해당 글은 제로베이스데이터스쿨 학습자료를 참고하여 작성되었습니다
관련연구: Computer Vision
Visual Transformer(ViT)
- AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE, ICLR 2021
- Vit는 Transformer를 사용하여 이미지 인식에 적용한 연구
- 컴퓨터 비전 분야에서는 Convolution 연산을 이용한 방법이 아직까지 대중적
Inductive bias(귀납편향)
- 데이터가 공간적으로 변화해도 불변하는 것
- ViT는 귀납편향없이 성능향상을 보임

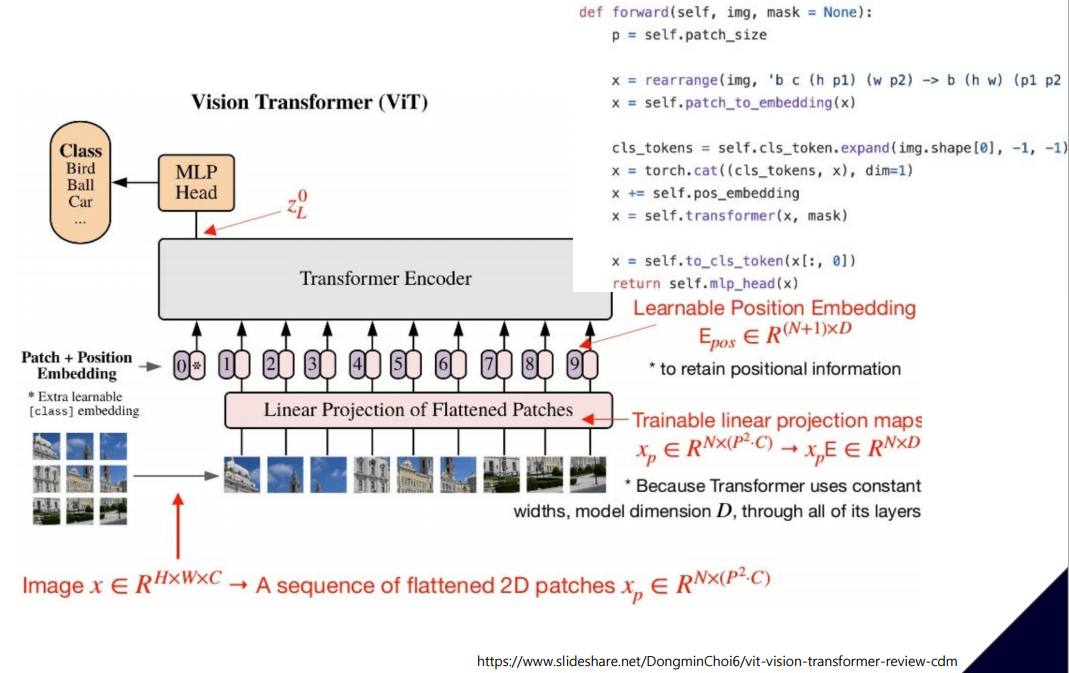
Key idea
- positional encoding에서 이미지를 분할하고 분할 대상을 각각의 토큰으로 판단하여 수행

Vit Forwarding
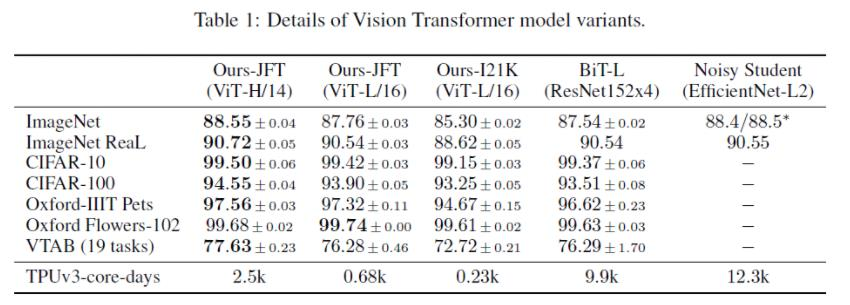
타모델과 비교
- JFT300M dataset으로 pretrain 시키고 테스트
- 이미지 약 3억개 사용(용량 : 18PB)
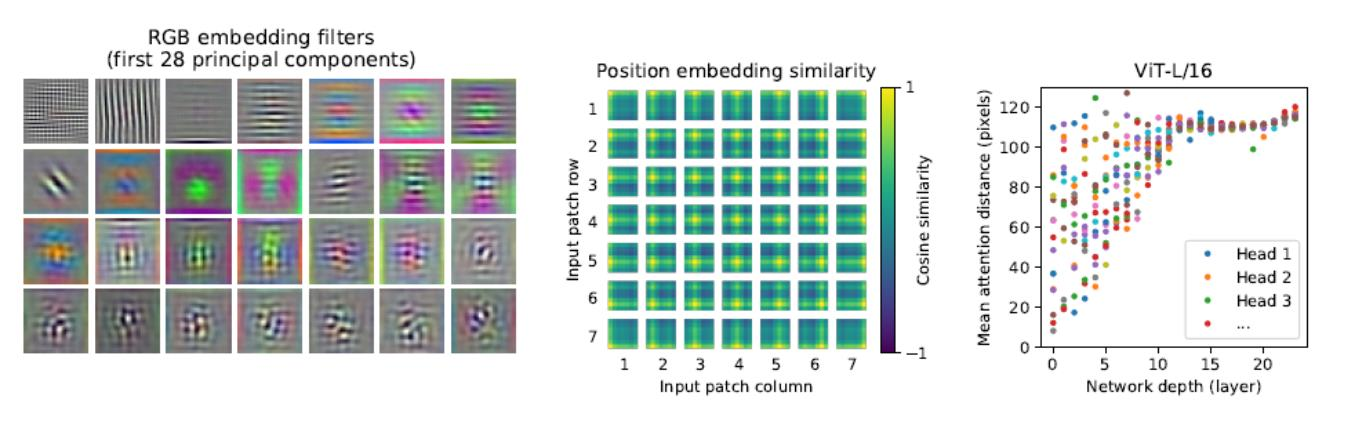
