👀 'Do it! 알고리즘 코딩테스트 with Python(김종관 저)'을 공부하고 정리한 내용입니다.
1. DFS - 깊이 우선 탐색
깊이 우선 탐색은 그래프 완전 탐색 기법 중 하나입니다. 깊이 우선 탐색은 그래프의 시작 노드에서 출발하여 탐색할 한 쪽 분기를 정하여 최대 깊이까지 탐색을 마친 후 다른 쪽 분기로 이동하여 다시 탐색을 수행하는 알고리즘입니다.
깊이우선 탐색은 실제 구현 시 재귀함수를 이용하므로 스택 오버플로에 유의해야 합니다. 깊이 우선 탐색을 응용하여 풀 수 있는 문제는 단절점 찾기, 단절선 찾기, 사이클 찾기, 위상 정렬 등이 있습니다.

DFS 핵심 이론
깊이 우선 탐색에서는 스택(Stack)이 사용됩니다. 사실 스택을 사용하지 않아도 구현이 가능한데, 컴퓨터의 세계는 애초에 구조적으로 스택의 원리를 사용하기 때문입니다. 재귀함수만으로도 구현할 수 있다는게 바로 이것 때문입니다.
DFS는 다음과 같은 간단한 알고리즘에 따라서 작동합니다.
- 스택의 최상단(가장 마지막에 들어온) 노드를 확인합니다.
- 최상단 노드에게 방문하지 않은 인접 노드가 있다면 그 노드를 스택에 넣고 방문처리합니다.
- 1-2를 반복합니다.
이론 자체는 상당히 쉬운데, 이것을 코드로 구현하는것은 생각보다 복잡할 수 있습니다.
DFS 수행과정
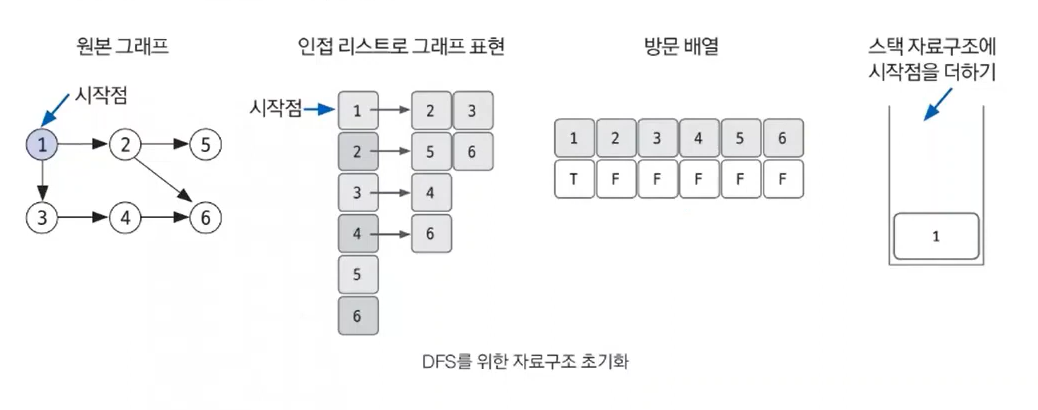
- DFS를 시작할 노드를 정한 후 사용할 자료구조를 초기화하기
DFS를 위해 필요한 초기 작업은 인접 리스트로 그래프 표현하기, 방문 배열 초기화하기, 시작 노드 스택에 삽입하기 입니다. 스택에 시작노드를 1로 삽입할 때 해당 위치의 방문 배열을 체크하면 T, F, F, F, F, F가 됩니다.
