Selenium과 주유소 가격 정보

해당 글은 제로베이스데이터스쿨 학습자료를 참고하여 작성되었습니다
📌Selenium
공식문서 : https://www.selenium.dev/documentation/
- 웹 브라우저를 원격 조작하는 도구
- 자동으로 URL을 열고 클릭 등의 매크로 동작구현
- 스크롤, 문자의 입력, 화면 캡처 등등
크롬 드라이버
- Selenium을 사용하려면 크롬드라이버가 필요하다
- 크롬버전을 확인한다
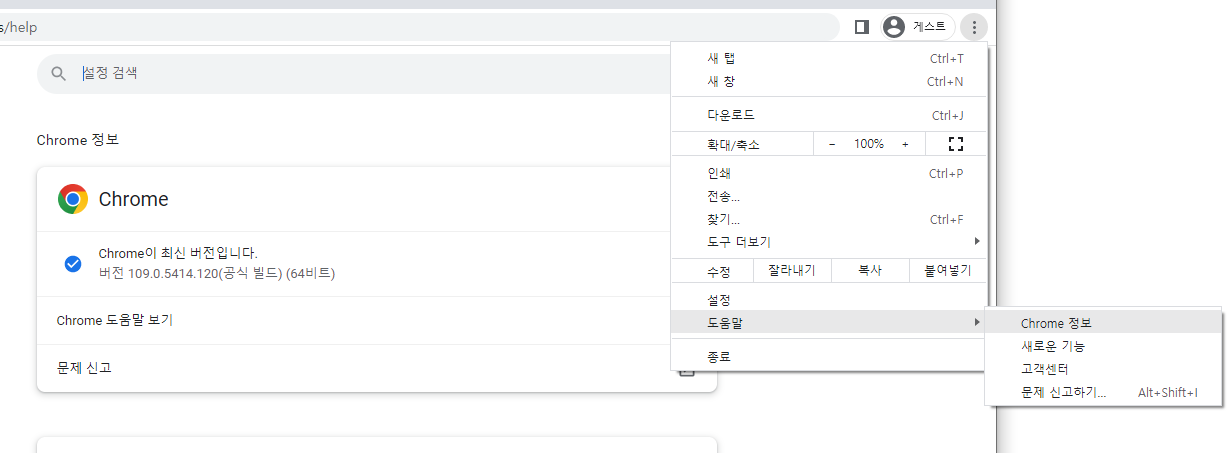
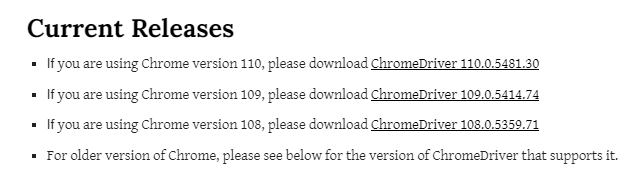
- 크롬드라이버 다운로드를 검색해서 버전에 맞는 것을 다운받고 알맞은 위치에 알집을 풀어준다
📌Selenium Basic
Selenium 설치
# !pip install Selenium import selenium selenium.__version__

