> MASTER_PASSWORD='{마스터 DB에서 설정한 비밀번호}',
-> MASTER_LOG_FILE='mysql-bin.000002',
-> MASTER_LOG_POS=155;
start slave;
show slave status\g
show slave status\g명렁어를 치면 어떻게 연결이 되었는지 나온다. 소스서버의 바이너리 로그 파일, position과 같은 값이 나오면 제대로 연결된 것이다.
Spring
- DB단에서 Replication을 해줬으니 자바 코드단에서도 변경을 해줘야 한다.
@Transactional(readOnly = true)라면 레플리카 서버에서 조회를 해야 하는 것이다.
자바 코드 단의 설정은 루키 블로그에 되게 쉽게 정리가 되어 있어서 도움을 많이 받았다.
확인
show variable like 'general_log%';
set global general_log = on;이렇게 하고 로그가 찍히는걸 확인하면 조회할때 slave들에서 조회 쿼리들이 처리되는 것을 확인할 수 있다.
참고로 이 옵션을 키니 서비스가 확 느려졌다. 모든 쿼리들을 다 로그로 남긴다면 저장공간에 대한 부담도 클 것이다. 확인 목적으로 사용하고 바로 끄도록 하자.
기타
-
DB를 이중화함으로서 고려해야할 것들이 확 늘었다.
-
만약 소스 서버에 문제가 생긴다면 레플리카 서버 중 한 대가 마스터 서버가 되어야 한다. 이렇게 레플리카 서버에서 소스 서버로 승격되는 것을 장애가 발생하고나서 대응하기 시작하면 늦을 것이다. 장애가 났을 때 바로 대응할 수 있게 스크립트를 작성하는 것도 한 방식일 것 같다.
