해당 글은 제로베이스데이터스쿨 학습자료를 참고하여 작성되었습니다
Few, Zero short learning & Transfer learning
자연어 데이터의 불완전성
- 특정 자연어 Task를 해결하기 위해서는 다양한 Label이 요구됨. 특히, format도 매우 복잡함
- input data는 굉장히 많은데 label이 적음
- 수많은 텍스트 데이터들이 레이블이 없이 존재함(ex. 의료 데이터셋)
pre-training
- 레이블이 지정되지 않은 데이터 세트에서 훈련하여 심층 신경망의 매개변수를 초기화하는 기술
Fine tunning
- 사전 학습된 모델을 새로운 문제에 적용하기 위해 일부 가중치를 조절하는 학습 과정
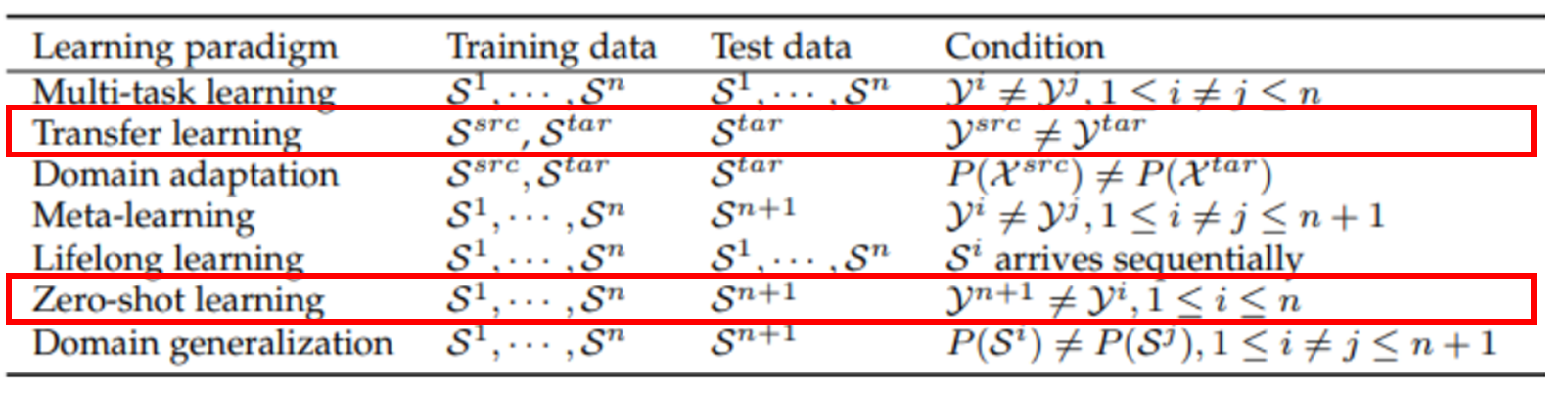
Transfer learning
- 일본어-영어, 한국-일본어 간의 번역 데이터는 많으나 한국-영어 데이터는 적을 경우
- 영어->일본어 데이터셋에서 문맥 벡터를 잘 뽑아내는 모델을 학습한 후 영어->한국어 데이터셋에 적용
Few shot, zero shot learning
