✍️Encoding, 🔖Decoding
Encoding 이라 함은 data를 일련의 과정을 통해서 디지털한 컴퓨터 데이터 형태로 변경하는 것을 말한다. 그리고 이를 다시 복원 해내는 과정은 Decoding 이라고 한다. 이 개념은 인공지능 이전에도 굉장히 많이 쓰였고 당장 우리 주변에서 보이는 Encoding, Decoding 과정이라 함은 암호화, 압축 등이 있다.
머신러닝에서의 Encoding과 Decoding도 별반 다르지 않다. Encoding은 Feature Extraction과 유사하여 크기는 줄어들지만 그 의미하는 바는 동일하고 그리고 데이터도 동일하다. 그리고 Decoding은 앞에서 진행한 Feature Extraction 과정을 다시 원본과 동일한 형태로 복원을 해내는 형태이다.
본격적인 Auto-Encoder 🤓
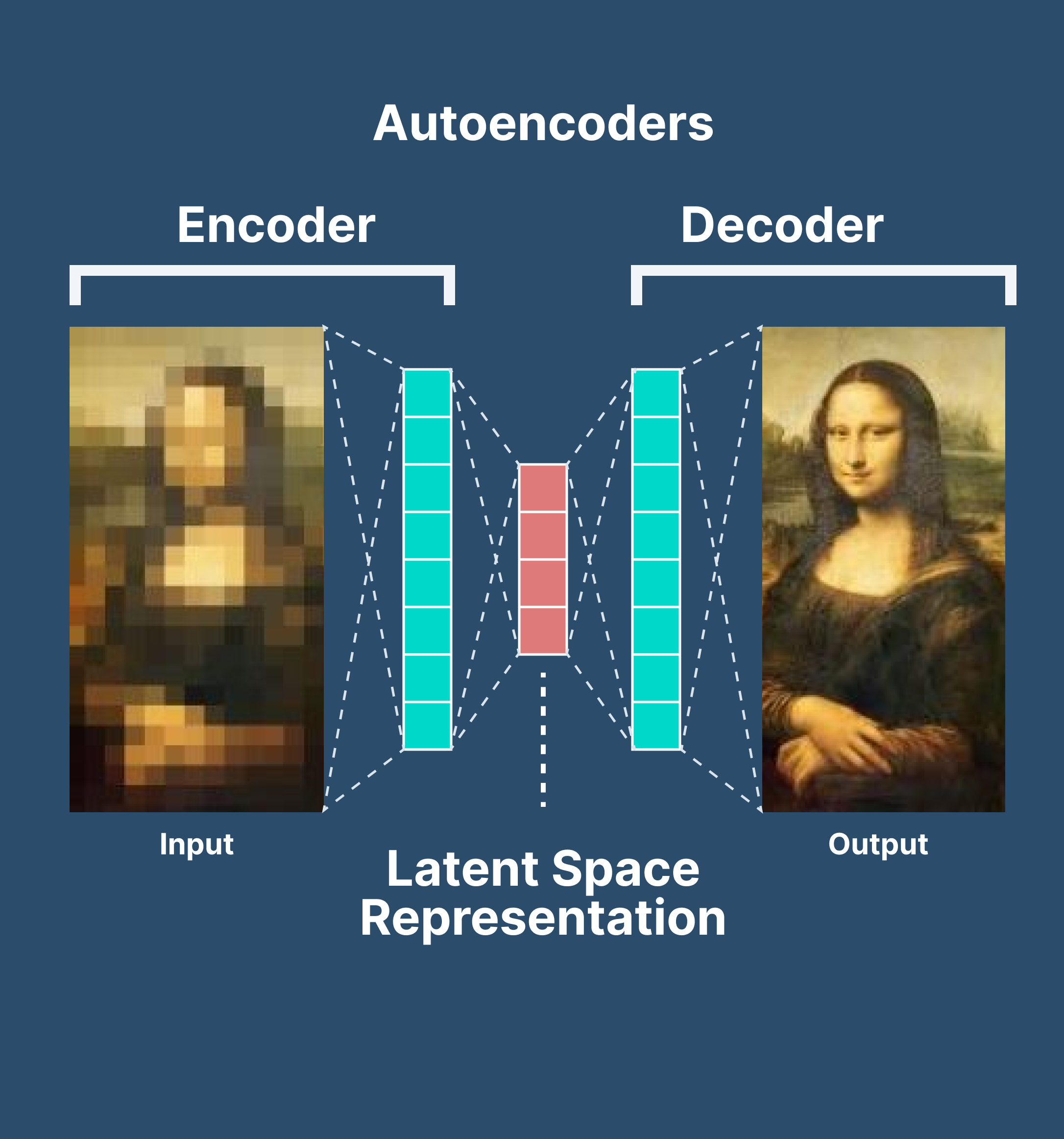
위 사진에서 보여지는 것으로 Encoder는 이미지를 읽고 Feature 를 잡아내는 역할을 하게 된다. 반대로 Decoder는 잡아낸 Feature를 통해서 다시 복원해내는 방식이다. 이 과정을 거치면서 모델에 제약, 노이즈 등을 주면서 학습에 방해를 주고 괴롭히게 되면 단순 복사, 붙여놓기가 아닌 데이터의 형태를 올바르게 잡아갈 수 있도록 한다.
이번 글에서는 Auto-Encoder와 유사하게 활용되는 U-Net을 통해 신경망에서의 Encoding, Decoding을 좀 더 파혜쳐 볼 예정이다.
