배경
한 스토어는 여러 개의 카테고리에 속한다. 이러한 매핑 관계를 표현하기 위한 테이블로 category_store_mapping이라는 테이블이 있다. store_id, category_id 를 기준으로 유니크 제약 조건이 걸려 있다.
create table category_store_mapping
(
category_store_mapping_id bigint auto_increment
primary key,
category_id bigint null,
store_id bigint null,
constraint category_store_unique_key
unique (category_id, store_id)
);새로운 스토어를 생성하거나 수정할 땐 putCategoryStoreMappings() 메소드를 호출해서 생성을 한다.
public void putCategoryStoreMappings(Store store, List<Long> categoryIds) {
List<Category> categories = findAllById(categoryIds);
categoryStoreMappingRepository.deleteByStore(store); // 모든 매핑을 삭제
categoryStoreMappingRepository.saveAll(
categories.stream().map(category -> new CategoryStoreMapping(store, category)).toList()
); // 새롭게 매핑을 만들어서 저장
}
...
public interface CategoryStoreMappingRepository extends JpaRepository<CategoryStoreMapping, Long> {
void deleteByStore(Store store);
}- 스토어와 카테고리 ID들을 입력 받아서
- 한 스토어가 가지고 있는 모든 카테고리 매핑을 제거하고 (REMOVED)