- Query image : 추론할 입력 데이터
- Training set : 모델이 학습하는 데이터 셋
- Support set : 추론해야 하는 셋
- support set의 종류 수를 way, 사진 수를 shot으로 표현함
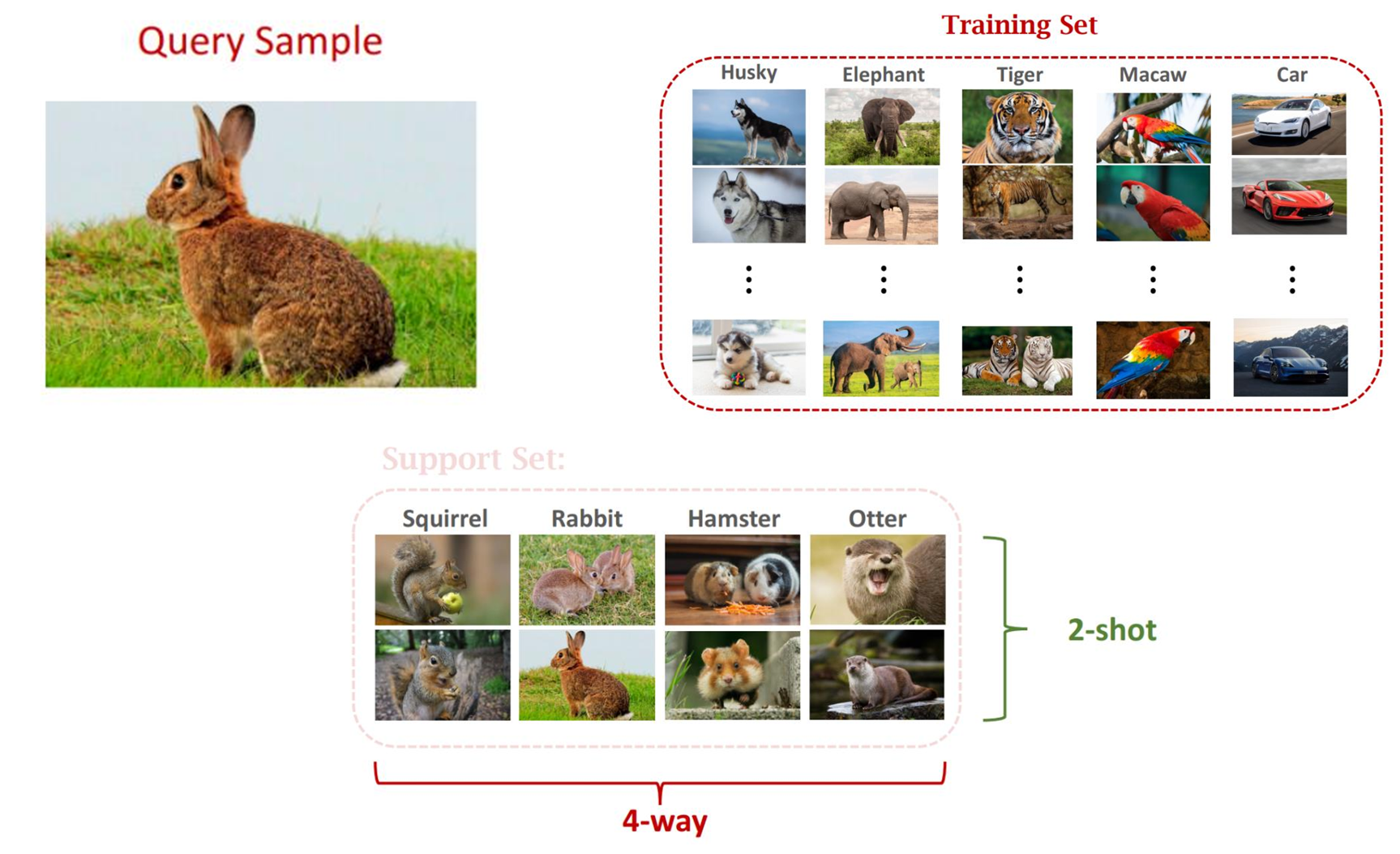
- support set의 종류 수를 way, 사진 수를 shot으로 표현함
GPT-1
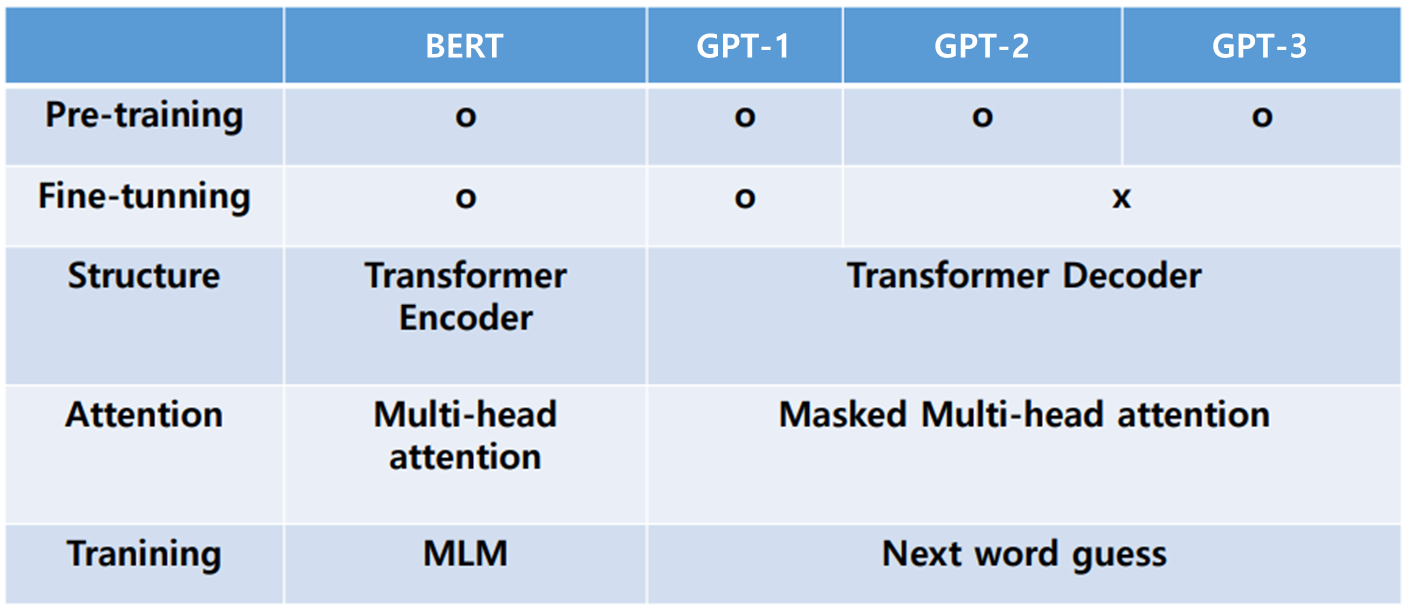
- Gpt1, Bert, Gpt2, Gpt3 순으로 연구됨
- Generative Pre-Training
- 비지도학습 기반의 pre-training과 지도학습 기반의 fine-tunning을 결합한 semi-supervised learning
- 그래서 다양한 자연어 task에서 fine-tunning만으로도 좋은 성능을 보이는 범용적인 자연어 representation을 학습하는 것
- 2 stage로 구성되어 있으며 transformer의 decoder 구조를 사용함