U-Net 👽🌈
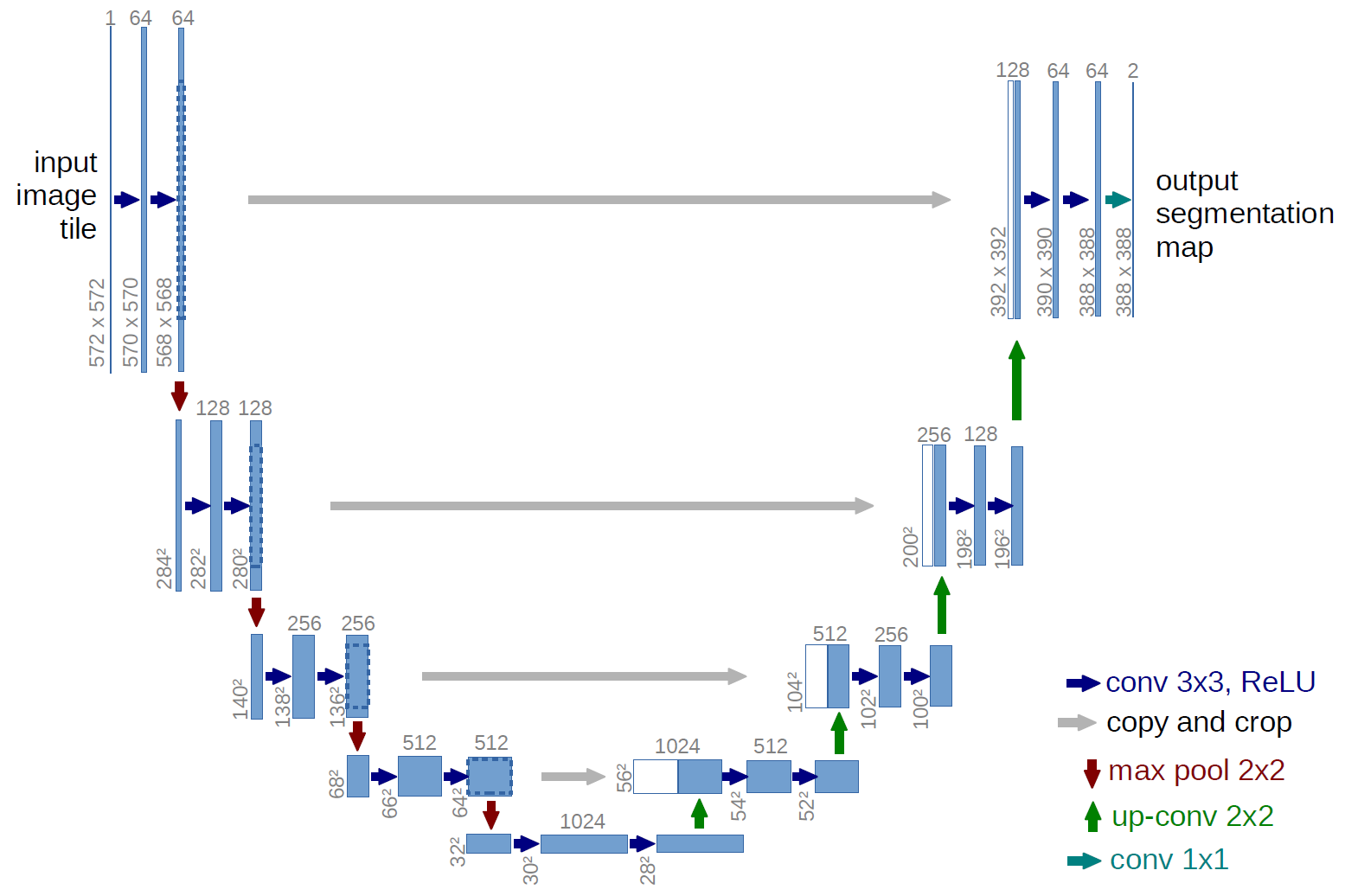
U-Net은 Image segmation 에서 쓰이는 모델로 input 이미지에서 '어느 부위가 ~~ 인거 같습니다.' 와 같은걸 표현하기 위해서 활용된다. 이름이 U-Net인 이유도 단순하다. 정말 U자 형태로 생겨서 그렇다. 모델의 구조를 보면 점차 채널의 크기가 작아지는 모습을 볼 수가 있다.
이 과정이 Encoding과 유사한데 그렇다면 어떻게 Decoding을 거치게 되는가? 물론 모델마다 다르다만 Decoding Block을 추가한다. Decoding block은 회색 화살표로 받는 이전 데이터와 그리고 새로 들어온 데이터를 합쳐서 원본 사이즈로 점차 늘려가는 과정을 일컷는다. 