📌Python with MySQL
- 파이썬을 활용하여 MySQL을 사용해보자
실습환경 구축
- AWS RDS 안의 Table:police_station 데이터를 백업하고 삭제한다
mysqldump --set-gtid-purged=OFF -h "database-1.cgto2ofp2xtq.ap-northeast-1.rds.amazonaws.com" -P 3306 -u admin -p zerobase > police_station.sql
mysql -h "database-1.cgto2ofp2xtq.ap-northeast-1.rds.amazonaws.com" -P 3306 -u admin -p zerobase
use zerobase;
delete from police_station;mysql> desc police_station; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | name | varchar(16) | YES | | NULL | | | address | varchar(128) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ 2 rows in set (0.05 sec) mysql> select * from police_station; Empty set (0.04 sec)
Python에서 MySQL 접속하기
설치코드
!pip install mysql-connector-python;
접속코드
import mysql.connector
mydb = mysql.connector.connect(
host = "<host>", #localhost or 엔드포인트
port = "<port>", # 로컬인 경우 생략가능
user = "<user>", # root or 유저명
password = "<password>",
database = "<database>" # 데이터베이스에 바로 접속시 사용
)
mydb.close()Python에서 MySQL 사용하기
커서생성 및 사용
cur = remote.cursor()
cur.execute("<query>")
- Python으로 table 만들기
remote = mysql.connector.connect( host = my_host, port = my_port, user = my_user, password = my_password, database = my_database ) cur = remote.cursor() cur.execute("create table sql_file (id int,filename varchar(16))") remote.close()
- Terminal에서 확인하기
mysql> show tables; +--------------------+ | Tables_in_zerobase | +--------------------+ | celeb | | crime_status | | police_station | | snl_show | | sql_file | | test1 | | test2 | +--------------------+ 7 rows in set (0.04 sec)
- Python으로 table 삭제하기
remote = mysql.connector.connect( host = my_host, port = my_port, user = my_user, password = my_password, database = my_database ) cur = remote.cursor() cur.execute("drop table sql_file") remote.close()
- Terminal에서 확인하기
mysql> flush privileges; Query OK, 0 rows affected (0.80 sec) mysql> desc sql_file; ERROR 1146 (42S02): Table 'zerobase.sql_file' doesn't exist
Python에서 SQL File 활용하기(단일쿼리)
실습환경 구축
- test03.sql
CREATE TABLE sql_file
(
id int,
filename varchar(16)
);sql파일 읽고 실행하기
cur = remote.cursor()
sql = open('<filename>.sql').read()
cur.execute(sql)
- test03.sql 파일 실행하기
cur = remote.cursor() sql = open('test03.sql').read() cur.execute(sql)
- 확인하기
mysql> desc sql_file; +----------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +----------+-------------+------+-----+---------+-------+ | id | int | YES | | NULL | | | filename | varchar(16) | YES | | NULL | | +----------+-------------+------+-----+---------+-------+ 2 rows in set (0.05 sec)
Python에서 SQL File 활용하기(다중쿼리)
실습환경 구축
- test04.sql
INSERT INTO sql_file VALUES (1, "test01.sql");
