목차
- SQL 주요 문법
- NOSQL
- 관계형 데이터베이스
- ACID
배운 내용
SQL
-
Structured Query Language → 구조화된 Query 언어(DB용 프로그래밍 언어)
-
Query란 ?
- 질의문( 검색어)
- 저장되어 있는 정보를 필터하기 위한 질의문(필터링)
-
데이터베이스에 query를 보내 원하는 데이터만을 뽑아올수 있다.
-
SQL을 사용하기 위해서는 데이터가 구조가 고정되어 있어야 한다.
-
In-memory
- 끄면 데이터가 없어짐
-
File I/O
- 원하는 데이터만 가져올 수 없고 항상 모든 데이터를 가져온 뒤 서버에서 필터링 필요
-
Database
- 필터링 외에도 File I/O로 구현이 힘든 관리를 위한 여러 기능들을 가지고 있는 데이터에 특화된 서버
-
NoSQL
- 데이터의 구조가 고정되어 있지 않은 데이터베이스
- 테이블을 사용하지 않고 데이터를 다른 형태로 저장
- ex) MongoDB 와 같은 문서 지향 데이터베이스
**데이터베이스 관련 명령어**
**데이터베이스 생성**
CREATE DATABASE 데이터베이스_이름;
**데이터베이스 사용**.
USE 데이터베이스_이름;
**테이블 생성**
CREATE TABLE user (
id int PRIMARY KEY AUTO_INCREMENT,
name varchar(255),
email varchar(255)
);**테이블 정보 확인**
DESCRIBE user;
**SQL 명령어**
*SELECT*
- 데이터셋에 포함될 특성을 특정
*FROM*
- 결과를 도출해낼 데이터베이스 테이블을 명시
SELECT 특성_1, 특성_2
FROM 테이블_이름
// 모든 특성선택
SELECT *
FROM 테이블_이름*WHERE*
- 필터 역할
//특정값과 동일한 데이터 찾기
SELECT 특성_1, 특성_2
FROM 테이블_이름
WHERE 특성_1 = "특정 값"
//특정값을 제외한 값을 찾기
SELECT 특성_1, 특성_2
FROM 테이블_이름
WHERE 특성_2 <> "특정 값"
// 특정값과 비슷한 값들을 필터할때 'LIKE'와 \%혹은 \*을사용
SELECT 특성_1, 특성_2
FROM 테이블_이름
WHERE 특성_2 LIKE "%특정 문자열%"
//리스트의 값들과 일치하는 데이터를 필터할때 'IN'을 사용
SELECT 특성_1, 특성_2
FROM 테이블_이름
WHERE 특성_2 IN ("특정값_1", "특정값_2")
//값이 없는 경우 'NULL' 을 찾을 때에는 'IS' 와 같이 사용
SELECT *
FROM 테이블_이름
WHERE 특성_1 IS NULL
// 값이 없는 경우를 제외할 때에는 'NOT' 을 추가
SELECT *
FROM 테이블_이름
WHERE 특성_1 IS NOT NULL*ORDER BY*
- 돌려받는 데이터 결과를 어떤 기준으로 정렬하여 출력할지 결정
// 기본 정렬 오름차순
SELECT *
FROM 테이블_이름
ORDER BY 특성_1
// 내림차순
SELECT *
FROM 테이블_이름
ORDER BY 특성_1 DESC*LIMIT*
- 결과로 출력할 데이터의 갯수를 정한다.
- 쿼리문에서 사용할 때에는 가장 마지막에 추가
//데이터 200개만 출력
SELECT *
FROM 테이블_이름
LIMIT 200*DISTINCT*
- 유니크한 값을 받고 싶을 때에는
SELECT DISTINCT를 사용
// 특성_1,2,3 의 유니크한 조합값들을 선택
SELECT
DISTINCT
특성_1
,특성_2
,특성_3
FROM 테이블_이름*INNER JOIN*
INNER JOIN이나JOIN으로 실행
// 둘 이상의 테이블을 서로 공통된 부분을 기준으로 연결
SELECT *
FROM 테이블_1
JOIN 테이블_2 ON 테이블_1.특성_A = 테이블_2.특성_B*OUTER JOIN*
Outer JOIN은 다양한 선택지가 있다.
//'LEFT OUTER JOIN'으로 LEFT INCLUSIVE 실행
SELECT *
FROM 테이블_1
LEFT OUTER JOIN 테이블_2 ON 테이블_1.특성_A = 테이블_2.특성_B
//'RIGHT OUTER JOIN'으로 RIGHT INCLUSIVE을 실행
SELECT *
FROM 테이블_1
RIGHT OUTER JOIN 테이블_2 ON 테이블_1.특성_A = 테이블_2.특성_BACID
- 데이터베이스 내에서 일어나는 하나의 트랜잭션(transaction)의 안전성을 보장하기 위해 필요한 성질
**Atomicity(원자성)**
- 하나의 트랜잭션에 속해있는 모든 작업이 전부 성공하거나 전부 실패해서결과를 예측할 수 있어야 한다.
