데이터베이스에서 내가 원하는 데이터가 이 디스크에 있는지 어떻게 판단할 수 있을까?
예를 들어 HBase나 데이터를 HFile에, Cassandra는 SSTable에 저장한다. HFile과 SSTable 모두 정렬된 형태로 데이터를 저장한다. 조회 쿼리를 수행할 때 해당 키에 대한 데이터가 없는 HFile / SSTable을 스캔하는 것은 성능이 크게 저하될 것이다.
그러면 파일 혹은 테이블, 저장소에 내가 원하는 데이터가 있는지 미리 알 수 있는 방법이 있을까?
블룸 필터를 사용해서 해당 저장소에 데이터가 있는지 효율적으로 확인할 수 있다.
Bloom Filter란?
Bloom Filter는 데이터를 직접 저장해두는 자료구조가 아니다. 데이터가 집합에 포함되어 있는지 여부만 판단할 수 있다.
Bloom Filter는 공간 효율적이다. 해시 테이블 기능이 필요하지만 공간이 넉넉하지 않은 상황에서 Bloom Filter가 효과를 발휘할 수 있다. 해시 테이블과 유사한 방식으로 삽입과 조회를 할 수 있지만, Key 자체를 저장하는 게 아닌 Bit Array를 사용하여 데이터를 저장하기에 매우 적은 공간만을 사용한다.
그래서 Bloom Filter를 RAM에 배치하여 데이터를 조회할 때 디스크를 바로 조회하는 것이 아니라 Bloom Filter에 먼저 "이 데이터가 이 Set에 존재하니?" 여부(Membership Query)를 먼저 물어볼 수 있다. Bloom Filter를 사용하면 해당 데이터가 이 Set에 없음 or 해당 데이터가 이 Set에 있을 수도 있음 중 하나를 알려준다.
그러면 이제 Bloom Filter의 작동 방식에 대해 알아보자.