📌기능요약
- 드라이버실행 : 네이버접속
from selenium import webdriver from selenium.webdriver import ActionChains from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys import time # # 크롬드라이버 실행 및 사이트 접속 print('크롬드라이버 실행 및 사이트 접속') driver = webdriver.Chrome() driver.get('https://www.naver.com')
- 화면조절
## 최대화 print('최대화') driver.maximize_window() time.sleep(2) # ## 최소화 print('최소화') driver.minimize_window() time.sleep(2) # ## 화면 크기 지정 print('화면 크기 지정') driver.set_window_size(1024, 600) time.sleep(2)
- 스크롤 동작
## 스크롤 가능한 높이 가져오기 last_height = driver.execute_script("return document.body.scrollHeight") print('스크롤 길이 : {}'.format(last_height)) # ## 아래로이동 print('아래로이동') driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(2) # ## 위로이동 print('위로이동') driver.execute_script("window.scrollTo(0, 0);") time.sleep(2) # ## 특정대상(공지사항)까지 스크롤 print('특정대상(공지사항)까지 스크롤') some_tag = driver.find_element(By.XPATH, '//*[@id="footer"]/div/div[2]/div/h3/a') action = ActionChains(driver) action.move_to_element(some_tag).perform() time.sleep(2) # ## 스크린샷 print('스크린샷') driver.save_screenshot('./target_height.png') time.sleep(2)
- 페이지 조작
## 글자 입력 print('글자 입력') some_tag = driver.find_element(By.ID, 'query') some_tag.send_keys('데이터사이언스' + Keys.ENTER) # some_tag.send_keys('데이터사이언스\n') time.sleep(2) # ## 버튼 클릭 print('버튼 클릭') some_tag = driver.find_element(By.CSS_SELECTOR, '#nx_query') some_tag.clear() # 검색창 초기화 some_tag.send_keys('웹크롤링') button = driver.find_element(By.CSS_SELECTOR, '#nx_search_form > fieldset > button > i') button.click() time.sleep(2) # ## 새로고침 print('새로 고침') driver.refresh() time.sleep(2) # ## 뒤로가기 print('뒤로가기') driver.back() time.sleep(2) # ## 앞으로가기 print('앞으로가기') driver.forward() time.sleep(2)
- 탭 조작
## 새로운 탭 생성 print('새로운 탭 생성') driver.execute_script('window.open("https://www.naver.com")') time.sleep(2) # ## 탭 이동 print('탭 이동') driver.switch_to.window(driver.window_handles[0]) # 원하는 탭의 idx 입력 time.sleep(2) # ## 탭 닫기 print('탭 닫기') driver.close() # 탭이 한개인 경우 종료 time.sleep(2) # # driver 종료 print('driver 종료') time.sleep(2) driver.quit()
크롬드라이버 실행 및 종료
- 크롬드라이버로 네이버에 접속하기
from selenium import webdriver from selenium.webdriver.chrome.service import Service # path = "../driver/chromedriver.exe" driver = webdriver.Chrome(service = Service(path)) url = 'https://www.naver.com/' driver.get(url)
- 크롬드라이버 종료
driver.quit() # driver.close()

기능 단계별 설명
스크롤
- 웹사이트에는 스크롤을 내리면 콘텐츠가 추가로 생성되도록 되는 기능이 있다. ex)네이버이미지
- 또는 동적인 기능을 갖는 소개 사이트들을 다루기 위함
강사님 페이지 접속
from selenium import webdriver # driver = webdriver.Chrome() url = 'https://pinkwink.kr/' driver.get(url)
스크롤 가능한 높이 가져오기
last_height = driver.execute_script("return document.body.scrollHeight") last_height

화면 스크롤
화면 스크롤
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")

특정 대상 화면 스크롤
"ROS 카메라 캘리브레이션 수행하기" XPath 복사
위치지정 후 스크롤
from selenium.webdriver import ActionChains from selenium.webdriver.common.by import By # some_tag = driver.find_element(By.XPATH, '//*[@id="content"]/div[4]/div/ul/li[2]/a/span[3]') action = ActionChains(driver) action.move_to_element(some_tag).perform()
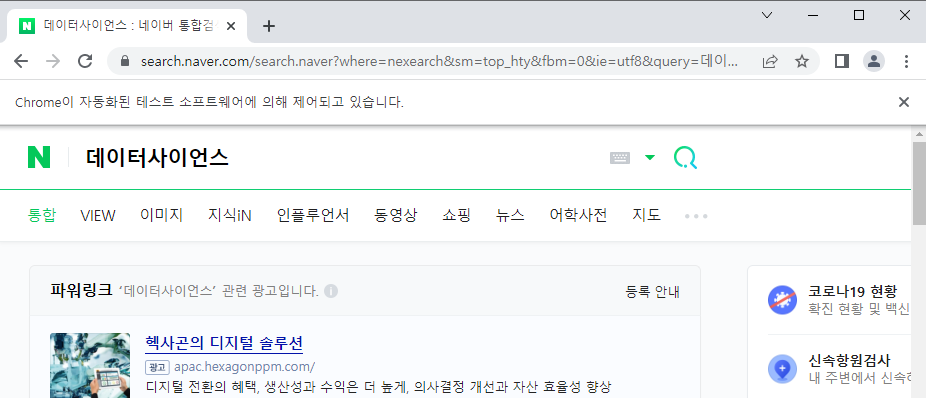
글자 입력
검색창 위치 확인
- 태그 : input
- 아이디 : query
- 클래스 : input_text
id는 고유값이므로 활용이 간편하다from selenium import webdriver # driver = webdriver.Chrome() url = 'https://www.naver.com/' driver.get(url) some_tag = driver.find_element(By.ID, 'query') some_tag.send_keys('데이터사이언스\n')

