학습 배경
현재 속닥속닥 프로젝트에는 무한 스크롤이 구현되어 있다. 일정 크기의 페이지만큼 게시글 목록을 배열로 주고, 사용자가 스크롤을 내려서 그 글을 다보면 프론트에서 다음 페이징에 대한 요청을 날린다.
MySQL에서 페이징 쿼리를 작성할 때 항상 limit과 offset 계산을 하는 것이 헷갈렸다. 그걸 프로젝트에서 JPA를 쓰면서 Slice와 Page로 쉽게 처리할 수 있게 되었다. 하지만 보편적으로 사용하는 방식은 문제가 있을 수도 있다는 것을 알게 되었다. 그래서 처음부터 차근차근 정리를 해본다. 이 글에서는 간단하게 limit, offset, slice, page에 대해 다루고 다음 글에서 문제점에 대해 정리한다.
MySQL
limit, offset
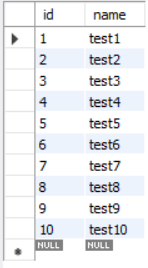
select * from test limit 3 offset 2;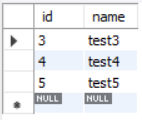
결과를 보면 알 수 있지만 offset은 데이터의 처음부터 몇 개를 건너뛸거냐를 설정하는 값이고, limit은 데이터를 몇 개 가져올 것인지 설정하는 값이다. offset은 2, limit은 3이므로 처음 데이터 2개를 건너뛰고 3개를 가져와서 3, 4, 5를 가져오는 것이다.
일반화하면 SELECT * FROM 테이블명 ORDERS LIMIT 숫자(A) OFFSET 숫자(B) 이 쿼리는 B+1행부터 A행 개수만큼을 출력한다.
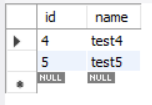
select * from test limit 3, 2;이렇게 limit 뒤에 숫자 2개를 적으면 앞의 것이 offset, 뒤의 것이 limit 역할을 한다.
이 쿼리를 작성해서 사용하려면 복잡한 것들이 생긴다. 프론트 개발자 입장에서 무한 스크롤을 구현할 때, 다음 페이지가 있는지 없는지 알아야한다. 마지막 페이지면 더 이상 요청을 안날려야하기 때문이다. 그럼 그 마지막 페이지도 개수가 딱 맞게 찰 수도 있고, 부족할 수도 있다. 이런 경우의 수들은 놓치기도 쉽다.
그래서 JPA에서 쉽게 페이징을 할 수 있도록 만들어 놨다.
JPA
Pageable
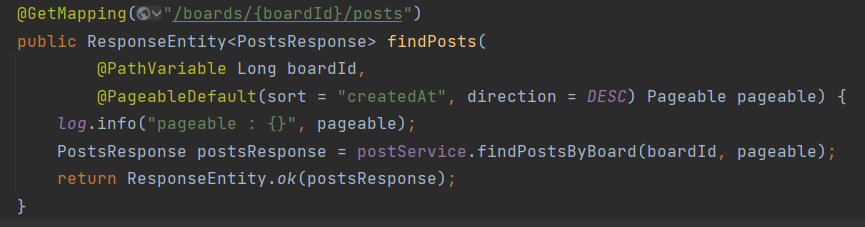
위처럼 컨트롤러에 Pageable을 선언해놓으면 요청을 받아서 알아서 Pageable로 받아준다. 그리고 이걸 그래도 사용하면된다. 심지어 정렬 기준도 선택해서 넣어줄 수 있다.


리포지토리에서도 이런식으로 그냥 Pageable을 받으면 알아서 쿼리를 날려준다.
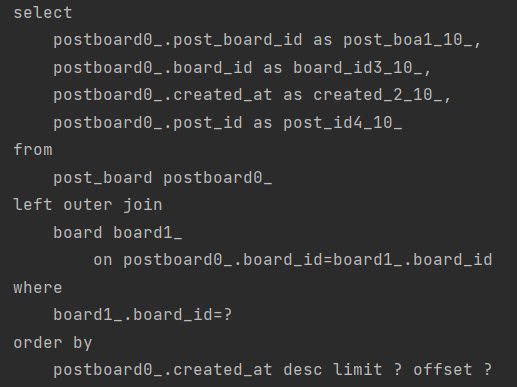
실제 쿼리로그를 봐도 잘 날라간걸 볼 수 있다.