- 자동으로 low-level의 특성을 학습하는 embedding filter
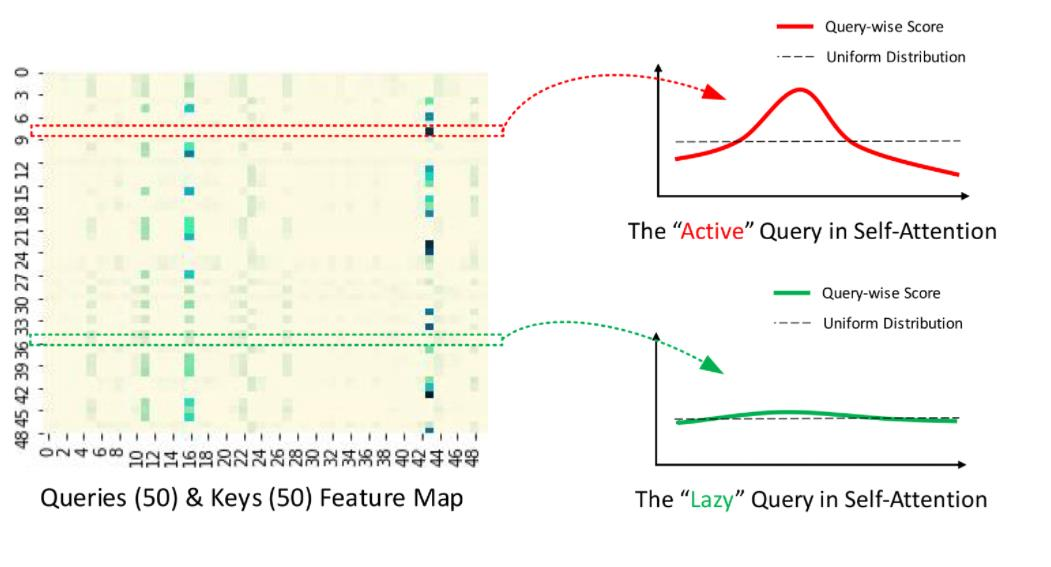
- Positional embdding 이후의 이미지와 패치와의 유사도
- Attention이 얼마나 먼 패치를 할당하고 있는지 (receptive field와 유사)
DETR
- End-to-End Object Detection with Transformers, ECCV 2020
- Object Detection 문제를 direct set prediction으로 푸는 모델
- 기존의 Detection 에서 생기는 non-maximum suppression (NMS) 문제를 해결
- Transformer 기반의 prediction
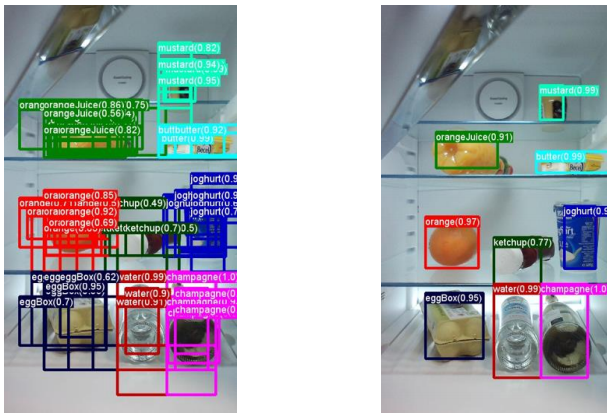
NMS Problem
- 기존 방법은 non-maximum suppression (NMS) 문제를 해결하기 위해 post processing 필요
- DETR은 transformer 를 활용한 end-to-end 방식
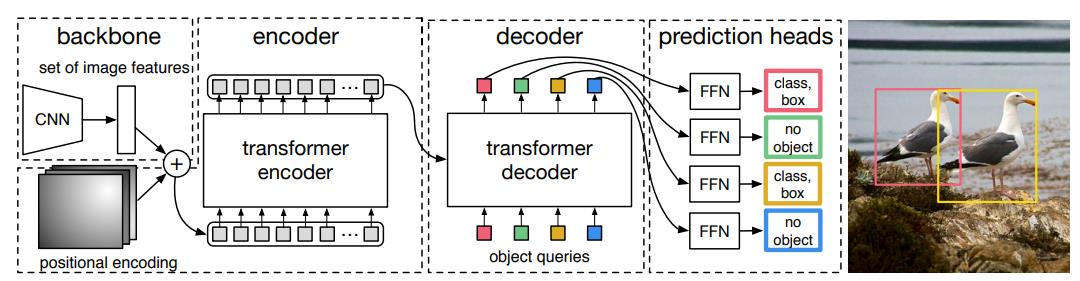
DETR 모델 절차
- CNN을 입력받아서 positional Encoding 수행