버튼 클릭
버튼 위치 확인
- 태그 : button
- 아이디 : search_btn
- 클래스 : btn_submit
driver.back() some_tag = driver.find_element(By.ID, 'query') some_tag.send_keys('웹크롤링') button = driver.find_element(By.ID, 'search_btn') button.click()


📌동적검색 창 사용하기 : ActionChains
강사님의 페이지 'pinkwink'의 검색창을 사용하기 위해서는 해당 검색을 누르고, 나타난 입력창에 검색어를 입력하고 검색버튼을 눌러야 작동한다
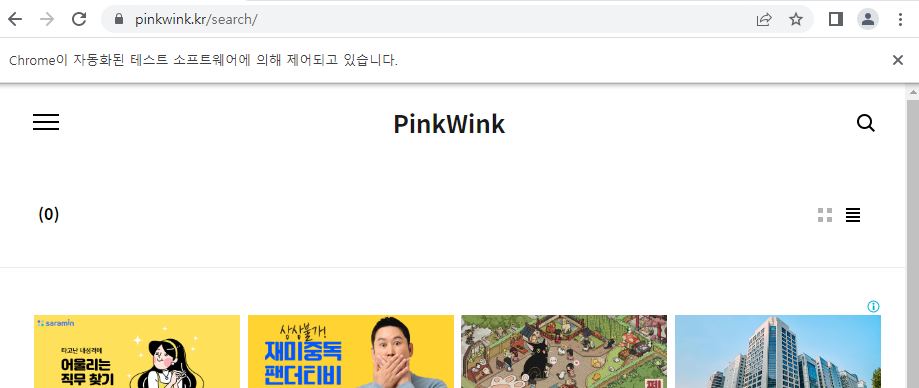

이러한 경우 Selenium의 기본기능만으로는 해결불가능하다
이럴 때 사용하는 것이 ActionChains이다
페이지 접속
from selenium import webdriver # driver = webdriver.Chrome() driver.get("https://pinkwink.kr/")
- 돋보기 버튼 선택
from selenium.webdriver.common.by import By from selenium.webdriver import ActionChains # search_tag = driver.find_element(By.CSS_SELECTOR, '#header > div.search') action = ActionChains(driver) action.click(search_tag) action.perform()
- 검색어 입력
driver.find_element(By.CSS_SELECTOR, '#header > div.search.on > input[type=text]').send_keys('딥러닝')

- 검색 버튼 클릭
driver.find_element(By.CSS_SELECTOR, '#header > div.search.on > button').click()

📌Selenium과 BeautifulSoup
현재페이지 html로 가져오기
from bs4 import BeautifulSoup # req = driver.page_source soup = BeautifulSoup(req, "html.parser") soup.select('.post-item')

BeautifulSoup 활용하기
contents = soup.select('.post-item') len(contents)