- 기존 RNN 대비 좋은 성능을 보였으며 일반화 성능 확인
Stage1: pre-training
- 문장 가 구성되어 있고 서브단어 로 각 확률들을 계산
- =초기화, =워드 임베딩, =단어(쿼리), =포지션 임베딩
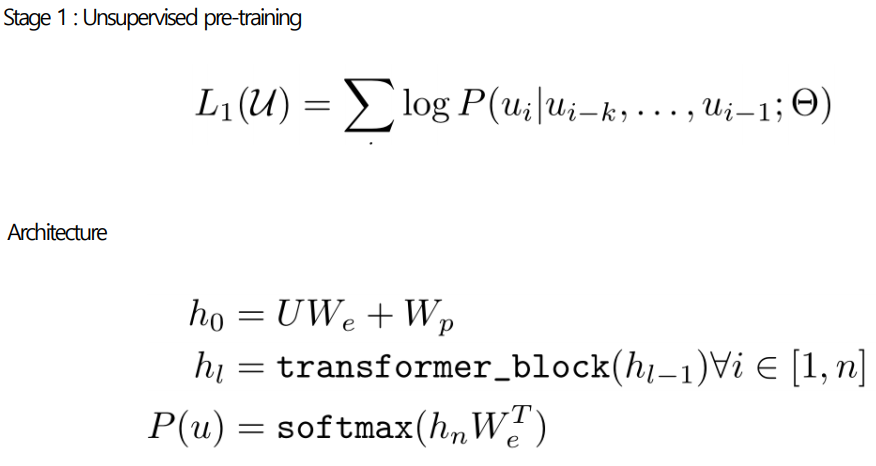
Stage2: fine-tuning
- =문장의 토큰들, =label
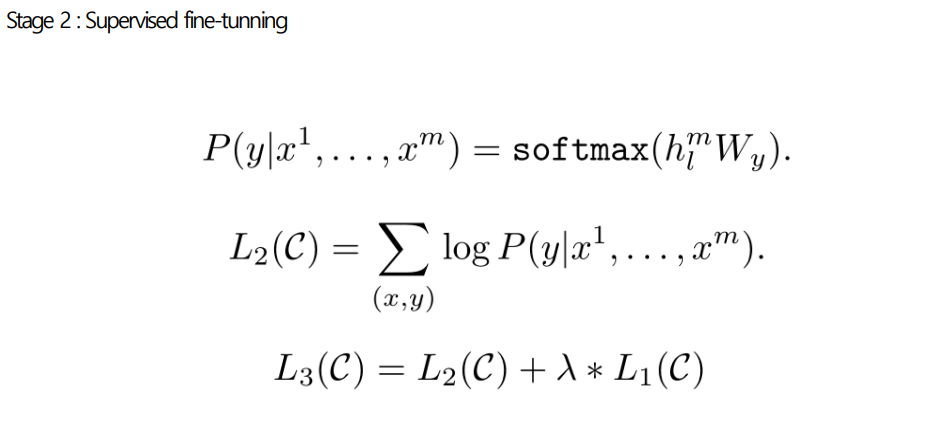
Task-specific input transformations
- 기존: Task specific 구조에 기반한 학습, 구조에 종속되기 때문에 task가 변할 때 마다 많은 커스터마이즈를 요구
- GPT-1 : Pre-training model 적용될 수 있도록 input구조를 convert
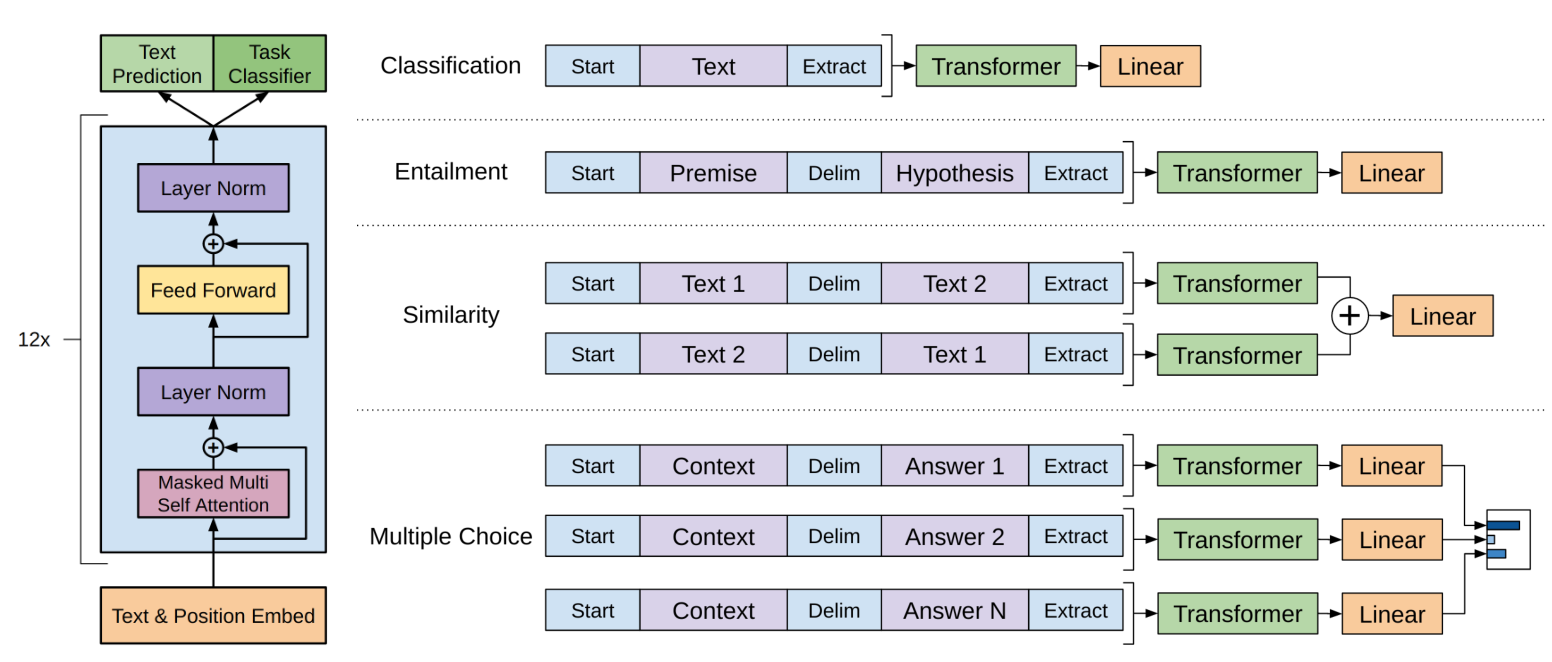
GPT-1의 성능
-
LM -> 큰 데이터셋 에서는 좋은 결과 but 작은 데이터셋에서는 아님

-
Layer 가 증가함에 따라 정확도가 높아지는 것을 확인
-
