요약
1. 데이터가 많아서 테이블을 분리해야하는 상황에서 최소한의 방법으로 해결
2. PostgreSQL이 제공하는 Table Partitioning 기능만으로 비즈니스 코드에서 분리 로직 제거
서론
기존 사내 레거시 시스템들은 데이터가 많아지는 것을 대비해 테이블 자체를 네이밍으로 분리(user_1, user_2 …) 하는 방식으로 운영하고 있었다.
당연히 비즈니스 로직에서는 "이 데이터가 어느 파티션에 들어가야 하는지"를 판단하는 코드가 반복적으로 들어갔고, Repository 계층에서도 파티션 번호를 직접 관리해야 했다.
그렇게 관리를 하다보니, 아래와 같은 문제가 발생했다.
- ORM 활용에 어려움 존재
- 파티션 로직이 비즈니스 코드에 침투
- 유지보수 난이도 상승
이 역할을 DB 레이어로 완전히 분리할 수 없을까 고민하다가 PostgreSQL Table Partitioning 기능을 알게 됐고, 이를 실제로 적용해 본 경험을 공유하려 한다.
PostgreSQL Table Partitioning
PostgreSQL은 10버전 이후로 Native Partitioning을 공식 지원한다.
기본 개념은 아래와 같이 단순하다.
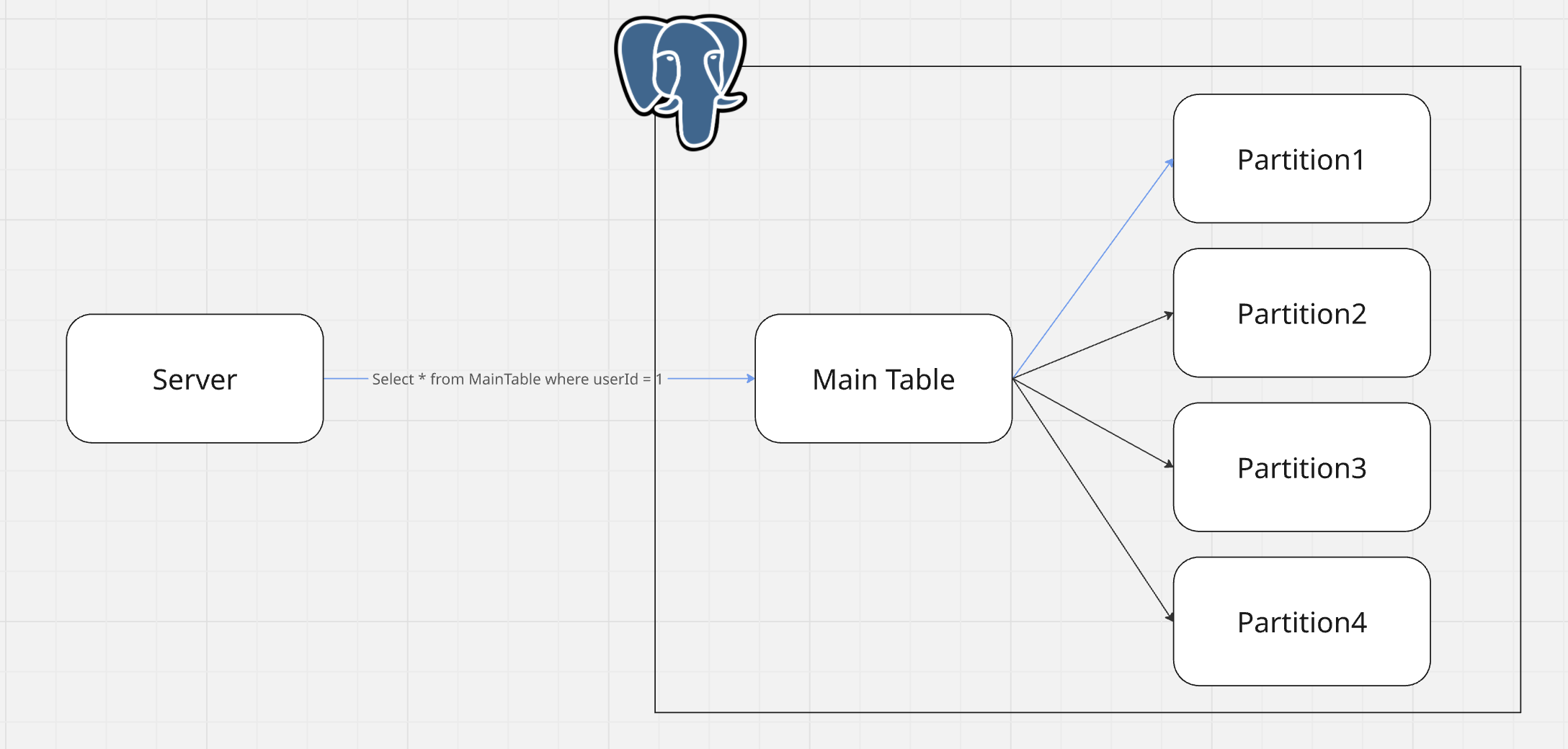
Server에서는 MainTable에 Query하면 Postgres가 내부적으로 파티션을 찾아서 수행해준다.