Bloom Filter의 작동 방식
Bloom Filter에는 두 가지 주요 구성 요소가 있다.
1. 모든 슬롯이 0으로 설정된 비트 배열
2. k개의 독립적인 해시 함수
삽입
Bloom Filter에 항목 x를 삽입하려면 x에서 k개의 해시 함수를 계산하고 각 결과에 대해 해당 슬롯을 1로 설정한다.
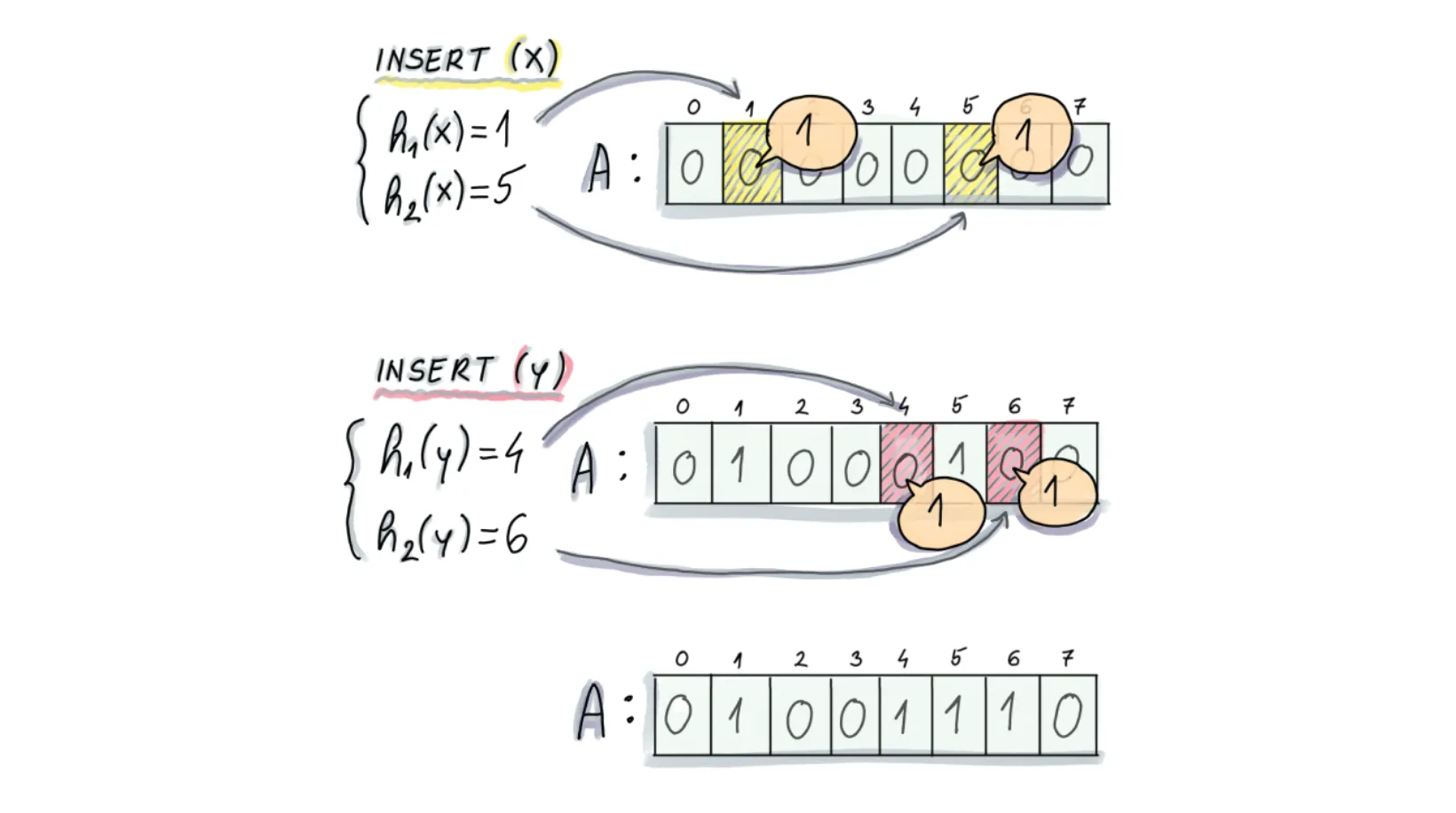
x를 삽입할 때:
1. 첫 번째 해시 함수에 대해 x의 결과가 1이라면, 비트 배열에서 1번째 인덱스를 1로 업데이트한다.
2. 두 번째 해시 함수에 대해 x의 결과가 5라면, 비트 배열에서 5번째 인덱스를 1로 업데이트한다.
y를 삽입할 때:
1. 첫 번째 해시 함수에 대해 y의 결과가 4이라면, 비트 배열에서 4번째 인덱스를 1로 업데이트한다.
2. 두 번째 해시 함수에 대해 y의 결과가 6이라면, 비트 배열에서 6번째 인덱스를 1로 업데이트한다.
조회
삽입과 마찬가지로 x에서 k개의 해시 함수를 계산하고 슬롯 중 하나가 처음으로 0일 때 항목을 존재하지 않음로 보고한다. 그렇지 않으면 존재함으로 보고한다.
x를 조회할 때:
1. 두 개의 해시 함수에 대해 x의 결과가 1, 5라면, 비트 배열에서 1, 5번째 인덱스가 모두 1인지 검사한다. 모두 1이므로 존재함으로 보고한다.
z를 조회할 때:
2. 두 개의 해시 함수에 대해 z의 결과가 3, 6이라면, 비트 배열에서 3, 6번째 인덱스가 모두 1인지 검사한다. 3번째 인덱스가 0이라면 존재하지 않음으로 보고한다.
체험이 필요하다면 아래 사이트에서 직접 Bloom Filter에 삽입하는 과정을 거쳐보면서 어떤 자료구조인지 눈으로 확인할 수 있다.
