
📌SQL 학습과제1. 스타벅스&이디야 분석
- 이전에 했던 스타벅스&이디야 데이터 분석과 동일한 방법으로 데이터를 얻는다
- 이전과 다른 것은 SQL를 사용한다는 것이다
제한사항
- Python 코드로 SQL 제어
- import mysql 필요
절차
- AWS RDS에 접속하여 데이터를 저장할 테이블을 생성한다.
- 생성할 테이블은 2개이다
- 브랜드를 표기할 테이블
- 데이터를 저장할 테이블, brand 칼럼을 브랜드칼럼의 id와 forign key로 연결
- 데이터 크롤링 및 저장
- 이전 크롤링 코드를 활용한다
- 브랜드 테이블에 브랜드 관련 데이터를 추가한다
- 크롤링데이터를 SQL에 바로 저장한다
- ex. 매장 1개 데이터 습득 후 commit()
- 스타벅스&이디야 데이터 저장
- 시각화를 위하여 CSV파일로 저장
- 각 스타벅스 매장별 이디야 전체 매장정보 매칭
📌SQL 학습과제2. 유가데이터 분석
- 이전에 했던 유가 데이터 분석과 동일한 방법으로 데이터를 얻는다
- 이전과 다른 것은 SQL를 사용한다는 것이다
제한사항
- Python 코드로 SQL 제어
- import mysql 필요
절차
- AWS RDS에 접속하여 데이터를 저장할 테이블을 생성한다.
- 생성할 테이블은 2개이다
- 브랜드를 표기할 테이블
- 데이터를 저장할 테이블, brand 칼럼을 브랜드칼럼의 id와 forign key로 연결
- 데이터 크롤링 및 저장
- 이전 크롤링 코드를 활용한다
- 브랜드 테이블에 브랜드 관련 데이터를 추가한다
- 크롤링데이터를 SQL에 바로 저장한다
- ex. 주유소 1개 데이터 습득 후 commit()
- 유가 데이터 저장
- 시각화를 위하여 CSV파일로 저장
- 특정 대상을 기준으로 특정 거리 안의 주유소 조회
- st_distance_sphere(POINT{A_lng, A_lat}, POINT(B_lng, B_lat))
- 두 점의 거리를 m로 산출
학습과제1,2 수행성과
- Python으로 SQL 제어는 매우 쉬움
- Python을 활용한 SQL 제어 숙달
📌9주차 학습내용 요약
1. 통계학(statistic)
- 산술적 방법을 기초로 하여, 다량의 데이터를 정리 및 분석하는 방법을 연구하는 수학의 한 분야
변수
- 수학 : 정해지지 않은 값, 변하는 숫자
- 통계 : 조사 목적에 따른 관측값
양적자료(수치형데이터 = 이산형 + 연속형)
-
관측된 데이터가 숫자의 형태로 숫자의 크기가 의미를 갖고 있음
-
숫자를 표현할 때 이산형과 연속형으로 구분됨
질적자료(범주형데이터 = 명목형 + 순서형)
-
관측된 데이터가 성별, 주소지 등 범주로 구분하여 표현할 수 있는 데이터
-
데이터 입력시 1은 남자, 2는 여자처럼 다른 의미로 사용할 수 있으나 크기의 의미는 없다.
Exploratory Data Analysis(탐색적 데이터 분석)
- 데이터를 탐색하는 분석 방법으로 도표, 그래프, 요약 통계 등을 사용하여 데이터를 체계적으로 분석하는 하나의 방법
중심경향치
-
표본(데이터)를 이해하기 위해 표본의 중심을 설명하는 값을 대표값
-
대표적인 중심경향치 : 평균, 중앙값, 최빈값, 절사평균
산포도
-
데이터의 흩어짐 정도를 의미함
-
대표적인 산포도 : 범위, 사분위수, 분산, 표준편차, 변동 계수 등
2. 확률
- 모든 경우의 수에 대한 특정 사건이 발생하는 비율
표본공간
- 어떤 사건에서 발생할 수 있는 모든 결과의 집합

