네이버 영화 평점

해당 글은 제로베이스데이터스쿨 학습자료를 참고하여 작성되었습니다
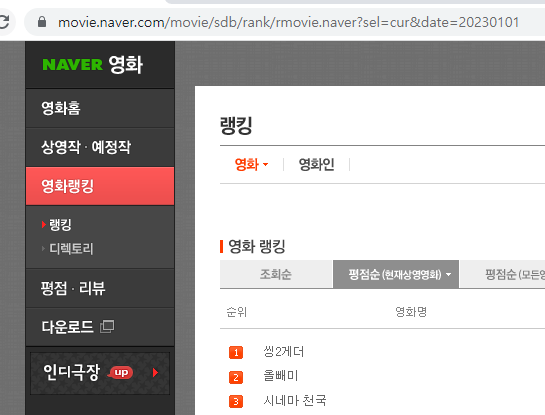
📌네이버 영화 평점 사이트 분석
- https://movie.naver.com/
- 영화랭킹 탭 이동
- 영화랭킹에서 평점순(현재상영영화) 선택
https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&date=20210914
- 웹 페이지 주소에는 많은 정보가 담겨있습니다.
- 원하는 정보를 얻기 위해서 변화시켜줘야 하는 주소의 규칙을 찾을 수 있습니다.
- 여기에서는 날짜 정보를 변경해주면 해당 페이지에 접근이 가능합니다.
📌프로젝트 절차
- 사이트 분석
- 데이터 확보
- 데이터 정리 및 시각화
📌1. 사이트 분석
- 네이버 영화 사이트에서 영화랭킹-> 평점순으로 보면 주소의 뒤에 날짜 데이터가 존재한다
- 이를 이용하면 원하는 날짜의 정보를 얻을 수 있게 된다
- 제목정보는 div.tit5, 평점은 td.point에 위치해있다

📌2. 데이터 확보
페이지 접속
페이지 접속
import pandas as pd from urllib.request import urlopen from bs4 import BeautifulSoup url = "https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&date=20210914" response = urlopen(url) soup = BeautifulSoup(response, "html.parser") print(soup.prettify())

샘플테스트
영화 제목 태그
soup.find_all("div", "tit5") # soup.select("div.tit5")

가장 첫번째 영화제목
soup.find_all("div", "tit5")[0].a.string

영화 평점 태그
soup.find_all("td", "point") # soup.select(".point")

영화제목 리스트
end = len(soup.find_all("div", "tit5")) # movie_name = [] # for n in range(0, end): movie_name.append( soup.find_all("div", "tit5")[n].a.string ) # movie_name = [soup.select(".tit5")[n].a.text for n in range(0, end)] movie_name

영화평점 리스트
end = len(soup.find_all("td", "point")) # movie_point = [soup.find_all("td", "point")[n].string for n in range(0, end)] movie_point

날짜데이터
21년1월1일부터 100일의 날짜데이터 생성
date = pd.date_range("2021.01.01", periods=100, freq="D") date

날짜 데이터 포맷팅
date[0].strftime("%Y-%m-%d") # date[0].strftime("%Y.%m.%d")

문자열 format
test_string = "Hi, I'm {name}" test_string.format(name="Pinkwink") # dir(test_string)

본문 적용
데이터프레임 생성을 위한 리스트 준비
import time from tqdm import tqdm # movie_date = [] movie_name = [] movie_point = [] # for today in tqdm(date): url = "https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&date={date}" response = urlopen(url.format(date=today.strftime("%Y%m%d"))) soup = BeautifulSoup(response, "html.parser") # end = len(soup.find_all("td", "point")) # movie_date.extend([today for _ in range(0, end)]) movie_name.extend([soup.select("div.tit5")[n].find("a").get_text() for n in range(0, end)]) movie_point.extend([soup.find_all("td", "point")[n].string for n in range(0, end)]) # time.sleep(0.5) # 너무 빠른속도의 데이터수집 방지