즉, 이전 형태를 보존함과 동시에 새로운 Feature를 통해서 새로운 이미지 복원을 만들어간다.
그렇게 되면 아래와 같은 결과를 얻게 된다.
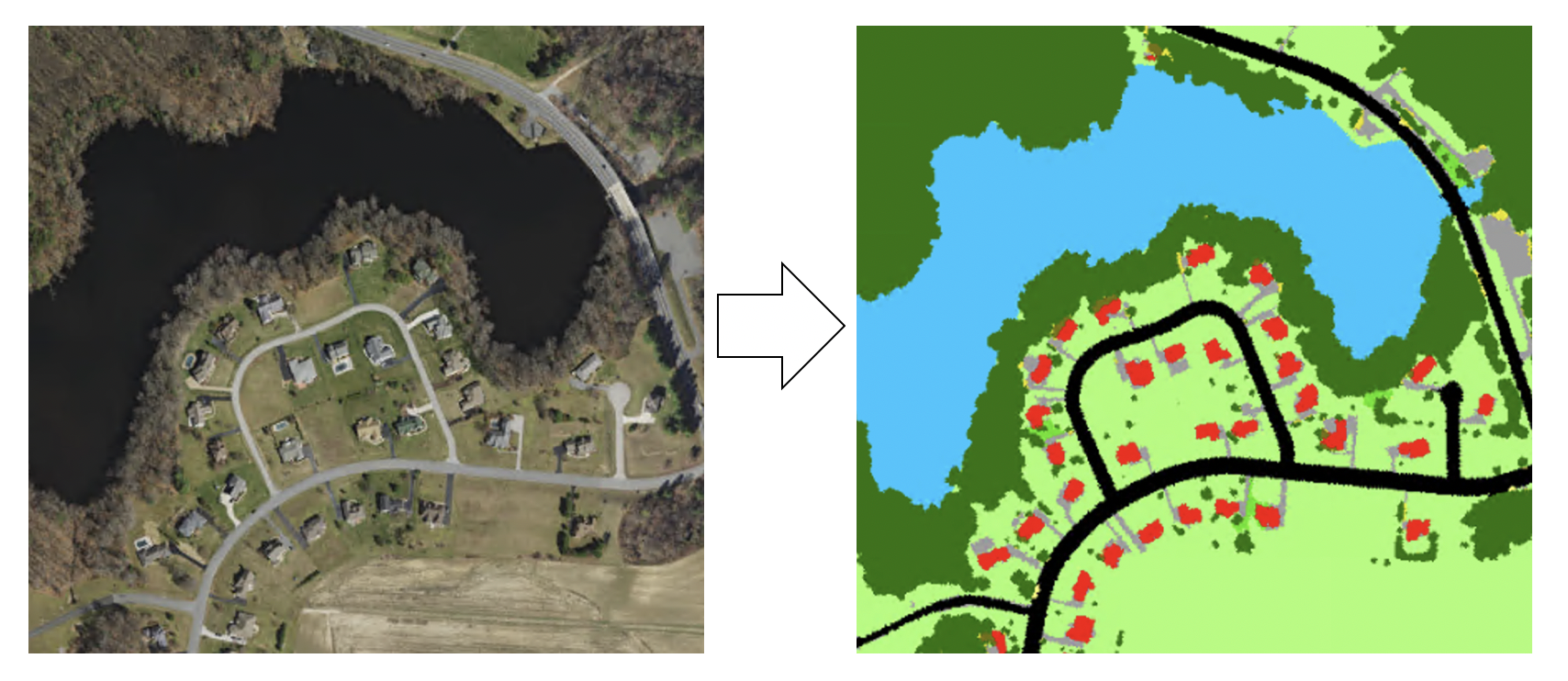
하지만 내가 궁금증이 되는 부분이 되게 많았다. 다른 논문들을 보다 보면 Softmax 를 통해 Classification을 한다고 나와있다. 그렇다면 AutoEncoding 과정을 거치면서 classification을 하게 되면 의미가 있는가?
궁금증 : AutoEncoder에서 왜, Softmax를? 🤔💭