- A 계좌에서 출금하는 일에 성공했지만, B 계좌에 입금하는 작업에 실패한다면 계좌 A에서 출금하는 작업을 포함하여 모든 작업이 실패로 돌아가야 한다는 것이 Atomicity(원자성)이다.
- 하나의 작업이라도 실패한다면, 하나의 단위로 묶여있는 모든 작업이 실패하게 만들어 기존 데이터를 보호
- SQL - 특정 쿼리를 실행했는데 부분적으로 실패하는 부분이 있다면, 전부 실패하도록 구현
- 과정을 취소시키는것을 롤백이라고 한다.
**Consistency(일관성)**
- 데이터베이스의 상태가 일관되어야 한다는 성질
- 하나의 트랜잭션 이전과 이후, 데이터베이스의 상태는 이전과 같이 유효해야 한다.
- 트랜잭션이 일어난 이후의 데이터베이스는 데이터베이스의 제약이나 규칙을 만족해야 한다
- 트랜잭션으로 데이터베이스에 특정한요소에 제약을 건다거나, 데이터베이스 전체의 상태를 일관적이지 않게 유지한다면, 데이터베이슨는 트랜잭션 처리안함 →일관성
**Isolation(격리성, 고립성)**
- 모든 트랜잭션은 다른 트랜잭션으로부터 독립되어야 한다
- 동시에 여러 개의 트랜잭션들이 수행될 때, 각 트랜젝션은 고립(격리)되어 있어 연속으로 실행된 것과 동일한 결과를 나타낸다.
- 예시
- 계좌에 만원이 있을때
- 계좌 B로 6천 원을, 계좌 C로 6천 원을 동시에 계좌 이체하는 경우, 계좌 B에 먼저 송금한 뒤 계좌 C에 보내는 결과와 동일해야 한다.
- 동시에 트랜잭션을 실행한다고 해서 계좌 B와 C에 각각 6천 원씩 송금하여 마이너스 통장이 되는 것이 아니라, 각각의 송금 작업을 연속으로 실행하는 것과 동일한 결과가 나타나야 한다.
- 각 트랜젝션은 철저히 독립적이기 때문에, 다른 트랜젝션의 작업 내용을 알 수 없고, 트랜잭션이 동시에 실행될 때와 연속으로 실행될 때의 데이터베이스 상태가 동일해야 한다.
**Durability(지속성)**
- 하나의 트랜잭션이 성공적으로 수행되었다면, 해당 트랜잭션에 대한 로그가 남아야 한다.
- 만약 런타임 오류나 시스템 오류가 발생하더라도, 해당 기록은 영구적이어야한다
- 금융업 - ACID 중점적으로 다룸
- 예를 들어 은행에서 게좌이체를 성공적으로 실행한 뒤에, 해당 은행 데이터베이스에 오류가 발생해 종료되더라도 계좌이체 내역은 기록으로 남아야 합니다.
- 마찬가지로 계좌이체를 로그로 기록하기 전에 시스템 오류 등에 의해 종료가 된다면, 해당 이체 내역은 실패로 돌아가고 각 계좌들은 계좌이체 이전 상태들로 돌아가게 된다.
**트랜잭션**
- 여러 개의 작업을 하나로 묶은 실행 유닛
- 각 트랜잭션은 하나의 특정 작업으로 시작을 해 묶여 있는 모든 작업들을 다 완료해야 정상적으로 종료
- 만약 하나의 트랜잭션에 속해있는 여러 작업 중에서 단 하나의 작업이라도 실패하면, 이 트랜잭션에 속한 모든 작업을 실패한 것으로 판단
- 성공 또는 실패라는 두 개의 결과만 존재하는 트랜잭션은, 미완료된 작업없이 모든 작업을 성공해야 한다.
**SQL(구조화 쿼리언어) vs. NoSQL(비구조화 쿼리언어)**
- 데이터베이스 - 관계형 데이터베이스 -SQL, 비관계형 데이터베이스-NoSQL
- 관계형 데이터베이스에서는 테이블의 구조와 데이터 타입 등을 사전에 정의하고, 테이블에 정의된 내용에 알맞은 형태의 데이터만 삽입할 수 있다.
