목차
- TCP/IP
- UDP
- PORT
- DNS
- URL , URI
- 2-TIER, 3-TIER 아키텍쳐
- SSR, CSR
- CORS
- AJAX
배운 내용
네이티브 애플리케이션
- 특정기기(모바일,PC)에 설치해서 사용하는 애플리케이션
- Apple iOS, Android OS, Windows 와 같은 특정 실행환경에 종속
장점
- 웹애플리케이션보다 빠르다.
- 애플리케이션이 설치된 기기의 시스템/기기의 리소스에 접근이 용이
- 인터넷 없이 사용가능
- 웹애플리케이션에 비해 안전(모바일의 경우 앱스토어에 승인을 받아야 하기때문)
단점
- 개발비가 더 들어간다(IOS와 Android 간의 멀티플랫폼 개발등)
- 빠른 업데이트가 힘듬
- 앱스토어 에 승인 받기가 힘들고 비용이 발생
웹 애플리케이션
- 정적인 웹사이트의 한계를 벗어나 다양한 동적인 응답을 웹 브라우저라는 소프트웨어를 통해 가능하게 한 애플리케이션
장점
- 브라우저를 통해 실행되기 때문에 설치나 다운로드가 필요 없다.
- 업데이트 등의 유지관리가 쉽다.
- 네이티브 애플리케이션에 비해 만들기가 비교적 간편하다.
단점
- 인터넷이 없으면 사용불가
- 네이티브 애플리케이션에 비해 속도가 느리다
- 애플리케이션 스토어에서 관리되지 않기 때문에 사용자 접근성이 떨어진다.
- 질적으로나 보안상 위험에 노출되기가 쉽다.
LAN & WAN
LAN(Local Area Network)
- 좁은 범위에서 연결된 지역 네트워크
- 이더넷 프로토콜 사용
WAN(Wide Area Network)
- 수많은 LAN들이 모여 세계의 네트워크 구성(광범위)
- LAN과 LAN사이를 연결
- LAN 이 WAN 으로 확장하기 위해서는 ISP[Internet Service Provider](KT, SKT)가 제공하는 각 거점을 연결하는 통신회선 서비스를 이용해야 한다. → 비용 지불
프로토콜(protocol)
- 컴퓨터들끼리 소통하기 위한 공통된 약속
TCP / IP
TCP/IP 4계층 모델
| TCP/IP 4계층 모델 | 주요 프로토콜 | 역할 | |
|---|---|---|---|
| 4층 | 응용 계층 | HTTP, DNS, FTP… | 애플리케이션에 맞추어 통신 |
| 3층 | 전송 계층 | TCP, UDP, … | IP와 애플리케이션을 중개해 데이터를 확실하게 전달 |
| 2층 | 인터넷 계층 | IP, ICMP, ARP, RARP | 네트워크 주소를 기반으로 데이터 전송 |
| 1층 | 네트워크 접근계층 | Ethernet, wifi .. | 컴퓨터를 물리적으로 네트워크에 연결해서 기기간에 전송이 가능하게 한다. |
IP address
- Internet Protocol address(IP 주소) : 네트워크에 연결된 특정 PC의 주소를 나타내는 체계
- Private IP : LAN 네트워크 내부에서 사용
- Public IP : 인터넷에서 사용
- localhost, 127.0.0.1 : 현재 사용 중인 로컬 PC를 지칭
- 0.0.0.0, 255.255.255.255 : broadcast address, 로컬 네트워크에 접속된 모든 장치와 소통하는 주소
IPV4 vs IPV6
- IPv4 주소 형식 : 192.168.1.1 의 10진수
- 32 4개의 8비트 필드로 구성
- IPv6 주소 형식 : 2002:0221:ABCD:DCBA:0000:0000:F:FFFF:4002