- 다시 카테고리 매핑을 생성하여 저장을 한다.
라는 심플한 로직을 수행하는 코드로 겉보기에는 전혀 문제가 없어보인다.
문제
다만 스토어를 수정하는 과정에서 UniqueConstraint를 위반했다는 메시지를 마주하게 된다.
Caused by: org.h2.jdbc.JdbcSQLIntegrityConstraintViolationException: Unique index or primary key violation: "PUBLIC.CATEGORY_STORE_UNIQUE_IDX_INDEX_7 ON PUBLIC.CATEGORY_STORE_MAPPING(CATEGORY_ID NULLS FIRST, STORE_ID NULLS FIRST) VALUES ( /* key:1 */ CAST(1 AS BIGINT), CAST(1 AS BIGINT))"; SQL statement:
왜 모든 매핑을 다 지우고 새롭게 INSERT를 하는데 왜 Unique 제약 조건을 위반할까?
원인
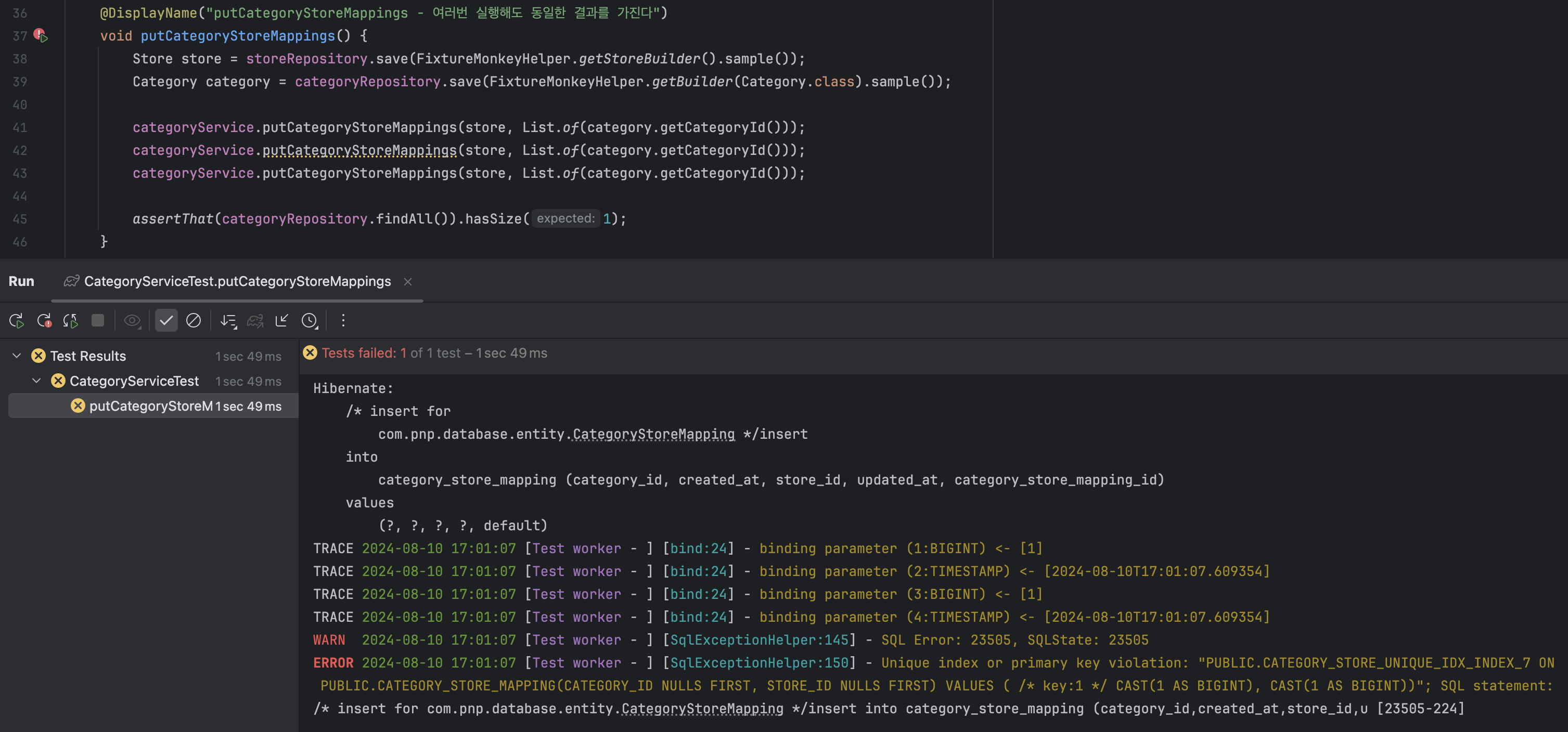
위 시나리오를 테스트 코드를 재현해보면, putCategoryStoreMappings를 여러 번 호출했을 때 DELETE 쿼리가 실행되지 않고 INSERT 쿼리가 먼저 실행된다는 사실을 알 수 있다.
이 사실을 기반으로 서칭을 해본 결과, 쓰기 지연 저장소 쿼리에 실행 순서가 있다는 사실을 알게 되었다.
쓰기 지연 저장소의 쿼리 실행 순서
JPA는 엔티티를 수정할 때 변경 사항을 즉시 데이터베이스에 반영하지 않는다. 대신 쓰기 지연 저장소(Write-Behind Buffer) 라는 메커니즘을 사용하여 변경 사항에 대한 SQL을 버퍼에 보관한다. 이 버퍼는 세션이 flush될 때 한 번에 쿼리를 실행한다.
다만 이 쿼리를 실행할 때는 코드의 순서에 따라 쿼리를 실행하지 않는다. 하이버네이트에서 쿼리를 수행을 하는 special order가 존재한다.