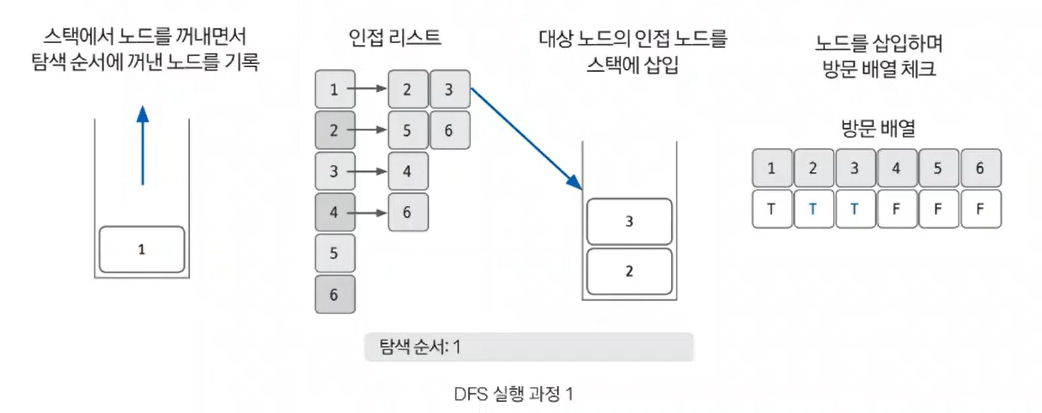
- 스택에서 노드를 꺼낸 후 인접 노드를 다시 스택에 삽입하기
이제 POP을 수행하여 노드를 꺼냅니다. 꺼낸 노드를 탐색 순서에 기입입하고 인접 리스트의 인접 노드를 스택에 삽입하여 배열을 체크합니다. 방문 배열은 T, T, T, F, F, F가 됩니다.
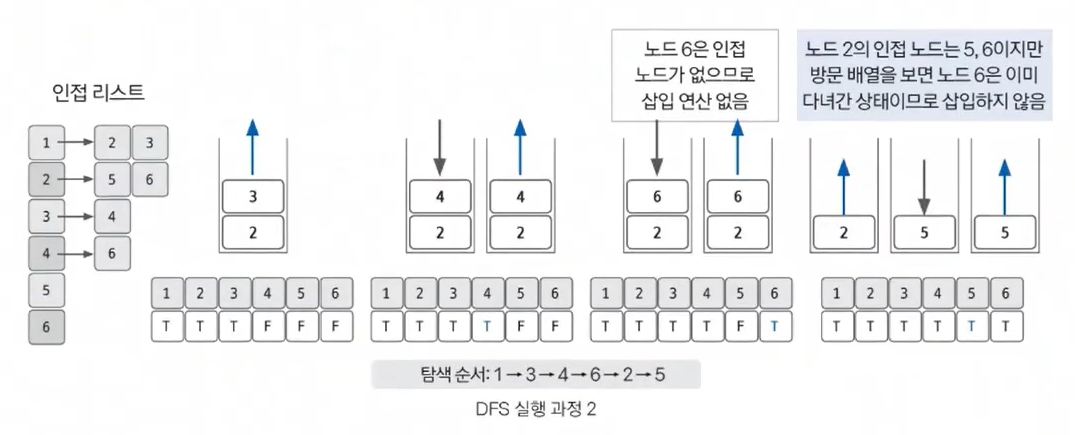
- 스택 자료구조에 값이 없을 때까지 반복하기
앞선 과정을 스택 자료구조에 값이 없을때까지 반복합니다. 이때 이미 다녀간 노드는 방문 배열을 바탕으로 재삽입하지 않습니다.
2. BFS - 너비 우선 탐색
너비 우선 탐색 또한, 그래프 완전 탐색 기법 중 하나입니다. 깊이 우선 탐색과는 다르게, 너비를 우선으로 하여 탐색하는 알고리즘입니다. 이것은 가장 가까운 노드를 먼저 방문하면서 탐색하기에, '최단 경로'를 찾아준다는 점에서 최단 길이를 보장해야 할 때 많이 사용합니다. 깊이 우선 탐색은 스택(Stack)을 사용했는데, 너비 우선 탐색은 큐(Queue)를 사용합니다.

BFS 수행 과정
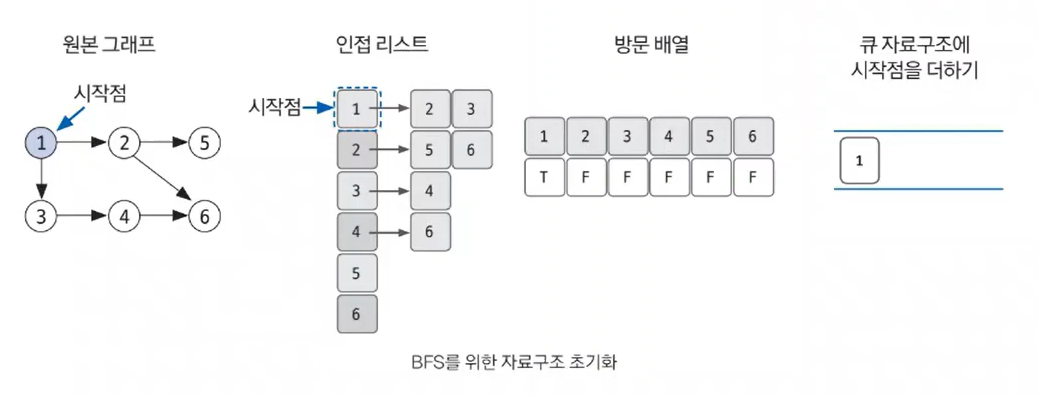
- BFS를 시작할 노드를 정한 후 사용할 자료구조 초기화하기
BFS도 DFS와 마찬가지로 방문했던 노드는 다시 방문하지 않으므로 방문한 노드를 체크하기 위한 배열이 필요합니다. 그래프를 인접 리스트로 표현하는 것 역시 DFS와 동일합니다.