INSERT INTO sql_file VALUES (2, "test02.sql");
INSERT INTO sql_file VALUES (3, "test03.sql");
INSERT INTO sql_file VALUES (4, "test04.sql");sql파일 읽고 실행하기
cur = remote.cursor()
sql = open('test03.sql').read()
cur.execute(sql, multi=True)
- 파일읽고 실행 후 실행문보여주기
cur = remote.cursor() sql = open('test04.sql').read() for result_iterator in cur.execute(sql, multi=True): if result_iterator.with_rows: print(result_iterator.fetchall()) else: print(result_iterator.statement) remote.commit() # 적용하기

데이터 읽어오기
fetchall()
import mysql.connector
remote = mysql.connector.connect(
host = my_host,
port = my_port,
user = my_user,
password = my_password,
database = my_database
)
cur = remote.cursor(buffered=True) # 데이터가 많은경우 buffered설정
cur.execute("select * from sql_file")
result = cur.fetchall()
for result_iterator in result:
print(result_iterator)
remote.close()
👀참고 : DataFrame으로 읽어오기
import pandas as pd
df = pd.DataFrame(result)
df
DF에 컬럼명 추가
result = cur.fetchall()
field_names = [n[0] for n in cur.description]
df = pd.DataFrame(result)
df.columns = field_names
df
Python with CSV
예제1. police_station
1) 데이터 확인
import pandas as pd
df = pd.read_csv("police_station.csv")
df.head()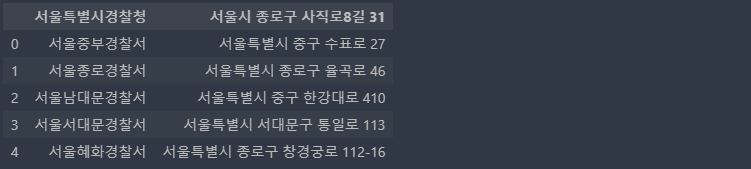
2) DB에 추가
import mysql.connector
conn = mysql.connector.connect(
host = my_host,
port = my_port,
user = my_user,
password = my_password,
database = my_database
)
cursor = conn.cursor(buffered=True)
sql = 'insert into police_station values (%s, %s)'
for i, row in df.iterrows():
cursor.execute(sql, tuple(row))
print(tuple(row))
conn.commit()
3) 데이터 확인
cursor.execute('select * from police_station')
result = cursor.fetchall()
for row in result:
print(row)
conn.close()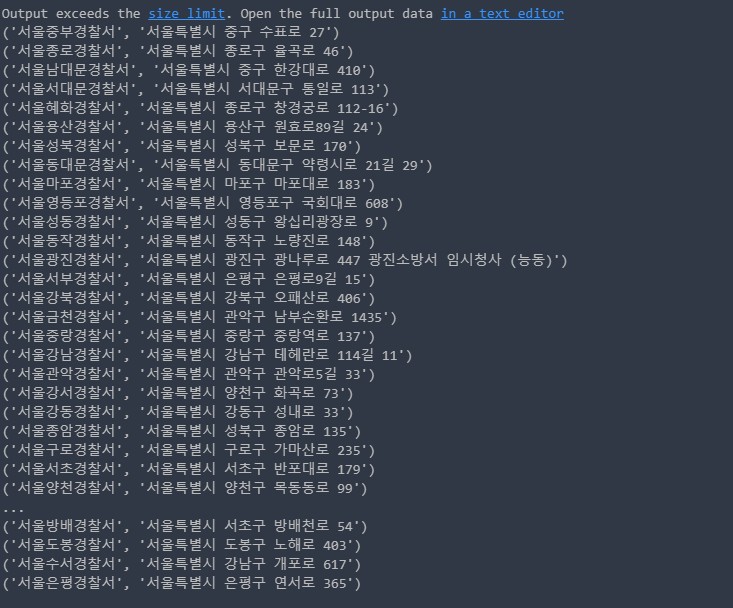
4) 데이터프레임 생성
df = pd.DataFrame(result)
df.rename(columns={0:'경찰서', 1:'주소'}, inplace=True)
df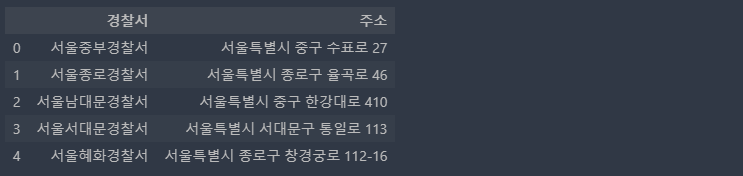
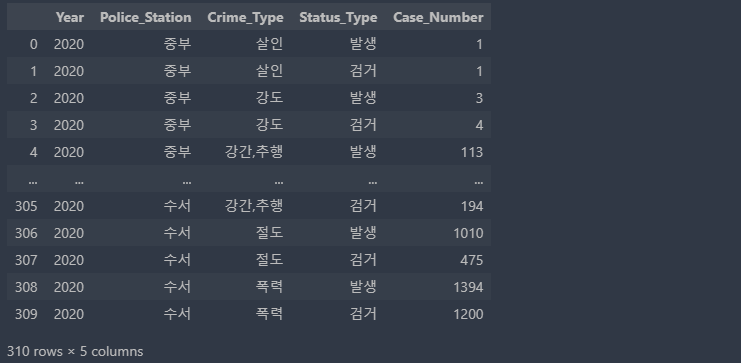
예제2. crime_status
1) 데이터 확인
import pandas as pd
df = pd.read_csv('./crime.csv', encoding='euc-kr')
df
2) DB에 추가
import mysql.connector
conn = mysql.connector.connect(
host = my_host,
port = my_port,
user = my_user,
password = my_password,
database = my_database
)
sql = "insert into crime_status values ('2020', %s, %s, %s, %s)"
cursor = conn.cursor(buffered=True)
for i, row in df.iterrows():
cursor.execute(sql, tuple(row))
print(tuple(row))
conn.commit()
3) 데이터 확인
cursor.execute("select * from crime_status")
result = cursor.fetchall()
for row in result:
print(row)
conn.close()
4) 데이터프레임 만들기
df = pd.DataFrame(result)
df.columns = ['Year', 'Police_Station', 'Crime_Type', 'Status_Type', 'Case_Number']
df