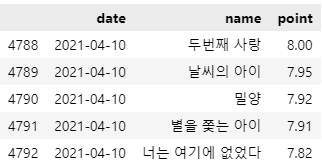
데이터프레임 생성
movie = pd.DataFrame({ "date": movie_date, "name": movie_name, "point": movie_point }) movie.tail()
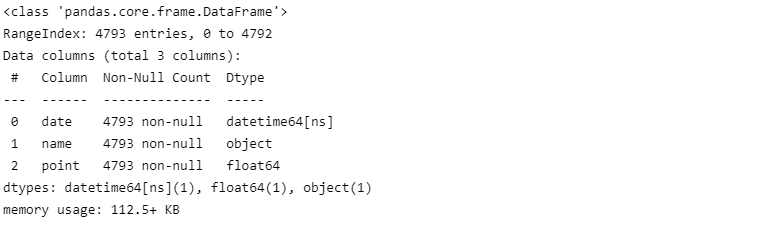
데이터 확인
movie.info()

데이터 타입 변경
movie["point"] = movie["point"].astype(float) movie.info() # 평점 결과가 object이므로 float로 변경
데이터 저장
movie.to_csv( "../data/03. naver_movie_data.csv", sep=",", encoding="utf-8" )
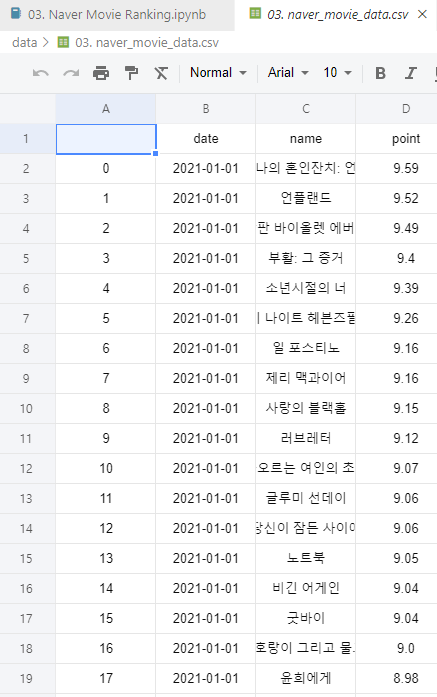
📌3. 데이터 정리 및 시각화
데이터정리
데이터 불러오기
import numpy as np import pandas as pd movie = pd.read_csv("../data/03. naver_movie_data.csv", index_col=0) movie.tail()
데이터 정리
movie_unique = pd.pivot_table(data=movie, index="name", values='point', aggfunc=np.mean) movie_unique