- 각 열은 하나의 속성에 대한 정보를 저장하고, 행에는 각 열의 데이터 형식에 맞는 데이터가 저장
- 관계형 데이터베이스에서는 스키마가 뚜렷하게 보인다
- 관계형 데이터베이스에서는 테이블 간의 관계를 직관적으로 파악가능
NoSQL
- 데이터가 고정되어 있지 않은 데이터베이스
- 스키마가 반드시 없는 것은 아니다.
- 관계형 데이터베이스에서는 데이터를 입력할 때 스키마에 맞게 입력해야 하는 반면, NoSQL에서는 데이터를 읽어올 때 스키마에 따라 데이터를 읽어 온다.
- 읽어올 때에만 데이터 스키마가 사용된다고 하여, 데이터를 쓸 때 정해진 방식이 없다는 의미는 아님, 데이터를 입력하는 방식에 따라, 데이터를 읽어올 때 영향을 미친다.
- Key-Value 타입 : 속성을
Key-Value의 쌍으로 나타내는 데이터를 배열의 형태로 저장 - 문서형(Document) 데이터베이스 : 데이터를 테이블이 아닌 문서처럼 저장하는 데이터베이스
- 많은 문서형 데이터베이스에서 JSON과 유사한 형식의 데이터를 문서화하여 저장
- 각각의 문서는 하나의 속성에 대한 데이터를 가지고 있고, 컬렉션이라고 하는 그룹으로 묶어서 관리
- MongoDB
- Wide-Column 데이터베이스 : 열(column)에 대한 데이터를 집중적으로 관리하는 데이터베이스
- 그래프(Graph) 데이터베이스 : 자료구조의 그래프와 비슷한 형식으로 데이터 간의 관계를 구성하는 데이터베이스
- 노드(nodes)에 속성별(entities)로 데이터를 저장
- 각 노드간 관계는 선(edge)으로 표현
**SQL ↔ NoSQL 차이점**
데이터 저장(Storage)
- NoSQL은 key-value, document, wide-column, graph 등의 방식으로 데이터를 저장
- 관계형 데이터베이스는 SQL을 이용해서 데이터를 테이블에 저장합니다. 미리 작성된 스키마를 기반으로 정해진 형식에 맞게 데이터를 저장
스키마(Schema)
- 스키마란? 데이터의 구조, 데이터베이스의 설계를 의미
- 자료의 구조나 표현방법, 자료간의 관계를 형식 언어로 정의한 구조
- 스키마는 데이터베이스를 구성하는 데이터 개체(entity), 속성(Attribute), 관계(Relationship) 및 데이터 조작시 데이터 값들이 갖는 제약 조건 등에 관해 전반적으로 정의
- 속성(Atrribute) 개체의 특성을 나타냄, 개체(Entity) 속성들의 집합으로 이루어짐, 관계(Relationg)개체 사이에 존재
- SQL을 사용하려면, 고정된 형식의 스키마가 필요
- 처리하려는 데이터 속성별로 열(column)에 대한 정보를 미리 정해두어야한다.
- 스키마는 나중에 변경할 수 있지만, 이 경우 데이터베이스 전체를 수정하거나 오프라인(down-time)으로 전환할 필요가 있다.
- NoSQL은 보다 동적으로 스키마의 형태를 관리 가능.
- 행을 추가할 때 즉시 새로운 열을 추가할 수 있고, 개별 속성에 대해서 모든 열에 대한 데이터를 반드시 입력하지 않아도 된다.
쿼리(Querying)
- 데이터베이스에 대해서 정보를 요청하는 질의문
- 관계형 데이터 베이스는 테이블의 형식과 테이블간의 관계에 맞춰 데이터를 요청해야한다.
- 비관계형 데이터베이스의 쿼리는 데이터 그룹 자체를 조회하는 것에 초점
- 구조화 되지 않은 쿼리 언어로도 데이터 요청이 가능
확장성(Scalability)
- SQL 기반의 관계형 데이터베이스는 수직적으로 확장, 높은 메모리, CPU를 사용
- 데이터베이스가 구축된 하드웨어의 성능을 많이 이용하기 때문에 비용이 많이든다.
- 여러 서버에 걸쳐서 데이터베이스의 관계를 정의할 수 있지만, 매우 복잡하고 시간이 많이 소모
- NoSQL로 구성된 데이터베이스는 수평적으로 확장
- 보다 값싼 서버 증설, 또는 클라우드 서비스 이용힌 확장, 상대적으로 비용이 저렴
- . NoSQL 데이터베이스를 위한 서버를 추가적으로 구축하면, 많은 트래픽을 보다 편리하게 처리할 수 있다.
- 많은 개발자들은 유저의 요구를 충족하기 위해 관계형, 비관계형 데이터베이스를 모두 사용하여 서비스에 맞게 설계
- NoSQL 기반의 비관계형 데이터베이스가 확장성이나 속도면에서 더 뛰어남.