- 128비트 16비트씩 8부분으로 16진수로 ㅛ시
MAC 주소
- 네트워크 기기는 처음부터 제조사에서 할당하는 고유 시리얼인 MAC 주소를 IP 주소와 조합해야만 네트워크를 통한 통신이 가능
- 이더넷에서는 네트워크상의 송수신 상대를 특정하고자 MAC 주소를 사용
- TCP/IP 에서는 IP address를 사용
- ARP(address resolution protocol) : 같은 LAN 에 속한 기기끼리 통신하려고 상대방의 MAC 주소를 파악하기위해 네트워크 전체에 브로드캐스트를 통해 패킷을 보내고, 해당 IP를 가지고 있는 컴퓨터가 자신의 MAC주소를 Response하게 됨의로써 통신할 수있게 해주는 프로토콜
기기간의 통신
회선 교환(Circuit Switching)
- 통신 회선을 설명하여 데이터 교환을 하는 방식
- 주로 음성전화 시스템에 사용
- 일대일로 데이터를 교환하고, 전화간 통화 중에는 다른 상대와 전화통화가 불가능
패킷 교환(Packet Switching)
- 원본 데이터를 패킷(packet) 이라고 하는 작은 단위로 나누고, 여러 회선을 공용해 통신을 주고 받는 방식
- 하나의 패킷은 헤더와 페이로드로 구성
- 헤더에는 어떤 데이터의 몇번째 데이터인지의 정보와 보내는 곳 이나 최종 목적지에 대한 정보가 들어있다.
- 도착한 곳에서 분할한 데이터 원래대로 복원
IP
IP 주소 구조
- IP 주소는 네트워크부와 호스트부로 분류
- 네트워크부 : 어떤 네트워크인지를 알 수 있는 정보
- 호스트부 : 그 네트워크 안의 특정 컴퓨터를 지칭하는 정보
- Mac주소와 달리, IP주소는 처음부터 주어지는것이 아니라 할당됨
서브넷 마스크(subnet mask)
- IPv4 주소에서 네트워크부가 어디까지인지 나타내는것
- 옥텟 : 8자리의 2진수 묶음 → IPv4주소는 4개의 옥텟
ex)
- IP 주소: 192.168.1.1
- 서브넷 마스크: 255.255.255.0
- 설명 : 1에서 3옥텟까지 네트워크부, 4옥텟이 호스트부
IP 프로토콜의 한계
비연결성
- 패킷을 받을 대상이 없거나 특정한 이유로 서비스 불능 상태에 빠져도 데이터를 받을 상대의 상태 파악이 불가능하기 때문에 패킷을 그대로 전송
비신뢰성
- 서로 다른노드를 거쳐서 전송되어 보내는 기기측에서 의도한 순서대로 데이터가 도착하지 않을 수 있다.
- 한 IP에서 여러 애플리케이션이 작동하는 경우 특정할 수 없다.
TCP, UDP
| TCP(Transmission control protocol) | UDP(User datagram protocol) | ||
|---|---|---|---|
| 서비스타입 | 연결 지향적 프로토콜 | 표적 기기까지의 전송이 보장되지 않는다. | |
| 순서 | 전송하는 패킷들이 순서가 보장됨 | 패킷순서 보장이 안된다. 패킷 순서를 보장하고 싶다면, 응용계층에서 관리되어야 한다. | |
| 속도 | 느린편 | 빠르고, 단순함 |
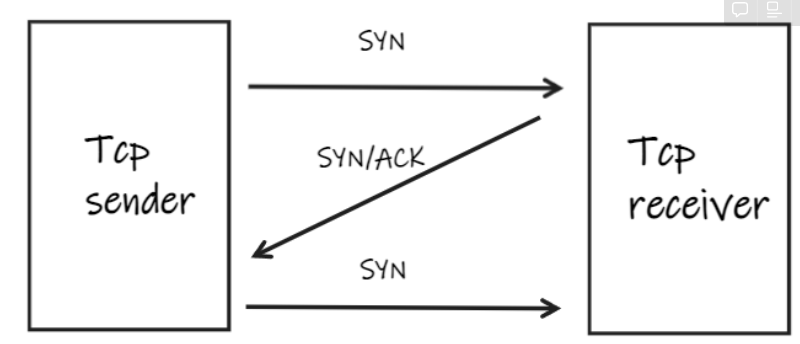
TCP 3Way-Handshake & 4 Way-Handshake
TCP 3Way-Handshake
- 데이터를 전송하기 전에 먼저 정확한 전송을 보장하기 위해 상대방 컴퓨터와 네트워크 연결을 설정(Connection Establish)하는 과정
STEP1 : Sender는 Segment를 랜덤으로 설정한 SYN(Synchronize Sequce Number)-연결요청 와 함께 보낸다.