그리고 그 결과 값을 Slice, Pageable로 반환할 수 있다.
Slice
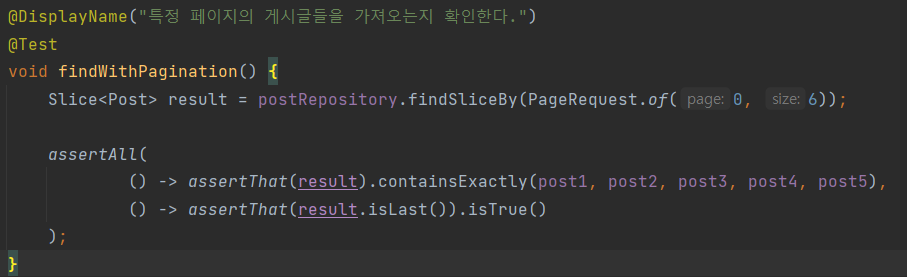
Pageble은 인터페이스느 테스트 코드에서 사용할 때는 인터페이스를 구현한
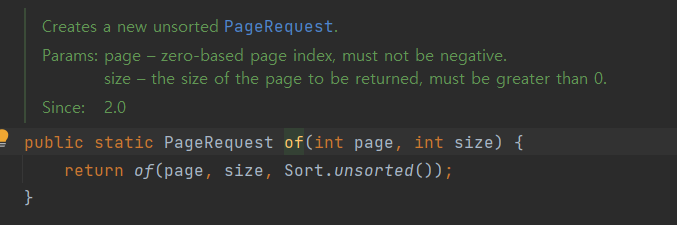
PageRequest객체를 사용하면 된다.
첫 번째 파라미터에는 현재 페이지를, 두번째 파라미터에는 조회할 데이터 수를 넣으면 된다.
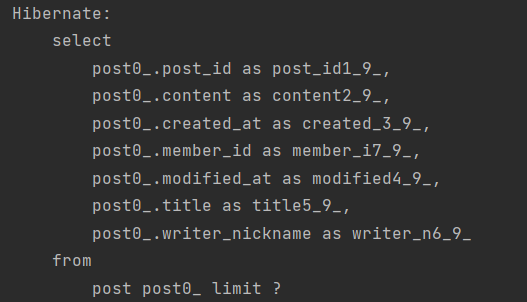
이렇게 Slice로 데이터를 조회하면
public interface Slice<T> extends Streamable<T> {
int getNumber(); //현재 페이지
int getSize(); //페이지 크기
int getNumberOfElements(); //현재 페이지에 나올 데이터 수
List<T> getContent(); //조회된 데이터
boolean hasContent(); //조회된 데이터 존재 여부
Sort getSort(); //정렬 정보
boolean isFirst(); //현재 페이지가 첫 페이지 인지 여부
boolean isLast(); //현재 페이지가 마지막 페이지 인지 여부
boolean hasNext(); //다음 페이지 여부
boolean hasPrevious(); //이전 페이지 여부
Pageable getPageable(); //페이지 요청 정보
Pageable nextPageable(); //다음 페이지 객체
Pageable previousPageable();//이전 페이지 객체
<U> Slice<U> map(Function<? super T, ? extends U> converter); //변환기
}와 같이 데이터의 많은 페이징 정보를 사용할 수 있다.