False Positive
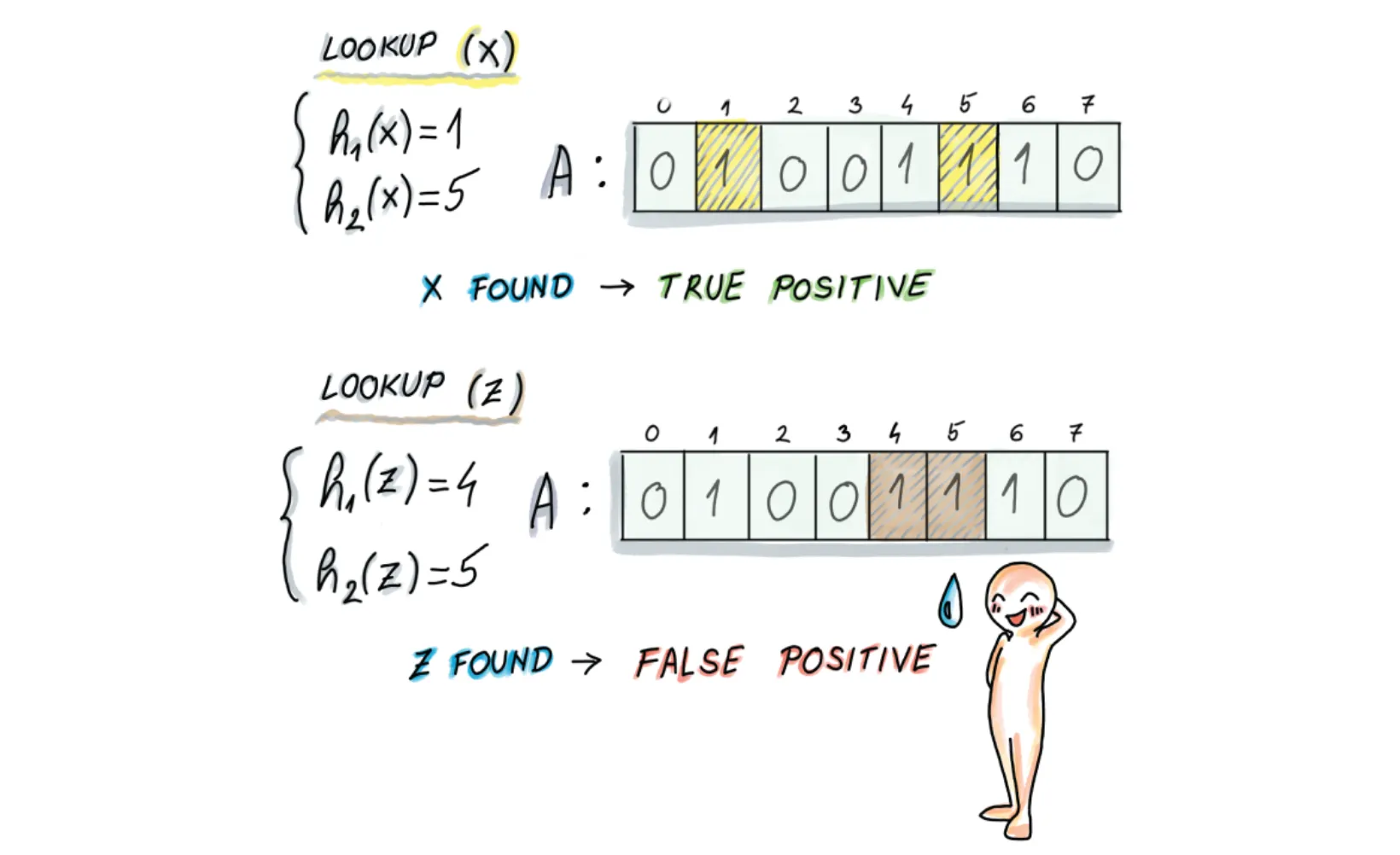
위 그림은 Bloom Filter가 어떻게 False Positive를 보고할 수 있는지 알려준다. z는 실제로 삽입된 적 없는 데이터지만, 해시된 값이 기존에 삽입된 키의 해시 값과 일치해서 False Positive(포함될 가능성이 있다고 했지만 사실 없었던 것)를 만들어낸 것이다.
앞서 설명했듯 Bloom Filter를 사용하면 해당 데이터가 이 Set에 없음 or 해당 데이터가 이 Set에 있을 수도 있음 중 하나를 알려준다. 따라서 있다고 했지만 사실 없을 수는 있는 것이다.