STEP2 : Reciever는 요청 수락의 응답의 신호인 ACK와 연결요청인 SYN 패킷을 보냄
STEP3 : Sender는 요청받은 SYN에 대한 응답인 ACK를 보냄.
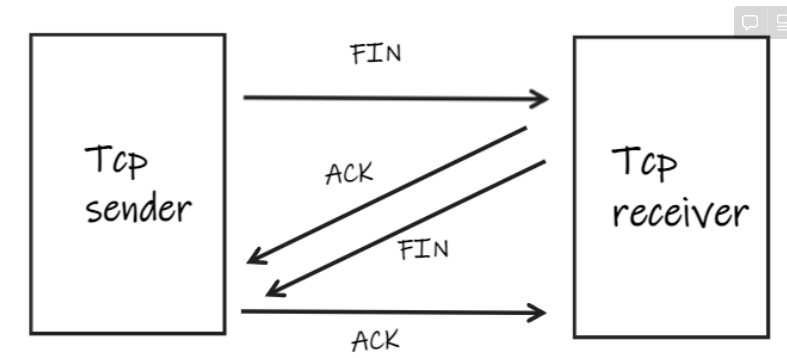
TCP의 4-Way Handshake
- 연결을 해제 (Connecntion Termination)하는 과정
STEP1 : Sender가 연결을 종료하겠다는 FIN플래그 전송
STEP2 : Reciever는 확인 메시지(ACK)를 보내고 자신의 통신이 끝날때까지 기다림(TIME_WAIT)
STEP3 : Reciever가 통신이 끄나면 연결이 종료되었다고 sender에게 FIN플래그 전송
STEP4: Sender가 확인 메시지 전송
UDP
사용이유
- 애플리케이션의 정교한 제어가능
- 실시간 전송에 대한 요구가 큰 애플리케이션 들은 높은 latency(지연시간)를 지양하므로 약간의 데이터 손실을 감수하고 사용
- 개발자 스스로가 이를 보완하기 위해 애플리케이션에 추가 기능을 구현가능
- 연결설정에 무관하다.
- 예비과정 없이 바로 전송을 시작 →반응속도가 빠르다.
- TCP 가 신뢰성을 위해 많은 파라미터와 정보 전달이 필요
- UDP는 연결설정 관리를 하지 않기 때문에 어떠한 파라미터도 기록안함 → 더 많은 클라이언트 수용가능
PORT
포트번호
- 대상 IP 기기의 특정 어플리케이션(connection endpoint)을 특정하는 번호
- 이미 사용중인 포트는 중복해서 사용불가
- 0~ 65,535 까지 사용가능
- 0~ 1023번까지는 주요통신을위한 규약에따라 이미 지정되어있다.
Well-known port
| 포트번호 | 프로토콜 이름 | 설명 |
|---|---|---|
| 80 | HTTP | 웹서버 접속 |
| 443 | HTTPS | 웹서버 접속(SSL) |
| 110 | POP3 | 메일 읽기 |
| 25 | SMTP | 메일서버간 메일 전송 |
| 22 | SSH | 컴퓨터 원격 로그인 |
| 53 | DNS | DNS 질의 |
| 123 | NTP | 시간 동기화 |
웹사이트보안
- SSL(Secure Sockets Layer): 보안 소켓 계층
- 웹사이트와 브라우저사이(or 두 서버 사이)에 전송되는 데이터를 암호화하여 인터넷 연결을 보호하기 위한 표준 기술
- 웹사이트와 브라우저사이(or 두 서버 사이)에 전송되는 데이터를 암호화하여 인터넷 연결을 보호하기 위한 표준 기술
- TLS(Transport Layer Security) : 전송 계층 보안
- SSL의 향상된 버전
URL, DNS
URL(Uniform Resource Locator)
- 인터넷상에서 HTML이나 이미지,동영상 등 리소스가 위치한 정보를 나타낸다.