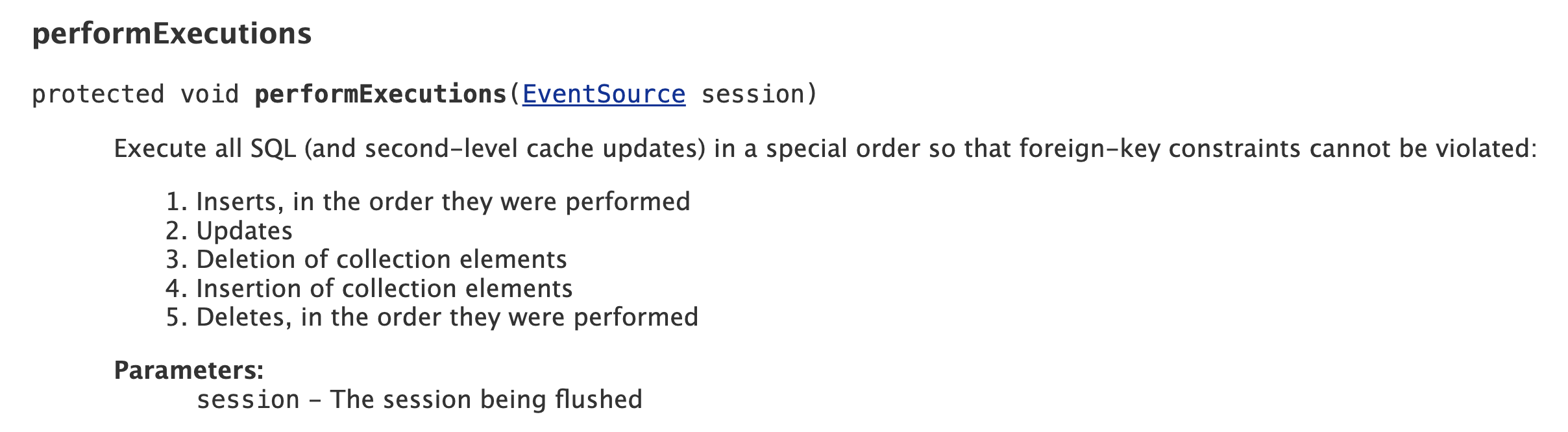
하이버네이트의 AbstractFlushingEventListener Class의 로직에 따르면
1. Inserts
2. Updates
3. Deletion of collection elements
4. Insertion of collection elements
5. Deletes
라는 순서를 따라서 SQL들을 실행한다.
따라서 삭제를 하는 쿼리보다 삽입을 하는 쿼리가 먼저 실행되어서, UniqueConstraint를 위반하게 되는 것이었다.
해결
삭제 쿼리를 삽입 쿼리보다 먼저 실행되게끔 하면 된다. 여러가지 방법이 있겠지만, 제일 간단한 방법을 택했다. 삭제를 JPQL로 실행시키는 것이다.
public interface CategoryStoreMappingRepository extends JpaRepository<CategoryStoreMapping, Long> {
@Modifying
@Query("DELETE from CategoryStoreMapping WHERE store = :store")
void deleteByStore(Store store);
}JPA에서 flush가 발생하는 조건은 아래와 같다.
1. 트랜잭션이 커밋될 때
2. JPQL이 실행될 때
3. 명시적으로 flush를 호출할 때
따라서 JPQL로 삭제를 진행하면 DELETE 쿼리가 수행할 때 즉시 flush되어 데이터베이스에 직접 반영된다. 즉, DELETE 쿼리 이후에 INSERT 쿼리가 이후에 실행된다. 따라서 UniqueConstraint를 위반하지 않고 원하는 결과를 얻을 수 있다.
수정된 코드에서는 여러 번 putCategoryStoreMappings를 호출하는 시나리오가 정상적으로 작동한다.