LSTM과 비교하여 다양한 task에서 일반화 성능 확인
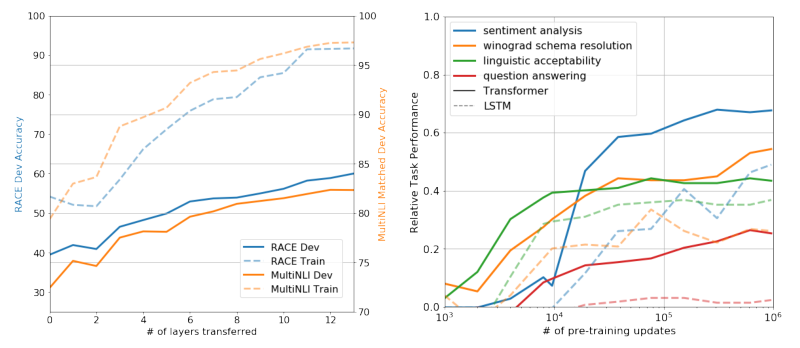
BERT
- Bidirectional Encoder Representations from Transformer
- Wiki & book data 와 같은 대용량 unlabeled data로 pre-training 시킨 후, 특정 task 에 transfer learning 을 함
- GPT와의 차이? -> unidirectional(GPT) vs bidirectional(BERT)
- GPT와는 달리 새로운 네트워크를 붙이지 않고 fine-tunning 만을 진행함
- GPT-1 : Unsupervised pre-training -> BERT : Masked Language Model(MLM) & Next sentence prediction
- Next sentence prediction
- 문장간 관계를 알아내기 위한 task, 두 문장이 실제 corpus 에서 이어져 있는지 아닌지 확인
- 50% 는 실제 이어져 있는 문장