- 서버가 제공되는 환경에 존재하는 파일의 위치를 나타냄
- scheme, host, url-path로 구성
URI(Uniform Resource Identifier)
- url + query, bookmark
- URI는 URL을 포함하는 상위 개념
| 부분 | 명칭 | 설명 |
|---|---|---|
| file://, http://, https:// | shceme | 통신 프로토콜 |
| 127.0.0.1, www.google.com | hosts | 웹 페이지, 이미지, 동영상 등의 파일이 위치한 웹서버, 도메인 또는 IP |
| :80, :443, :3000 | port | 웹 서버에 접속하기 위한 통로 |
| /search, Users/username/Desktop | url-path | 웹 서버의 루트 디렉토리로부터 웹페이지, 이미지, 동영상 등의 파일위치까지의 경로 |
| q=Java | query | 웹 서버에 전달하는 추가 질문 |
DNS(Domain Name System)

- 호스트의 도메인 이름을 IP주소로 변환하거나 반대의 경우를 수행하는 데이터베이스 시스템
- localhost를 제외한 모든 도메인 이름은 일정기간 동안 대여하여 사용
- 도메인주소는 오른쪽부터 왼쪽으로 최상위 도메인과 여러개 도메인으로 구성
- Registry는 도메인 관리 기관, 각 도메인 정보의 데이터 베이스 관리
- Registrar는 중개 등록업체, Registry의 데이터베이스에 직접 도메인정보 등록 가능
종류
- Root Domain
- Top Level Domain(TLD) :
.com, .kr, .net등 도메인의 가장 오른쪽에 위치 - Sub Domain :
www(기본), m(모바일), store(스토어)와 같은 제일 왼쪽에 위치하며 도메인에 따라 사이트 구성이 달라짐
Domain Name Server(zone)
- 안정성을 위해 최소 두개이상의 서버가 하나의 도메인 네임 담당
- Root 네임 Server
- 최상위 도메인 네임 서버들의 주소를 알고 있다
- TLD 네임 서버
- 권한 있는 네임 서버의 주소를 알고있다.
- 권한 있는 네임 서버
- 도메인 IP 주소 및 도메인 정보를 관리하는 권한을 가진 서버
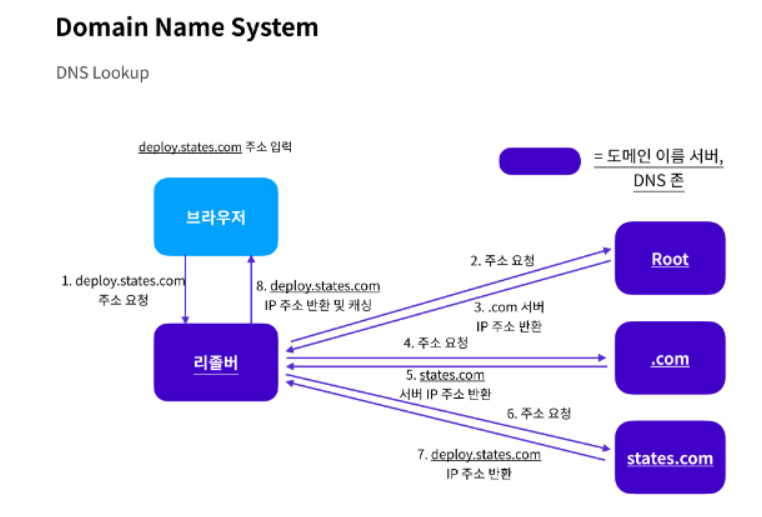
- 리졸버는 요청받은 도메인의 IP 주소를 찾기 위해 여러 네임 서버에 반복적인 질의를 하는 네임서버
- 리졸버는 우선 기존에 찾아본 도메인 정보가 내용이 담긴 캐시 파일을 살펴봅니다.