📌셀프주유소 가격 분석
- https://www.opinet.co.kr/searRgSelect.do
- 사이트 구조 확인
- 목표 데이터
- 브랜드
- 가격
- 셀프 주유 여부
- 위치
📌프로젝트 절차
- 사이트 분석
- 데이터 확보
- 데이터 정리
- 데이터 시각화
📌1. 사이트 분석 및 접근
오피넷을 검색해서 사이트 접속
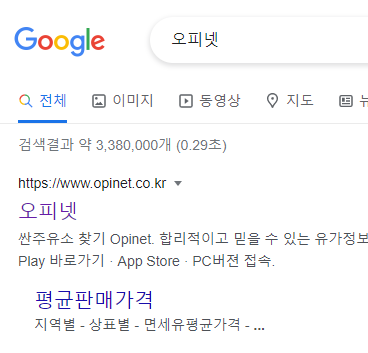
싼 주유소찾기 -> 지역별
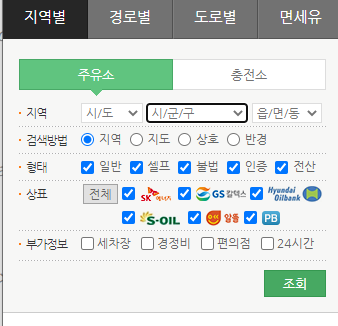
사이트 분석
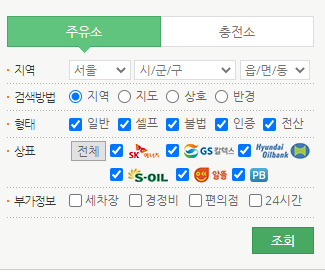
- 시/도, 시/군/구, /읍/면/동 등 주소 선택가능
- 형태, 상표, 부가정보 선택가능
- 데이터를 변경하면 지도에 갱신됨
- URL이 변화하지 않음
- 하단에 엑셀저장이 존재함
-> 해당 과정들을 마우스로 진행해야 함
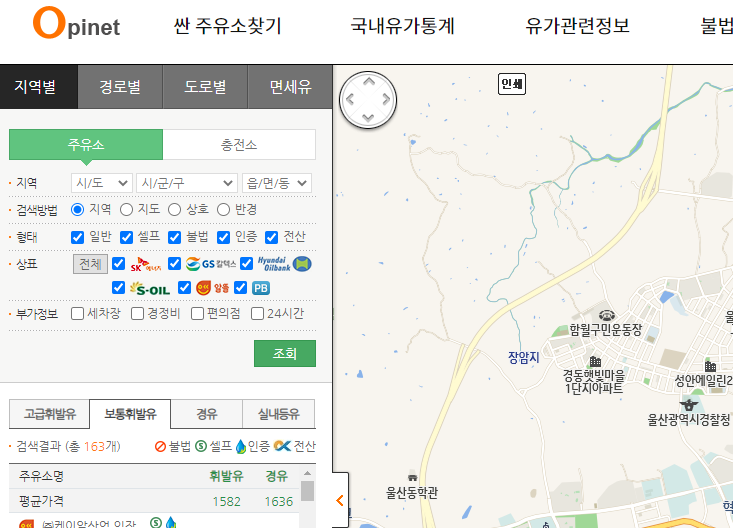
사이트 접근
- 팝업창이 생성되는 경우 반복문을 통해 제거
- URL 최초 접근은 홈페이지, 2번 접근해야 원하는 페이지 접근
from selenium import webdriver import time # def main_get(): # 1회 주소접근시 홈페이지로 이동 url = 'https://www.opinet.co.kr/searRgSelect.do' driver = webdriver.Chrome() driver.get(url) time.sleep(3) # 너무 빠른 실행시 오류 발생 driver.switch_to.window(driver.window_handles[-1]) # # 팝업 창 닫기 while len(driver.window_handles[:]) > 1: driver.close() driver.switch_to.window(driver.window_handles[-1]) # # 2회 접근하면 접근가능 driver.get(url) # main_get()
📌 2. 데이터 확보
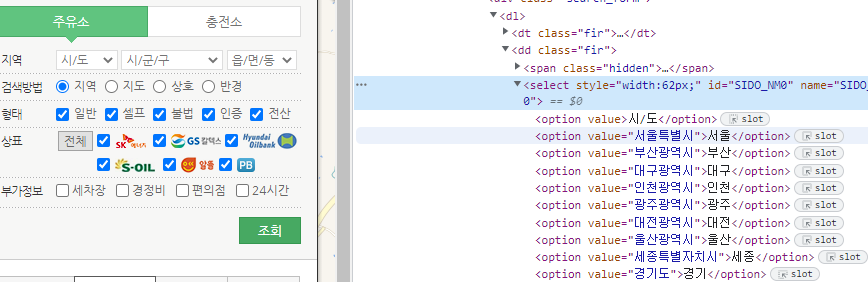
시/도 정보 위치
- SIDO_NM0 아이디 하위에 option 태그로 존재
- 구 데이터도 이와 같은 구조로 존재
사이트 접속
from selenium import webdriver import time # # 1회 주소접근시 홈페이지로 이동 url = 'https://www.opinet.co.kr/searRgSelect.do' driver = webdriver.Chrome() driver.get(url) time.sleep(3) # 너무 빠른 실행시 오류 발생 # # 팝업 창 닫기, 팝업이 없어서 주석처리 # driver.switch_to.window(driver.window_handles[-1]) # driver.close() # driver.switch_to.window(driver.window_handles[-1]) # # 2회 접근하면 접근가능 driver.get(url)
샘플테스트
시/도 정보 추출
from selenium.webdriver.common.by import By # sido_list_raw = driver.find_element(By.ID, "SIDO_NM0") sido_list_raw

그 중 '서울특별시' 추출
sido_list = sido_list_raw.find_elements(By.TAG_NAME, 'option') sido_list[1].get_attribute("value")