- Pre-training 프로세스는 GPT-1과 같음
BERT와 GPT
Mask Language Model(MLM)
- [MASK] 비율 : 15%
- Tokenization : Wordpiece
- LM 의 left-to-right 와는 달리, [MASK] 를 추론하는 task 수행
- Fine tunning 에는 사용되지 않음
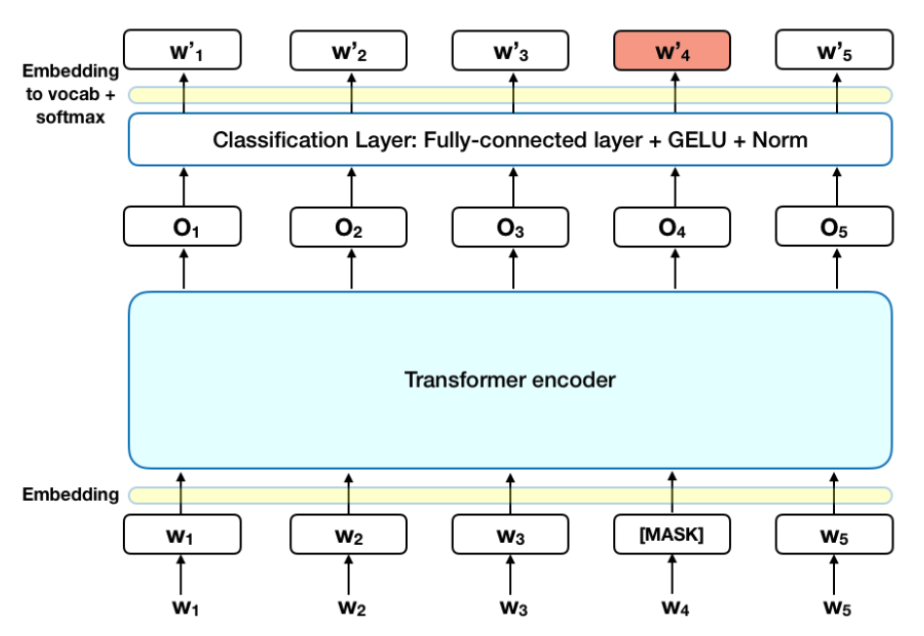
MASK 생성 과정
- 80% : token 을 [MASK]로 변환
- 10% : token 을 임의의 단어로 변경
- 10% : 원래의 단어 token 으로 둠
Pre-trained 되는 transformer encode의 입장에서는 contextual representation 학습
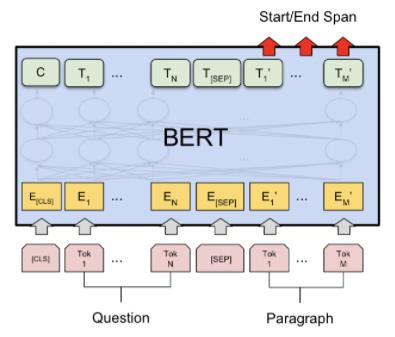
BERT의 input
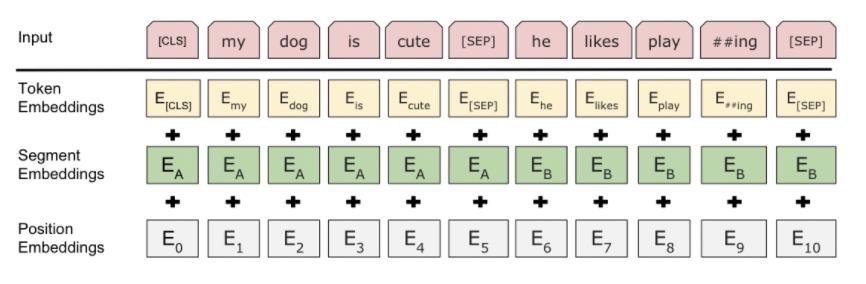
BERT의 fine-tuning
- Sequence-level classification