해당되는 도메인 정보가 있다면 즉시 IP 주소를 리턴 - 해당되는 도메인 정보를 찾을수 없는 경우 2번을 진행
-
DNS 리졸버는 IP 주소를 얻기 위해 네임 서버들에게 재귀적인 쿼리를 진행
루트, 탑 레벨, 권한 있는 도메인 서버에 차례대로 쿼리를 진행하며 IP 주소를 알아냄
리졸버는 쿼리수를 줄일 목적으로 기록되지 않은 도메인 네임 서버들의 주소를 저장하기도함
-
마지막으로 리졸버는 전달받은 deploy.states.com의 IP 주소를 기록하고 브라우저에게 전달
레코드 상세 정보
- 이름
- 도메인 네임 or 서브 도메인 이름 저장
- 레코드 클래스
- 네트워크 타입 지정
- TTL(Time To Live)
- 리졸버가 레코드를 몇 초 동안 저장할지 명시
- 해당 시간이 지나면 해당 레코드 삭제
웹
- 인테넷에서 제공되는 하이퍼텍스트 시스템
- 하이퍼텍스트(HyperText) : 문서안에 다른 문서의 위치정보 등을 포함하여 문서 간의 정보를 서로 연관 지어 참조 할 수 있는 문서
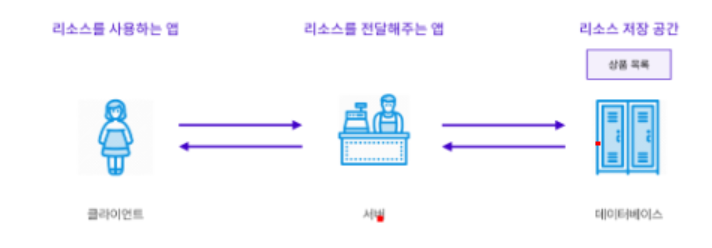
클라이언트 -서버 아키텍처(2-Tier Architecture)
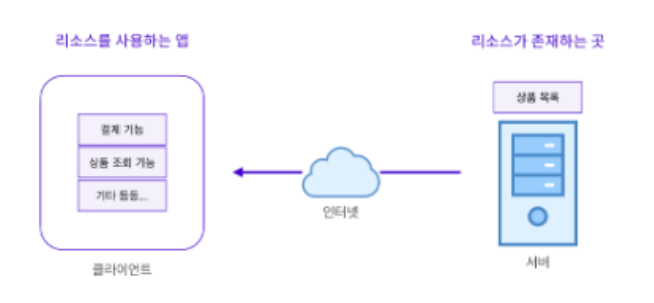
- 서비스를 이용하는(클라이언트)와 서비스를 제공하는(서버)로 나누는 구조
- 클라이언트 - 사용자가 직접 이용 → 사용 편의성이나 휴대성 고려해 개발
- 서버 - 사용자와 직접적 접점이 없기 때문에 편의성 보다는 기능에 중점을 두고 개발
- 인터넷 연결 없이 쇼핑몰앱이 작동되지 않은 이유
- 상품 정보를 인터넷 어딘가에 존재하는 서버로부터 받아와야 하기때문
- 빈번한 데이터 업데이트가 필요한 경우, 리소스가 존재하는 곳과 리소스를 사용하는 앱을 분리시키는 것이 유리
- 리소스가 존재하는 곳(서버)과 리소스를 사용하는 앱(클라이언트)을 분리시킨 것을 2티어 아키텍처 라고 한다.