- 큐에서 노드를 꺼난 후 꺼낸 노드의 인접 노드를 다시 큐에 삽입하기
큐에서 노드를 꺼내면서 인접 노드를 큐에 삽입합니다. 이때 방문 배열을 체크하여 이미 방문한 노드는 큐에 삽입하지 않습니다. 또한 큐에서 꺼낸 노드는 탐색 순서에 기록합니다.
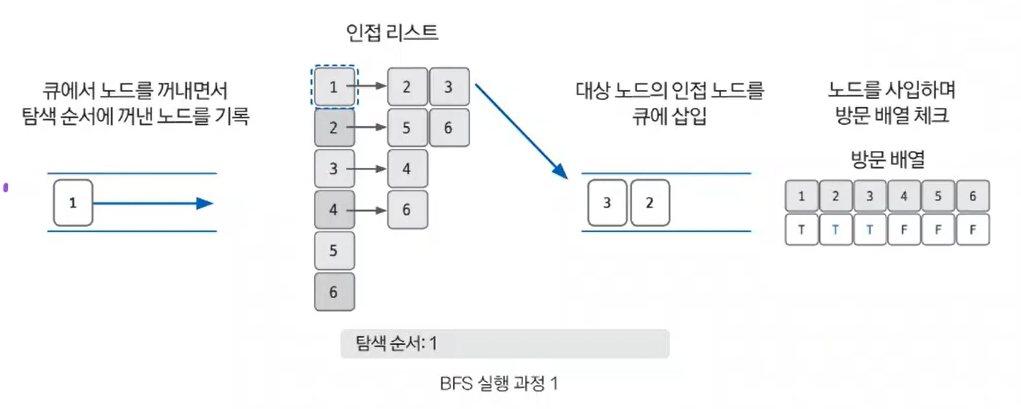
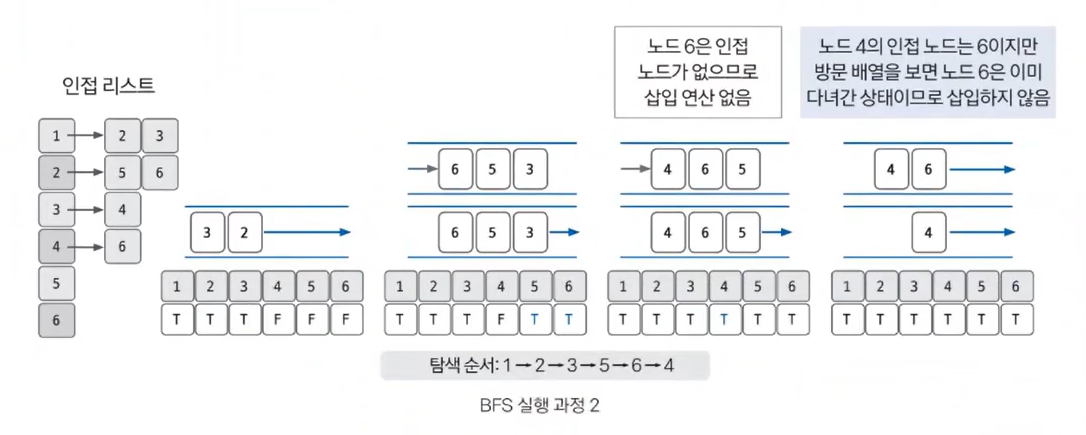
- 큐 자료구조에 값이 없을 때까지 반복하기
큐에 노드가 없을 때 까지 앞선 과정을 반복합니다. 선입선출 방식으로 탐색하므로 탐색 순서가 DFS와 다릅니다.
*함께 보기 좋은 자료
DFS - https://blog.naver.com/ndb796/221230945092
BFS - https://blog.naver.com/ndb796/221230944971