- [CLS] token 의 output 사용
- CLS output 에 W matrix 를 곱해주고 softmax를 취해 준다.
- Span-level, token-level prediction
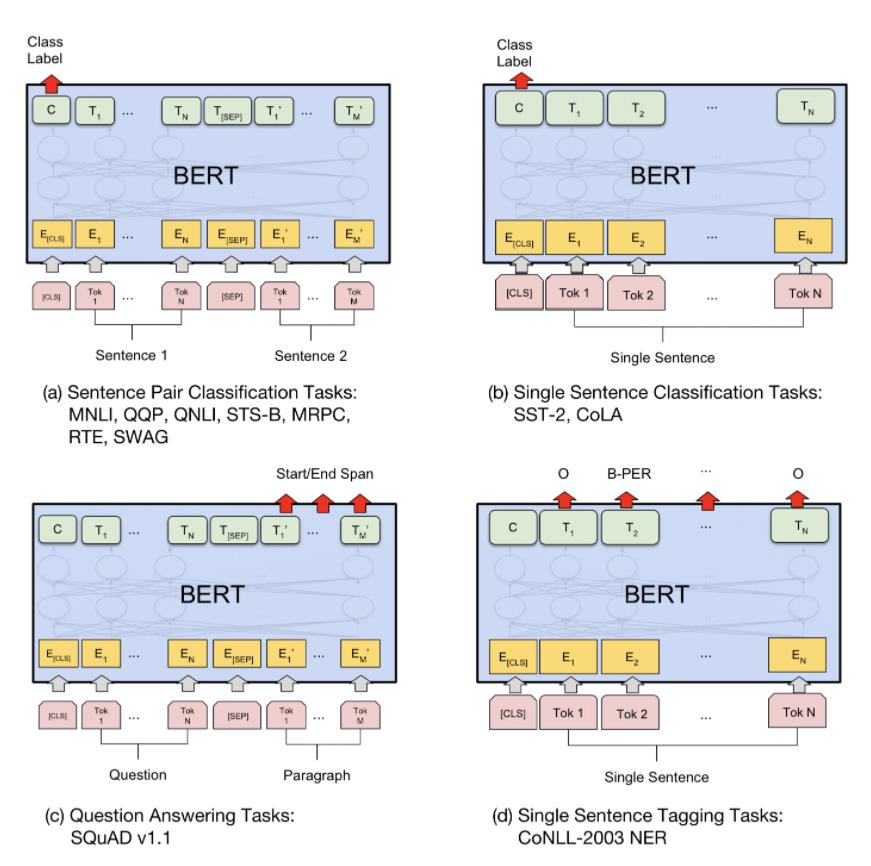
BERT의 성능
GLUE
- 다양한 task를 모아놓아 종합적인 자연어 이해 능력 테스트가 가능한 벤치마크
- BERT는 대부분의 task에 SOTA(State-of-the-art)
- 특히 데이터 크기가 작아도 fine-tunning 후에는 좋은 성능
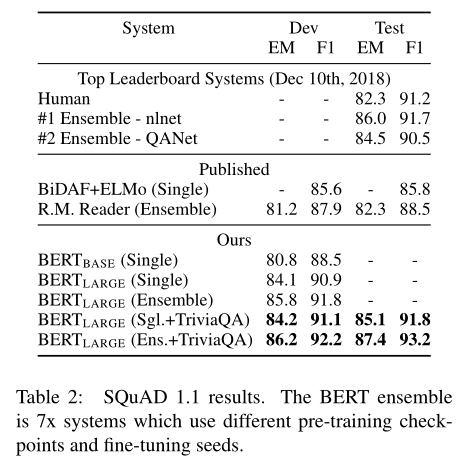
SQuAD
- GLUE는 sequence classification
- SQuAD 는 질문 과 지문이 주어지고, substring 인 정답 찾기
- 질문 A, 지문 B 지문에서 substring 찾기 문제
- Start vector와 end vector의 dot product를 하여 찾기
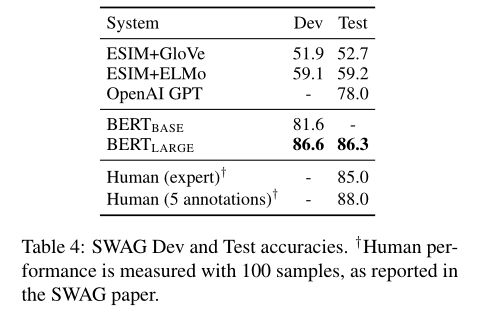
SWAG