시/도에 '서울특별시' 정보 입력
sido_list_raw.send_keys(sido_list[1].get_attribute("value"))
엑셀저장
driver.find_elements(By.CSS_SELECTOR, "#glopopd_excel > span").click()
본문 적용
시/도 정보 습득
from selenium.webdriver.common.by import By # sido_list_raw = driver.find_element(By.ID, "SIDO_NM0") sido_list = sido_list_raw.find_elements(By.TAG_NAME, 'option') # sido_names = [option.get_attribute("value") for option in sido_list] sido_names = sido_names[1:] # 0번째 데이터는 '시/도' 표기이므로 배제 sido_names[:5], len(sido_names)

시/군/구 정보 습득
gu_list_raw = driver.find_element(By.ID,"SIGUNGU_NM0") # 부모 태그 gu_list = gu_list_raw.find_elements(By.TAG_NAME, "option") # 자식 태그 # gu_names = [option.get_attribute("value") for option in gu_list] gu_names = gu_names[1:] # 0번째 데이터는 '시/군/구' 표기이므로 배제 gu_names[:5], len(gu_names)
서울의 주유소 정보 습득
import time from tqdm import tqdm_notebook # 서울선택 sido = driver.find_element(By.ID, "SIDO_NM0") sido.send_keys(sido_names[0]) time.sleep(3) # # 구 데이터 수집 for gu in tqdm_notebook(gu_names): element = driver.find_element(By.ID, "SIGUNGU_NM0") element.send_keys(gu) time.sleep(3) # element_get_excel = driver.find_element(By.ID, "glopopd_excel").click() time.sleep(3)

📌 3. 데이터 정리
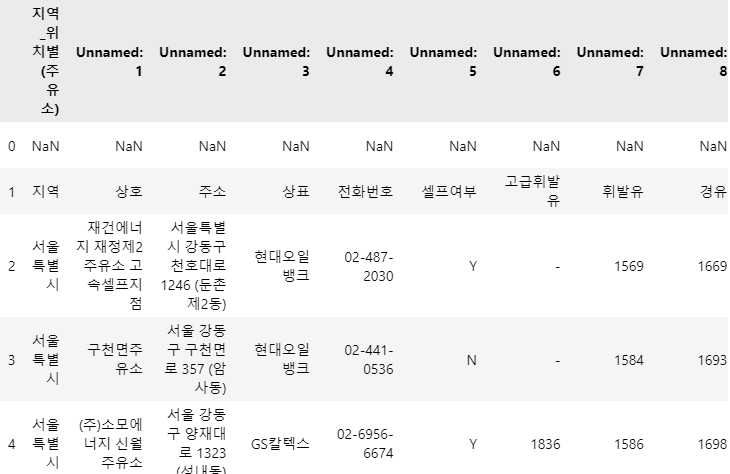
다운받은 엑셀파일 확인
import pandas as pd from glob import glob # stations_files = glob("../data/지역_*.xls") stations_files

샘플테스트
엑셀 읽기
tmp = pd.read_excel(stations_files[0] tmp.head()
헤드라인 조정
tmp = pd.read_excel(stations_files[0], header=2) tmp.head()
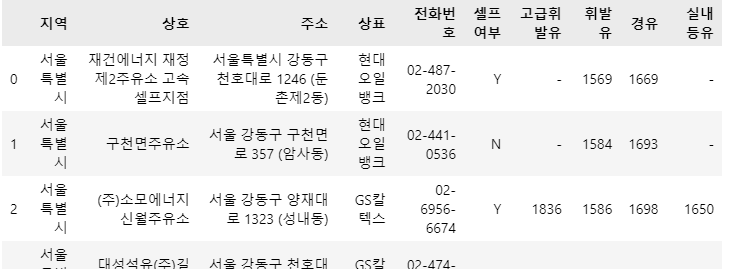
본문 적용
엑셀 합치기
tmp_raw = [] # for file_name in stations_files: tmp = pd.read_excel(file_name, header=2) tmp_raw.append(tmp) # station_raw = pd.concat(tmp_raw) station_raw