실제로 Explain으로 확인을 해도 Partition1에만 Select을 수행하는 것을 확인할 수 있다.
다만 Postgres에서 판별할 수 있도록, Table에 설정을 추가해야한다.
아래는 Partition Table을 설정하기 위한 쿼리이다.
# Main Table
CREATE TABLE users (
id BIGSERIAL,
username TEXT,
created_at DATE NOT NULL
) PARTITION BY RANGE (created_at);
# Partition1
CREATE TABLE users_2024 PARTITION OF users
FOR VALUES FROM ('2024-01-01') TO ('2025-01-01');
# Partition2
CREATE TABLE users_2025 PARTITION OF users
FOR VALUES FROM ('2025-01-01') TO ('2026-01-01');위와 같이 RANGE를 기반으로 범위를 지정하고, 해당하는 범위의 Partition Table을 추가하면 자동으로 연결이 된다.
이후 쿼리에서 where절에 created_at을 적절하게 걸어주면 해당하는 테이블만 스캔하게 된다. (Select/Insert/Update/Delete 모두 동일하게 동작)
다만 where절에 Partition에 해당하는 적절한 조건이 없으면 모든 파티션에 대해서 스캔을 수행하게 된다.
Partition 종류
Range Partition
-- Main Table
CREATE TABLE orders (
id BIGSERIAL PRIMARY KEY,
user_id BIGINT,
amount NUMERIC,
created_at DATE NOT NULL
) PARTITION BY RANGE (created_at);
-- 2024년 1월 파티션
CREATE TABLE orders_202401 PARTITION OF orders
FOR VALUES FROM ('2024-01-01') TO ('2024-02-01');
-- 2024년 2월 파티션
CREATE TABLE orders_202402 PARTITION OF orders
FOR VALUES FROM ('2024-02-01') TO ('2024-03-01');- 날짜 기반 로그 테이블, 사용자 가입일 기준 파티션 등에 매우 유용하다.
- 시간 기반으로 자동 스캔 범위가 줄어들어 쿼리 성능 향상된다.
- 운영 중 range 구간을 늘리거나 줄이기도 쉽다.
- 만약 구간이 겹치면 오류가 발생하니 주의해야한다.
Hash Partition
-- Main Table
CREATE TABLE user_actions (
id BIGSERIAL PRIMARY KEY,
user_id BIGINT NOT NULL,
action TEXT,
created_at TIMESTAMP NOT NULL
) PARTITION BY HASH (user_id);
-- 파티션 0
CREATE TABLE user_actions_p0 PARTITION OF user_actions
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
-- 파티션 1
CREATE TABLE user_actions_p1 PARTITION OF user_actions
FOR VALUES WITH (MODULUS 4, REMAINDER 1);
-- 파티션 2
CREATE TABLE user_actions_p2 PARTITION OF user_actions
FOR VALUES WITH (MODULUS 4, REMAINDER 2);
-- 파티션 3
CREATE TABLE user_actions_p3 PARTITION OF user_actions
FOR VALUES WITH (MODULUS 4, REMAINDER 3);- 균등 분포가 중요한 테이블에 적합하다.
- Range처럼 특정 기간만 스캔하는 최적화는 없지만 특정 user_id에 대한 데이터 집중을 피할 수 있다.
- 파티션 개수를 바꾸기 어렵기 때문에 설계 단계에서 고정 필요하다.
List Partition
-- Main Table
CREATE TABLE products (
id BIGSERIAL PRIMARY KEY,
name TEXT,
country_code TEXT NOT NULL
) PARTITION BY LIST (country_code);
-- 한국
CREATE TABLE products_kr PARTITION OF products
FOR VALUES IN ('KR');
-- 미국
CREATE TABLE products_us PARTITION OF products
FOR VALUES IN ('US');
-- 일본
CREATE TABLE products_jp PARTITION OF products
FOR VALUES IN ('JP');
-- 기타 국가
CREATE TABLE products_default PARTITION OF products DEFAULT;- 값 종류가 한정되어 있고 범위 기반이 아니어도 될 때 적합하다
- 예: 국가, 카테고리, 상태(status) 등
- Range와 달리 "특정 값 매칭" 기반으로 판단된다.
결론
✔ 장점
- 서버 코드 단계에서는 데이터 파티션에 대한 코드가 없다.
- 다른 Schema에 파티션을 둘 수 있어서 관리가 용이하다.
- 다양한 옵션을 기반으로 처리할 수 있다.
- 내부에서 데이터 분석용이나 운영툴에서 활용하기 용이하다.
✘ 단점
- PrimaryKey에 대한 제약에 대한 고민을 추가로 해야한다.
- Hash Partition을 사용할 경우, 기준이 되는 키는 반드시 Primary가 되야 한다.
- Full Scan시, 모든 파티션 테이블을 Scan하기 때문에 더 신경써야 한다.
→ 하지만 이는 구조적으로 당연한 부분이라, 쿼리 설계만 신경 쓰면 크게 문제되진 않았다.