- Grounded common-sense inference
- 문장이 주어지고, 가장 잘 이어지는 문장 찾기
- 주어진 문장 A, 가능한 문장들 B
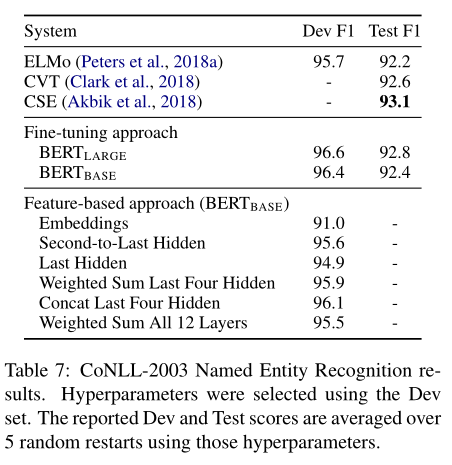
CoNLL-2003
- 각각의 단어가 어떤 형식인지
- Person, Organization, Location …
- 토큰마다 classifier 붙이기
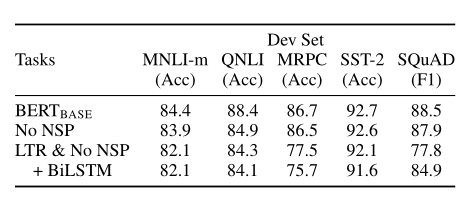
Ablation studies
-
Pre-train 을 하나라도 제거하면 성능 감소가 일어남
-
No NSP -> 자연어 추론 계열(NLI)에서 성능 감소 폭 큼
-
MLM 대신 LTR -> 성능이 매우 감소함
-
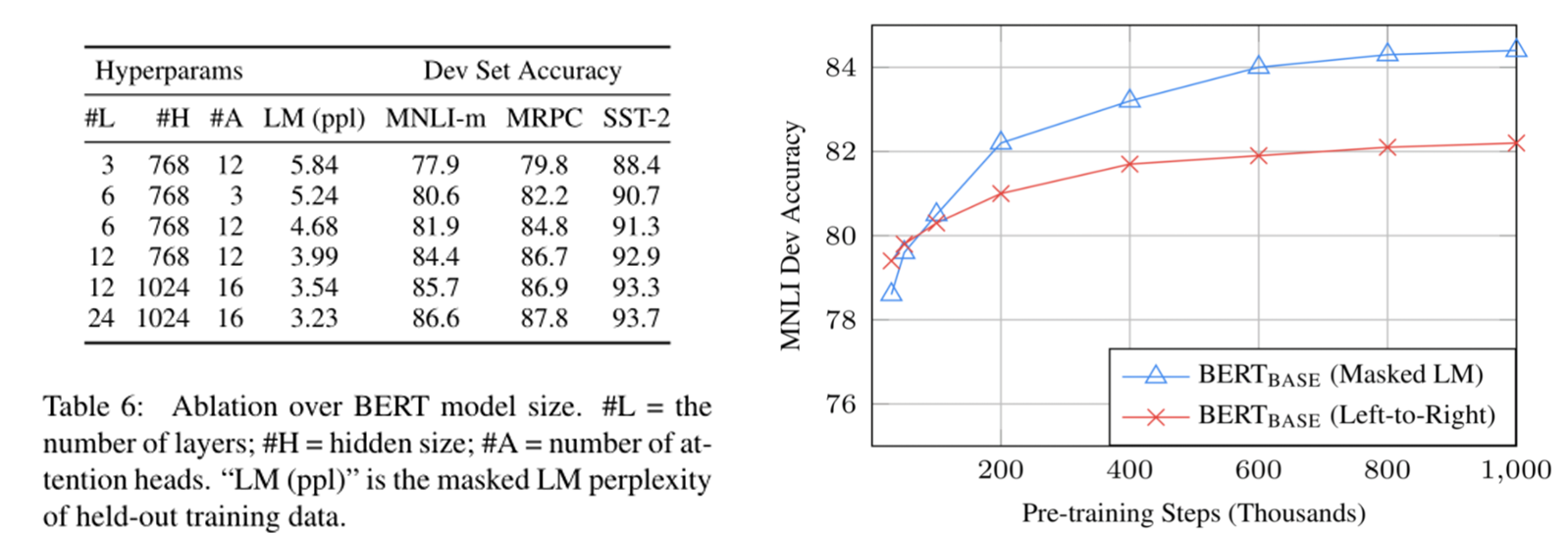
모델 사이즈가 커질수록 성능 향상
-
MLM이 많은 training이 필요하지만 성능향상 확인
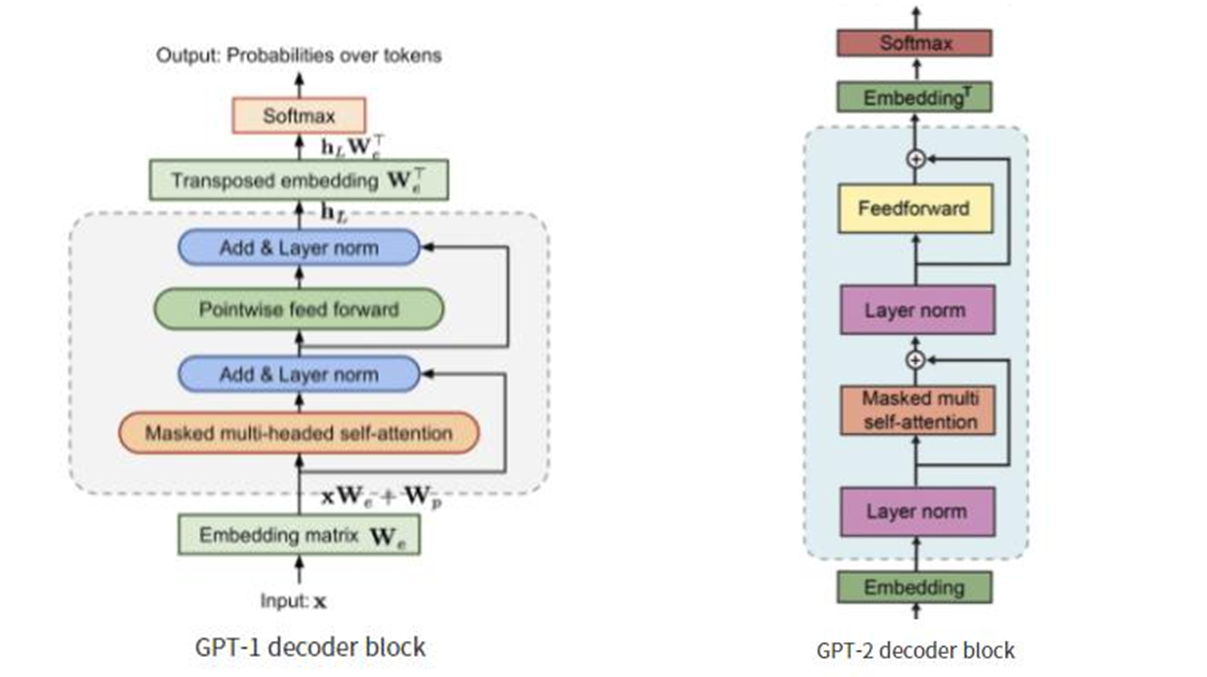
GPT-2
-
Fine-tunning 없이도 우리는 가능하게 하고 싶다.