3 Tier-Architecture
사용자가 직접 눈으로 보고, UI를 클릭 또는 터치하는 등의 상호작용을 할 수 있는 앱을 주로 개발하면 프론트엔드 개발자
사용자 눈에 보이지 않지만, 상품 정보를 API로 노출한다든지, 로그인/로그아웃, 권한 관리 등의 사용자 인증을 주로 다루는 개발자는 백엔드 개발자
데이터베이스 등의 시스템 설계도한다.
웹 애플리케이션 아키텍쳐
-
website : 정적 페이지들의 집합체
-
web application : 웹사이트가 정적 페이지들 뿐 아니라 동적 페이지를 포함하고있다.
- 데스크탑 애플리케이션처럼 상호작용 가능
- 특정 기능을 가지고 있다(정보 검색)
- 정보나 자료 등의 콘텐츠 관리 시스템과 함께 작동
-
오늘날 만들어지는 대부분의 웹사이트들은 사실 엄밀하게 이야기 하면 웹 애플리케이션들이다
-
애플리케이션 아키텍처는 내부 요소들이 상호작용을 유지할 수 있도록 서로를 결부시키는 뼈대라고 볼수 있다.
웹 애플리케이션 요청흐름
- 브라우저에
https://urclass.codestates.com를 입력합니다. - 브라우저는 URL을 입력 받으면 서버의 주소를 찾기 위해 DNS 서버에 요청을 보냅니다.
- IP 주소를 찾으면 해당 주소에 HTTPS 요청을 보냅니다. 이미 방문 기록이 캐시 메모리에 있으면 주소를 캐시 메모리에서 가져옵니다.
- 웹서버에 요청이 도착 합니다.
- 웹서버는 저장소에 요청을 보내 페이지 관련 데이터들을 가져옵니다.
- 정보들은 가져오는 중에 비지니스 로직이 작용합니다.
- 비지니스 로직들은 각 데이터들을 어떻게 다룰지가 정해져 있습니다.
- 로직들을 통해 요청 받은 데이터들이 처리되고 브라우저에 응답합니다.
- 요청들이 브라우저에 응답으로 돌아왔을 때, web page 화면에서 출력됩니다.
모든 애플리케이션은 client-side 와 server-side로 작동
• 유저의 입 력에 따라 브라우저에서 작동하는 프로그램 → front-end 개발
• HTTP 요청에 따라 서버에서 요청 처리하는 프로그램 → back-end 개발
웹 애플리케이션의 요소
- 유저 인터페이스와 유저 경험과 관련된 요소
- 구조 요소 - 기능적인 부분담당
웹 애플리케이션의 3단계 계층 구조

- Presentation Layer: 이 계층은 유저와 브라우저 등을 이용해 직접적으로 접촉을 합니다. Web Server가 이 영역에 포함되며, 유저 인터페이스 요소들을 포함합니다.
- Application Layer: Business Layer, Business Logic 혹은 Domain Logic 이라고 불리기도 하는 이 영역은 유저의 요청을 브라우저로부터 받아서 처리를 합니다. Application Server가 이 계층에 포함되며 또한, 데이터 접근을 위한 경로를 규격화 하는 등의 과정이 이 계층에 작성이 됩니다.
- Data access layer: Persistence layer 라고도 불리는 이 계층은 애플리케이선의 데이터 저장소에 접근하여 데이터를 불러 오거나 저장을 담당 합니다. Application Layer 는 이 계층과 밀접한 연관을 가지고 있습니다. 이 단계를 통해 Application Layer 의 로직들은 어느 데이터베이스에 접근해서 데이터를 회수하고 혹은 저장할지를 더 최적화 할 수 있습니다.