- 고차원으로 구조화된 SQL 기반의 데이터베이스가 더 좋은 성능을 보여주는 서비스도 있음
**관계형 데이터베이스를 사용하는 케이스**
- **데이터베이스의 ACID 성질을 준수해야 하는 경우**
- SQL을 사용하면 데이터베이스와 상호 작용하는 방식을 정확하게 규정할 수 있기 때문에, 데이터베이스에서 데이터를 처리할 때 발생할 수 있는 예외적인 상황을 줄이고, 데이터베이스의 무결성을 보호
- 전자 상거래를 비롯한 모든 금융 서비스를 위한 소프트웨어 개발 에서는 반드시 데이터베이스의 ACID 성질을 준수해야한다.
**2. 소프트웨어에 사용되는 데이터가 구조적이고 일관적인 경우**
- 소프트웨어(프로젝트)의 규모가 많은 서버를 필요로 하지 않고 일관된 데이터를 사용하는 경우
**비관계형 데이터베이스를 사용하는 케이스**
- 데이터의 구조가 거의 또는 전혀 없는 대용량의 데이터를 저장하는 경우
- 저장할 수 있는 데이터의 유형에 제한이없다.
- 필요에 따라, 언제든지 데이터의 새 유형을 추가가능
- 정형화 되지 않은 많은 양의 데이터가 필요한 경우, NoSQL을 적용하는 것이 더 효율적
- 클라우드 컴퓨팅 및 저장공간을 최대한 활용하는 경우
- 클라우드 기반으로 데이터베이스 저장소를 구축하면, 저렴한 비용의 솔루션을 제공받을 수 있다.
- 소프트웨어에 데이터베이스의 확장성이 중요하다면, 별다른 번거로움 없이 확장할 수 있는 NoSQL 데이터베이스를 사용하는것이 좋다.
- 빠르게 서비스를 구축하는 과정에서 데이터 구조를 자주 업데이트 하는 경우
- 스키마를 미리 준비할 필요가 없기 때문에 빠르게 개발하는 과정에 매우 유리 시장에 빠르게 프로토타입을 출시해야 하는 경우.
- 소프트웨어 버전별로 많은 다운타임(데이터베이스 서버를 오프라인으로 전환하여 데이터 처리를 진행하는 작업 시간) 없이 데이터 구조를 자주 업데이트 해야하는 경우, 스키마를 매번 수정해야 하는 관계형 데이터베이스 보다 NoSQL 기반의 비관계형 데이터베이스를 사용하는 게 더 적합
**스케일 업(Scale-up)**
- 기존의 서버를 보다 높은 사양으로 업그레이드하는 것
- 수직 스케일링(vertical scaling)
- EX) 서버에 디스크를 추가하거나 CPU나 메모리를 업그레이드시키는 것
- AWS의 EC2 인스턴스 사양을 micro에서 small, small에서 medium 등으로 높이는 것
**스케일 아웃(Scale-out)**

- 장비를 추가해서 확장하는 방식
- 기존 서버만으로 용량이나 성능의 한계에 도달했을 때, 비슷한 사양의 서버를 추가로 연결해 처리할 수 있는 데이터 용량이 증가할 뿐만 아니라 기존 서버의 부하를 분담해 성능 향상의 효과를 기대
- 수평 스케일링(horizontal scaling)
- 클라우드 서비스에서는 자원 사용량을 모니터링하여 자동으로 서버를 증설(Scale Out)하는 Auto Scaling 기능도 있다
SCALE UP VS SCALE OUT
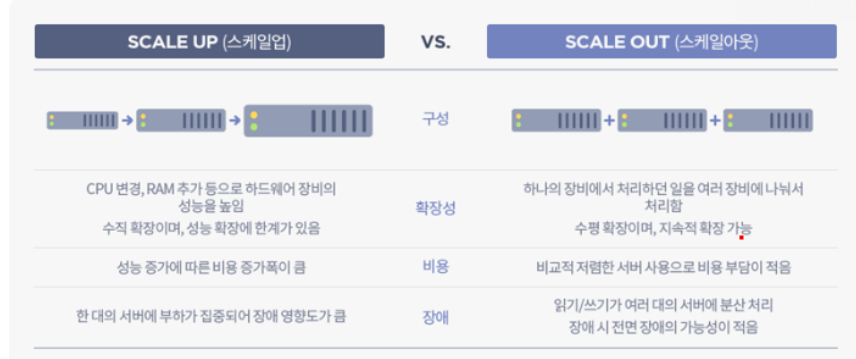
참조: https://tecoble.techcourse.co.kr/post/2021-10-12-scale-up-scale-out/

백엔드 개발자