확률변수
- 표본 공간에서 각 사건이 발생할 확률을 표현한 변수
확률 변수의 평균 : 기대값
확률 변수의 분산
확률분포
- 확률 변수 X가 취할 수 있는 모든 값과 그 값을 나타날 확률을 표현한 함수


확률밀도함수(PDF)
- 연속형 확률 변수 X에 대하여 함수 가 아래의 조건을 만족하는 경우

정규분포(가우스분포)
- 확률변수 X가 평균이 이고, 분산이 인 정규분포
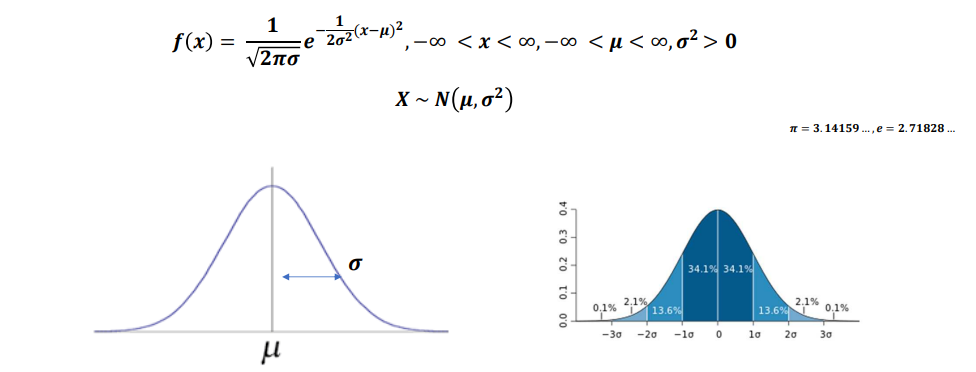