데이터 확인
station_raw.info() # 인덱스 재정렬필요
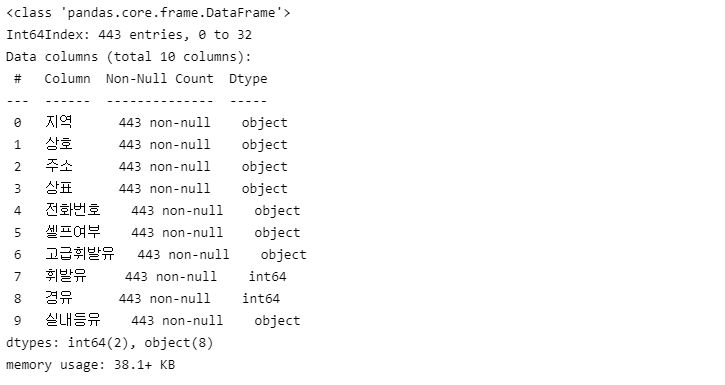
데이터프레임 생성
stations = pd.DataFrame( { "상호": station_raw['상호'], "주소": station_raw['주소'], "가격": station_raw['휘발유'], "셀프": station_raw['셀프여부'], "상표": station_raw['상표'], } ) stations.head()
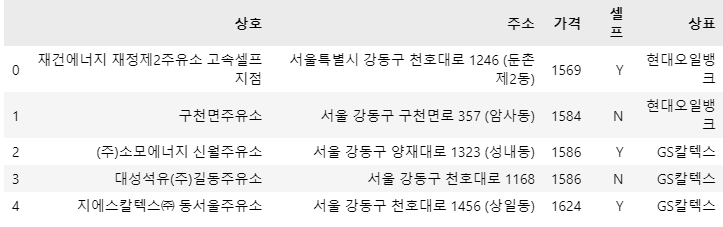
구별 데이터 생성
stations['구'] = [eachAddress.split()[1] for eachAddress in stations['주소']] stations.head()
구 데이터 오류 여부 확인
len(stations['구'].unique()), stations['구'].unique() #오류 없음

구 데이터 추가 후 데이터프레임 확인
stations.info()
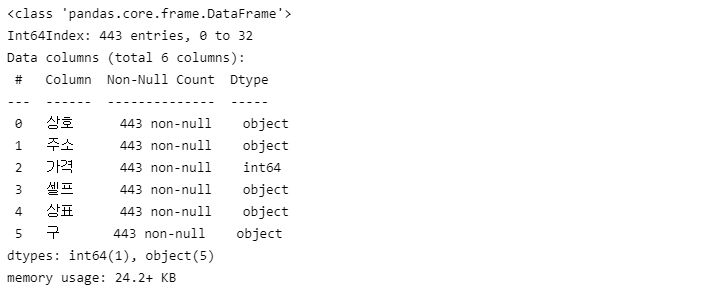
인덱스 리셋
stations.reset_index(inplace=True) stations.head()
인덱스 컬럼 제거
del stations['index'] stations.head()
📌 4. 데이터 시각화
윈도우 한글설정
import matplotlib.pyplot as plt import seaborn as sns import platform from matplotlib import font_manager, rc # # get_ipython().run_line_magic("matplotlib", "inline") %matplotlib inline # rc("font", family='Malgun Gothic') plt.title('한글') plt.show()

