0. 정렬
정렬의 방법은 여러가지가 있습니다.
저번에 버블, 선택, 삽입 세가지 정렬에 대해서 알아보았는데,
이번에는 이어서 퀵, 병합, 기수 정렬에 대해 알아봅시다.
👀 'Do it! 알고리즘 코딩테스트 with Python(김종관 저)'을 공부하고 정리한 내용입니다.
1. 퀵 정렬
퀵 정렬은 기준값을 선정해 해당 값보다 작은 데이터와 큰 데이터로 분류하는 것을 반복해 정렬하는 알고리즘 입니다. pivot(기준값)이 어떻게 선정되는지가 시간복잡도에 많은 영향을 미치고, 시간복잡도는 평균 O(nlogn), 최악의 경우 O(n**2)입니다.
퀵 정렬 수행과정 요약
-
리스트 안에 있는 한 요소를 선택한다. 이렇게 고른 원소를 pivot(기준값) 이라고 한다.
-
pivot을 기준으로 pivot보다 작은 요소들은 모두 피벗의 왼쪽으로, pivot보다 큰 요소들은 모두 pivot의 오른쪽으로 옮겨진다.
-
pivot을 제외한 왼쪽 리스트와 오른쪽 리스트에 대해 순환 호출을 이용하여 정렬을 반복한다.
-
부분 리스트들이 더 이상 분할이 불가능할 때까지(리스트의 크기가 0이나 1이 될 때까지) 반복한다.
퀵정렬의 수행 과정을 간단하게 이야기하자면 위 4단계이다.
워낙 간략하게 설명하여 이것만으로 설명이 충분하지 않을것이다.
아래에 상세 과정이 있다.
퀵 정렬 수행과정
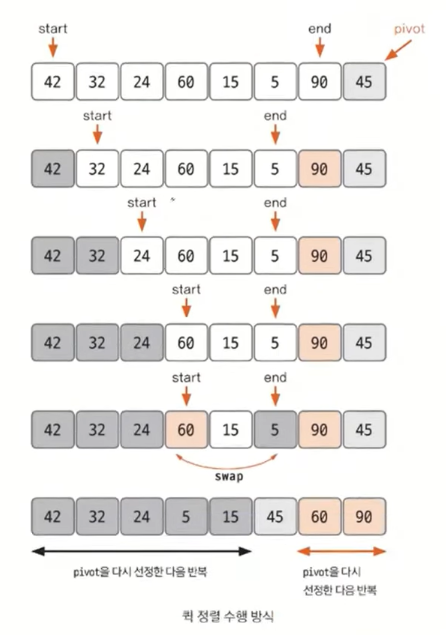
-
데이터를 분할하는 pivot을 설정한다.
-
pivot을 기준으로 다음 a~e 과정을 거쳐 데이터를 2개의 집합으로 분리한다.
2-1. start가 가리키는 데이터가 pivot이 가리키는 데이터보다 작으면 start를 오른쪽으로 1칸 이동한다.
2-2. end가 가리키는 데이터가 pivot이 가리키는 데이터보다 크면 end를 왼쪽으로 1칸 이동한다.
2-3. start가 가리키는 데이터가 pivot이 가리키는 데이터보다 크고, end가 가리키는 데이터가 pivot이 가리키는 데이터보다 작으면, start, end가 가리키는 데이터를 swap하고 start는 오른쪽, end는 왼쪽으로 1칸씩 이동한다.
2-4. start와 end가 만날 때 까지 2-1~2-3을 반복한다.
2-5. start와 end가 만나면 만난 지점에서 가리키는 데이터와 pivot이 가리키는 데이터를 비교하여 pivot이 가리키는 데이터가 크면 만난 지점의 오른쪽에, 작으면 만난 지점의 왼쪽에 pivot이 가리키는 데이터를 삽입한다.
-
분리 집합에서 각각 다시 pivot을 선정한다.
-
분리 집합이 1개 이하가 될 때까지 1~3과정을 반복한다.
머리가 아프다.
자세한건 나중에 문제를 통해 만나보고 예시를 추가해보도록 하자.
2. 병합 정렬
병합정렬은 분할과 정복 방식을 사용해 데이터를 분할하고 분할한 집합을 정렬하며 합치는 알고리즘입니다. 병합정렬의 시간복잡도는 O(nlogn)입니다.
병합 정렬은 효율적인 정렬방식입니다. 하지만 정렬을 위해 추가적인 메모리 공간이 필요하다는 점이 병합 정렬의 단점 중 하나입니다.
병합 정렬 수행과정

위 그림을 보시면 최초 리스트를 쪼개고 쪼개고 쪼개서 가장 작은 데이터 집합으로 나누었습니다.
이 상태에서 2개씩 그룹을 합치며 오름차순으로 정렬하기를 반복합니다.
그런데 저는 혼란스럽습니다.
첫번째 combine은 그냥 두개 비교해서 합치는거라고 치는데,
나머지 정렬은 대체 어케하는걸까요?