특정 영화 정보 조회
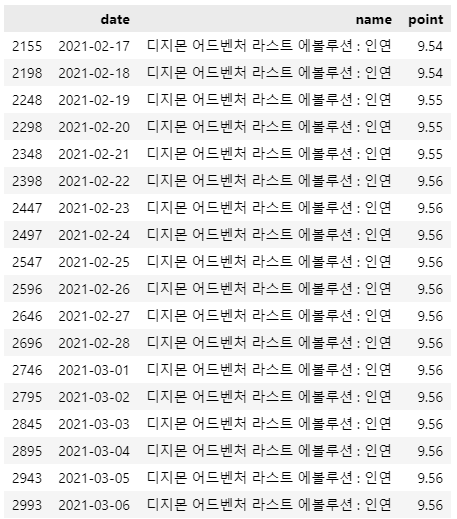
# 그나마 친숙해보이는 디지몬의 정보를 확인해보자 tmp = movie.query("name == ['디지몬 어드벤처 라스트 에볼루션 : 인연']") tmp
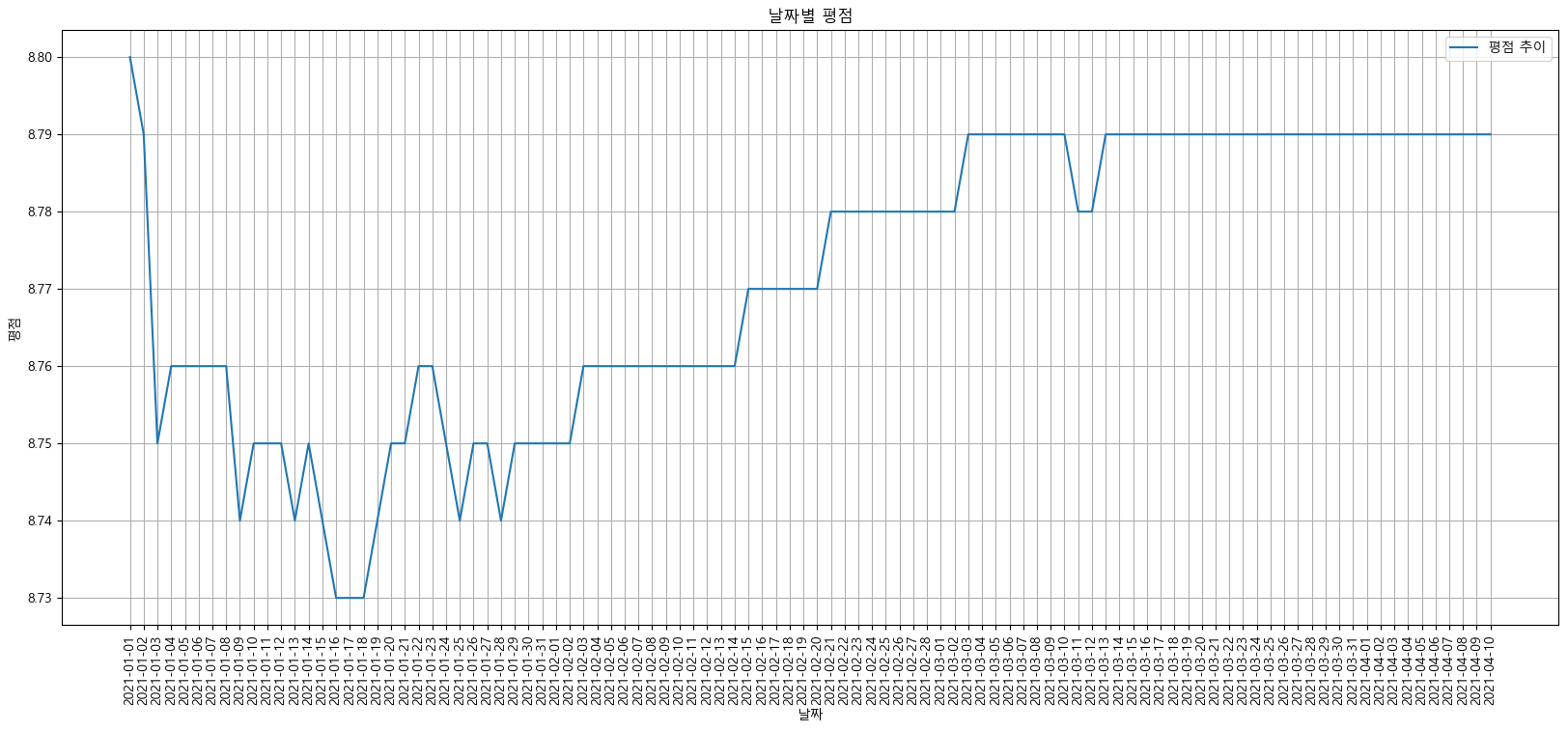
데이터 시각화
시각화
import matplotlib.pyplot as plt from matplotlib import rc # rc("font", family="Malgun Gothic") %matplotlib inline # get_ipython().run_line_magic("matplotlib", "inline")plt.figure(figsize=(20, 8)) # x 20, y, 8 plt.plot(tmp["date"], tmp["point"]) # 선 그래프 x축 날짜, y축 평점 => 날짜에 따른 평점 변화를 선그래프로 표현(시계열) plt.title("날짜별 