목차
- MySQL 활용
- 스키마 & 쿼리 디자인
- DB 설계
- Instagram 스키마 디자인 - ERD 다이어그램 실습
- SQL 활용 ERD 설계
배운 내용
SQL 구성요소
- 데이터(data): 각 항목에 저장되는 값
- 테이블(table; 또는 relation) : 사전에 정의된 열의 데이터 타입대로 작성된 데이터가 행으로 축적됨
- 칼럼(column; 또는 field) : 테이블의 한 열을 가리킨다.
- 레코드(record; 또는 tuple) : 테이블의 한 행에 저장된 데이터
- 키(key) : 테이블의 각 레코드를 구분할 수 있는 고유한 값. 기본키(primary key)와 외래키(foreign key) 등이 있다.
Schema & Query Design
Schema
- 데이터베이스에서 데이터가 구성되는 방식과 서로 다른 엔티티 간의 관계에 대한 설명
- Entity : 고유한 정보의 단위
- Field : 엔티티의 특성을 설명 (열)
- Record : 테이블에 저장된 항목 (행)
기본키(Primary Key)
- 각테이블의 레코드 하나를 가리키는 고유한 ID
- 자동으로 값이 증가(auto increments)
외래키(Foreign Key)
- 다른 테이블에서 기본 키를 참조할 때 해당하는 값
관계종류
**1:1 관계**
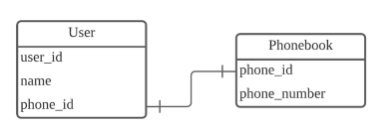
- 하나의 레코드가 다른 테이블의 레코드 한 개와 연결된 경우
- phone_id는 외래키(foreign key)로써, Phonebook 테이블의 phone_id와 연결되어있다.
- 각 전화번호가 단 한 명의 유저와 연결되어 있고, 그 반대도 동일하다면, User 테이블과 Phonebook 테이블은 1:1 관계이다.
**1:N 관계**
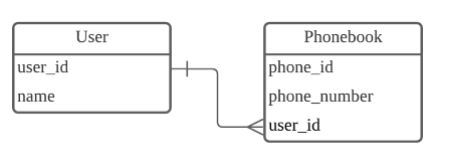
- 하나의 레코드가 서로 다른 여러 개의 레코드와 연결된 경우
- 한 명의 유저가 여러 전화번호를 가질수 있다.그러나 여러명의 유저가 하나의 전화번호를 가질 수는 없다.
**N:N 관계**
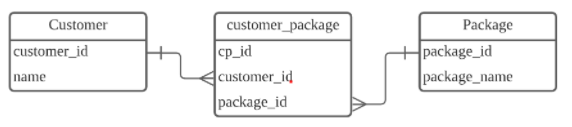
- 두 개의 테이블과 1:N(일대다) 관계를 형성하는 새로운 테이블로 N:N(다대다) 관계를 나타낼 수 있다.
- 다대다 관계를 위한 테이블을 조인 테이블이라고한다.
- customer_package 테이블에서는 고객 한 명이 여러 개의 여행 상품을 가질 수 있고, 여행 상품 하나가 여러 개의 고객을 가질 수 있다.
- customer_package 테이블은 customer_id와 package_id를 묶어주는 역할
- 이 테이블을 통해 어떤 고객이 몇 개의 여행 상품을 구매했는지 또는, 어떤 여행 상품이 몇 명의 고객을 가지고 있는지 등을 확인할수 있다.
- 조인 테이블을 생성하더라도, 조인 테이블을 위한 기본키(여기서는 cp_id)는 반드시 있어야 한다.
- N:N(다대다) 관계를 위해 스키마를 디자인할 때에는, Join 테이블을 만들어 관리
**자기참조 관계(Self Referencing Relationship)**

- 때로는 테이블 내에서도 관계가 필요, ex) 추천인이 누구인지 파악할때
- user_id가 기본키
- 한명의 유저가 한명의 추천인 or 여러명이 한명의 추천인을 등록가능
**SQL 내장함수**
**집합연산**
- **레코드를 조회하고 분류한 뒤, 특정 작업을 하는 연산**
**GROUP BY**
// 그룹에 대한 작업없이 조회만해서 쿼리의 결과로 나타나는 데이터는 각그룹의 첫번째 데이터만포함
SELECT * FROM customers
GROUP BY State;**HAVING**
- GROUP BY 로 조회된 결과를 필터링할 수 있다.