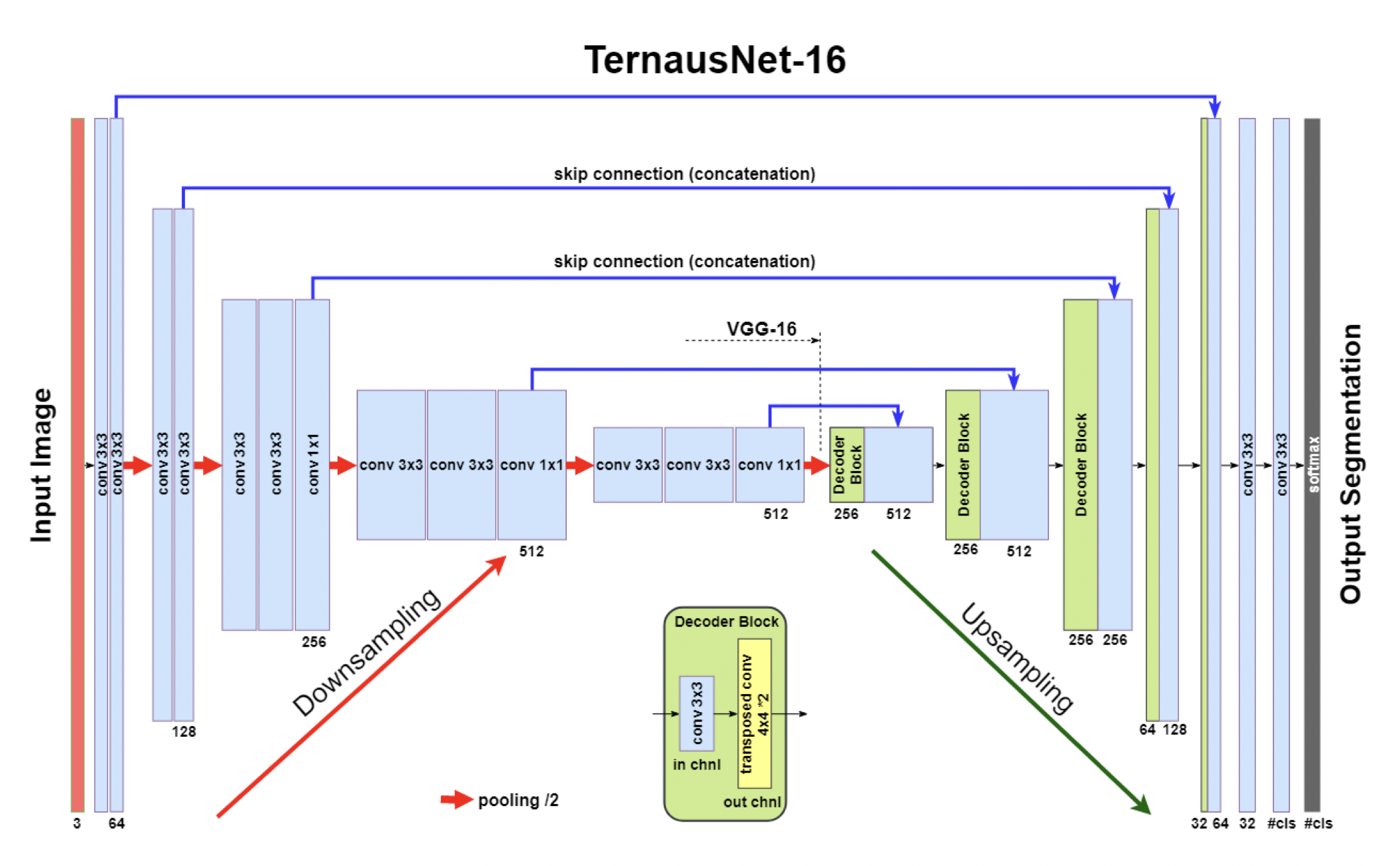
TernausNet-16 모델이다. U-Net 형태를 띄우고 있으며 Decoder block 이전 까지는 VGG-16 모델과 유사한 형태로 Encoding 을 거치게 된다. Feature Extraction과 동일하다고 생각해도 될거 같다.
그 전에 우리는 Softmax가 어떻게 결과를 뱉어내는지에 대해서도 생각해봐야한다. 기본적으로 Softmax는 N개의 클래스를 다 더하면 1이 되는 값을 뱉어내도록 하고 있다.식을 보는게 아니라 지금 내가 말하는거는 기능과 출력을 말하는거다. 그렇다면 저 위에서 나오는 Softmax의 역할은 각 픽셀의 정확도 혹은 확률을 말하는 것이다.