평점") plt.xlabel("날짜") plt.ylabel("평점") plt.xticks(rotation="vertical") plt.legend(labels=["평점 추이"], loc="best") plt.grid(True) plt.show()
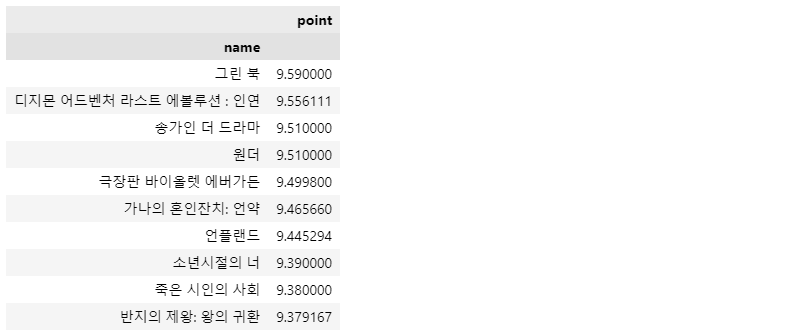
상위 10개 영화
movie_best.head(10)
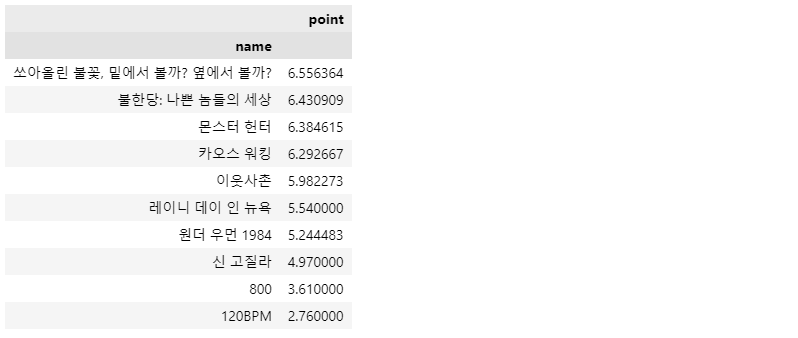
하위 10개 영화
movie_best.tail(10)
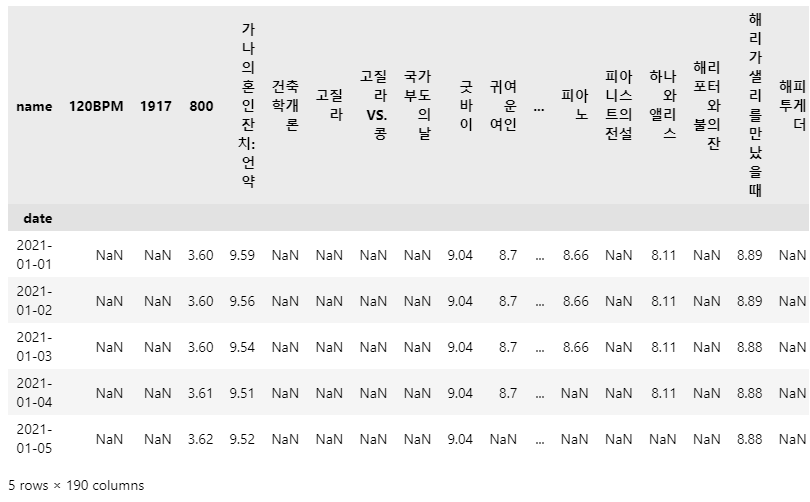
날짜를 index로 정렬
movie_pivot = pd.pivot_table(data=movie, index="date", columns="name", values="point") movie_pivot.head() # 데이터저장 movie_pivot.to_excel("../data/03. movie_pivot.xlsx")
한글설정