- HAVING은 그룹화한 결과에 대한 필터이고, WHERE는 저장된 레코드를 필터링
SELECT CustomerId, AVG(Total)
FROM invoices
GROUP BY CustomerId
HAVING AVG(Total) > 6.00**COUNT()**
- 레코드의 갯수를 헤아릴 때 사용
//각그룹의 첫번째 레코드와 각 그룹의 레코드 갯수 집계하여 리턴
SELECT *, COUNT(*) FROM customers
GROUP BY State;
// 그룹으로 묶인 결과의 레코드 갯수 확인가능
SELECT State, COUNT(*) FROM customers
GROUP BY State;**SUM()**
레코드의 합을 리턴
SELECT OrderID, SUM(Quantity)
FROM OrderDetails
GROUP BY OrderID;AVG()
레코드의 평균값 계산
SELECT TrackId, AVG(UnitPrice)
FROM invoice_items
GROUP BY TrackId;**MAX(), MIN()**
레코드의 최대값, 최소값 리턴
SELECT CustomerId, MIN(Total)
FROM invoices
GROUP BY CustomerId**SELECT 실행 순서**
위에서 아래 순서로 동작
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
SELECT CustomerId, AVG(Total)
FROM invoices
WHERE CustomerId >= 10
GROUP BY CustomerId
HAVING SUM(Total) >= 30
ORDER BY 2FROM invoices: invoices 테이블에 접근을 합니다.WHERE CustomerId >= 10: CustomerId 필드가 10 이상인 레코드들을 조회합니다.GROUP BY CustomerId: CustomerId를 기준으로 그룹화합니다.HAVING SUM(Total) >= 30: Total 필드의 총합이 30 이상인 결과들만 필터링합니다.SELECT CustomerId, AVG(Total): 조회된 결과에서 CustomerId 필드와 Total 필드의 평균값을 구합니다.ORDER BY 2:AVG(Total)필드를 기준으로 오름차순 정렬한 결과를 리턴합니다.
**데이터베이스 정규화**
**Data Redundancy(데이터 중복)**
- 실제 데이터의 동일한 복사본이나 부분적인 복사본
- 데이터를 복구할 때에 더 수월할 수도 있겠지만 데이터베이스 내에서는 몇가지 문제점들을 지닌다.
- 일관된 자료 처리의 어려움
- 저장 공간 낭비
- 데이터 효율성 감소
**Data Integrity(데이터 무결성)**
- 데이터의 수명 주기 동안 정확성과 일관성을 유지
- 입력된 데이터가 오염되지 않고 입력된 그대로 데이터를 사용할 수 있다
**Anomaly(데이터 이상 현상)**
- 데이터에서 기대한 것과 다른 이상 현상
- 갱신 이상 (update anomaly)
- 동일한 데이터가 여러 행 (레코드) 에 걸쳐 있을 때에 어느 데이터를 갱신해야 하는지에 대한 논리적 일관성이 없어 발생
- 삽입 이상 (insertion anomaly)
- 데이터 삽입을 못하는 경우
- 삭제 이상 (deletion anomaly)
- 데이터의 특정 부분을 지울 때에 의도치 않게 다른 부분들도 함께 지워지는 이상 현상
**SQL 종류**
**Data Definition Language(DDL)**
- 데이터를 정의할 때 사용하는 언어
테이블 생성 CREATE , 삭제 DROP
**Data Manipulation Language(DML)**
- 데이터를 저장할 때 사용하는 언어
데이터 추가INSERT , 삭제 DELETE, 변경UPDATE
**Data Control Language(DCL)**
- 데이터베이스에 대한 접근 권한
- 어느 유저가 데이터베이스에 접근할 수 있는지 권한을 설정
권한을 주는 GRANT 가져가는 REVOKE
**Data Query Language(DQL)**
- 정해진 스키마 내에서 쿼리할 수 있는 언어
SELECT
**Transaction Control Language(TCL)**
- DML을 거친 데이터의 변경사항을 수정
COMMITDML이 작업한 내용을 데이터베이스에 커밋ROLLBACK커밋했던 내용을 다시 롤백
**SQL Advanced**
**CASE**
// if문과 같다.