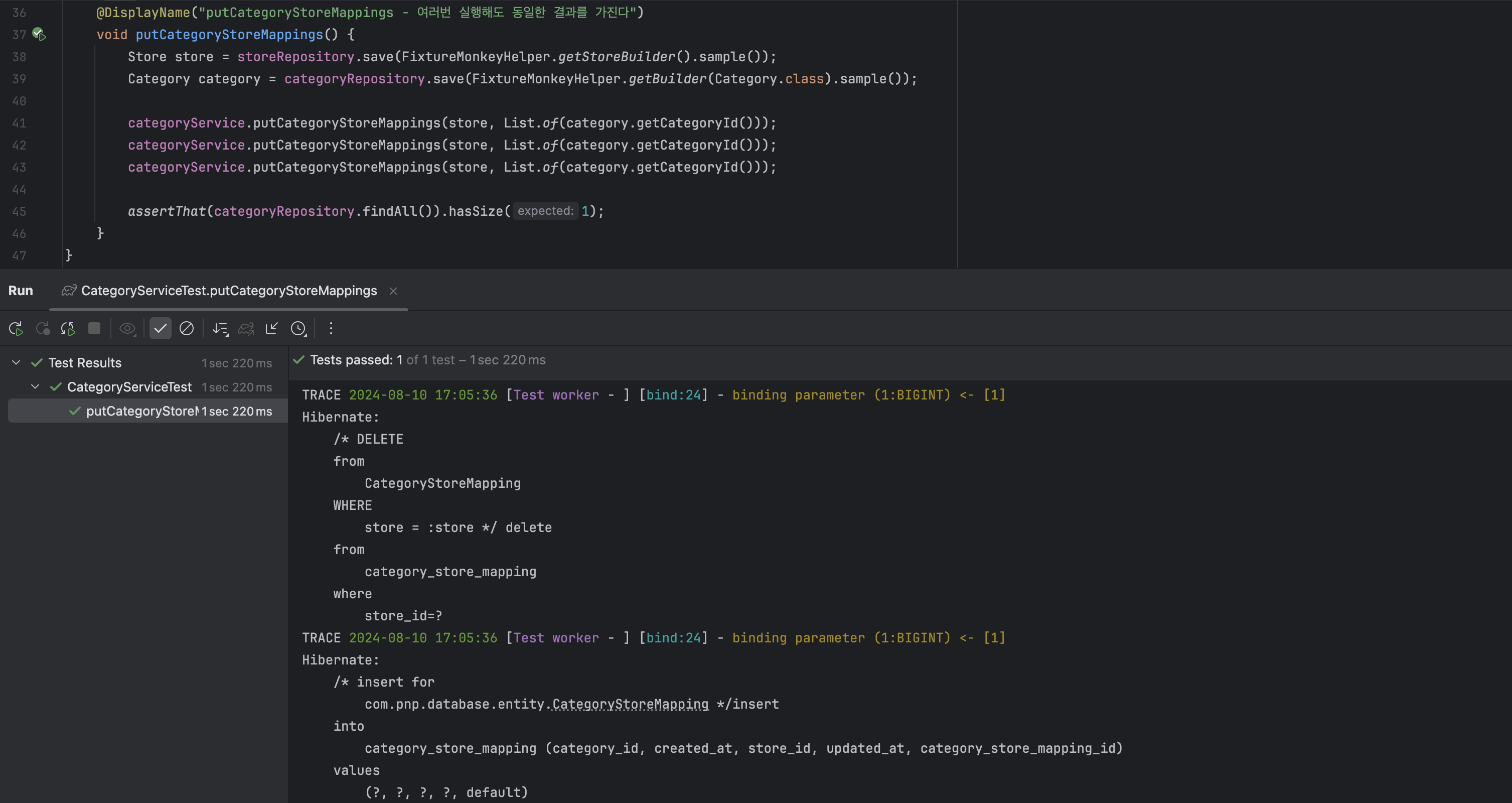
물론 JPQL을 사용하지 않더라도 명시적으로 flush를 호출해도 무관하다.
categoryStoreMappingRepository.deleteByStore(store);
entityManager.flush(); // 명시적으로 flush 호출JPQL과 flush의 관계
왜 JPQL이 실행될 때 flush가 호출될까?
만약 JPQL을 실행하기 전에 영속성 컨텍스트에 남아있는 변경 사항이 데이터베이스에 반영되지 않는다면, JPQL 쿼리는 최신 상태가 아닌 데이터에 대해 실행될 것이다.
따라서 JPQL 쿼리가 실행되기 직전에 flush를 수행하여 영속성 컨텍스트의 모든 변경 사항을 데이터베이스에 반영해야 데이터가 최신 상태임 을 보장할 수 있다.
결론
JPA/Hibernate에서 쓰기 지연 저장소의 쿼리를 실행하는 순서가 있기에 예상치 못한 동작을 가져올 수 있다는 점을 유념해야 한다.