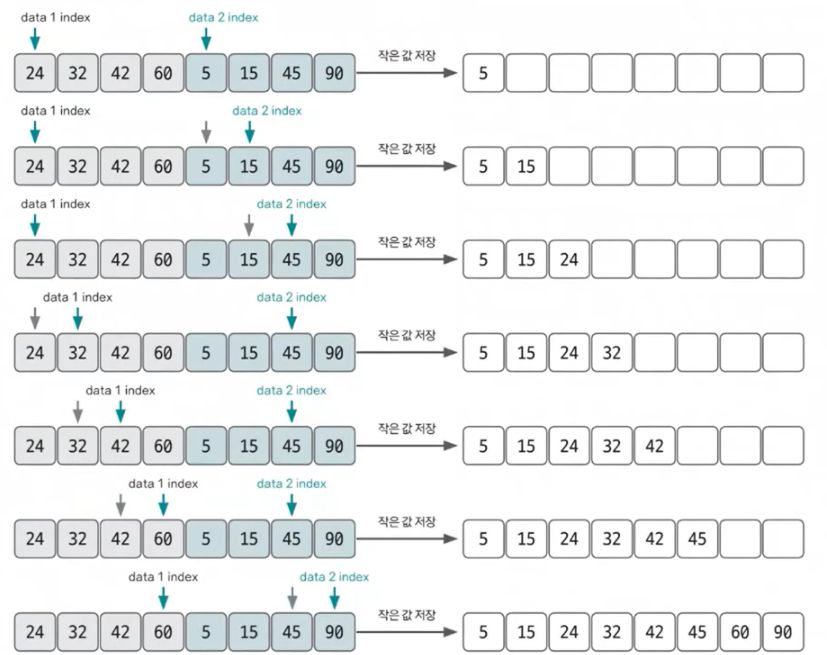
우리가 원하는 정렬을 하기 위해서는 비교가 필수적입니다.
병합 정렬에서 이루어지는 비교는 다음과 같습니다.
-
2개의 리스트 값들을 처음부터
하나씩 비교하며 두개의 값 중에서 더 작은 값을 새로운 리스트에 옮긴다. -
작은 값이 빠져나간 리스트에서 index++ 연산을 수행한다.
-
1~2를 반복한다.
-
만약 둘 중에서 하나의 리스트가 먼저 끝나게 되면 남은 리스트의 값을 그대로 새로운 리스트에 옮긴다.
-
새로 만들어진 리스트가 정렬전 리스트와 같은 길이가 될때까지 반복한다.
3. 기수 정렬
기수 정렬은 특이하게도 값을 비교하지 않습니다.
비교를 아예 안한다는 것이 아니라, 다른 정렬 방법의 경우 주어진 값을 하나하나 비교하겠지만, 기수 정렬은 자릿수를 정한 다음 해당 자릿수만 비교합니다.
예를들어 234와 123을 비교해야한다면, 4와 3, 3과 2, 2와 1만 비교합니다.
기수 정렬 수행과정
기수 정렬은 10개의 큐를 이용합니다. 각 큐는 값의 자릿수를 대표합니다.
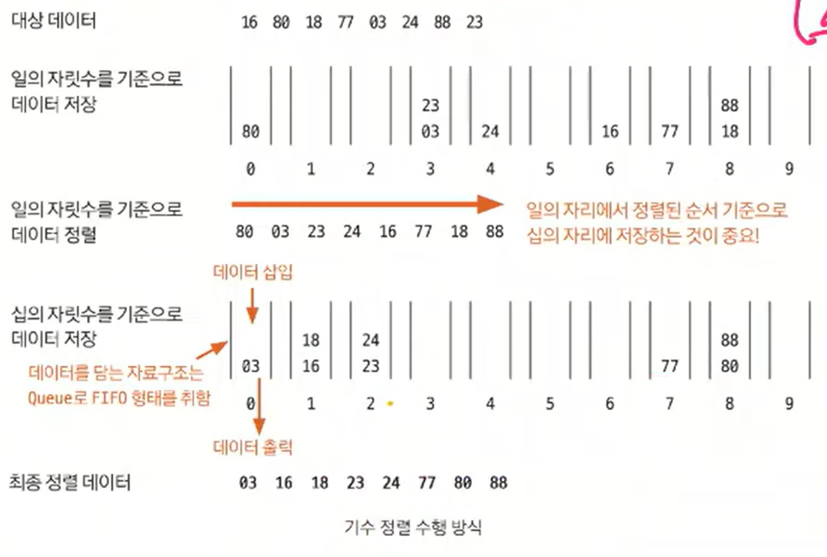
위 그림을 보면 최초 주어지는 대상 데이터는 [16, 80, 18, 77, 03, 24, 88, 23]입니다.
정렬 과정은 다음과 같습니다.
-
원 배열을 일의 자릿수를 기준으로 큐에 넣는다.
-
0번째 큐부터 9번째 큐까지 pop을 진행하여 일의 자릿수를 기준으로 데이터를 정렬한다.
-
2에서 정렬된 배열을 십의 자릿수를 기준으로 큐에 넣습니다.
-
0번째 큐부터 9번째 큐까지 pop을 진행하여 십의 자릿수를 기준으로 데이터를 정렬한다.
이처럼, 마지막 자릿수를 기준으로 정렬할 때까지 과정을 반복합니다.
참고자료
https://gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort
https://gmlwjd9405.github.io/2018/05/08/algorithm-merge-sort