import platform import seaborn as sns from matplotlib import font_manager, rc # path = "C:/Windows/Fonts/malgun.ttf" # if platform.system() == "Darwin": rc("font", family="Arial Unicode MS") elif platform.system() == "Windows": font_name = font_manager.FontProperties(fname=path).get_name() rc("font", family=font_name) else: print("Unknown system. sorry")
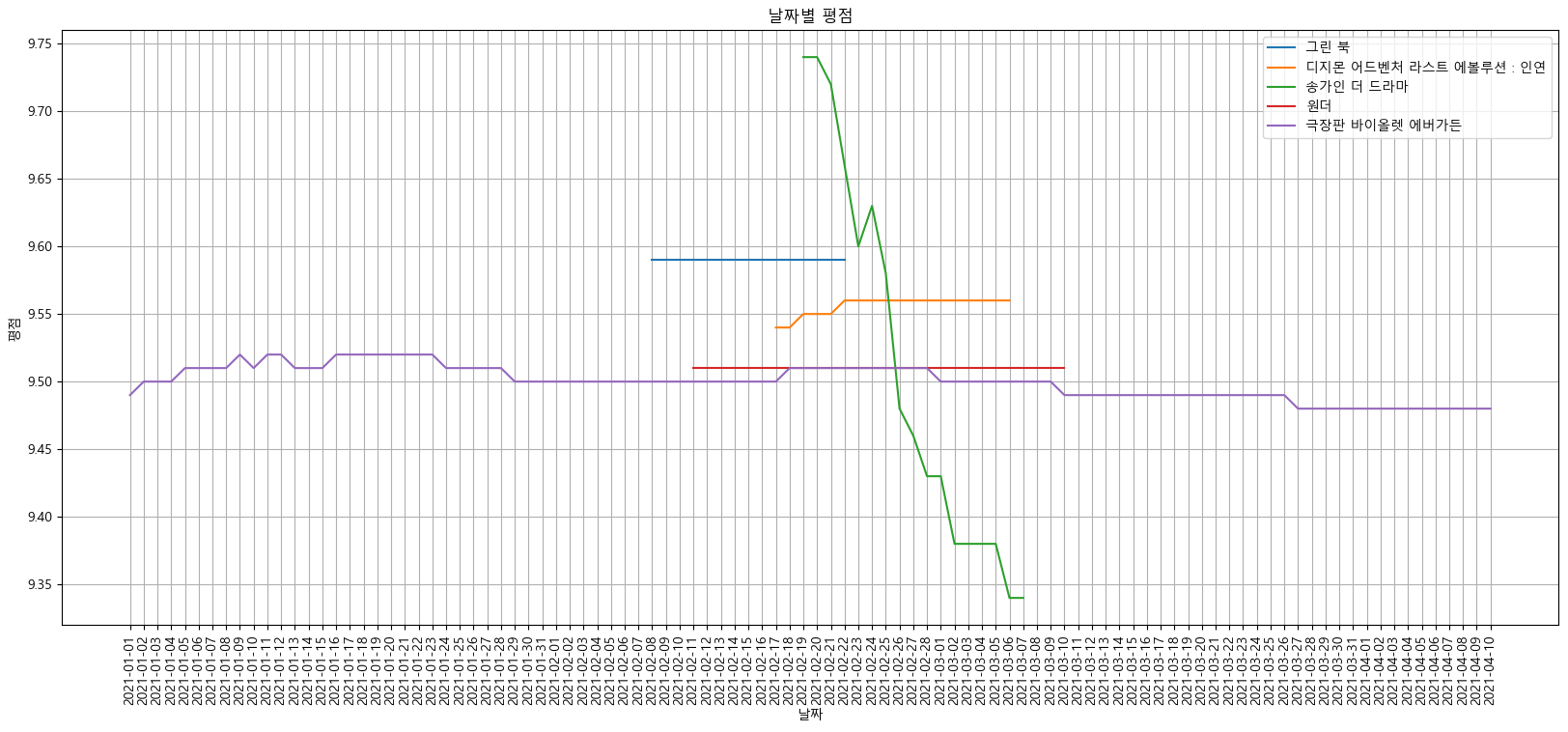
상위 5개 데이터 시각화
target_col = ["그린 북", "디지몬 어드벤처 라스트 에볼루션 : 인연", "송가인 더 드라마", "원더", "극장판 바이올렛 에버가든"] plt.figure(figsize=(20, 8)) plt.title("날짜별 