- 주 3계층 외 구조요소
- Cross-cutting: 이 요소들은 주로 보안, 통신, 운영 관리등을 위한 요소
- Third-party integrations: 제 3의 API 서비스를 이용, OAuth 2.0을 이용한 소셜 로그인, PG 사를 이용한 결재기능 등
Web Server와 WAS 차이
Web Server와 Web Application Server
웹 애플리케이션의 구현
구현방식
Single Page Application (SPA)
- 웹페이지에서 일부분만교체
- 유저의 입력과 요청에 의한 콘텐츠나 정보의 최신화가 페이지를 새로 불러오지 않고 현재 페이지에서 이루어진다. →요청한 응답을 기다리면서 페이지와 상호작용이 가능
- 직관적으로 알기 쉽고 상호작용 가능한 요소들을 이용해 유저 경험을 극대화
- AJAX , XML이 주로 사용
Microservice architecture (MSA)
- 작고 가벼운 특정한 한가지 기능에 집중한 웹 애플리케이션
- 각 애플리케이션의 기능 요소들은 상호간에 의존적으로 설계되지 않는다. → 개발단계 그리고 개발 완성이후로도 같은 개발 언어를 사용할 필요가 없다.
- 개발자는 원하는 언어를 사용해 기능 개발에 유연성을 더 갖게 되고. 개발 과정의 전반적인 속도와 생산성이 향상
Serverless Architectures
- 개발자가 웹 애플리케이션의 서버와 기타 기반 기능들에 대해 외부의 3자인 클라우드 서비스 제공자에게 의탁하는 방식
Cookie 와 Session
- 쿠키: 웹 애플리케이션을 사용하는 유저의 정보를 클라이언트에 보관하고, 다음 접속부터는 유저의 정보를 클라이언트가 서버로 보내서 유저를 서버가 식별하게 합니다. 쿠키에 담긴 내용으로 웹 애플리케이션에 유저가 설정했던 항목들에 대해 저장을 해서 다음에 이어서 같은 방식으로 작동하게 도와줍니다.
- 세션: 세션의 경우 서버에 Session-Id 라는 고유 아이디를 할당해서 유저를 식별합니다. 단순하고 유출이 되면 안되는 정보는 서버에서 관리를 하면서 세션 ID와 매칭해서 저장해 관리합니다. 주로 사용되는 방법은, 세션정보는 쿠키에서 관리하고, 실제 매칭되는 값들은 서버 측에서 관리하는 것이 일반적입니다.
SSR (Server Side Rendering)
- Javascript 가 웹 페이지를 브라우저에서 렌더링하는 대신에, 서버에서 완전히 렌더링한 후에 브라우저에 전송
- 브라우저가 다른 경로로 이동할 때마다 서버는 이 작업을 다시 수행해야 한다.
- SEO(Search Engine Optimization) 가 우선순위인 경우 사용
- 웹 페이지의 첫 화면 렌더링이 빠르게 필요한 경우, 단일 파일의 용량이 작은 SSR 이 적합
- 웹 페이지가 사용자와 상호작용이 적은 경우, SSR 을 활용
- 자원이용이 서버에 집중되기 때문에 애플리케이션 유지비용이 높다
- ex) 네이버 블로그, 뉴욕 타임즈
CSR(Client Side Rendering)
- 클라이언트(브라우저)에서 Javascript 가 페이지를 렌더링
- 브라우저의 요청을 서버로 보내면 서버는 웹 페이지를 렌더링하는 대신, 웹 페이지의 골격이 될 단일 페이지와 JavaScript를 클라이언트에 전송
- 클라이언트가 웹 페이지를 받으면, 웹 페이지와 함께 전달된 JavaScript 파일은 브라우저에서 웹 페이지를 완전히 렌더링 된 페이지로 바꾼다.
- 웹페이지에 필요한 내용이 데이터베이스에 저장된 데이터일 경우
- 웹 페이지를 렌더링하는 데에 필요한 데이터를 API 요청으로 해결
- 브라우저는 브라우저가 요청한 경로에 따라 페이지를 다시 렌더링 이때 보이는 웹 페이지의 파일은 맨 처음 서버로부터 전달받은 웹 페이지 파일과 동일한 파일 페이지를 새로고침 하지 않고, 동적으로 라우팅을 관리
- 사이트에 풍부한 상호 작용이 있는 경우, CSR 은 빠른 라우팅으로 강력한 사용자 경험을 제공
- 느린 렌더링 속도로 사용자 경험이 안 좋아 질 수 있다.