Page
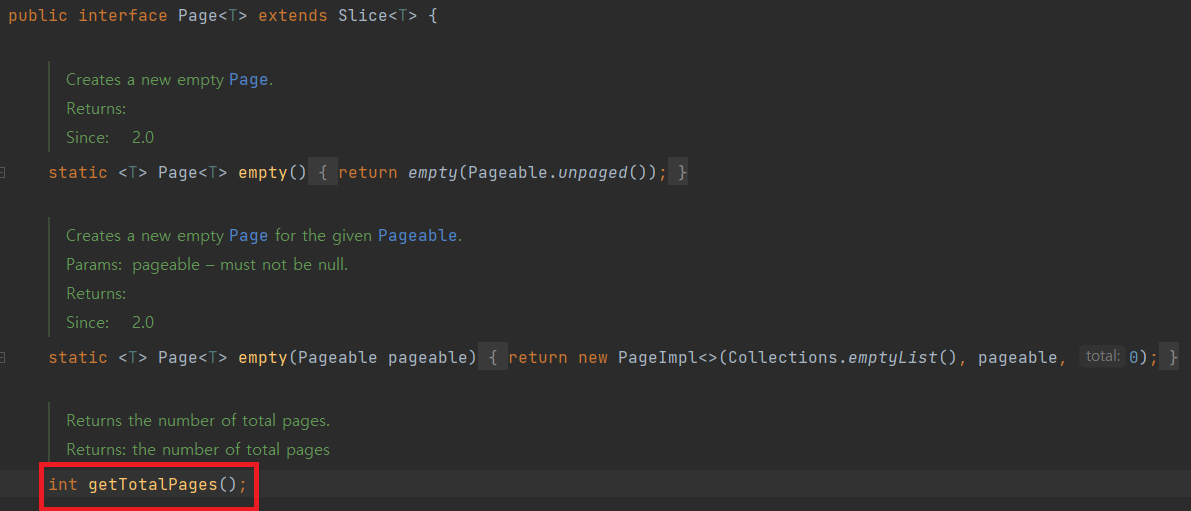
page는 slice를 상속해서 몇몇 기능들을 더 제공한다. 그 중 하나가 전체 데이터 개수를 알려주는 것이다. 이 전체 개수를 알기 위해서 실제로 쿼리가 별도로 한번 더 나간다.
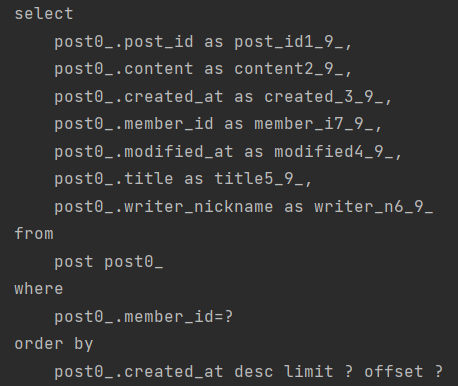
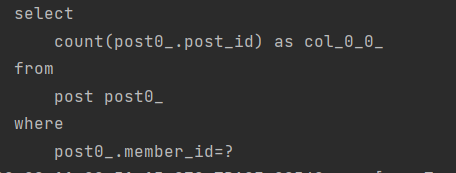
쿼리가 별도로 한번 더 나가는 것을 알 수 있다. 그래서 totalCount가 필요 없으면 slice를 쓰는 것이 성능상 더 좋다.
문제점
지금 방식은 매우 편리하다. 하지만 데이터가 많아지면 큰 문제가 있다.