단 False Negative는 존재하지 않는다! Bloom Filter가 해당 데이터가 없다고 응답했으면 확실히 없는 것이다.
1. 확실히 포함되지 않음: Bloom Filter가 해당 데이터가 없다고 응답하면, 데이터는 절대 집합에 없다.
2. 포함될 가능성 있음: Bloom Filter가 데이터가 있다고 응답하면, 해당 데이터는 집합에 있을 수도 있고 없을 수도 있다. (False Positive 가능)
여기서 Bloom Filter를 확률형 데이터 구조라고 하는 이유를 알 수 있다. Bloom Filter는 False Positive를 대가로 공간 절약 이점을 제공하는 것이다!
1억 개 항목을 저장하면서 False Positive 확률을 1%로 설정하면 약 120MB의 공간밖에 필요하지 않는다.
Bloom Filter의 사용 용례
대규모 데이터 Set에서 데이터 존재 여부 를 공간 효율적으로 알고자 하는 경우 사용한다.
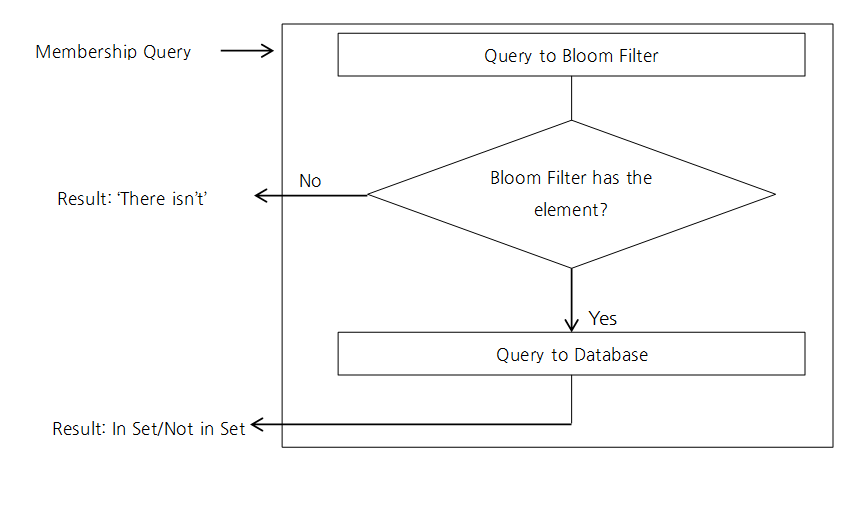
1. 데이터베이스
앞서 설명한 HBase, Cassandra, PostgreSQL, BigTable 같은 저장소에서 찾고자 하는 Key가 저장소에 조회하는지 여부를 먼저 판단해서 불필요한 디스크 스캔을 줄이고 있다.
HBase에서는 HFile을 저장할 때 Row 혹은 Row-Col 단위로 Bloom Filter에 저장하여 조회 시 해당 Key가 존재하는지 확인할 수 있다. 이를 통해 HBase의 읽기 성능을 높이는 데 기여한다. 참고로 HFile은 Immutable하게 관리된다.
2. 웹 캐시/CDN
조회하는 콘텐츠가 캐시되었는지 여부를 Bloom Filter를 활용해 빠르게 조회해서 속도를 감소시킬 수 있다. Squid는 Bloom Filter를 기반으로 동작한다.
What is the theory behind Cache Digests?
Cache Digests are based on Bloom Filters - they are a method for representing a set of keys with lookup capabilities; where lookup means “is the key in the filter or not?”.
https://wiki.squid-cache.org/SquidFaq/CacheDigests
3. Whitelist/Blacklist 관리
Medium은 사용자가 이미 읽은 적 있는 게시글을 추천에서 제외시키기 위해 Bloom Filter를 사용한다.
https://blog.medium.com/what-are-bloom-filters-1ec2a50c68ff#.xlkqtn1vy
Bloom Filter의 한계
우선 당연하게도 False Positive를 허용한다는 것은 큰 단점이 될 수 있다. False Positive Rate를 조절하여 거의 발생하지 않게끔 만들 수 있지만, 그마저도 허용되면 안 될 수 있다. 예를 들어 위 예제의 Medium에서 Bloom Filter를 사용하기에 False Positive로 인해 읽은 적 없는 게시글이 추천에서 제외되어 볼 수 없게 될 수 있다.