표준정규분포
- 확률변수 ~인 정규분포를 따르고, 확률변수 라고 할 때 확률변수 ~라고 한다



3. 모집단과 표본
- 모집단 : 관측치의 전체 집합
- 표본 : 모집단을 추정하기 위해 일부를 추출한 집합

표본추출(Sampling)
-
모집단으로 부터 표본을 추출하는 것
-
추출 방법
-
복원추출
- 모집단에서 데이터를 추출할 때 하나를 추출하고 다시 넣고 추출하는 방법, 중복가능
-
비복원추출
- 모집단에서 데이터를 추출할 때 하나를 추출하고 다시 넣지 않는 방법, 중복불가능
-
랜덤샘플링
- 각 개체를 모두 동일한 확률로 추출하는 방법(주의. 비편향되어야 함)
-
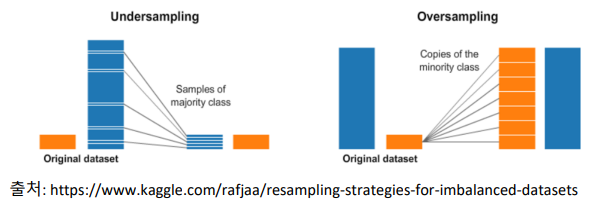
샘플링 기법
- Over Sampling
- 타겟 데이터가 적은 경우 많은 class의 비율만큼 증가시킴(일정 비율로 복원추출)
- 과적합 발생가능
- Under Sampling
- 타겟 데이터가 많은 경우 적은 class의 비율만큼 감소시킴
- 편향가능, 모형의 성능 감소가능
4. 추정
-
추정(estimation)
- 모집단의 모수를 모를 경우 표본으로 추출된 통계량을 모집단의 근사값으로 사용하는 것
-
추정량(estimator)
- 표본 평균으로 모평균을 추정할 때 표본 평균을 모평균에 대한 추정량 이라고 함
모수 추정방법
-
점추정(point estimation) : 모수를 하나의 특정값으로 추정하는 방법
-
일치성 : 표본의 크기가 모집단의 크기에 근접해야 함
-
불편성 : 추정량이 모수와 같아야 함
-
유효성 : 추정량의 분산이 최소값이어야 함
-
평균오차 제곱 : 평균오차제곱이 최소값이어야 함
-
5. 가설검정과 유의수준 정의
- 가설 검정 = 가설(Hypothesis) + 검정(Testing)
가설
-
주어진 사실 또는 조사하려고 하는 사실에 대한 주장 또는 추측
-
통계학에서는 모수를 추정할 때 모수가 어떠하다고 증명하고 싶은 추측이나 주장을 의미함
-
귀무 가설(Null hypothesis:
- 기존의 사실(아무것도 없다, 의미가 없다)
- 대립가설과 반대되는 가설로 연구하고자 하는 가설의 반대이며, 연구목적이 아님
- ex) : 코로나 백신이 효과가 없다,
-
대립 가설(Alternative hypothesis:
- 데이터를 기반으로 주장하고 싶은 가설 또는 연구 목적인 가설, 귀무가설의 반대
- ex) : 코로나 백신이 효과가 있다, or
오류
- 제1종 오류
- 귀무가설이 참이지만, 귀무가설을 기각하는 오류
- 제2종 오류
- 귀무가설을 기각해야 하지만, 귀무가설을 채택하는 오류
검정통계량, P-value, 기각역
-
검정통계량
-
귀무가설이 참이라는 가정하에 얻은 통계량
-
검정결과 대립가설을 선택하게 되면 귀무가설을 기각(reject)함
-
검정결과 귀무가설을 선택하게 되면 귀무가설을 기각하지 못한다고 표현함
-
-
P-value: 귀무가설이 참일 확률
-
0~1사이의 표준화된 지표(확률값)
-
귀무가설이 참이라는 가정하에 통계량이 귀무가설을 얼마나 지지 하는지를 나타내는 확률
-
대게 0.05 or 0.1의 유의수준(\alpha)보다 낮으면 귀무가설을 기각한다
-
-
기각역(reject region)
- 귀무가설을 기각시키는 검정통계량의 관측값의 영역
6. 범주형자료분석
- 범주형 자료
- 관측된 결과를 어떤 속성에 따라 몇 개의 범주로 분류시켜 도수로 주어진 데이터
- 범주형 자료 분석
- 범주형 자료에 대한 통계적 추론 방법
- 범주형 자료 분석은 카이제곱 검정으로 추론함
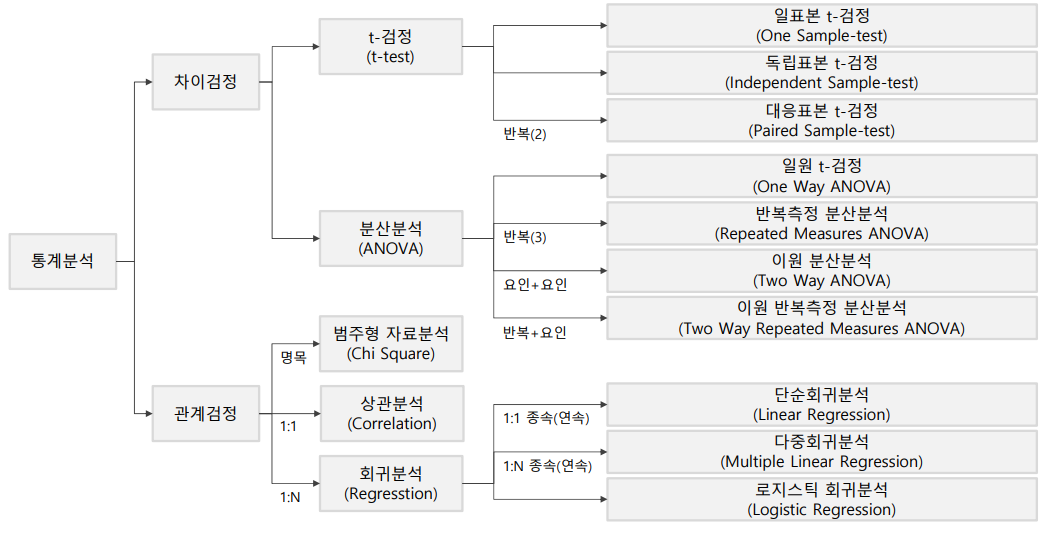
적합도 검정
- 관측된 값들이 추론하는 분포를 따르고 있는지 검정, 한 개의 요인을 대상으로 검정