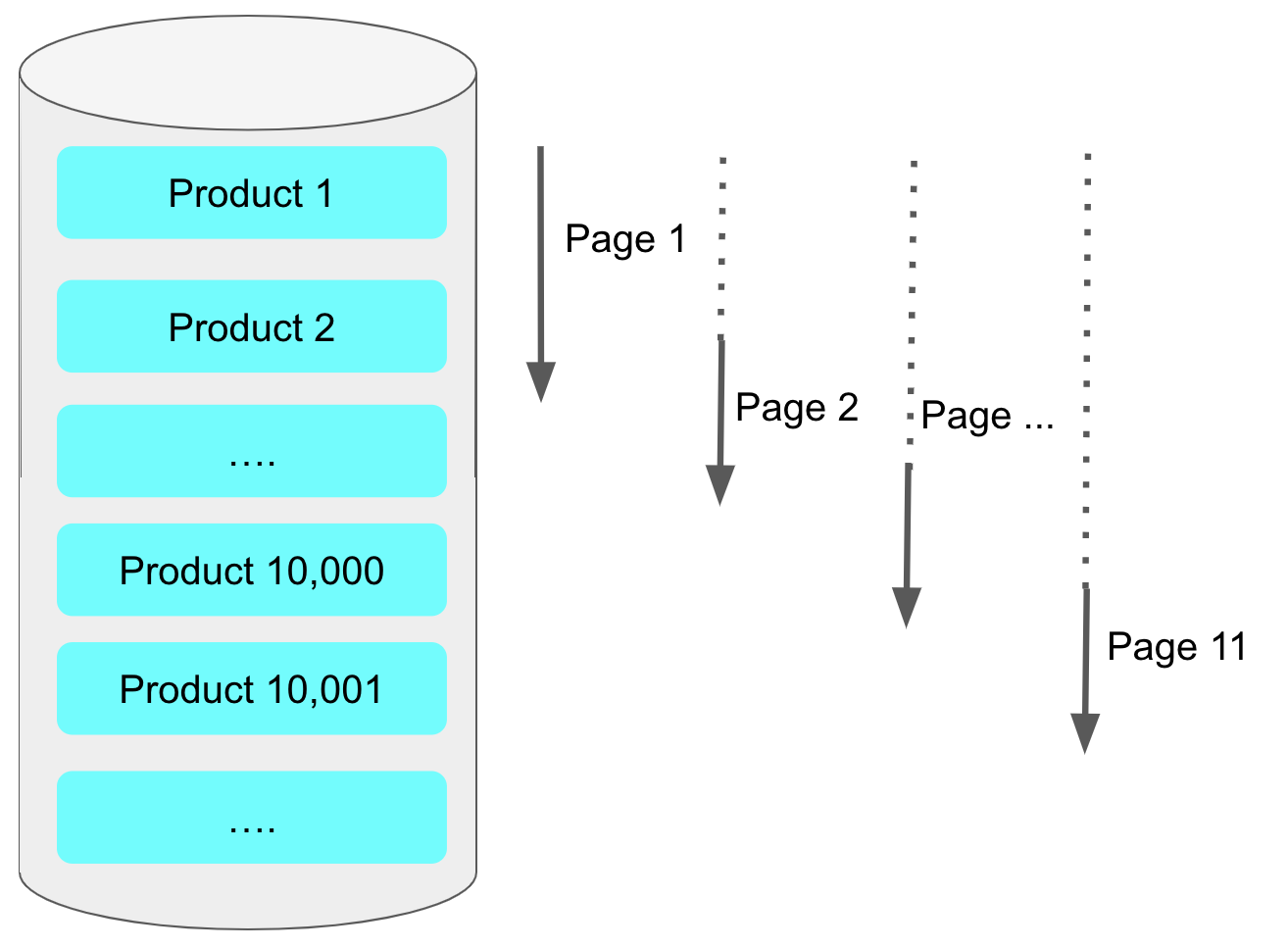
MySQL의 OFFSET은 데이터를 다 읽어와서 필요한 부분만 잘라내는 방식이다. offset 1000000, limit 20이라 하면 1,000,020개를 row들을 다 읽어와서 1,000,000개를 버리는 것이다.
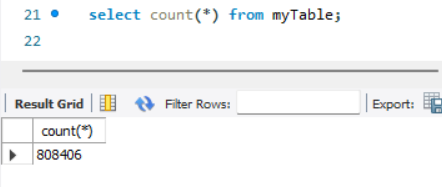
대략 800,000개의 데이터를 만들어 두고 실험을 해봤다.

초반의 데이터를 가져오는데는 시간이 거의 걸리지 않는다.

대략 가운데 있는 데이터를 가져오려고 하니 이정도 시간이 걸렸다.

제일 끝에 있는 데이터를 가져오려고 하니 거의 두배가 걸렸다. 이건 80만건의 데이터밖에 되지 않았는데, 데이터 수가 많았다면 훨씬 시간이 많이 걸렸을 것이다.
그래서 서비스가 커지고 DB에 데이터가 많아졌을 때는 페이징을 어떻게 하면 좋을지 다음 글에 써볼거다.