이것을 포함한 여러 이유로 Elastic Search에서도 Bloom Filter가 원래 (Lucene에) 존재했지만 제거되었다. Lucene 엔진의 발전(skip-list, FST)이 있는 것과 더불어 메모리를 더 효율적으로 사용할 수 있는 방법들이 제안되어 제거된 걸로 보인다.
https://github.com/elastic/elasticsearch/issues/8571
https://discuss.elastic.co/t/use-bloomfilter-as-default-codec-for-uid-field/145267
물론 애초에 False Positive가 없어야 한다는 것은 확률형 자료구조를 쓰지 않겠다는 것이다. 이런 상황엔 Roaring Bitmap 등을 써서 정확도가 100%인 압축된 비트맵을 쓰기도 한다.
또한 Bloom Filter는 삭제를 처리할 수 없다. 그래서 Write Once, No Update인 시스템에 더 적합하다. 예를 들어 URL Shortner의 경우 한번 URL을 Shorten 하고나면 바뀔 일이 없으므로 Write Once, No Update라고 할 수 있다. 이런 시스템이 아니라 삽입하고자 하는 Key 자체가 수정될 가능성이 있다면 부적합할 것이다. 그래서 삭제가 가능한 형태의 Cuckoo Filter 등 여러 변형이 존재하지만, 보통 Bloom Filter에 비해 더 많은 공간을 차지한다.
그리고 Key가 특정 패턴을 따르거나 편향된 경우에는 취약할 수 있다. 예를 들어 Key가 user123, user234 같은 패턴을 따르는 경우. Bloom Filter는 해시 함수의 결과가 균일하게 분포한다고 가정하여 설계되기에, 해시 함수의 결과가 특정 비트에 집중되면, Bloom Filter의 비트 배열이 불균형하게 설정되어서 False Positive 비율이 증가할 수 있다.
실제 적용
Bloom Filter는 1970년대 나온 아이디어이기 때문에 이미 많은 라이브러리로 구현이 되었다. 일례로 Redis도 Bloom Filter 자료구조를 지원한다.
https://redis.io/docs/latest/develop/data-types/probabilistic/bloom-filter/
Redis에서 Bloom Filter를 사용하기 위한 커맨드에서 보다시피 미리 고려해야 할 것들이 몇 가지 있다.
BF.RESERVE {key} {error_rate} {capacity} [EXPANSION expansion] [NONSCALING]첫 번째는 error_rate(false positive rate) 를 얼마로 지정할 것인가이다. error_rate가 낮을 수록 차지하는 메모리 크기가 커지므로 트레이드오프의 영역이다.
두 번째는 capacity다. Bloom Filter를 만들 때 예상되는 최대 항목 수를 대략적으로라도 파악해야 메모리를 낭비하지 않고 효율적인 필터를 구성할 수 있다. capacity를 너무 작게 잡으면 새로운 sub-filter가 계속 쌓이게 된다.
세 번째는 EXPANSION이다. Redis의 Bloom Filter는 기본적으로 auto-scale 동작을 지원하기 때문에 최대 용량에 도달하면 기존 크기의 몇 배(EXPANSION)로 새 sub-filter를 생성한다. EXPANSION 값을 2 이상으로 설정하면 새 sub-filter를 더 크게 잡아 sub-filter의 중첩을 줄일 수 있지만, 초기 메모리가 조금 더 많이 들 수 있다.
마지막으로 NONSCALING 옵션도 있는데, 이건 미리 설정한 capacity 이상으로 확장하지 않을 것이 확실한 경우 사용하면 해시 함수를 하나 덜 사용하게 되어 약간의 성능 이점을 얻을 수 있다.
Redis의 Bloom Filter를 사용하는 것이 아니여도 공통적으로 고려해보면 좋을 것들이기에 참고하여 서비스에 적용하자. 또한 Key의 삭제 혹은 수정이 존재하는지 등 여부에 따라 대안으로 제안되는 다른 확률형 자료구조를 사용할 수 있다는 점도 잊지 말자.