독립성 검정
- 관측된 값을 두 개의 요인으로 분할하고 각 요인이 다른 요인에 영향을 끼치는지 독립성을 검정

동질성 검정
- 서로 다른 세 개 이상의 모집단으로 관측된 값들이 범주내에서 동일한 비율을 나타내는지 검정

7. 상관&회귀 분석
상관분석
- 두 변수 간의 함수 관계가 선형적인 관계가 있는지 파악할 수 있는 측도


회귀분석
- 회귀분석
- 변수들간의 함수적 관계를 선형으로 추론하는 통계적 분석 방법으로 독립변수를 통해 종속변수를 예측하는 방법
- 종속 변수
- 다른 변수의 영향을 받는 변수, 반응변수, 예측 하고자 하는 변수
- 독립 변수
- 종속변수에 영향을 주는 변수, 설명변수, 예측 하는 값을 설명하는 변수
회귀분석의 종류
- 단순 회귀분석
- 하나의 독립변수로 종속변수를 예측하는 모형
- 다중 회귀분석
- 2개 이상의 독립변수로 종속변수를 예측하는 회귀모형
8. 분산분석
- 셋 이상의 모집단으로부터 추출한 양적데이터를 비교하는 통계적 분석 방법
분산분석의 이해
분산분석의 이해
-
실험계획법(experimental design)
- 모집단의 특성에 대하여 추론하기 위해 특별한 목적성을 가지고 데이터를 수집하기 위한 실험설계
-
반응변수
- 관심의 대상이 되는 변수(종속변수)
-
요인/인자(Factor)
- 실험 환경 또는 조건을 구분하는 변수로 실험에 영향을 주는 변수
-
인자수준
- 인자가 취하는 개별 값(처리:treatment)
분산분석의 기본 가정
1) 각 모집단은 정규 분포를 따른다
2) 각 모집단은 동일한 분산을 갖는다
3) 각 표본은 독립적으로 추출되었다
분산분석의 가설과 실험의 가정
가설
- H0: 각 집단의 평균은 동일하다 vs H1: 각 집단의 평균에 차이가 있다
실험의 가정
-
반복의 원리: 실험을 반복해서 실행해야 함
-
랜덤화의 원리: 각 실험의 순서를 무작위로 해야함
-
블록화의 원리: 제어해야 할 변수가 있다면 인자에 영향을 받지 않도록 조건을 묶어서 실험해야 함
분산분석의 종류
일원 분산분석
- 한가지 요인을 기준으로 집단간의 차이를 조사하는 것
이원 분산분석
- 두 가지 요인을 기준으로 집단 간의 차이를 조사하는 것
다원 분산분석
- 세 가지 이상의 요인을 기준으로 집단 간의 차이를 조사하는 것
9. 시계열분석
- 시계열(시간의 흐름에 따라 기록된 것) 자료를 분석하고 여러 변수들간의 인과관계를 분석하는 방법
시계열데이터
- 시간을 기준으로 관측된 데이터로, 보통 일->주->월->분기->년 또는 hour 등 시간의 경과에 따라서 관측한 데이터
- ex) GDP, 주가, 거래액, 매출액, 승인금액 등
- 연속 시계열과 이산 시계열 데이터로 구분됨
시계열 종류
연속형 시계열
-
자료가 연속적으로 생성
-
대부분의 데이터 형태가 연속형이나 이산형 정의하여 분석
이산형 시계열
-
일정 시차(간격)를 두고 관측되는 형태의 데이터
-
대부분 이산형 데이터를 분석
시계열 분석의 목적
-
예측
- 금융시장 예측, 수요 예측등 미래의 특정 시점에 대한 관심의 대상(반응변수)을 예측
-
시계열 특성 파악
- 경향(Trend), 주기, 계절성, 변동성(패턴) 등 관측치의 시계열 특성 파악