- 모든 렌더링의 부하가 클라이언트 쪽에 집중되기 때문에 사용자에 따라서 경험이 달라질 수 있다.
- search engine bots 와 상성이 안좋습니다. Javascript가 렌더링해야 하는 정보들은 Google 과 같은 search engine index에 포함이 안될 가능성이 매우 높다.
- ex) 아고다
AJAX
AJAX(Asynchronous JavaScript And XMLHttpRequest)
- JavaScript, DOM, Fetch, XMLHttpRequest, HTML등 다양한 기술을 사용하는 웹개발 기법
- 웹 페이지에 필요한 부분에 필요한 데이터만 비동기적으로 받아와 화면에 그려낼 수 있다
무한스크롤 이벤트
-
무한 스크롤이 발생할 때마다 Fetch를 통해 데이터를 가져와서 업데이트하고 렌더링한다.
-
원티드 탐색 페이지에서 사용자가 채용 공고 목록 페이지의 맨 밑까지 스크롤 하여 스크롤바 하단에 도달하면, 새로운 채용 공고를 서버로부터 가져와 렌더링
-
전통적인 웹 애플리케이션에서는
<form>태그를 이용해 서버에 데이터를 전송하고 서버는 요청에 대한 응답으로 새로운 웹페이지를 제공해주어야 했다 -
Fetch를 사용하면, 페이지를 이동하지 않아도 서버로부터 필요한 데이터를 받아올 수 있다.
-
Fetch는 사용자가 현재 페이지에서 작업을 하는 동안 서버와 통신할 수 있도록 한다.
-
자바스크립트에서 DOM을 사용해 조작할 수 있기 때문에, Fetch를 통해 전체 페이지가 아닌 필요한 데이터만 가져와 DOM에 적용시켜 새로운 페이지로 이동하지 않고 기존 페이지에서 필요한 부분만 변경가능
-
Fetch 이전에는 XHR(XMLHttpRequest)를 사용했습니다. Fetch는 XHR의 단점을 보완한 새로운 Web API이며, XML보다 가볍고 JavaScript와 호환되는 JSON을 사용, 간편하고 promise 지원받음
// Fetch를 사용
fetch('http://52.78.213.9:3000/messages')
.then (function(response) {
return response.json();
})
.then(function (json) {
...
});AJAX의 장점
- AJAX를 사용하면 서버에서 완성된 HTML을 보내주지 않아도 필요한 데이터를 비동기적으로 가져와 브라우저에서 화면의 일부만 업데이트하여 렌더링 할 수 있습니다.
- 유저 중심 애플리케이션 개발 AJAX를 사용하면 필요한 일부분만 렌더링하기 때문에 빠르고 더 많은 상호작용이 가능한 애플리케이션을 만들 수 있습니다.
- 더 작은 대역폭 : 네트워크 통신 한 번에 보낼 수 있는 데이터의 크기 이전에는 서버로부터 완성된 HTML 파일을 받아와야 했기 때문에 한 번에 보내야 하는 데이터의 크기가 컸습니다. 그러나 AJAX에서는 필요한 데이터를 텍스트 형태(JSON, XML 등) 보내면 되기 때문에 비교적 데이터의 크기가 작습니다.
4. AJAX의 단점
- Search Engine Optimization(SEO)에 불리 AJAX 방식의 웹 애플리케이션은 한 번 받은 HTML을 렌더링 한 후, 서버에서 비동기적으로 필요한 데이터를 가져와 그려냅니다. 따라서, 처음 받는 HTML 파일에는 데이터를 채우기 위한 틀만 작성되어 있는 경우가 많습니다.
동기 비동기
- URL에 구성 중 origin을 구분하는 기준은 "프로토콜", "호스트(도메인)", "포트 번호
문제
해결