-
모델 자체는 GPT-1과 크게 차이 없음
-
Zero shot learning
- Model이 바로 downstream task에 적용함 (few shot: 몇 번 보고 적용함 )
-
WebText 데이터을 구축
- 이 대용량 데이터셋에 LM 모델을 학습했을 때 supervision 없이도 다양한 task 처리
-
Byte pair Encoding을 활용 하여 Out of Vocabulary 문제 해결
Zero shot 적용방법
- 문장의 긍/부정 -> what do you think about this sentence ? 같은 질문 추가
- 문장 요약 -> What is the summary of … ? 추가
- 번역 -> what is translated sentence in Korean? 추가
Byte pair Encoding
Word Piece model (BERT)

- Jet은 자주 등장하지 않아서 J et 로 나눔
- 모든 단어 시작에는 _
Byte-pair encoding(BPE)


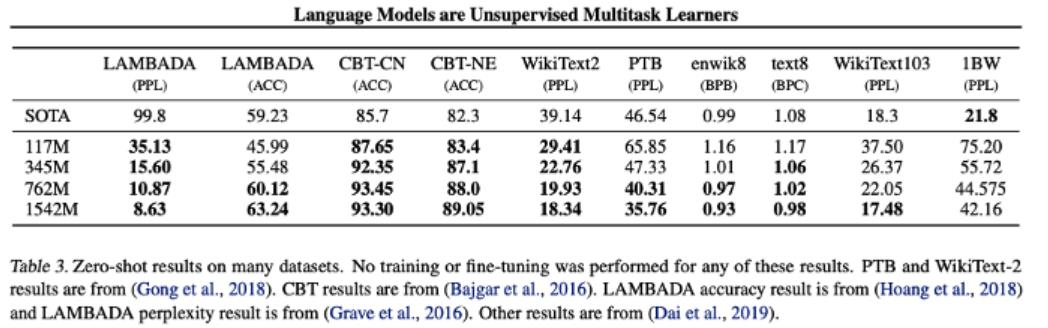
GPT-2의 성능
- Zero shot 임에도 불구하고 8개중 7개에서 SOTA
- 특히, PTB,Wikitext-2 와 같은 적은 데이터셋에서 좋은 성능
GPT-3
- GPT-2 대비 Self-attention layer를 굉장히 많이 쌓아 parameter 수를 대폭 늘림
- GPT-2에서 사용하는 Zero shot learning framework의 확장
shot learing

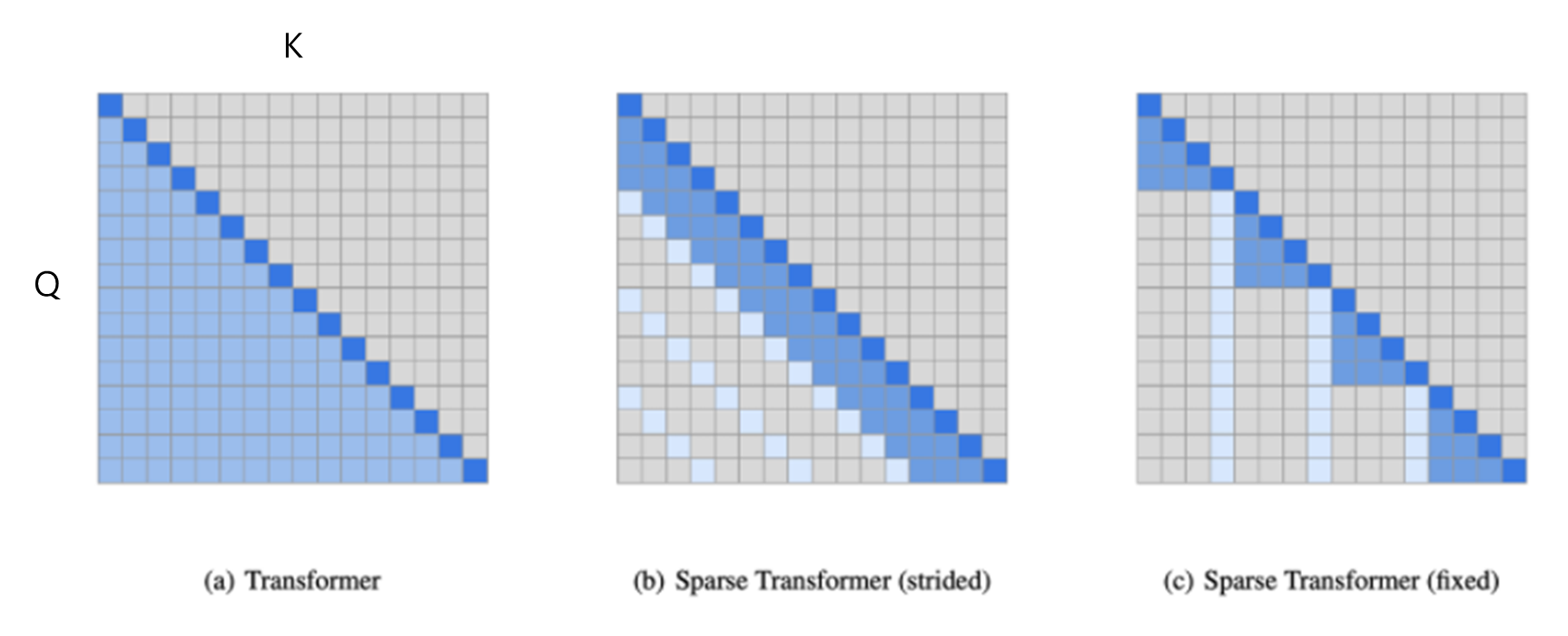
Transformer
- Transformer : 예측 K값 이전의 모든 입력 데이터을 예측에 활용
- 입력 데이터의 크기가 크면 계산량이 매우 많아짐
- Sparse Transformers : 입력 데이터의 일부분만 활용
- 계산 효율성을 높이고, 불필요한 계산을 줄일 수 있음
- GPT3가 strided와 fixed 사용
전체 요약