boxplot
pandas boxplot
stations.boxplot(column="가격", by="셀프", figsize=(12, 8));
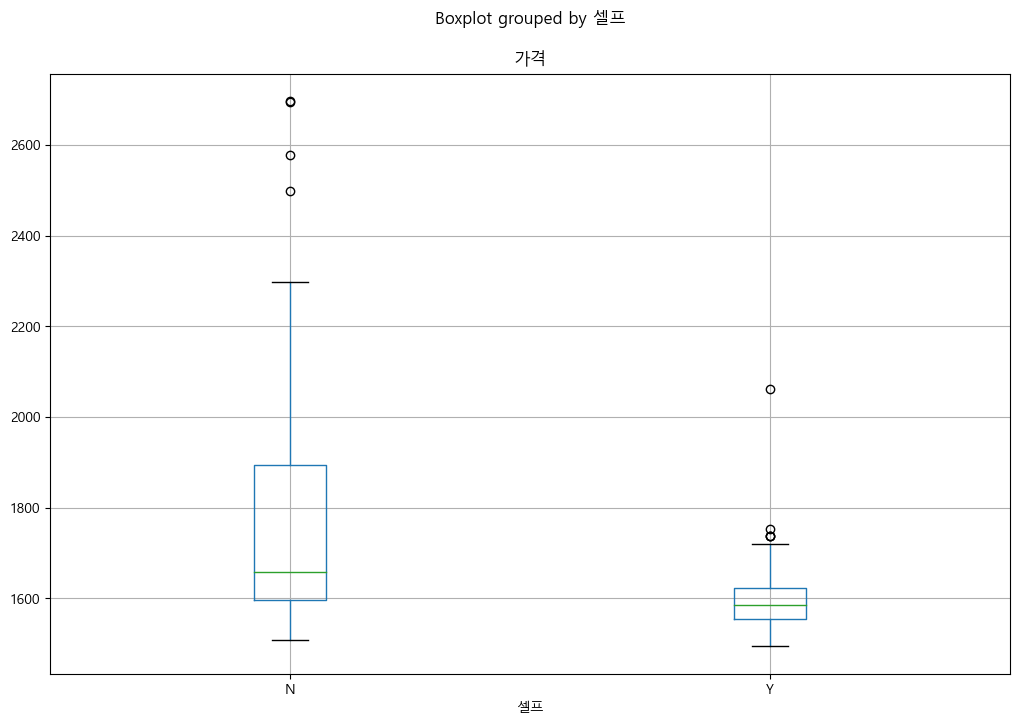
seaborn boxplot
plt.figure(figsize=(12, 8)) sns.boxplot(x="셀프", y="가격", data=stations, palette="Set1") plt.grid(True) plt.show()
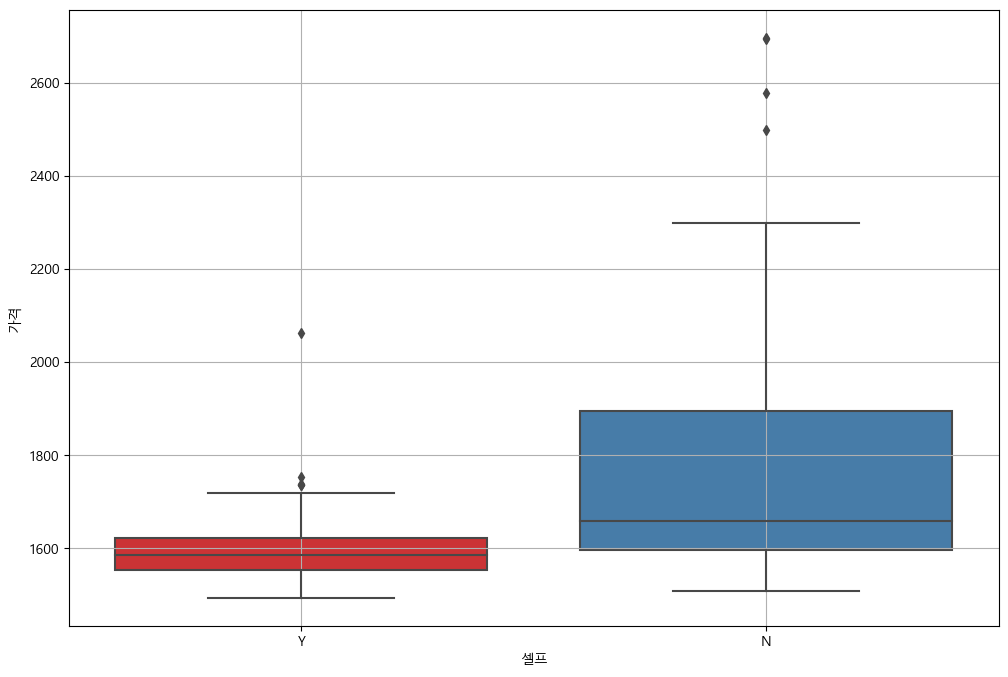
브랜드 별 휘발유 가격
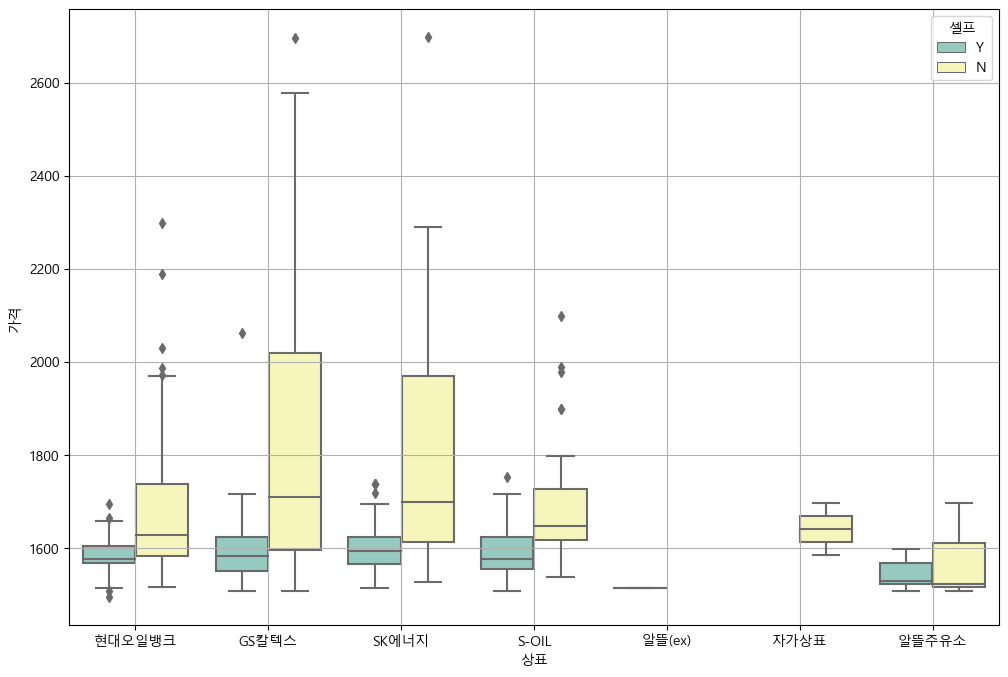
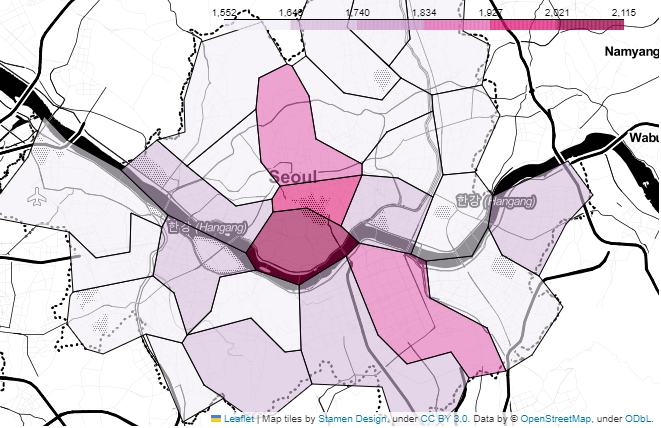
**지도 시각화**
>
```python
import json
import folium
import warnings
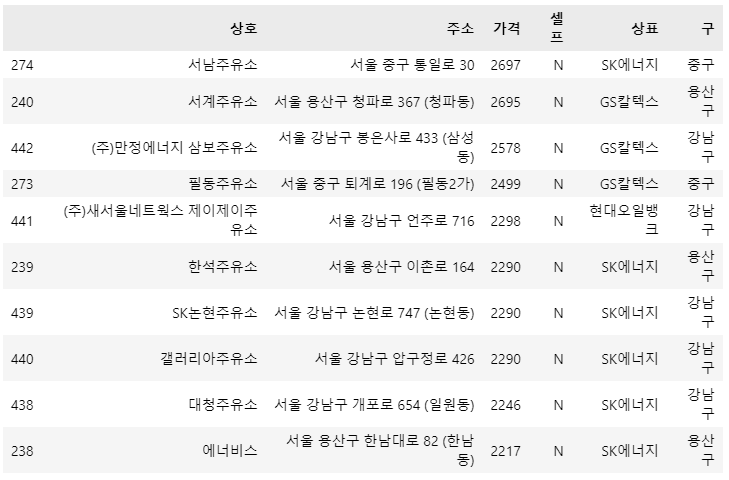
warnings.simplefilter(action="ignore", category=FutureWarning) # 경고무시가장 비싼 주유소 10개
stations.sort_values(by="가격", ascending=False).head(10)
가장 값싼 주유소 10개
stations.sort_values(by="가격", ascending=True).head(10)

구를 인덱스로, 가격을 평균으로 정렬
import numpy as np # gu_data = pd.pivot_table(data=stations, index="구", values="가격", aggfunc=np.mean) gu_data.head()

지도 시각화
geo_path = "../data/02. skorea_municipalities_geo_simple.json" geo_str = json.load(open(geo_path, encoding="utf-8")) # my_map = folium.Map(location=[37.5502, 126.982], zoom_start=10.5, tiles="Stamen Toner") my_map.choropleth( geo_data=geo_str, data=gu_data, columns=[gu_data.index, "가격"], key_on="feature.id", fill_color="PuRd" ) my_map