평점") plt.xlabel("날짜") plt.ylabel("평점") plt.xticks(rotation="vertical") plt.tick_params(bottom="off", labelbottom="off") plt.plot(movie_pivot[target_col]) plt.legend(target_col, loc="best") plt.grid(True) plt.show()
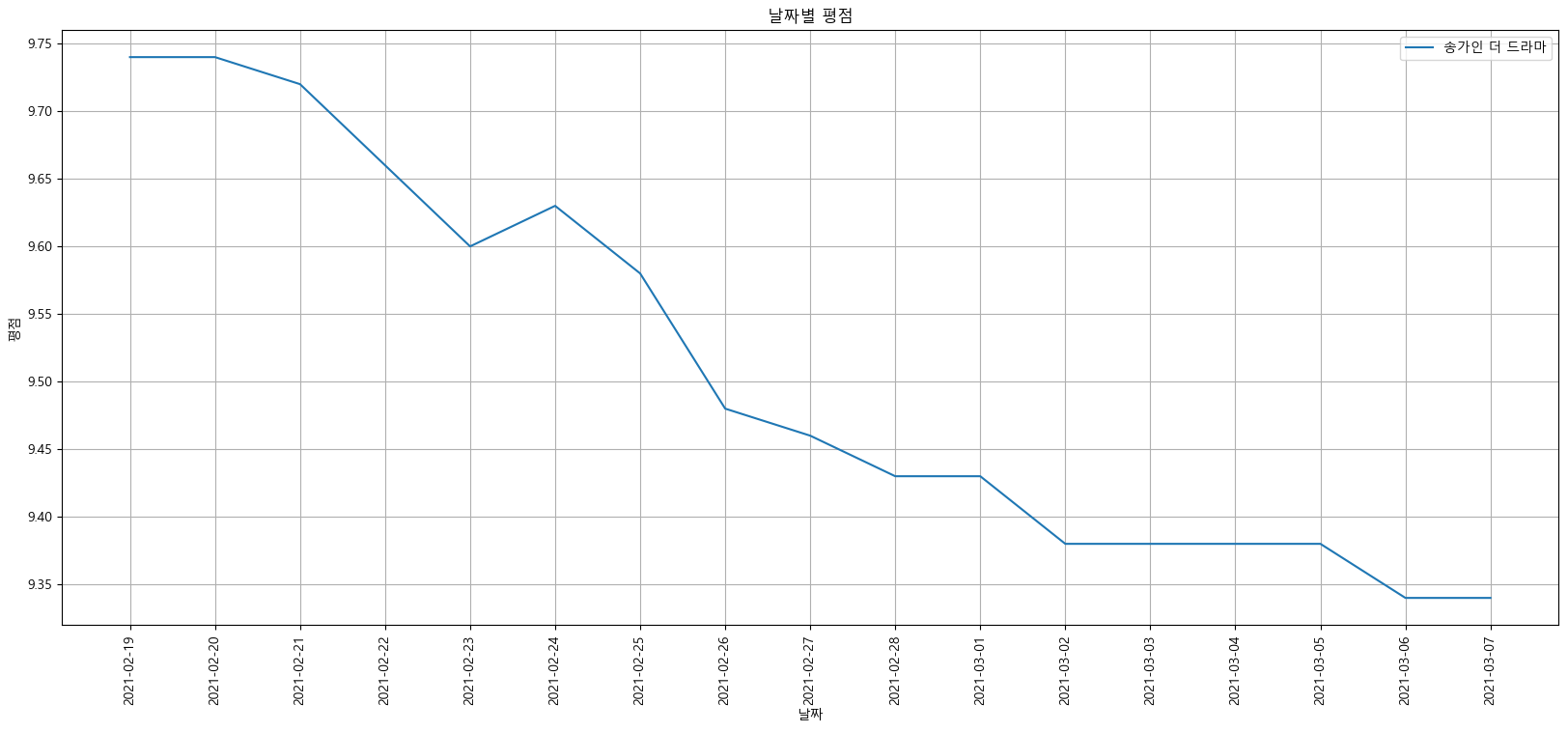
극적으로 변화한 데이터 집중 시각화
target_col = ["송가인 더 드라마"] plt.figure(figsize=(20, 8)) plt.title("날짜별 평점") plt.xlabel("날짜") plt.ylabel("평점") plt.xticks(rotation="vertical") plt.tick_params(bottom="off", labelbottom="off") plt.plot(movie_pivot[target_col]) plt.legend(target_col, loc="best") plt.grid(True) plt.show()