SELECT CASE
WHEN CustomerId <= 25 THEN 'GROUP 1'
WHEN CustomerId <= 50 THEN 'GROUP 2'
ELSE 'GROUP 3'
END
FROM customers**SUBQUERY**
- 쿼리문을 작성할 때, 다른 쿼리문(서브쿼리) 포함가능
- 실행되는 쿼리에 중첩으로 위치해, 정보를 전달
- 서브쿼리는 소괄호로 감싸야한다.
- 서브쿼리의 결과는 개별 값이나 레코드 리스트
- 서브쿼리의 결과를 하나의 칼럼으로 사용가능
SELECT CustomerId, CustomerId = (SELECT CustomerId FROM customers WHERE CustomerId = 2)
FROM customers
WHERE CustomerId < 6**IN, NOT IN**
- 특정한 값이 서브쿼리에 있는지 확인
SELECT *
FROM customers
WHERE CustomerId IN (SELECT CustomerId FROM customers WHERE CustomerId < 10)**EXISTS**
- EXISTS 또는 NOT EXISTS는 돌려받은 서브쿼리에 존재하는 레코드를 확인
- 조회하려는 레코드가 존재한다면 참(TRUE)을, 그렇지 않은 경우에는 거짓(FALSE)을 리턴
SELECT EmployeeId
FROM employees e
WHERE EXISTS (
// 서브 쿼리문에 SELECT 1을 하게 되면 해당 조건을 만족하면 1을 반환하고
// EXISTS는 해당 로우가 존재하는지의 여부만 확인한 후 TRUE이면 메인 쿼리문을 수행
SELECT 1
FROM customers c
WHERE c.SupportRepId = e.EmployeeId
)
ORDER BY EmployeeId**FROM**
SELECT *
FROM (
// 쿼리문과 서브쿼리를 사용해 조회된 결과를 하나의 테이블이나 조회할 대상으로 지정해 사용
SELECT CustomerId
FROM customers
WHERE CustomerId < 10
)**제약 조건(constraint)**
정규화& 역정규화
[DB] 📚 제 1-2-3 정규화 & 역정규화 💯 정리
CASCADE
CASCADE는 부모 테이블의 row 에DELETE또는UPDATE명령어를 적용할 때, 자동적으로 자식 테이블의 매치되는 row 에도 똑같이DELETE또는UPDATE를 반영하는 것을 의미- foreign key constraints 옵션에
ON DELETE CASCADE를 설정 ON DELETE CASCADE옵션을 적용하면 부모 테이블에서 row 를 삭제할 경우 연결된 자식 테이블의 row 가 함께 삭제- 연결된 데이터를 한 번에 지울 수 있어 데이터의 관리가 편리해지고 일관성을 유지
- 테이블을 생성할 때 적용. 만약 이미 테이블이 생성되었다면,
ALTER TABLE
명령어를 활용해 기존의 foreign key 부분을 지웠다가 다시 생성하는 방식으로 사용할 ON UPDATE CASCADE를 설정하면UPDATE를 할 때CASCADE옵션이 적용
참조:
ON DELETE CASCADE (feat. foreign key 로 연결된 row 한 번에 지우는 방법) (TIL 78일차)
어려운 내용(에러)
비즈니스 로직(Business logic)
- 컴퓨터 프로그램에서 실세계의 규칙에 따라 데이터를 생성·표시·저장·변경하는 부분
- 업무에 필요한 데이터 처리를 수행하는 응용프로그램의 일부
- 데이터 입력, 수정, 조회 등 뒤에서 일어나는 각종처리(데이터를 가공하여 처리하고 유효성을 체크하고 트랜잭션을 거는등)
- 유전의 눈에 보이지는 않지만, 유저가 바라는 결과물을 올바르게 도출할 수 있게 짜여진 코드 로직
//예시
회원이 작성한 아이디 값 저장하기 -> 회원정보가 있는 데이터베이스 연결 ->
데이터베이스에 회원이 작성한 아이디 값이 있는지 Select->
회원의 아이디가 이미 있는지 없는지 여부를 데이터화 하여 저장 ->
데이터베이스 연결 끊기 -> View영역에게 가공된 데이터 전달출처:
[개발자로 홀로 서기:티스토리]
ERD 모델링

백엔드 개발자