- Encoder을 거치고 Decoder 수행
- Decoder에서 대상에 대해서 하나의 Bounding box가 할당되도록 birpartite mathing 사용
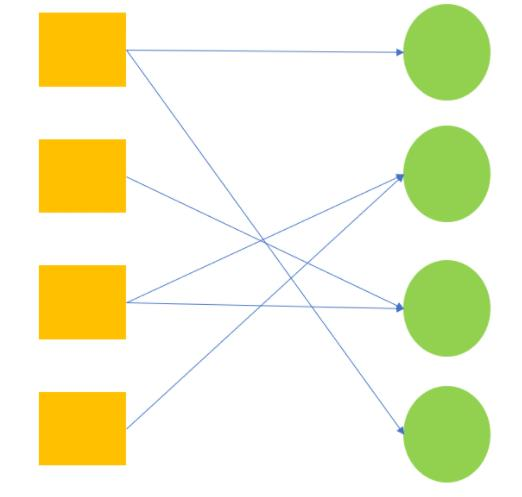
bipartite matching
- NMS 해결 -> 각각의 실제 레이블에 대해서 하나만 할당
- 오브젝트가 없다면 확률을 계산하지 않고
- 오브젝트가 있다면 바운딩 박스의 확률을 계산하고 최적의 박스를 찾는다
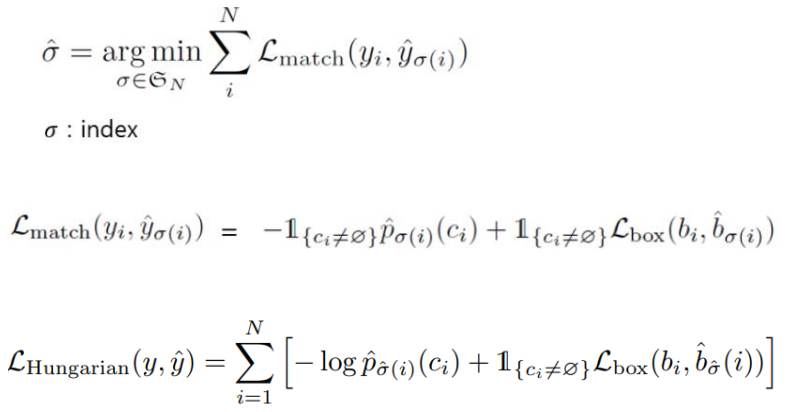
Python Code

관련연구: 시계열 데이터
BETS
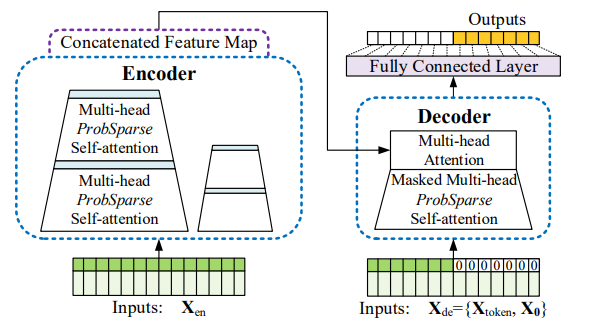
- Informer: Beyond Efficient Transformer for Long Sequence TimeSeriesForecasting (AAAI'21 Best Paper)
- 기존의 시계열 데이터 처리는 LSTM을 많이 사용
- BETS는 일반적으로 훨씬 긴 시계열을 예측하는 시계열 데이터
- Transformer 의 attention layer 는 matrix 연산임 -> 계산인 size의 제곱만큼 증가