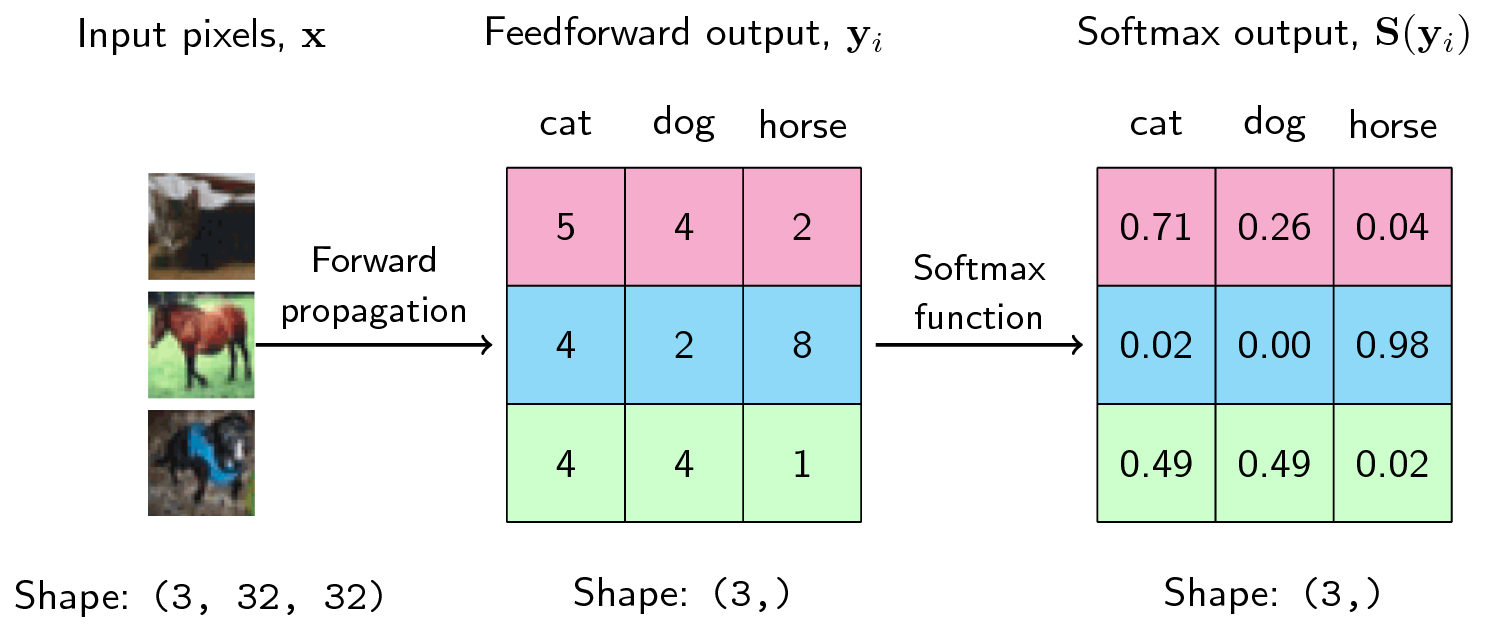
다크모드를 쓰고 있다면 안 보일거다... 위와 같이 각 이미지의 확률을 보여주는 것이다. 말이라면 아마 저 픽셀에 해당하는 값은 말 일 확률이 98% 정도 된다... 이런식으로 말이다. 그렇다면 위에 TernausNet-16의 최종적인 출력 값도 각 픽셀의 정확도라고 생각하면 되겠다. 일반적인 AutoEncoder라면 Softmax의 최종 출력 값은 결국에 input x 와 output x 의 차이는 별반 없을 것이다. 하지만 위와 같은 Encoding을 거쳤다면 정말 Feature만 살아있는 Feature Map 의 Softmax 출력 값이기 때문에 Segmentation이 가능한 것이다.
궁금증 : 그러면 Classification은 안되는가?
그게 나의 핵심적인 질문이다. Segmentation도 알겠다. 하지만 내가 지금 당장해보고 싶은건 One-hot으로 된 y Label를 통해서 어떤 것인지 맞추는 검출기가 필요하다.
다시 생각해보자...
Classification을 하기 위해서는 각 픽셀을 아닌 단순 이미지 그 자체를 봐야한다. 지금 위에 있는 모델은 Input 이미지의 픽셀 특성들 을 중요시하고 있다. 그럼 전체를 보기 위해서는 어떻게 해야할까? 사실 정말 단순하게는 Flatten 을 할수도 있다. 하지만 이는 Feature를 뭉개버릴 수도 있기에 함부로 하기에는 썩 좋은 방법은 아닌거 같다.
이 부분에 대해서는 계속 논의 하고 생각하고 있지만 아직 제대로 된 이해가 되지 않아서 천천히 다시 짚어갈거 같다. 제대로 된 학습이 되면 다시 글을 적도록 하겠다...
